
Kreuzvalidierung in Python: Alles, was Sie wissen müssen
Veröffentlicht: 2020-02-14In der Datenwissenschaft ist die Validierung wahrscheinlich eine der wichtigsten Techniken, die von Datenwissenschaftlern verwendet werden, um die Stabilität des ML-Modells zu validieren und zu bewerten, wie gut es sich auf neue Daten verallgemeinern lässt. Die Validierung stellt sicher, dass das ML-Modell die richtigen (relevanten) Muster aus dem Datensatz aufnimmt und gleichzeitig das Rauschen im Datensatz erfolgreich unterdrückt. Im Wesentlichen besteht das Ziel von Validierungstechniken darin, sicherzustellen, dass ML-Modelle einen niedrigen Bias-Varianz-Faktor aufweisen.
Heute werden wir ausführlich über eine solche Modellvalidierungstechnik diskutieren – Kreuzvalidierung.
Inhaltsverzeichnis
Was ist Kreuzvalidierung?
Die Kreuzvalidierung ist eine Validierungstechnik, die entwickelt wurde, um zu bewerten und zu bewerten, wie sich die Ergebnisse der statistischen Analyse (Modell) auf einen unabhängigen Datensatz verallgemeinern lassen. Die Kreuzvalidierung wird hauptsächlich in Szenarien verwendet, in denen Vorhersagen das Hauptziel sind und der Benutzer abschätzen möchte, wie gut und genau ein Vorhersagemodell in realen Situationen funktioniert.
Die Kreuzvalidierung versucht, einen Datensatz zu definieren, indem das Modell in der Trainingsphase getestet wird, um Probleme wie Overfitting und Underfitting zu minimieren. Beachten Sie jedoch, dass sowohl die Validierung als auch das Trainingsset aus derselben Distribution extrahiert werden müssen, da dies sonst zu Problemen in der Validierungsphase führen würde.
Lernen Sie den Data Science-Zertifizierungskurs von den besten Universitäten der Welt kennen. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Vorteile der Kreuzvalidierung
- Es hilft, die Qualität Ihres Modells zu bewerten.
- Es hilft, Probleme mit Overfitting und Underfitting zu reduzieren/vermeiden.
- Sie können das Modell auswählen, das die beste Leistung bei unsichtbaren Daten liefert.
Lesen Sie: Python-Projekte für Anfänger
Was sind Overfitting und Underfitting?
Überanpassung bezieht sich auf den Zustand, wenn ein Modell zu datenempfindlich wird und am Ende viel Rauschen und zufällige Muster erfasst, die sich nicht gut auf unsichtbare Daten verallgemeinern lassen. Während ein solches Modell auf dem Trainingsset normalerweise gut abschneidet, leidet seine Leistung auf dem Testset.
Underfitting bezieht sich auf das Problem, wenn das Modell nicht genügend Muster im Datensatz erfasst und dadurch sowohl für das Trainings- als auch für das Test-Set eine schlechte Leistung liefert.
Wenn man sich diese beiden Extremitäten ansieht, ist das perfekte Modell eines, das sowohl für Trainings- als auch für Testsätze gleichermaßen gut abschneidet.
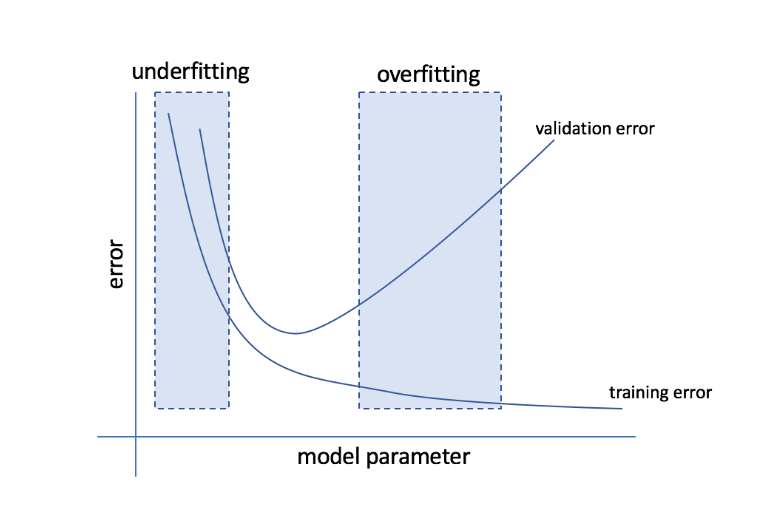
Quelle
Kreuzvalidierung: Verschiedene Validierungsstrategien
Validierungsstrategien werden basierend auf der Anzahl der Teilungen in einem Datensatz kategorisiert. Sehen wir uns nun die verschiedenen Cross-Validation-Strategien in Python an.
1. Validierungsset
Dieser Validierungsansatz teilt den Datensatz in zwei gleiche Teile – während 50 % des Datensatzes für die Validierung reserviert sind, sind die restlichen 50 % für das Modelltraining reserviert. Da dieser Ansatz das Modell auf der Grundlage von nur 50 % eines bestimmten Datensatzes trainiert, besteht immer die Möglichkeit, relevante und aussagekräftige Informationen zu verpassen, die in den anderen 50 % der Daten verborgen sind. Infolgedessen erzeugt dieser Ansatz im Allgemeinen eine höhere Verzerrung im Modell.
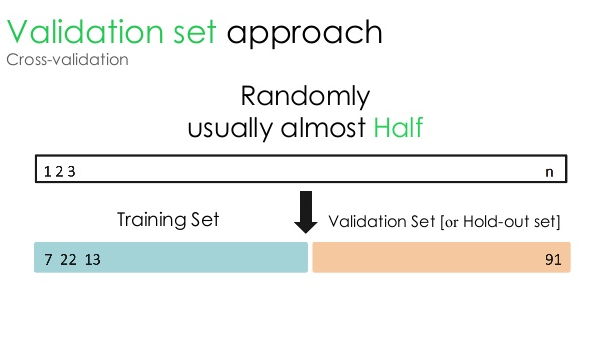
Quelle
Python-Code:
train, validation = train_test_split(data, test_size=0.50, random_state = 5)
2. Trainings-/Testaufteilung
Bei diesem Validierungsansatz wird der Datensatz in zwei Teile aufgeteilt – Trainingssatz und Testsatz. Dies geschieht, um eine Überlappung zwischen dem Trainingssatz und dem Testsatz zu vermeiden (wenn sich der Trainings- und der Testsatz überschneiden, ist das Modell fehlerhaft). Daher ist es wichtig sicherzustellen, dass der für das Modell verwendete Datensatz keine doppelten Proben in unserem Datensatz enthalten darf. Mit der Trainings-/Test-Split-Strategie können Sie Ihr Modell basierend auf dem gesamten Datensatz neu trainieren, ohne irgendwelche Hyperparameter des Modells zu ändern.

Quelle
Dieser Ansatz hat jedoch eine erhebliche Einschränkung – die Leistung und Genauigkeit des Modells hängen weitgehend davon ab, wie es aufgeteilt wird. Wenn die Aufteilung beispielsweise nicht zufällig ist oder eine Teilmenge des Datensatzes nur einen Teil der vollständigen Informationen enthält, führt dies zu einer Überanpassung. Bei diesem Ansatz können Sie nicht sicher sein, welche Datenpunkte sich in welchem Validierungssatz befinden, wodurch unterschiedliche Ergebnisse für verschiedene Sätze erzeugt werden. Daher sollte die Train/Test-Split-Strategie nur verwendet werden, wenn Sie genügend Daten zur Hand haben.
Python-Code:
>>> aus sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
Array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> Liste(n)
[0, 1, 2, 3, 4]
3. K-fach
Wie in den beiden vorherigen Strategien zu sehen ist, besteht die Möglichkeit, wichtige Informationen im Datensatz zu verpassen, was die Wahrscheinlichkeit eines durch Verzerrungen verursachten Fehlers oder einer Überanpassung erhöht. Dies erfordert eine Methode, die reichlich Daten für das Modelltraining reserviert und gleichzeitig genügend Daten für die Validierung hinterlässt.
Geben Sie die K-fache Validierungstechnik ein. Bei dieser Strategie wird der Datensatz in 'k' Teilmengen oder Falten aufgeteilt, wobei k-1 Teilmengen für das Modelltraining reserviert sind und die letzte Teilmenge für die Validierung (Testsatz) verwendet wird. Das Modell wird mit den einzelnen Falten gemittelt und dann finalisiert. Sobald das Modell fertiggestellt ist, können Sie es mit dem Testset testen.
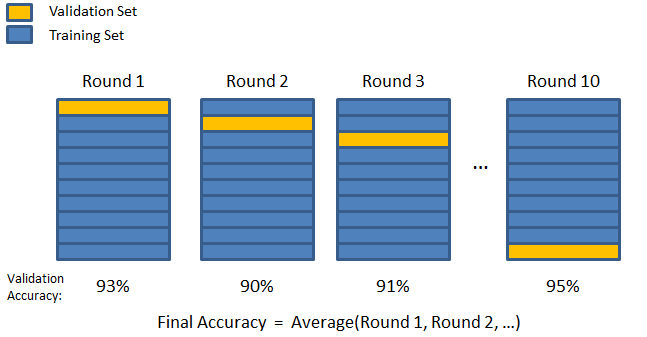
Quelle
Hier erscheint jeder Datenpunkt genau einmal im Validierungssatz, während er k-1-mal im Trainingssatz verbleibt. Da die meisten Daten für die Anpassung verwendet werden, wird das Problem der Unteranpassung erheblich reduziert. Ebenso wird das Problem der Überanpassung eliminiert, da ein Großteil der Daten auch im Validierungssatz verwendet wird.

Lesen Sie: Python vs Ruby: Vollständiger Side-by-Side-Vergleich
Die K-Fold-Strategie eignet sich am besten für Fälle, in denen Sie über eine begrenzte Datenmenge verfügen und es einen erheblichen Unterschied in der Qualität der Faltungen oder unterschiedliche optimale Parameter zwischen ihnen gibt.
Python-Code:
from sklearn.model_selection import KFold # import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # erstelle ein Array
y = np.array([1, 2, 3, 4]) # Erstellen Sie ein weiteres Array
kf = KFold(n_splits=2) # Definiere die Teilung – in 2 Falten
kf.get_n_splits(X) # gibt die Anzahl der Splitting-Iterationen im Cross-Validator zurück
drucken (kf)
KFold(n_splits=2, random_state=Keine, shuffle=False)
4. Lassen Sie eins weg
Die Leave-One-Out-Cross-Validation (LOOCV) ist ein Sonderfall des K-fachen, wenn k gleich der Anzahl der Stichproben in einem bestimmten Datensatz ist. Hier ist nur ein Datenpunkt für den Testsatz reserviert, und der Rest des Datensatzes ist der Trainingssatz. Wenn Sie also das „k-1“-Objekt als Trainingsmuster und das „1“-Objekt als Testsatz verwenden, werden sie weiterhin durch jedes Muster im Datensatz iterieren. Es ist die nützlichste Methode, wenn zu wenig Daten verfügbar sind.
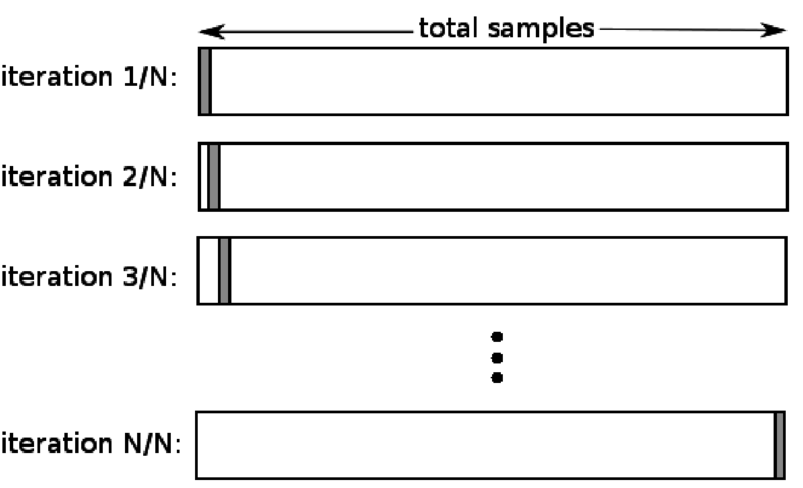
Quelle
Da dieser Ansatz alle Datenpunkte verwendet, ist die systematische Abweichung typischerweise gering. Da der Validierungsprozess jedoch n-mal wiederholt wird (n = Anzahl der Datenpunkte), führt dies zu einer längeren Ausführungszeit. Eine weitere bemerkenswerte Einschränkung der Methoden besteht darin, dass dies zu einer größeren Variation in der Effektivität des Testmodells führen kann, wenn Sie das Modell anhand eines Datenpunkts testen. Wenn dieser Datenpunkt also ein Ausreißer ist, erzeugt er einen höheren Variationsquotienten.
Python-Code:
>>> numpy als np importieren
>>> aus sklearn.model_selection import LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> y = np.array([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> drucken(klo)
LeaveOneOut()
>>> für train_index, test_index in loo.split(X):
… print("ZUG:", train_index, "TEST:", test_index)
… X_Zug, X_Test = X[Zug_Index], X[Test_Index]
… y_train, y_test = y[train_index], y[test_index]
… print(X_train, X_test, y_train, y_test)
ZUG: [1] TEST: [0]
[[3 4]] [[1 2]] [2] [1]
ZUG: [0] TEST: [1]
[[1 2]] [[3 4]] [1] [2]
5. Schichtung
Typischerweise werden die Daten für die Trainings-/Testaufteilung und die K-Faltung gemischt, um eine zufällige Trainings- und Validierungsaufteilung zu erstellen. Somit ermöglicht es eine unterschiedliche Zielverteilung in unterschiedlichen Faltungen. In ähnlicher Weise erleichtert die Schichtung auch die Zielverteilung über verschiedene Folds, während die Daten aufgeteilt werden.
Dabei werden Daten in verschiedenen Folds so neu arrangiert, dass sichergestellt wird, dass jedes Fold zu einem Repräsentanten des Ganzen wird. Wenn Sie es also mit einem binären Klassifizierungsproblem zu tun haben, bei dem jede Klasse aus 50 % der Daten besteht, können Sie die Daten mithilfe der Schichtung so anordnen, dass jede Klasse die Hälfte der Instanzen umfasst.
Der Schichtungsprozess eignet sich am besten für kleine und unausgeglichene Datensätze mit Mehrklassenklassifizierung.
Python-Code:
aus sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=None)
# X ist der Feature-Satz und y ist das Ziel
für train_index, test_index in skf.split(X,y):
print("Train:", train_index, "Validierung:", val_index)
X_Zug, X_Test = X[Zug_Index], X[Wert_Index]
y_train, y_test = y[train_index], y[val_index]
Lesen Sie: Datenrahmen in Python – Tutorial
Wann sollte jede dieser fünf Cross-Validation-Strategien verwendet werden?
Wie bereits erwähnt, hat jede Cross-Validation-Technik einzigartige Anwendungsfälle und funktioniert daher am besten, wenn sie korrekt auf die richtigen Szenarien angewendet wird. Wenn Sie beispielsweise über genügend Daten verfügen und die Ergebnisse und optimalen Parameter (des Modells) für verschiedene Aufteilungen wahrscheinlich ähnlich sind, funktioniert der Zug/Test-Aufteilungsansatz hervorragend.
Wenn jedoch die Werte und optimalen Parameter für verschiedene Splits variieren, ist die K-fache Technik am besten. In Fällen, in denen Sie zu wenig Daten haben, funktioniert der LOOCV-Ansatz am besten, während bei kleinen und unausgewogenen Datensätzen die Schichtung der richtige Weg ist.
Wir hoffen, dass dieser ausführliche Artikel Ihnen dabei geholfen hat, sich ein umfassendes Bild von Cross-Validation in Python zu machen.
Wenn Sie neugierig sind, etwas über Data Science zu lernen, schauen Sie sich das Executive PG Program in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1 -on-1 mit Branchenmentoren, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was ist der „Permutationstest“ in ML?
Durch Generieren einer Teststatistik für den Datensatz und dann für viele zufällige Permutationen dieser Daten wird ein Permutationstest verwendet, um die statistische Signifikanz eines Modells zu bewerten. Der anfängliche Teststatistikwert sollte in einen der Enden der Nullhypothesenverteilung fallen, wenn das Modell signifikant ist. Um den p-Wert zu finden, müssen Sie einfach die Anzahl der Teststatistiken zählen, die genauso schwerwiegend oder extremer als die ursprünglichen Teststatistiken sind, und diese Zahl dann durch die Gesamtzahl der von uns berechneten Teststatistiken dividieren. Da die Nullhypothese wahr ist, ist der P-Wert die Wahrscheinlichkeit, ein Ergebnis zu erhalten, das mindestens so schwerwiegend ist wie die Teststatistik.
Welche Nachteile hat die Kreuzvalidierung beim maschinellen Lernen?
1. Cross Validation verlängert die Ausbildungszeit erheblich. Bisher konnten Sie Ihr Modell nur mit einem Trainingssatz trainieren; Jetzt können Sie es mit Cross Validation in mehreren Trainingssets trainieren.
2. In den meisten Fällen entwickelt sich die Struktur, die Sie untersuchen, im Laufe der Zeit bei der Vorhersagemodellierung. Daher können Sie Abweichungen in den Trainings- und Validierungssätzen feststellen.
3. Kreuzvalidierung erfordert viel Rechenleistung.
Wie kann ich Overfitting in ML-Modellen erkennen?
Bevor Sie die Daten auswerten, ist es nahezu unmöglich, eine Überanpassung zu erkennen. Es kann bei der Schwierigkeit helfen, Datensätze zu verallgemeinern, was ein wesentliches Merkmal von Overfitting ist. Infolgedessen können die Daten in verschiedene Teilmengen unterteilt werden, um das Training und Testen zu erleichtern. Der Anteil der Genauigkeit, der in beiden Datensätzen zu sehen ist, kann verwendet werden, um zu bestimmen, ob eine Überanpassung vorliegt oder nicht. Wenn das Modell auf dem Trainingsdatensatz besser abschneidet als auf dem Testdatensatz, besteht die Möglichkeit einer Überanpassung.
Ein weiterer Vorschlag ist, mit einem sehr einfachen ML-Modell zu beginnen, das als Basis dient. Später, wenn Sie komplexe Algorithmen testen, haben Sie einen Benchmark, anhand dessen Sie beurteilen können, ob sich die zusätzliche Komplexität lohnt.
Validierungsmaße wie Genauigkeit und Verlust können auch verwendet werden, um eine Überanpassung zu erkennen. Wenn das Modell von Überanpassung betroffen ist, wachsen die Validierungsmaße im Allgemeinen, bis sie ein Plateau erreichen oder zu sinken beginnen.