
人工知能のためのアクティブラーニング[包括的なガイド]
公開: 2020-12-01人工知能の能動学習の概要
この記事では、アクティブラーニングの基本と人工知能の世界におけるその関連性について説明します。
目次
序章
機械学習には、教師あり学習と教師なし学習の2種類の学習方法があります。 教師あり学習では、各トレーニングサンプルのラベルがモデルに提供されます。 モデルはトレーニングデータサンプルの特徴を学習し、それらを対応するラベルにマッピングします。
出力は、特定のクラスに属するテストサンプルの確率です。 ただし、教師なし学習にはラベルは必要ありません。モデルは、トレーニングプロセス中に学習したパターンまたは傾向に基づいて、テストサンプルを分類します。
現在、教師あり学習では、画像(入力として想定)とその注釈が必要です。 モデルは、画像とその注釈に合うように十分に最適化することにより、画像から学習できます。
ただし、実際には、モデルがテストサンプルで非常に良好に機能するためには、多数の画像とその注釈が必要です。 この問題を解決するために、アクティブラーニングは多くの研究者によって採用されました。

モチベーション
多くの場合、通常は数百万のデータが利用可能ですが、それらすべてに注釈を付けることは実行不可能で時間がかかります。 いくつかの例が含まれます:
- 飛行中にドローンによって記録されたビデオ
- 数百万の細胞を含む医用画像
- 信号機からのCCTV録画
このような重いデータを処理するために、注釈に使用できるすべてのデータから、どのサンプルが意味をなすかを注釈として示すアクティブラーニングが採用されています。
基本的なプロセス
MLエンジニア/Oracleスペシャリストは、ラベルのないデータの大規模なプールにアクセスできます。 たとえば、タスクは猫と犬の分類子を作成することです。 このデータプール全体から、エンジニアはデータの20%のみでモデルをトレーニングすることを選択し(最初にラベルを付けます)、残りの80%をテスト目的で使用します。
これはラウンドベースの方法です。 すべての反復で、分類のためにテスト画像がモデルに与えられます。 モデルのパフォーマンスが低い場合、またはモデルによって割り当てられる確率が低い場合、たとえば0.6の場合は、全体的なパフォーマンスを向上させるために、このサンプルでモデルをトレーニングする必要があります。 モデルが不確実または自信がない画像には、モデルが学習するためのより多くの情報が含まれています。
次に、このサンプルにラベルが付けられ、トレーニングサンプルとして選択されます。 この反復は、最後のテストサンプルまで繰り返されます。 このようにして、注釈を付ける価値のある新しいトレーニングセットを組み立てます。 モデルは、新しく収集された選択的トレーニングデータでトレーニングされるため、全体的なトレーニング時間が短縮されます。 これは、注釈セットが終了するまで繰り返されます。
注釈の画像を選択するにはどうすればよいですか?
上記のアプローチは、注釈のサンプルを選択する簡単な方法の1つにすぎません。 実際には、次の2つの方法が使用されますが、2つの方法を組み合わせて使用することもあります。
- 不確実性に基づくサンプリング:モデルが不確実な画像、またはモデルによって低い確率が割り当てられた画像。
- 多様性に基づくサンプリング:多様性を表す画像、つまり、空間表現、スペクトル表現、クラス表現などの変化。 モデルが学習するための多様性、利用可能な情報が増えます。
データサンプル(画像)を入力として取得し、優先度/ランキングスコアを返す関数を取得関数と呼びます。
読む: AIの課題
一般的な取得機能
1.ベスト対セカンドベスト(BvSB)
このメソッドは、主にいくつかのクラス(3〜5)で使用されます。 使用される式は、最高クラスと2番目に高いクラスの確率値を考慮します。 y1とy2は、モデルpによって予測された最も高い確率値と2番目に高い確率値を示します。 与えられたサンプルxに対して。

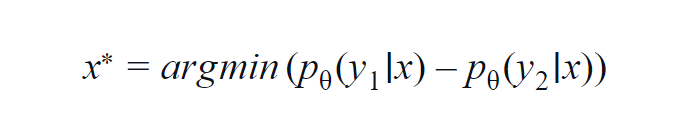
基本的な考え方は、以下の式を最小化することです。 差が小さいほど、データサンプルxに含まれる情報が多くなります。
簡単に理解できるように、データサンプルに含まれるクラスが犬、猫、馬、ライオンである例を想定します。 モデルへの入力が犬の画像であり、犬のクラス(最も可能性が高い)の出力確率が0.6で、猫のクラス(2番目に可能性が高い)の出力確率が0.35である最初のシナリオを考えてみます。
残りの0.5は、他の2つのクラスに分散されます。 2番目のシナリオでは、同じ入力に対して、上位2つのクラスの出力確率は0.7と0.2です。 2つのシナリオから、2番目のシナリオでは、モデルはその予測についてより確実であると推測できます(0.7–0.2 = 0.5)。
最初のシナリオでは、モデルは予測に関してより不確実です(0.6–0.35 = 0.25)。 これにより、上記の式を最小化することで、注釈を付ける価値のあるデータサンプルを収集できます。
2.エントロピー
BvSBは少数のクラスに適しています。 ただし、クラス数が多い場合は、取得関数としてエントロピーを使用します。 その理由は、以下の式は残りのクラスの情報を考慮しているためです。 エントロピーは、不純物または不均衡の尺度です。 機械学習の観点からは、モデルの不確実性の尺度として定義できます。 エントロピーの値が高い場合は、クラスの関連付けに不確実性が高いことを示しています。
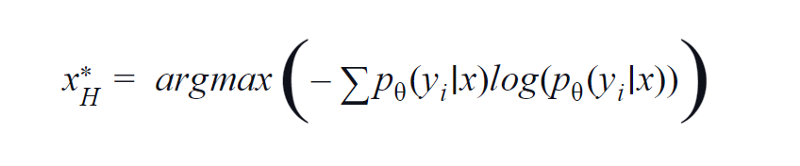
エントロピー方程式、作者による画像
したがって、上記の方程式を最大化すると、モデルが分類タスクで非常に不確実であるか、信頼性が最も低い画像サンプルが得られます。
3.委員会QBCによる問い合わせ
ランダムフォレストがアンサンブル学習を利用するのと同じように、いくつかの決定木を利用します。 同様に、データサンプルxに関する不確実性は、さまざまなモデル(さまざまなハイパーパラメーターまたはシードを持つ)のアンサンブルで測定されます。
これにより、特定の画像について、モデルごとに出力が大きく異なる場合、モデルがこの画像を分類するのに慣れていないことを意味します。 通常、各モデルからの最も可能性の高いスコアはベクトルに積み重ねられます。 このベクトルのエントロピーが計算されます。 この場合も、エントロピーが高い場合、画像にはさらにラベルが付けられ、注釈が付けられます。
一足先
これまで、モデルが十分にわからないデータサンプルを使用してきました。 しかし、モデルが非常に確実であるか、高い確率スコアを割り当てるサンプルについてはどうでしょうか。 さて、そのようなサンプルを使用できる場合、モデルはすでに学習した機能についての学習を改善します。
このように、学習を磨くことでパフォーマンスが向上します。 全体として、エンジニアは確率スコアが0.9以上のデータサンプルを取得し、それにラベルを割り当てることができます。 これにさらに注釈を付けて、トレーニングサンプルとして提供することができます。
このような方法の動機は、モデルの機能に関する既存の学習を改善することです。 このようにして、MLモデルとMLエンジニアは互いに協力して、注釈を付けるデータサンプルを効果的に作成します。 このような手法は、協調学習と呼ばれます。
また読む: AIの将来の範囲
結論
アクティブラーニング技術を使用することで、実践者は注釈やラベル付けに費やされた時間の約80%を節約できることがわかっています。 アクティブラーニングの利点は、モデルのトレーニング時間の短縮と効率的なデータ注釈だけにとどまりません。
また、単一タイプのサンプルが多数存在するために発生する過剰適合が減少し、モデルに偏りが生じます。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。