
التحقق المتقاطع في Python: كل ما تحتاج لمعرفته حول
نشرت: 2020-02-14في علم البيانات ، من المحتمل أن يكون التحقق من الصحة أحد أهم التقنيات التي يستخدمها علماء البيانات للتحقق من صحة استقرار نموذج ML وتقييم مدى نجاحه في التعميم على البيانات الجديدة. يضمن التحقق من الصحة أن نموذج ML يلتقط الأنماط الصحيحة (ذات الصلة) من مجموعة البيانات أثناء إلغاء الضوضاء في مجموعة البيانات بنجاح. بشكل أساسي ، الهدف من تقنيات التحقق من الصحة هو التأكد من أن نماذج ML لها عامل تباين تحيز منخفض.
سنناقش اليوم باستفاضة إحدى تقنيات التحقق من صحة النموذج - التحقق المتقاطع.
جدول المحتويات
ما هو التحقق المتقاطع؟
Cross-Validation (التحقق المتقاطع) هو أسلوب تحقق مصمم لتقييم وتقييم كيفية تعميم نتائج التحليل الإحصائي (نموذج) على مجموعة بيانات مستقلة. يُستخدم التحقق المتقاطع بشكل أساسي في السيناريوهات التي يكون فيها التنبؤ هو الهدف الرئيسي ، ويريد المستخدم تقدير مدى جودة ودقة أداء النموذج التنبئي في مواقف العالم الحقيقي.
يسعى Cross-Validation إلى تحديد مجموعة بيانات عن طريق اختبار النموذج في مرحلة التدريب للمساعدة في تقليل المشكلات مثل التجهيز الزائد والتركيب غير المناسب. ومع ذلك ، يجب أن تتذكر أنه يجب استخراج كل من التحقق من الصحة ومجموعة التدريب من نفس التوزيع ، وإلا فسيؤدي ذلك إلى مشاكل في مرحلة التحقق من الصحة.
تعلم دورة شهادة علوم البيانات من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
فوائد المصادقة المتقاطعة
- يساعد في تقييم جودة النموذج الخاص بك.
- يساعد على تقليل / تجنب مشاكل فرط التجهيز.
- يتيح لك تحديد النموذج الذي سيقدم أفضل أداء على البيانات غير المرئية.
قراءة: مشاريع Python للمبتدئين
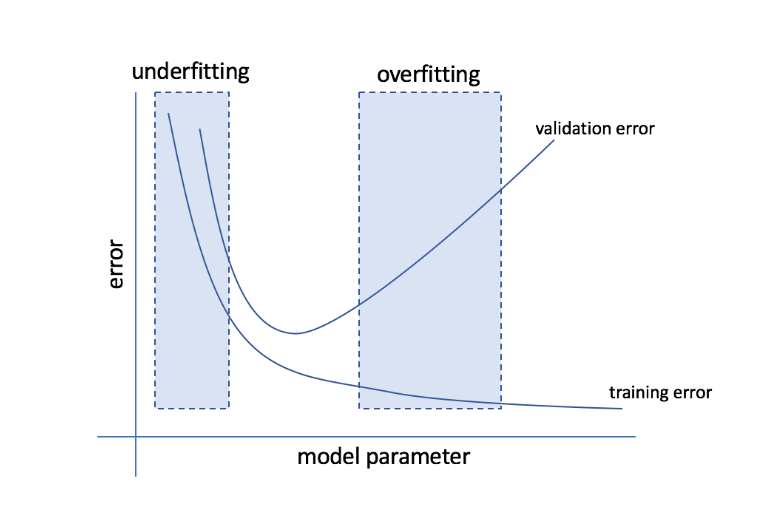
ما هي الانقطاع والتركيب؟
يشير overfitting إلى الحالة التي يصبح فيها النموذج حساسًا للغاية للبيانات وينتهي بالتقاط الكثير من الضوضاء والأنماط العشوائية التي لا تعمم جيدًا على البيانات غير المرئية. في حين أن مثل هذا النموذج عادةً ما يؤدي أداءً جيدًا في مجموعة التدريب ، إلا أن أدائه يعاني في مجموعة الاختبار.
يشير التضمين غير الملائم إلى المشكلة عندما يفشل النموذج في التقاط أنماط كافية في مجموعة البيانات ، وبالتالي تقديم أداء ضعيف لكل من التدريب ومجموعة الاختبار.
من خلال هذين الطرفين ، فإن النموذج المثالي هو الذي يؤدي أداءً جيدًا على قدم المساواة لكل من مجموعات التدريب والاختبار.
مصدر
عبر التحقق من الصحة: استراتيجيات التحقق المختلفة
يتم تصنيف استراتيجيات التحقق استنادًا إلى عدد الانقسامات التي تم إجراؤها في مجموعة البيانات. الآن ، دعنا نلقي نظرة على استراتيجيات التحقق المتقاطع المختلفة في Python.
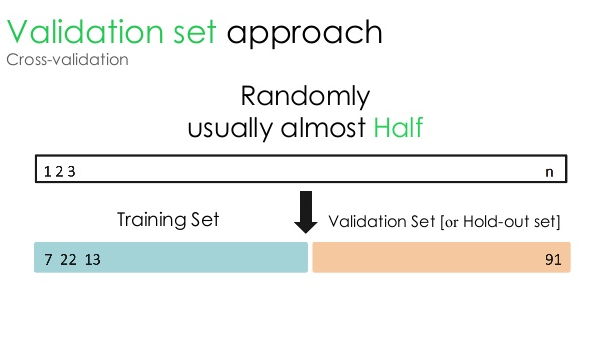
1. مجموعة التحقق من الصحة
يقسم نهج التحقق هذا مجموعة البيانات إلى جزأين متساويين - بينما يتم حجز 50٪ من مجموعة البيانات للتحقق من الصحة ، أما الـ 50٪ المتبقية فهي محجوزة لتدريب النموذج. نظرًا لأن هذا النهج يقوم بتدريب النموذج استنادًا إلى 50٪ فقط من مجموعة بيانات معينة ، فلا يزال هناك دائمًا احتمال فقدان معلومات ذات صلة وذات مغزى مخبأة في الـ 50٪ الأخرى من البيانات. نتيجة لذلك ، فإن هذا النهج بشكل عام يخلق تحيزًا أعلى في النموذج.
مصدر
كود بايثون:
القطار ، التحقق من الصحة = train_test_split (البيانات ، test_size = 0.50 ، الحالة العشوائية = 5)
2. تدريب / اختبار الانقسام
في نهج التحقق هذا ، يتم تقسيم مجموعة البيانات إلى جزأين - مجموعة التدريب ومجموعة الاختبار. يتم ذلك لتجنب أي تداخل بين مجموعة التدريب ومجموعة الاختبار (إذا تداخلت مجموعات التدريب والاختبار ، فسيكون النموذج معيبًا). وبالتالي ، من الأهمية بمكان التأكد من أن مجموعة البيانات المستخدمة للنموذج يجب ألا تحتوي على أي عينات مكررة في مجموعة البيانات الخاصة بنا. تتيح لك إستراتيجية تقسيم التدريب / الاختبار إعادة تدريب النموذج الخاص بك بناءً على مجموعة البيانات بأكملها دون تغيير أي معلمات تشعبية للنموذج.

مصدر
ومع ذلك ، فإن هذا النهج له قيد واحد مهم - يعتمد أداء النموذج ودقته إلى حد كبير على كيفية تقسيمه. على سبيل المثال ، إذا لم يكن التقسيم عشوائيًا ، أو إذا كانت مجموعة فرعية واحدة من مجموعة البيانات تحتوي فقط على جزء من المعلومات الكاملة ، فسيؤدي ذلك إلى زيادة التجهيز. باستخدام هذا الأسلوب ، لا يمكنك التأكد من نقاط البيانات التي ستكون في أي مجموعة تحقق من الصحة ، وبالتالي إنشاء نتائج مختلفة لمجموعات مختلفة. ومن ثم ، يجب استخدام استراتيجية تقسيم التدريب / الاختبار فقط عندما يكون لديك بيانات كافية في متناول اليد.
كود بايثون:
>>> من sklearn.model_selection استيراد train_test_split
>>> X، y = np.arange (10) .reshape ((5، 2))، range (5)
>>> X
مجموعة ([0 ، 1] ،
[2 ، 3] ،
[4 ، 5] ،
[6 ، 7] ،
[8 ، 9]])
>>> قائمة (ص)
[0 ، 1 ، 2 ، 3 ، 4]
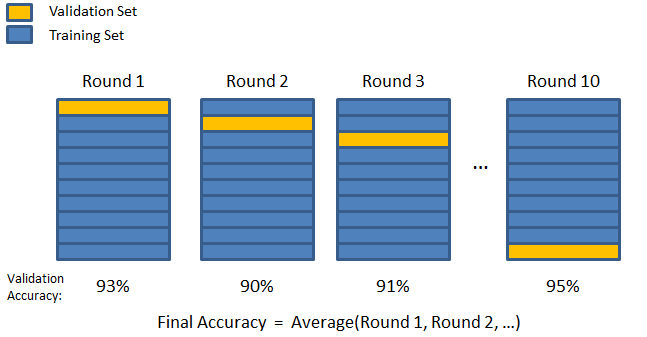
3. K- أضعاف
كما رأينا في الاستراتيجيتين السابقتين ، هناك احتمال ضياع معلومات مهمة في مجموعة البيانات ، مما يزيد من احتمال الخطأ الناجم عن التحيز أو التجهيز الزائد. هذا يستدعي طريقة تحتفظ ببيانات وفيرة لتدريب النموذج مع ترك بيانات كافية للتحقق من صحتها.
أدخل تقنية التحقق من صحة K-fold. في هذه الإستراتيجية ، يتم تقسيم مجموعة البيانات إلى عدد "k" من المجموعات الفرعية أو الطيات ، حيث يتم حجز مجموعات فرعية k-1 لتدريب النموذج ، ويتم استخدام المجموعة الفرعية الأخيرة للتحقق من الصحة (مجموعة الاختبار). يتم حساب متوسط النموذج مقابل الطيات الفردية ثم يتم الانتهاء منه. بمجرد الانتهاء من النموذج ، يمكنك اختباره باستخدام مجموعة الاختبار.
مصدر
هنا ، تظهر كل نقطة بيانات في مجموعة التحقق مرة واحدة تمامًا أثناء البقاء في مجموعة التدريب k-1 عدد المرات. نظرًا لاستخدام معظم البيانات للتركيب ، تقل مشكلة عدم الملاءمة بشكل كبير. وبالمثل ، يتم التخلص من مشكلة فرط التخصيص نظرًا لاستخدام غالبية البيانات أيضًا في مجموعة التحقق من الصحة.

قراءة: Python vs Ruby: إكمال المقارنة جنبًا إلى جنب
تعتبر استراتيجية K-fold هي الأفضل للحالات التي يكون لديك فيها كمية محدودة من البيانات ، وهناك فرق كبير في جودة الطيات أو المعلمات المثلى المختلفة فيما بينها.
كود بايثون:
من sklearn.model_selection استيراد KFold # import KFold
X = np.array ([[1، 2]، [3، 4]، [1، 2]، [3، 4]]) # إنشاء مصفوفة
y = np.array ([1، 2، 3، 4]) # أنشئ مصفوفة أخرى
kf = KFold (n_splits = 2) # حدد الانقسام - إلى طيات 2
إرجاع kf.get_n_splits (X) # عدد تكرارات التقسيم في أداة التحقق المشتركة
طباعة (kf)
KFold (n_splits = 2 ، random_state = بلا ، خلط عشوائي = خطأ)
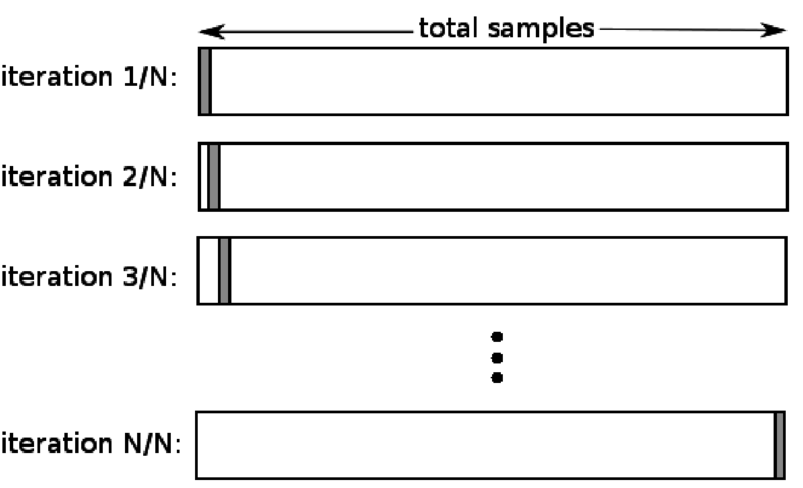
4. اترك واحد خارج
يعد التحقق المتبادل من ترك واحد (LOOCV) حالة خاصة من K-fold عندما يساوي k عدد العينات في مجموعة بيانات معينة. هنا ، يتم حجز نقطة بيانات واحدة فقط لمجموعة الاختبار ، وبقية مجموعة البيانات هي مجموعة التدريب. لذلك ، إذا كنت تستخدم الكائن "k-1" كعينات تدريب وكائن "1" كمجموعة اختبار ، فسوف يستمرون في التكرار خلال كل عينة في مجموعة البيانات. إنها الطريقة الأكثر فائدة عندما يكون هناك القليل من البيانات المتاحة.
مصدر
نظرًا لأن هذا النهج يستخدم جميع نقاط البيانات ، فعادة ما يكون التحيز منخفضًا. ومع ذلك ، نظرًا لتكرار عملية التحقق من الصحة عدد المرات (n = عدد نقاط البيانات) ، فإنها تؤدي إلى وقت تنفيذ أكبر. هناك قيد ملحوظ آخر للطرق وهو أنه قد يؤدي إلى تباين أعلى في اختبار فعالية النموذج أثناء اختبار النموذج مقابل نقطة بيانات واحدة. لذلك ، إذا كانت نقطة البيانات هذه شاذة ، فسيؤدي ذلك إلى إنشاء حاصل تباين أعلى.
كود بايثون:
>>> استيراد numpy كـ np
>>> من sklearn.model_selection استيراد LeaveOneOut
>>> X = np.array ([[1، 2]، [3، 4]])
>>> y = np.array ([1، 2])
>>> loo = LeaveOneOut ()
>>> loo.get_n_splits (X)
2
>>> طباعة (مرحاض)
مغادرة OneOut ()
>>> من أجل train_index ، test_index في loo.split (X):
... طباعة ("TRAIN:" ، train_index ، "TEST:" ، test_index)
… X_train، X_test = X [train_index]، X [test_index]
… y_train ، y_test = y [train_index] ، y [test_index]
... طباعة (X_train ، X_test ، y_train ، y_test)
القطار: [1] الاختبار: [0]
[[3 4]] [[1 2]] [2] [1]
القطار: [0] الاختبار: [1]
[[1 2]] [[3 4]] [1] [2]
5. التقسيم الطبقي
عادةً ، بالنسبة لتقسيم القطار / الاختبار و K-fold ، يتم خلط البيانات لإنشاء تدريب عشوائي وتقسيم التحقق من الصحة. وبالتالي ، فإنه يسمح بتوزيع هدف مختلف في طيات مختلفة. وبالمثل ، فإن التقسيم الطبقي يسهل أيضًا التوزيع المستهدف على طيات مختلفة أثناء تقسيم البيانات.
في هذه العملية ، يتم إعادة ترتيب البيانات في طيات مختلفة بطريقة تضمن أن تصبح كل طية ممثلة للكل. لذلك ، إذا كنت تتعامل مع مشكلة تصنيف ثنائي حيث يتكون كل فئة من 50٪ من البيانات ، فيمكنك استخدام التقسيم الطبقي لترتيب البيانات بطريقة تتضمن كل فئة نصف الحالات.
تعتبر عملية التقسيم الطبقي هي الأنسب لمجموعات البيانات الصغيرة وغير المتوازنة ذات التصنيف متعدد الفئات.
كود بايثون:
من sklearn.model_selection استيراد StratifiedKFold
skf = StratifiedKFold (n_splits = 5 ، random_state = لا شيء)
# X هي مجموعة الميزات و y هو الهدف
بالنسبة لـ train_index ، test_index في skf.split (X ، y):
طباعة ("Train:" ، train_index ، "Validation:" ، val_index)
X_train ، X_test = X [train_index] ، X [val_index]
y_train، y_test = y [train_index]، y [val_index]
قراءة: إطارات البيانات في بايثون - البرنامج التعليمي
متى يتم استخدام كل من استراتيجيات التحقق الشامل الخمس هذه؟
كما ذكرنا سابقًا ، لكل تقنية من تقنيات التحقق المتقاطع حالات استخدام فريدة ، وبالتالي فهي تحقق أفضل أداء عند تطبيقها بشكل صحيح على السيناريوهات الصحيحة. على سبيل المثال ، إذا كان لديك بيانات كافية ، ومن المحتمل أن تكون الدرجات والمعلمات المثلى (للنموذج) للتقسيمات المختلفة متشابهة ، فسيعمل نهج تقسيم التدريب / الاختبار بشكل ممتاز.
ومع ذلك ، إذا اختلفت الدرجات والمعلمات المثلى باختلاف الانقسامات ، فستكون تقنية K-fold هي الأفضل. في الحالات التي يكون لديك فيها القليل جدًا من البيانات ، يعمل نهج LOOCV بشكل أفضل ، بينما بالنسبة لمجموعات البيانات الصغيرة وغير المتوازنة ، فإن التقسيم الطبقي هو السبيل للذهاب.
نأمل أن تساعدك هذه المقالة التفصيلية في الحصول على فكرة متعمقة عن التحقق المتقاطع في Python.
إذا كنت مهتمًا بالتعرف على علوم البيانات ، فراجع برنامج IIIT-B & upGrad التنفيذي PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع خبراء الصناعة ، 1 - في 1 مع موجهين في الصناعة ، أكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
ما هو "اختبار التقليب" في ML؟
من خلال إنشاء إحصاء اختبار على مجموعة البيانات ثم للعديد من التباديل العشوائي لتلك البيانات ، يتم استخدام اختبار التقليب لتقييم الأهمية الإحصائية للنموذج. يجب أن تندرج القيمة الإحصائية الأولية للاختبار في أحد ذيول توزيع الفرضية الصفرية إذا كان النموذج مهمًا. للعثور على القيمة p ، تحتاج فقط إلى حساب عدد إحصائيات الاختبار التي تكون شديدة أو أكثر تطرفًا من إحصائيات الاختبار الأولية ثم قسمة هذا الرقم على العدد الإجمالي لإحصاءات الاختبار التي قمنا بحسابها. بالنظر إلى أن الفرضية الصفرية صحيحة ، فإن القيمة P هي فرصة الحصول على نتيجة لا تقل خطورة عن إحصائية الاختبار.
ما عيوب التحقق المتبادل في التعلم الآلي؟
1. عبر التحقق من الصحة يطيل بشكل ملحوظ فترة التدريب. في السابق ، كان بإمكانك تدريب النموذج الخاص بك على مجموعة تدريب واحدة فقط ؛ الآن ، يمكنك تدريبه على عدة مجموعات تدريب باستخدام التحقق المتقاطع.
2- في معظم الحالات ، يتطور الهيكل الذي تدرسه بمرور الوقت في النمذجة التنبؤية. نتيجة لذلك ، قد تلاحظ اختلافات في مجموعات التدريب والتحقق من الصحة.
3. يتطلب التحقق المتقاطع الكثير من قوة الحوسبة.
كيف يمكنني اكتشاف التجاوز في نماذج ML؟
قبل تقييم البيانات ، من المستحيل تقريبًا اكتشاف فرط التجهيز. يمكن أن يساعد في صعوبة تعميم مجموعات البيانات ، وهي ميزة جوهرية للتخصيص الزائد. نتيجة لذلك ، يمكن تقسيم البيانات إلى مجموعات فرعية متميزة لتسهيل التدريب والاختبار. يمكن استخدام نسبة الدقة التي تظهر في كلتا مجموعتي البيانات لتحديد ما إذا كان التجاوز موجودًا أم لا. إذا كان أداء النموذج في مجموعة التدريب أفضل مما كان عليه في مجموعة الاختبار ، فهناك احتمالية أن يكون أكثر من اللازم.
اقتراح آخر هو البدء بنموذج ML أساسي للغاية ليكون بمثابة خط أساس. في وقت لاحق ، عندما تختبر الخوارزميات المعقدة ، سيكون لديك معيار يمكن على أساسه الحكم على ما إذا كان التعقيد الإضافي مفيدًا أم لا.
يمكن أيضًا استخدام إجراءات التحقق مثل الدقة والفقد لاكتشاف التجهيز الزائد. عندما يتأثر النموذج بالتركيب الزائد ، تنمو إجراءات التحقق بشكل عام حتى تصل إلى مرحلة الاستقرار أو تبدأ في الانخفاض.