
Python'da Çapraz Doğrulama: Bilmeniz Gereken Her Şey
Yayınlanan: 2020-02-14Veri Biliminde doğrulama, muhtemelen Veri Bilimcileri tarafından ML modelinin kararlılığını doğrulamak ve bunun yeni verilere ne kadar iyi genelleştirileceğini değerlendirmek için kullanılan en önemli tekniklerden biridir. Doğrulama, veri kümesindeki gürültüyü başarıyla iptal ederken ML modelinin veri kümesinden doğru (ilgili) kalıpları almasını sağlar. Esasen doğrulama tekniklerinin amacı, ML modellerinin düşük bir sapma varyans faktörüne sahip olduğundan emin olmaktır.
Bugün böyle bir model doğrulama tekniğinden - Çapraz Doğrulama - üzerinde uzun uzun tartışacağız.
İçindekiler
Çapraz Doğrulama nedir?
Çapraz Doğrulama, istatistiksel analiz (model) sonuçlarının bağımsız bir veri kümesine nasıl genelleştirileceğini değerlendirmek ve değerlendirmek için tasarlanmış bir doğrulama tekniğidir. Çapraz Doğrulama öncelikle tahminin ana amaç olduğu senaryolarda kullanılır ve kullanıcı bir tahmine dayalı modelin gerçek dünya durumlarında ne kadar iyi ve doğru performans göstereceğini tahmin etmek ister.
Çapraz Doğrulama, fazla uyum ve eksik uyum gibi sorunları en aza indirmeye yardımcı olmak için modeli eğitim aşamasında test ederek bir veri kümesi tanımlamayı amaçlar. Ancak, hem doğrulamanın hem de eğitim setinin aynı dağıtımdan çıkarılması gerektiğini, aksi takdirde doğrulama aşamasında sorunlara yol açacağını unutmamalısınız.
Dünyanın en iyi Üniversitelerinden veri bilimi sertifika kursunu öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.
Çapraz Doğrulamanın Faydaları
- Modelinizin kalitesini değerlendirmenize yardımcı olur.
- Fazla takma ve eksik takma sorunlarını azaltmaya/önlemeye yardımcı olur.
- Görünmeyen veriler üzerinde en iyi performansı sağlayacak modeli seçmenize olanak tanır.
Okuyun: Yeni Başlayanlar için Python Projeleri
Fazla takma ve eksik takma nedir?
Fazla uydurma, bir modelin verilere çok duyarlı hale geldiği ve görünmeyen verilere iyi genellemeyen çok sayıda gürültü ve rastgele kalıplar yakaladığı durumu ifade eder. Böyle bir model genellikle eğitim setinde iyi performans gösterirken, performansı test setinde düşer.
Eksik uyum, modelin veri kümesinde yeterli örüntüyü yakalayamadığı ve bu nedenle hem eğitim hem de test kümesi için düşük bir performans sergilediği sorunu ifade eder.
Bu iki uç noktadan hareketle, mükemmel model hem eğitim hem de test setleri için eşit derecede iyi performans gösteren modeldir.
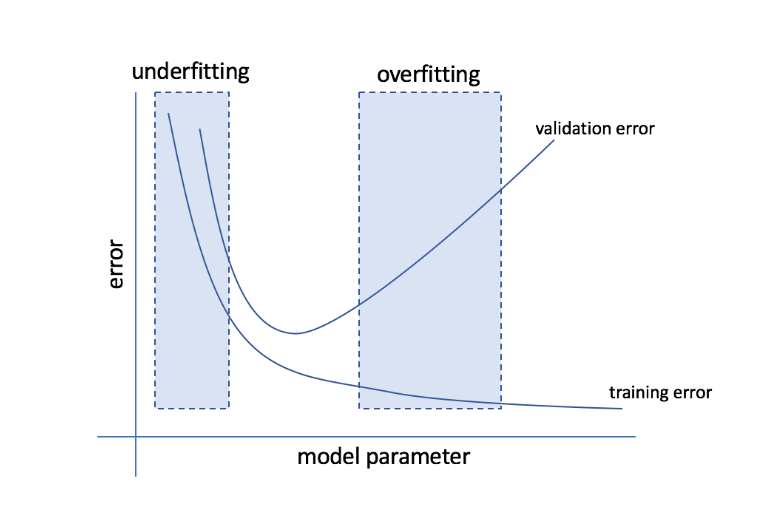
Kaynak
Çapraz Doğrulama: Farklı Doğrulama Stratejileri
Doğrulama stratejileri, bir veri kümesinde yapılan bölmelerin sayısına göre kategorilere ayrılır. Şimdi Python'daki farklı Çapraz Doğrulama stratejilerine bakalım.
1. Doğrulama seti
Bu doğrulama yaklaşımı, veri kümesini iki eşit parçaya böler - veri kümesinin %50'si doğrulama için, kalan %50'si ise model eğitimi için ayrılır. Bu yaklaşım, modeli belirli bir veri kümesinin yalnızca %50'sine dayalı olarak eğittiğinden, verilerin diğer %50'sinde saklı olan ilgili ve anlamlı bilgileri kaçırma olasılığı her zaman vardır. Sonuç olarak, bu yaklaşım genellikle modelde daha yüksek bir yanlılık yaratır.
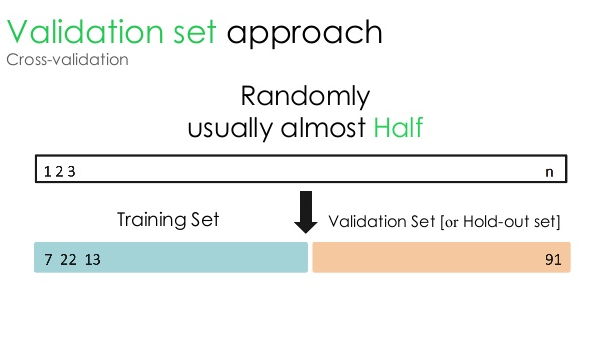
Kaynak
Python kodu:
tren, doğrulama = train_test_split(veri, test_size=0.50, random_state = 5)
2. Eğitim/Test ayrımı
Bu doğrulama yaklaşımında, veri seti eğitim seti ve test seti olmak üzere iki kısma ayrılır. Bu, eğitim seti ile test seti arasında herhangi bir örtüşmeyi önlemek için yapılır (eğitim ve test setleri çakışırsa, model hatalı olacaktır). Bu nedenle, model için kullanılan veri kümesinin veri kümemizde yinelenen örnekler içermemesini sağlamak çok önemlidir. Eğitme/test ayırma stratejisi, modelin herhangi bir hiperparametresini değiştirmeden tüm veri kümesine dayalı olarak modelinizi yeniden eğitmenize olanak tanır.

Kaynak
Bununla birlikte, bu yaklaşımın önemli bir sınırlaması vardır - modelin performansı ve doğruluğu büyük ölçüde nasıl bölündüğüne bağlıdır. Örneğin, bölme rastgele değilse veya veri kümesinin bir alt kümesi tüm bilgilerin yalnızca bir kısmına sahipse, fazla uydurmaya yol açacaktır. Bu yaklaşımla, hangi veri noktalarının hangi doğrulama setinde olacağından emin olamazsınız, dolayısıyla farklı setler için farklı sonuçlar yaratabilirsiniz. Bu nedenle, eğitim/test ayırma stratejisi yalnızca elinizde yeterli veri olduğunda kullanılmalıdır.
Python kodu:
>>> sklearn.model_selection'dan train_test_split'i içe aktarın
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
dizi([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> liste(y)
[0, 1, 2, 3, 4]
3. K katlama
Önceki iki stratejide görüldüğü gibi, veri kümesindeki önemli bilgileri kaçırma olasılığı vardır, bu da önyargı kaynaklı hata veya fazla uydurma olasılığını artırır. Bu, model eğitimi için bol miktarda veri saklarken aynı zamanda doğrulama için yeterli veri bırakan bir yöntem gerektirir.
K-kat doğrulama tekniğini girin. Bu stratejide, veri kümesi 'k' sayıda alt kümeye veya kıvrıma bölünür, burada k-1 alt kümeleri model eğitimi için ayrılır ve son alt küme doğrulama (test kümesi) için kullanılır. Model, tek tek kıvrımlara göre ortalaması alınır ve ardından sonlandırılır. Model tamamlandıktan sonra test setini kullanarak test edebilirsiniz.
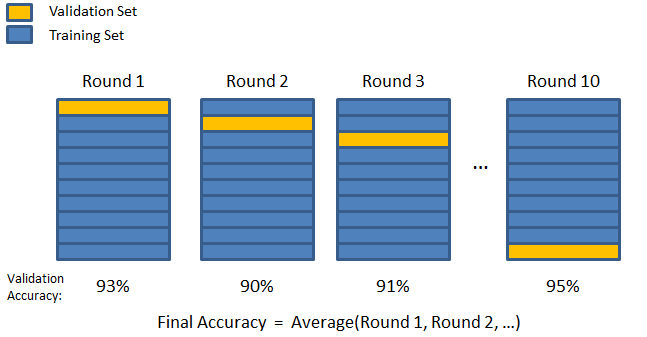
Kaynak
Burada her bir veri noktası doğrulama setinde tam olarak bir kez görünürken eğitim setinde k-1 sayısı kadar kalır. Verilerin çoğu takma için kullanıldığından, eksik takma sorunu önemli ölçüde azalır. Benzer şekilde, verilerin çoğu doğrulama setinde de kullanıldığı için fazla uydurma sorunu ortadan kalkar.

Okuyun: Python vs Ruby: Komple Yan yana karşılaştırma
K-katlama stratejisi, sınırlı miktarda veriye sahip olduğunuz ve katlamaların kalitesinde veya aralarındaki farklı optimal parametrelerde önemli bir farkın olduğu durumlar için en iyisidir.
Python kodu:
sklearn.model_selection'dan KFold'u içe aktar # KFold'u içe aktar
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # bir dizi oluştur
y = np.array([1, 2, 3, 4]) # Başka bir dizi oluştur
kf = KFold(n_splits=2) # Bölmeyi tanımlayın – 2 kata
kf.get_n_splits(X) # çapraz doğrulayıcıdaki bölme yinelemelerinin sayısını döndürür
yazdır(kf)
KFold(n_splits=2, random_state=Yok, shuffle=Yanlış)
4. Birini dışarıda bırakın
Birini dışarıda bırakma çapraz doğrulama (LOOCV), k belirli bir veri kümesindeki örnek sayısına eşit olduğunda K-katlamanın özel bir durumudur. Burada, test kümesi için yalnızca bir veri noktası ayrılmıştır ve veri kümesinin geri kalanı eğitim kümesidir. Bu nedenle, eğitim örnekleri olarak “k-1” nesnesini ve test seti olarak “1” nesnesini kullanırsanız, veri kümesindeki her örnekte yinelemeye devam edeceklerdir. Çok az veri olduğunda en kullanışlı yöntemdir.
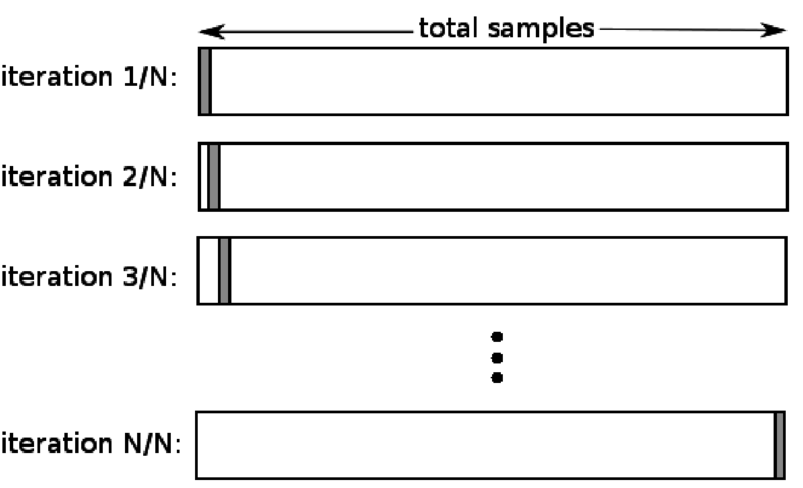
Kaynak
Bu yaklaşım tüm veri noktalarını kullandığından, sapma genellikle düşüktür. Ancak, doğrulama işlemi 'n' sayıda (n=veri noktası sayısı) tekrarlandığından, daha uzun yürütme süresine yol açar. Yöntemlerin bir diğer dikkate değer kısıtlaması, siz modeli bir veri noktasına karşı test ederken, model etkinliğini test etmede daha yüksek bir varyasyona yol açabilmesidir. Dolayısıyla, bu veri noktası bir aykırı değer ise, daha yüksek bir varyasyon bölümü oluşturacaktır.
Python kodu:
>>> numpy'yi np olarak içe aktar
>>> sklearn.model_selection'dan LeaveOneOut'u içe aktarın
>>> X = np.dizi([[1, 2], [3, 4]])
>>> y = np.dizi([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> yazdır(lo)
AyrılBiriÇıkış()
>>> train_index için, loo.split(X) içindeki test_index:
… print(“TREN:”, train_index, “TEST:”, test_index)
… X_tren, X_test = X[tren_index], X[test_index]
… y_train, y_test = y[train_index], y[test_index]
… yazdır(X_tren, X_test, y_tren, y_test)
TREN: [1] TEST: [0]
[[3 4]] [[1 2]] [2] [1]
TREN: [0] TEST: [1]
[[1 2]] [[3 4]] [1] [2]
5. Tabakalaşma
Tipik olarak, tren/test ayrımı ve K-katlama için veriler, rastgele bir eğitim ve doğrulama ayrımı oluşturmak üzere karıştırılır. Böylece farklı kıvrımlarda farklı hedef dağılımına izin verir. Benzer şekilde, katmanlaştırma, verileri bölerken farklı kıvrımlar üzerinde hedef dağılımını da kolaylaştırır.
Bu süreçte veriler, her katın bütünün temsilcisi olmasını sağlayacak şekilde farklı kıvrımlarda yeniden düzenlenir. Bu nedenle, her sınıfın verilerin %50'sinden oluştuğu bir ikili sınıflandırma sorunuyla uğraşıyorsanız, verileri her sınıf örneklerin yarısını içerecek şekilde düzenlemek için katmanlaştırmayı kullanabilirsiniz.
Tabakalandırma süreci, çok sınıflı sınıflandırmaya sahip küçük ve dengesiz veri kümeleri için en uygunudur.
Python kodu:
sklearn.model_selection'dan StratifiedKFold'u içe aktarın
skf = KatmanlıKFold(n_splits=5, random_state=Yok)
# X özellik kümesidir ve y hedeftir
train_index için, skf.split(X,y) içindeki test_index:
print(“Tren:”, train_index, “Doğrulama:”, val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[tren_index], y[val_index]
Okuyun: Python'da Veri Çerçeveleri – Öğretici
Bu beş Çapraz Doğrulama stratejisinin her biri ne zaman kullanılmalı?
Daha önce de belirttiğimiz gibi, her Çapraz Doğrulama tekniğinin benzersiz kullanım durumları vardır ve bu nedenle, doğru senaryolara doğru şekilde uygulandığında en iyi performansı gösterirler. Örneğin, yeterli veriye sahipseniz ve farklı bölmeler için (modelin) puanları ve optimal parametreleri muhtemelen benzerse, tren/test ayırma yaklaşımı mükemmel bir şekilde çalışacaktır.
Bununla birlikte, farklı bölmeler için puanlar ve optimal parametreler değişiyorsa, K-katlama tekniği en iyisi olacaktır. Çok az veriye sahip olduğunuz durumlarda, LOOCV yaklaşımı en iyi sonucu verir, oysa küçük ve dengesiz veri kümeleri için gidilecek yol katmanlaştırmadır.
Bu ayrıntılı makalenin Python'da Çapraz Doğrulama hakkında derinlemesine bir fikir edinmenize yardımcı olduğunu umuyoruz.
Veri bilimi hakkında bilgi edinmek istiyorsanız, IIIT-B & upGrad'ın çalışan profesyoneller için oluşturulmuş ve 10'dan fazla vaka çalışması ve proje, uygulamalı uygulamalı atölye çalışmaları, endüstri uzmanlarıyla mentorluk, 1 Endüstri danışmanlarıyla bire bir, en iyi firmalarla 400+ saat öğrenim ve iş yardımı.
ML'deki 'permütasyon testi' nedir?
Veri kümesi üzerinde bir test istatistiği oluşturularak ve daha sonra bu verilerin birçok rastgele permütasyonu için, bir modelin istatistiksel önemini değerlendirmek için bir permütasyon testi kullanılır. Model anlamlıysa, ilk test istatistik değeri boş hipotez dağılımının kuyruklarından birine düşmelidir. p-değerini bulmak için, sadece ilk test istatistikleri kadar ciddi veya daha aşırı olan test istatistiklerinin sayısını saymanız ve ardından bu sayıyı hesapladığımız toplam test istatistiği sayısına bölmeniz gerekir. Boş hipotezin doğru olduğu göz önüne alındığında, P-değeri, en az test istatistiği kadar şiddetli bir sonuç alma şansıdır.
Makine öğreniminde çapraz doğrulamanın dezavantajları nelerdir?
1. Çapraz Doğrulama, eğitim süresini önemli ölçüde uzatır. Önceden, modelinizi yalnızca bir eğitim setinde eğitebiliyordunuz; şimdi, Çapraz Doğrulama'yı kullanarak onu birkaç eğitim setinde eğitebilirsiniz.
2. Çoğu durumda, üzerinde çalıştığınız yapı, tahmine dayalı modellemede zamanla gelişir. Sonuç olarak, eğitim ve doğrulama setlerinde farklılıklar görebilirsiniz.
3. Çapraz Doğrulama çok fazla bilgi işlem gücü gerektirir.
ML modellerinde fazla uyumu nasıl tespit edebilirim?
Verileri değerlendirmeden önce, fazla uydurmayı tespit etmek neredeyse imkansızdır. Fazla uydurmanın içsel bir özelliği olan veri kümelerini genelleştirmenin zorluğuna yardımcı olabilir. Sonuç olarak, eğitim ve testi kolaylaştırmak için veriler farklı alt kümelere bölünebilir. Her iki veri setinde görülen doğruluk oranı, fazla uydurma olup olmadığını belirlemek için kullanılabilir. Model, eğitim setinde test setinden daha iyi performans gösteriyorsa, fazla uydurma olasılığı vardır.
Başka bir öneri, temel olarak hareket etmek için çok temel bir ML modeliyle başlamaktır. Daha sonra, karmaşık algoritmaları test ettiğinizde, eklenen karmaşıklığın buna değip değmediğini değerlendirmek için bir karşılaştırma ölçütüne sahip olacaksınız.
Doğruluk ve kayıp gibi doğrulama ölçütleri de fazla uydurmayı tespit etmek için kullanılabilir. Model, fazla uydurmadan etkilendiğinde, doğrulama önlemleri genellikle sabitlenene veya düşmeye başlayana kadar büyür.