
人工智能的主動學習[綜合指南]
已發表: 2020-12-01人工智能主動學習概述
在本文中,我們將介紹主動學習的基礎知識及其在人工智能領域的相關性。
目錄
介紹
在機器學習中,存在兩種類型的學習方法——監督學習和無監督學習。 在監督學習中,我們為模型提供每個訓練樣本的標籤。 該模型學習訓練數據樣本的特徵並將它們映射到相應的標籤。
輸出是測試樣本屬於特定類別的概率。 然而,無監督學習不需要標籤,模型根據它在訓練過程中學到的一些模式或趨勢對測試樣本進行分類。
現在在監督學習中,需要圖像(假設為輸入)及其註釋。 該模型可以通過優化到足以適應圖像及其註釋來從圖像中學習。
但是,實際上要使模型在測試樣本上表現得非常好,需要大量的圖像及其註釋。 為了解決這個問題,許多研究人員採用了主動學習。

動機
在許多情況下,通常會有數以百萬計的數據可用,但對所有數據進行註釋是不可行且耗時的。 幾個例子包括:
- 無人機在飛行過程中錄製的視頻
- 包含數百萬個細胞的醫學圖像
- 來自交通燈信號的閉路電視錄像
為了處理如此大量的數據,採用了主動學習,它告訴我們所有可用的註釋數據,註釋哪些樣本是有意義的。
基本流程
ML 工程師/Oracle 專家可以訪問大量未標記的數據。 比如說,任務是建立一個貓狗分類器。 現在,在整個數據池中,工程師選擇僅使用 20% 的數據(首先標記它們)訓練模型,並將其餘 80% 用於測試目的。
這是一種基於回合的方法。 在每次迭代中,都會將測試圖像提供給模型進行分類。 如果模型表現不佳,或者模型分配的概率較小,例如 0.6,則需要在此樣本上訓練模型以提高整體性能。 模型不確定或不自信的圖像包含更多信息供模型學習。
然後將該樣本標記並選擇為訓練樣本。 重複此迭代,直到最後一個測試樣本。 通過這種方式,我們組裝了一個值得註釋的新訓練集。 該模型在新收集的選擇性訓練數據上進行訓練,從而減少了整體訓練時間。 重複此操作,直到註釋集結束。
如何選擇圖像進行標註?
上述方法只是選擇註釋樣本的一種簡單方法。 在實際實踐中,使用了以下兩種方法,有時將兩者結合使用。
- 基於不確定性的採樣:模型不確定的圖像,或者模型已分配低概率的圖像。
- 基於多樣性的採樣:表示多樣性的圖像,即空間表示、光譜表示、類表示等方面的變化。 更多的多樣性,更多的可用信息供模型學習。
將數據樣本(圖像)作為輸入並返回優先級/排名分數的函數稱為採集函數。
閱讀:人工智能的挑戰
常用採集函數
1. 最佳與次佳 (BvSB)
這種方法主要用於少數類(3到5)。 使用的公式考慮了最高和次高類別的概率值。 y1 和 y2 表示模型 p? 預測的最高和第二高概率值? 對於給定的樣本 x。

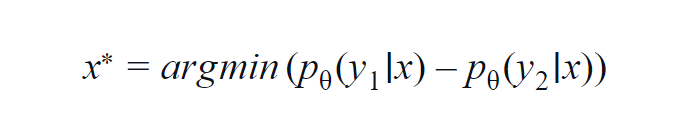
基本思想是最小化下面的方程。 差異越小,數據樣本 x 中包含的信息就越多。
為了簡單理解,假設數據樣本中涉及的類是狗、貓、馬和獅子。 考慮第一個場景,模型的輸入是狗圖像,狗類(最可能)的輸出概率為 0.6,貓類(第二最可能)的輸出概率為 0.35。
剩餘 0.5 分佈在其他兩個類之間。 在第二種情況下,對於相同的輸入,前兩個類別的輸出概率為 0.7 和 0.2。 現在從這兩個場景中,我們可以推斷出,在第二個場景中,模型對其預測更加確定(0.7-0.2=0.5)。
在第一種情況下,模型對預測的不確定性更大(0.6-0.35=0.25)。 從而最小化上述方程,我們可以收集到一個值得標註的數據樣本。
2.熵
BvSB 適用於較少的課程。 然而,對於大量的類,熵被用作獲取函數。 原因是,下面的公式考慮了其餘類中的信息。 熵是雜質或不平衡的量度。 在機器學習方面,它可以定義為模型不確定性的度量。 熵的高值表示類關聯中的高度不確定性。
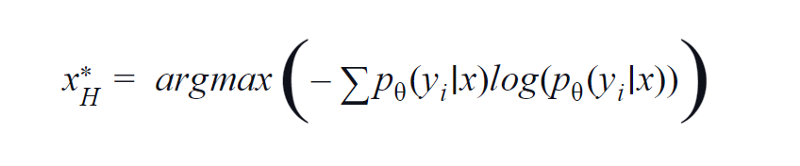
熵方程,作者圖片
因此,最大化上述方程將為我們生成一個模型高度不確定或對分類任務最不自信的圖像樣本。
3. 委員會QBC查詢
就像隨機森林利用集成學習一樣——利用多個決策樹。 類似地,關於數據樣本 x 的不確定性是通過一組不同模型(具有不同的超參數或種子)來測量的。
有了這個,如果對於給定的圖像,不同模型的輸出變化很大,這意味著模型在分類這個圖像時不舒服。 通常,來自每個模型的最可能得分堆疊在一個向量中。 計算該向量的熵。 同樣,如果熵很高,則進一步標記和註釋圖像。
領先一步
到目前為止,我們使用的數據樣本模型還不夠確定。 但是對於模型非常確定或分配了高概率分數的樣本呢? 現在,如果我們可以使用這樣的樣本,那麼模型會改進它對已經學習的特徵的學習。
通過這種方式,它通過完善其學習來提高其性能。 總而言之,工程師可以抽取概率分數為 0.9 及以上的數據樣本,並可以為其分配標籤。 這可以進一步註釋並作為訓練樣本提供。
這種方法的動機是改進模型對特徵的現有學習。 通過這種方式,ML 模型和 ML 工程師相互合作,有效地提出要標註的數據樣本。 這種技術被稱為合作學習。
另請閱讀:人工智能的未來範圍
結論
已經發現,使用主動學習技術,從業者可以節省大約 80% 的時間,而這些時間原本是花在註釋和標籤上的。 主動學習的優勢不僅限於減少模型的訓練時間和高效的數據標註。
它還減少了由於存在大量單一類型的樣本導致模型有偏差而發生的過度擬合。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。