
人工智能的主动学习[综合指南]
已发表: 2020-12-01人工智能主动学习概述
在本文中,我们将介绍主动学习的基础知识及其在人工智能领域的相关性。
目录
介绍
在机器学习中,存在两种类型的学习方法——监督学习和无监督学习。 在监督学习中,我们为模型提供每个训练样本的标签。 该模型学习训练数据样本的特征并将它们映射到相应的标签。
输出是测试样本属于特定类别的概率。 然而,无监督学习不需要标签,模型根据它在训练过程中学到的一些模式或趋势对测试样本进行分类。
现在在监督学习中,需要图像(假设为输入)及其注释。 该模型可以通过优化到足以适应图像及其注释来从图像中学习。
但是,实际上要使模型在测试样本上表现得非常好,需要大量的图像及其注释。 为了解决这个问题,许多研究人员采用了主动学习。

动机
在许多情况下,通常会有数以百万计的数据可用,但对所有数据进行注释是不可行且耗时的。 几个例子包括:
- 无人机在飞行过程中录制的视频
- 包含数百万个细胞的医学图像
- 来自交通灯信号的闭路电视录像
为了处理如此大量的数据,采用了主动学习,它告诉我们所有可用的注释数据,注释哪些样本是有意义的。
基本流程
ML 工程师/Oracle 专家可以访问大量未标记的数据。 比如说,任务是建立一个猫狗分类器。 现在,在整个数据池中,工程师选择仅使用 20% 的数据(首先标记它们)训练模型,并将其余 80% 用于测试目的。
这是一种基于回合的方法。 在每次迭代中,都会将测试图像提供给模型进行分类。 如果模型表现不佳,或者模型分配的概率较小,例如 0.6,则需要在此样本上训练模型以提高整体性能。 模型不确定或不自信的图像包含更多信息供模型学习。
然后将该样本标记并选择为训练样本。 重复此迭代,直到最后一个测试样本。 通过这种方式,我们组装了一个值得注释的新训练集。 该模型在新收集的选择性训练数据上进行训练,从而减少了整体训练时间。 重复此操作,直到注释集结束。
如何选择图像进行标注?
上述方法只是选择注释样本的一种简单方法。 在实际实践中,使用了以下两种方法,有时将两者结合使用。
- 基于不确定性的采样:模型不确定的图像,或者模型已分配低概率的图像。
- 基于多样性的采样:表示多样性的图像,即空间表示、光谱表示、类表示等方面的变化。 更多的多样性,更多的可用信息供模型学习。
将数据样本(图像)作为输入并返回优先级/排名分数的函数称为采集函数。
阅读:人工智能的挑战
常用采集函数
1. 最佳与次佳 (BvSB)
这种方法主要用于少数类(3到5)。 使用的公式考虑了最高和次高类别的概率值。 y1 和 y2 表示模型 p? 预测的最高和第二高概率值? 对于给定的样本 x。

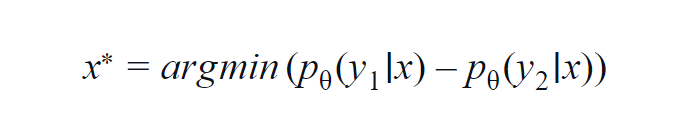
基本思想是最小化下面的方程。 差异越小,数据样本 x 中包含的信息就越多。
为了简单理解,假设数据样本中涉及的类是狗、猫、马和狮子。 考虑第一个场景,模型的输入是狗图像,狗类(最可能)的输出概率为 0.6,猫类(第二最可能)的输出概率为 0.35。
剩余 0.5 分布在其他两个类之间。 在第二种情况下,对于相同的输入,前两个类别的输出概率为 0.7 和 0.2。 现在从这两个场景中,我们可以推断出,在第二个场景中,模型对其预测更加确定(0.7-0.2=0.5)。
在第一种情况下,模型对预测的不确定性更大(0.6-0.35=0.25)。 从而最小化上述方程,我们可以收集到一个值得标注的数据样本。
2.熵
BvSB 适用于较少的课程。 然而,对于大量的类,熵被用作获取函数。 原因是,下面的公式考虑了其余类中的信息。 熵是杂质或不平衡的量度。 在机器学习方面,它可以定义为模型不确定性的度量。 熵的高值表示类关联中的高度不确定性。
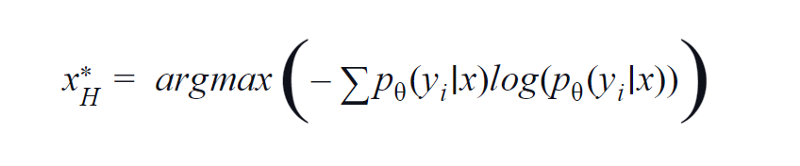
熵方程,作者图片
因此,最大化上述方程将为我们生成一个模型高度不确定或对分类任务最不自信的图像样本。
3. 委员会QBC查询
就像随机森林利用集成学习一样——利用多个决策树。 类似地,关于数据样本 x 的不确定性是通过一组不同模型(具有不同的超参数或种子)来测量的。
有了这个,如果对于给定的图像,不同模型的输出变化很大,这意味着模型在分类这个图像时不舒服。 通常,来自每个模型的最可能得分堆叠在一个向量中。 计算该向量的熵。 同样,如果熵很高,则进一步标记和注释图像。
领先一步
到目前为止,我们使用的数据样本模型还不够确定。 但是对于模型非常确定或分配了高概率分数的样本呢? 现在,如果我们可以使用这样的样本,那么模型会改进它对已经学习的特征的学习。
通过这种方式,它通过完善其学习来提高其性能。 总而言之,工程师可以抽取概率分数为 0.9 及以上的数据样本,并可以为其分配标签。 这可以进一步注释并作为训练样本提供。
这种方法的动机是改进模型对特征的现有学习。 通过这种方式,ML 模型和 ML 工程师相互合作,有效地提出要标注的数据样本。 这种技术被称为合作学习。
另请阅读:人工智能的未来范围
结论
已经发现,使用主动学习技术,从业者可以节省大约 80% 的时间,而这些时间原本是花在注释和标签上的。 主动学习的优势不仅限于减少模型的训练时间和高效的数据标注。
它还减少了由于存在大量单一类型的样本导致模型有偏差而发生的过度拟合。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。