
การตรวจสอบความถูกต้องใน Python: ทุกสิ่งที่คุณต้องรู้เกี่ยวกับ
เผยแพร่แล้ว: 2020-02-14ใน Data Science การตรวจสอบความถูกต้องน่าจะเป็นเทคนิคที่สำคัญที่สุดวิธีหนึ่งที่ใช้โดย Data Scientists เพื่อตรวจสอบความเสถียรของแบบจำลอง ML และประเมินว่าข้อมูลใหม่จะสรุปโดยรวมได้ดีเพียงใด การตรวจสอบความถูกต้องช่วยให้มั่นใจว่าโมเดล ML จะเลือกรูปแบบที่ถูกต้อง (ที่เกี่ยวข้อง) จากชุดข้อมูล ในขณะที่สามารถขจัดสัญญาณรบกวนในชุดข้อมูลได้สำเร็จ โดยพื้นฐานแล้ว เป้าหมายของเทคนิคการตรวจสอบความถูกต้องคือการทำให้แน่ใจว่าโมเดล ML มีปัจจัยความแปรปรวนอคติต่ำ
วันนี้เราจะมาพูดคุยกันอย่างยาวเหยียดเกี่ยวกับเทคนิคการตรวจสอบแบบจำลองอย่างใดอย่างหนึ่ง – การตรวจสอบความถูกต้อง
สารบัญ
การตรวจสอบข้ามคืออะไร?
Cross-Validation เป็นเทคนิคการตรวจสอบความถูกต้องที่ออกแบบมาเพื่อประเมินและประเมินว่าผลลัพธ์ของการวิเคราะห์ทางสถิติ (แบบจำลอง) จะสรุปเป็นชุดข้อมูลอิสระได้อย่างไร การตรวจสอบข้ามจะใช้เป็นหลักในสถานการณ์ที่การคาดการณ์เป็นเป้าหมายหลัก และผู้ใช้ต้องการประเมินว่าแบบจำลองการคาดการณ์จะทำงานได้ดีเพียงใดในสถานการณ์จริง
Cross-Validation พยายามที่จะกำหนดชุดข้อมูลโดยการทดสอบแบบจำลองในขั้นตอนการฝึกเพื่อช่วยลดปัญหาต่างๆ เช่น การใส่มากเกินไปและน้อยไป อย่างไรก็ตาม คุณต้องจำไว้ว่าทั้งการตรวจสอบความถูกต้องและชุดการฝึกต้องแยกออกจากการแจกจ่ายเดียวกัน มิฉะนั้นจะนำไปสู่ปัญหาในขั้นตอนการตรวจสอบ
เรียนรู้ หลักสูตรการรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ประโยชน์ของการตรวจสอบไขว้
- ช่วยประเมินคุณภาพของแบบจำลองของคุณ
- ช่วยลด/หลีกเลี่ยงปัญหาการสวมใส่มากเกินไปและการสวมใส่ไม่พอดี
- ช่วยให้คุณเลือกแบบจำลองที่จะให้ประสิทธิภาพสูงสุดกับข้อมูลที่มองไม่เห็น
อ่าน: โครงการ Python สำหรับผู้เริ่มต้น
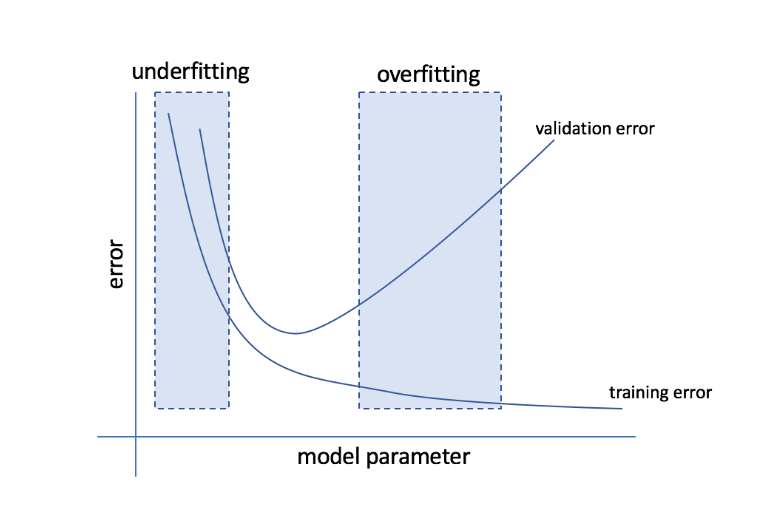
Overfitting และ Underfitting คืออะไร?
Overfitting หมายถึงสภาวะที่โมเดลมีความอ่อนไหวต่อข้อมูลมากเกินไป และจบลงด้วยการดักจับสัญญาณรบกวนและรูปแบบสุ่มจำนวนมากซึ่งไม่สามารถสรุปได้ดีกับข้อมูลที่มองไม่เห็น แม้ว่าโมเดลดังกล่าวมักจะทำงานได้ดีในชุดการฝึก แต่ประสิทธิภาพของโมเดลดังกล่าวก็จะลดลงในชุดทดสอบ
Underfitting หมายถึงปัญหาเมื่อตัวแบบไม่สามารถจับรูปแบบที่เพียงพอในชุดข้อมูลได้ ส่งผลให้ทั้งการฝึกอบรมและชุดทดสอบมีประสิทธิภาพต่ำ
ด้วยสองแขนขานี้ โมเดลที่สมบูรณ์แบบคือรุ่นที่ทำงานได้ดีเท่ากันสำหรับทั้งชุดฝึกซ้อมและชุดทดสอบ
แหล่งที่มา
การตรวจสอบข้าม: กลยุทธ์การตรวจสอบที่แตกต่างกัน
กลยุทธ์การตรวจสอบจะถูกจัดประเภทตามจำนวนการแยกที่ทำในชุดข้อมูล ตอนนี้ มาดูกลยุทธ์ Cross-Validation ที่แตกต่างกันใน Python
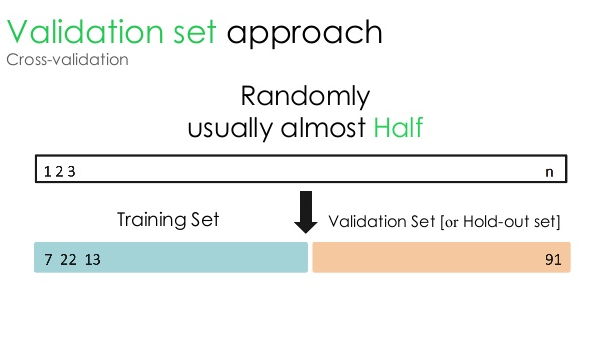
1. ชุดตรวจสอบความถูกต้อง
วิธีการตรวจสอบความถูกต้องนี้แบ่งชุดข้อมูลออกเป็นสองส่วนเท่า ๆ กัน – ในขณะที่ 50% ของชุดข้อมูลถูกสงวนไว้สำหรับการตรวจสอบ ส่วนที่เหลืออีก 50% สงวนไว้สำหรับการฝึกแบบจำลอง เนื่องจากวิธีการนี้ฝึกโมเดลโดยอิงจากชุดข้อมูลที่กำหนดเพียง 50% จึงมีความเป็นไปได้ที่จะพลาดข้อมูลที่เกี่ยวข้องและมีความหมายที่ซ่อนอยู่ในอีก 50% ของข้อมูล ด้วยเหตุนี้ แนวทางนี้จึงทำให้เกิดความเอนเอียงในแบบจำลองที่สูงขึ้น
แหล่งที่มา
รหัสหลาม:
รถไฟ การตรวจสอบความถูกต้อง = train_test_split(ข้อมูล test_size=0.50, random_state = 5)
2. แยกรถไฟ/ทดสอบ
ในแนวทางการตรวจสอบความถูกต้องนี้ ชุดข้อมูลจะถูกแบ่งออกเป็นสองส่วน – ชุดการฝึกและชุดทดสอบ สิ่งนี้ทำเพื่อหลีกเลี่ยงการทับซ้อนกันระหว่างชุดการฝึกและชุดทดสอบ (หากชุดการฝึกและชุดทดสอบทับซ้อนกัน โมเดลจะผิดพลาด) ดังนั้นจึงเป็นสิ่งสำคัญที่จะต้องแน่ใจว่าชุดข้อมูลที่ใช้สำหรับโมเดลจะต้องไม่มีตัวอย่างที่ซ้ำกันในชุดข้อมูลของเรา กลยุทธ์การแยกฝึก/ทดสอบช่วยให้คุณฝึกโมเดลของคุณใหม่โดยอิงตามชุดข้อมูลทั้งหมดโดยไม่ต้องแก้ไขไฮเปอร์พารามิเตอร์ใดๆ ของโมเดล

แหล่งที่มา
อย่างไรก็ตาม แนวทางนี้มีข้อจำกัดที่สำคัญประการหนึ่ง นั่นคือ ประสิทธิภาพและความแม่นยำของโมเดลส่วนใหญ่ขึ้นอยู่กับวิธีการแยกส่วน ตัวอย่างเช่น หากการแบ่งแยกไม่ใช่แบบสุ่ม หรือชุดข้อมูลย่อยหนึ่งชุดมีข้อมูลเพียงบางส่วนเท่านั้น จะนำไปสู่การใส่มากเกินไป ด้วยวิธีการนี้ คุณไม่สามารถแน่ใจได้ว่าจุดข้อมูลใดจะอยู่ในชุดการตรวจสอบความถูกต้อง ดังนั้นจึงสร้างผลลัพธ์ที่แตกต่างกันสำหรับชุดที่แตกต่างกัน ดังนั้น ควรใช้กลยุทธ์การแยกฝึก/ทดสอบเมื่อคุณมีข้อมูลเพียงพอเท่านั้น
รหัสหลาม:
>>> จาก sklearn.model_selection นำเข้า train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
อาร์เรย์ ([, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> รายการ (ป)
[0, 1, 2, 3, 4]
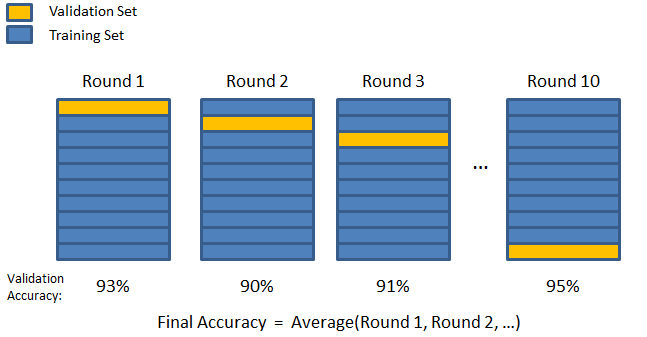
3. K-fold
ตามที่เห็นในสองกลยุทธ์ก่อนหน้านี้ มีความเป็นไปได้ที่จะพลาดข้อมูลสำคัญในชุดข้อมูล ซึ่งเพิ่มความน่าจะเป็นของข้อผิดพลาดที่เกิดจากอคติหรือความเหมาะสมมากเกินไป สิ่งนี้เรียกร้องให้มีวิธีการที่สงวนข้อมูลไว้มากมายสำหรับการฝึกแบบจำลองในขณะที่ยังเหลือข้อมูลเพียงพอสำหรับการตรวจสอบ
ป้อนเทคนิคการตรวจสอบ K-fold ในกลยุทธ์นี้ ชุดข้อมูลจะถูกแบ่งออกเป็นจำนวน 'k' ของชุดย่อยหรือการพับ โดยที่ชุดย่อย k-1 ถูกสงวนไว้สำหรับการฝึกโมเดล และชุดย่อยสุดท้ายจะใช้สำหรับการตรวจสอบความถูกต้อง (ชุดทดสอบ) แบบจำลองนี้ใช้ค่าเฉลี่ยเทียบกับแต่ละพับแล้วจึงสรุป เมื่อแบบจำลองเสร็จสิ้น คุณสามารถทดสอบได้โดยใช้ชุดทดสอบ
แหล่งที่มา
ที่นี่ จุดข้อมูลแต่ละจุดจะปรากฏในชุดการตรวจสอบความถูกต้องเพียงครั้งเดียวในขณะที่เหลืออยู่ในชุดการฝึก k-1 จำนวนครั้ง เนื่องจากข้อมูลส่วนใหญ่ใช้สำหรับการปรับให้พอดี ปัญหาเรื่องชุดรัดรูปจึงลดลงอย่างมาก ในทำนองเดียวกัน ปัญหาเรื่องการใส่มากเกินไปจะหมดไป เนื่องจากข้อมูลส่วนใหญ่ยังถูกใช้ในชุดการตรวจสอบความถูกต้องด้วย

อ่าน: Python vs Ruby: เปรียบเทียบแบบเคียงข้างกันอย่างสมบูรณ์
กลยุทธ์ K-fold ดีที่สุดสำหรับอินสแตนซ์ที่คุณมีข้อมูลในจำนวนจำกัด และคุณภาพของการพับหรือพารามิเตอร์ที่เหมาะสมต่างกันนั้นมีความแตกต่างกันอย่างมาก
รหัสหลาม:
จาก sklearn.model_selection นำเข้า KFold # นำเข้า KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # สร้างอาร์เรย์
y = np.array([1, 2, 3, 4]) # สร้างอาร์เรย์อื่น
kf = KFold(n_splits=2) # Define the split – เป็น 2 เท่า
kf.get_n_splits(X) # ส่งคืนจำนวนการแยกซ้ำในตัวตรวจสอบข้าม
พิมพ์ (kf)
KFold(n_splits=2, random_state=None, shuffle=False)
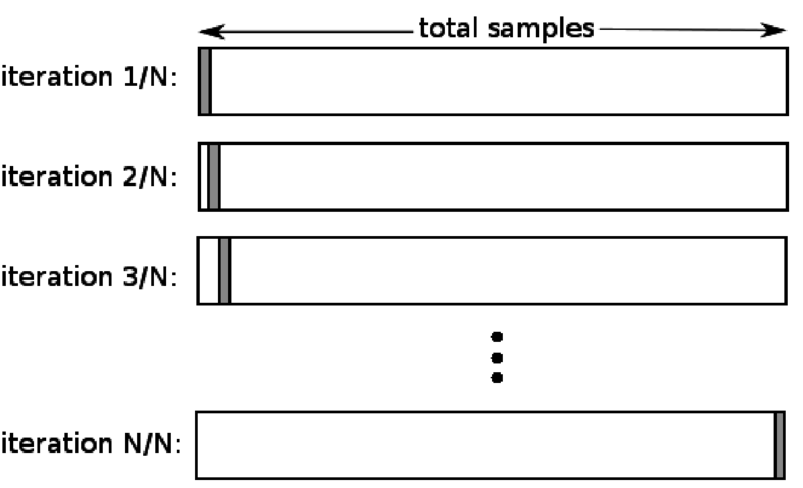
4. ปล่อยหนึ่งออกไป
Leave one out cross-validation (LOOCV) เป็นกรณีพิเศษของ K-fold เมื่อ k เท่ากับจำนวนตัวอย่างในชุดข้อมูลเฉพาะ ในที่นี้ จะสงวนจุดข้อมูลเพียงจุดเดียวสำหรับชุดการทดสอบ และชุดข้อมูลที่เหลือคือชุดการฝึก ดังนั้น หากคุณใช้ออบเจ็กต์ "k-1" เป็นตัวอย่างการฝึก และใช้ออบเจ็กต์ "1" เป็นชุดทดสอบ วัตถุเหล่านั้นจะวนซ้ำทุกตัวอย่างในชุดข้อมูลต่อไป เป็นวิธีที่มีประโยชน์มากที่สุดเมื่อมีข้อมูลน้อยเกินไป
แหล่งที่มา
เนื่องจากวิธีนี้ใช้จุดข้อมูลทั้งหมด ความเอนเอียงจึงมักจะต่ำ อย่างไรก็ตาม เนื่องจากกระบวนการตรวจสอบความถูกต้องซ้ำแล้วซ้ำอีก 'n' ครั้ง (n=จำนวนจุดข้อมูล) จึงส่งผลให้มีเวลาดำเนินการมากขึ้น ข้อจำกัดที่โดดเด่นอีกประการของวิธีการคืออาจนำไปสู่การเปลี่ยนแปลงที่สูงขึ้นในประสิทธิภาพของแบบจำลองการทดสอบเมื่อคุณทดสอบแบบจำลองกับจุดข้อมูลหนึ่งจุด ดังนั้น หากจุดข้อมูลนั้นเป็นค่าผิดปกติ ก็จะสร้างผลหารการเปลี่ยนแปลงที่สูงขึ้น
รหัสหลาม:
>>> นำเข้า numpy เป็น np
>>> จาก sklearn.model_selection นำเข้า LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> y = np.array([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>>พิมพ์(ลู)
LeaveOneOut()
>>> สำหรับ train_index, test_index ใน loo.split(X):
… พิมพ์ (“TRAIN:”, train_index, “TEST:”, test_index)
… X_train, X_test = X[train_index], X[test_index]
… y_train, y_test = y[train_index], y[test_index]
… พิมพ์ (X_train, X_test, y_train, y_test)
รถไฟ: [1] ทดสอบ: [0]
[[3 4]] [[1 2]] [2] [1]
รถไฟ: [0] ทดสอบ: [1]
[[1 2]] [[3 4]] [1] [2]
5. การแบ่งชั้น
โดยทั่วไป สำหรับการแบ่งการฝึก/การทดสอบและการแบ่ง K ข้อมูลจะถูกสับเปลี่ยนเพื่อสร้างการฝึกแบบสุ่มและการแยกการตรวจสอบ ดังนั้นจึงช่วยให้มีการกระจายเป้าหมายที่แตกต่างกันในส่วนต่างๆ ในทำนองเดียวกัน การแบ่งชั้นยังอำนวยความสะดวกในการกระจายเป้าหมายบนส่วนพับต่างๆ ในขณะที่แยกข้อมูล
ในกระบวนการนี้ ข้อมูลจะถูกจัดเรียงใหม่ในลักษณะการพับที่แตกต่างกัน เพื่อให้มั่นใจว่าการพับแต่ละครั้งจะเป็นตัวแทนของภาพรวมทั้งหมด ดังนั้น หากคุณกำลังจัดการกับปัญหาการจัดประเภทไบนารีโดยที่แต่ละคลาสประกอบด้วยข้อมูล 50% คุณสามารถใช้การแบ่งชั้นเพื่อจัดเรียงข้อมูลในลักษณะที่แต่ละคลาสมีอินสแตนซ์ครึ่งหนึ่ง
กระบวนการแบ่งชั้นเหมาะที่สุดสำหรับชุดข้อมูลขนาดเล็กและไม่สมดุลที่มีการจำแนกประเภทหลายคลาส
รหัสหลาม:
จาก sklearn.model_selection นำเข้า StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=None)
# X คือชุดคุณลักษณะและ y คือเป้าหมาย
สำหรับ train_index, test_index ใน skf.split(X,y):
พิมพ์ ("รถไฟ:", train_index, "การตรวจสอบ:", val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
อ่าน: Data Frames ใน Python – บทช่วยสอน
เมื่อใดควรใช้กลยุทธ์ Cross-Validation แต่ละกลยุทธ์
ดังที่เราได้กล่าวไว้ก่อนหน้านี้ เทคนิคการตรวจสอบข้ามแต่ละวิธีมีกรณีการใช้งานที่ไม่ซ้ำกัน และด้วยเหตุนี้ เทคนิคเหล่านี้จะทำงานได้ดีที่สุดเมื่อใช้อย่างถูกต้องกับสถานการณ์ที่เหมาะสม ตัวอย่างเช่น หากคุณมีข้อมูลเพียงพอ และคะแนนและพารามิเตอร์ที่เหมาะสมที่สุด (ของแบบจำลอง) สำหรับการแยกส่วนต่างๆ มีแนวโน้มที่จะใกล้เคียงกัน วิธีแยกการฝึก/การทดสอบจะทำงานได้อย่างยอดเยี่ยม
อย่างไรก็ตาม หากคะแนนและพารามิเตอร์ที่เหมาะสมแตกต่างกันสำหรับการแบ่งส่วนต่างๆ เทคนิค K-fold จะดีที่สุด สำหรับอินสแตนซ์ที่คุณมีข้อมูลน้อยเกินไป วิธี LOOCV ทำงานได้ดีที่สุด ในขณะที่สำหรับชุดข้อมูลขนาดเล็กและไม่สมดุล การแบ่งชั้นเป็นวิธีที่จะไป
เราหวังว่าบทความโดยละเอียดนี้จะช่วยให้คุณได้แนวคิดเชิงลึกเกี่ยวกับการตรวจสอบความถูกต้องใน Python
หากคุณอยากเรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูล ลองดูโปรแกรม Executive PG ของ IIIT-B & upGrad ใน Data Science ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 รายการ เวิร์กช็อปภาคปฏิบัติจริง การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม 1 -on-1 พร้อมที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
'การทดสอบการเปลี่ยนแปลง' ใน ML คืออะไร
โดยการสร้างสถิติการทดสอบในชุดข้อมูล จากนั้นสำหรับการเปลี่ยนแปลงแบบสุ่มหลายๆ ครั้งของข้อมูลนั้น การทดสอบการเรียงสับเปลี่ยนใช้เพื่อประเมินนัยสำคัญทางสถิติของแบบจำลอง ค่าสถิติการทดสอบเริ่มต้นควรอยู่ในส่วนท้ายของการกระจายสมมติฐานว่างหากแบบจำลองมีนัยสำคัญ ในการหาค่า p คุณต้องนับจำนวนสถิติการทดสอบที่มีความรุนแรงเท่ากับหรือมากกว่าสถิติการทดสอบเริ่มต้น แล้วหารจำนวนนั้นด้วยจำนวนสถิติการทดสอบทั้งหมดที่เราคำนวณ เนื่องจากสมมติฐานว่างเป็นจริง ค่า P คือโอกาสที่จะได้รับผลลัพธ์อย่างน้อยที่สุดเท่าสถิติการทดสอบ
อะไรคือข้อเสียของการตรวจสอบความถูกต้องในการเรียนรู้ของเครื่อง?
1. การตรวจสอบความถูกต้องช่วยยืดระยะเวลาการฝึกอบรมอย่างมาก ก่อนหน้านี้ คุณสามารถฝึกแบบจำลองของคุณได้ในชุดการฝึกชุดเดียวเท่านั้น ตอนนี้ คุณสามารถฝึกกับชุดการฝึกหลายๆ ชุดได้โดยใช้การตรวจสอบข้าม
2. ในกรณีส่วนใหญ่ โครงสร้างที่คุณกำลังศึกษาพัฒนาตลอดเวลาในการสร้างแบบจำลองการคาดการณ์ ด้วยเหตุนี้ คุณอาจสังเกตเห็นความแตกต่างในชุดการฝึกและการตรวจสอบ
3. การตรวจสอบความถูกต้องข้ามต้องใช้พลังประมวลผลเป็นจำนวนมาก
ฉันจะตรวจจับการใส่มากเกินไปในรุ่น ML ได้อย่างไร
ก่อนที่คุณจะประเมินข้อมูล การตรวจพบการใส่มากเกินไปนั้นแทบจะเป็นไปไม่ได้เลย สามารถช่วยในเรื่องความยากในการสรุปชุดข้อมูล ซึ่งเป็นคุณลักษณะที่แท้จริงของการจัดวางมากเกินไป ด้วยเหตุนี้ ข้อมูลอาจถูกแบ่งออกเป็นชุดย่อยที่แตกต่างกันเพื่อให้การฝึกอบรมและการทดสอบง่ายขึ้น สัดส่วนของความแม่นยำที่เห็นในชุดข้อมูลทั้งสองสามารถใช้เพื่อระบุว่ามีมากเกินไปหรือไม่ หากโมเดลทำงานได้ดีในชุดฝึกซ้อมมากกว่าชุดทดสอบ ก็มีโอกาสสูงที่โมเดลจะใส่มากเกินไป
ข้อเสนอแนะอีกประการหนึ่งคือการเริ่มต้นด้วยโมเดล ML พื้นฐานเพื่อทำหน้าที่เป็นพื้นฐาน ต่อมา เมื่อคุณทดสอบอัลกอริธึมที่ซับซ้อน คุณจะมีเกณฑ์เปรียบเทียบที่จะตัดสินว่าความซับซ้อนที่เพิ่มเข้ามานั้นคุ้มค่าหรือไม่
มาตรการตรวจสอบความถูกต้อง เช่น ความแม่นยำและความสูญเสียยังสามารถใช้เพื่อตรวจจับการใส่มากเกินไป เมื่อแบบจำลองได้รับผลกระทบจากการปรับให้เหมาะสมมากเกินไป โดยทั่วไปแล้ว มาตรการตรวจสอบความถูกต้องจะเติบโตขึ้นจนกว่าจะมีระดับหรือเริ่มลดลง