
Aprendizaje activo para inteligencia artificial [Guía completa]
Publicado: 2020-12-01Descripción general del aprendizaje activo para la inteligencia artificial
En este artículo, cubriremos los conceptos básicos del aprendizaje activo y su relevancia en el mundo de la Inteligencia Artificial.
Tabla de contenido
Introducción
En el aprendizaje automático, existen dos tipos de métodos de aprendizaje: aprendizaje supervisado y no supervisado. En el aprendizaje supervisado, proporcionamos al modelo etiquetas para cada muestra de entrenamiento. El modelo aprende las características de las muestras de datos de entrenamiento y las asigna a sus etiquetas correspondientes.
La salida es una probabilidad de que una muestra de prueba pertenezca a una clase particular. Sin embargo, el aprendizaje no supervisado no requiere etiquetas y el modelo clasifica la muestra de prueba según algún patrón o tendencia que haya aprendido durante el proceso de entrenamiento.
Ahora, en el aprendizaje supervisado, se necesitan imágenes (asumir como entrada) y sus anotaciones. El modelo puede aprender de las imágenes mediante la optimización lo suficientemente bien como para adaptarse a las imágenes y su anotación.
Pero, prácticamente para que el modelo funcione extremadamente bien en las muestras de prueba, se requiere una gran cantidad de imágenes y sus anotaciones. Para resolver este problema, muchos investigadores emplearon el aprendizaje activo.

Motivación
En muchos casos, normalmente habrá millones de datos disponibles, pero anotarlos todos sería inviable y llevaría mucho tiempo. Algunos ejemplos incluyen:
- Un video grabado por un dron durante su vuelo
- Una imagen médica que contiene millones de células.
- Una grabación de circuito cerrado de televisión de una señal de semáforo
Para manejar datos tan pesados, se emplea el aprendizaje activo que nos informa de todos los datos disponibles para la anotación, anotando qué muestras tienen sentido.
Proceso básico
El ingeniero de ML/especialista en Oracle tiene acceso a un gran conjunto de datos sin etiquetar. Digamos que la tarea es construir un clasificador de perros y gatos. Ahora, de todo este conjunto de datos, el ingeniero elige entrenar el modelo solo con el 20% de los datos (los etiqueta primero) y usa el 80% restante para fines de prueba.
Este es un método basado en rondas. En cada iteración, se entrega una imagen de prueba al modelo para su clasificación. Si el modelo funciona mal, o si la probabilidad asignada por el modelo es menor, digamos 0,6, entonces el modelo debe entrenarse en esta muestra para mejorar el rendimiento general. La imagen para la que el modelo no está seguro o no está seguro contiene más información para que el modelo aprenda.
A continuación, esta muestra se etiqueta y selecciona como muestra de formación. Esta iteración se repite hasta la última muestra de prueba. De esta forma, armamos un nuevo conjunto de entrenamiento que vale la pena anotar. El modelo se entrena con los datos de entrenamiento selectivo recién recopilados, lo que reduce el tiempo total de entrenamiento. Esto se repite hasta que finaliza el conjunto de anotaciones.
¿Cómo seleccionar la imagen para la anotación?
El enfoque mencionado anteriormente es solo una forma simple de elegir una muestra para la anotación. En la práctica real, se utilizan los siguientes dos métodos, a veces una combinación de los dos.
- Muestreo basado en la incertidumbre : imágenes sobre las que el modelo no está seguro o imágenes a las que el modelo les ha asignado una probabilidad baja.
- Muestreo basado en diversidad : Imágenes que representan la diversidad, es decir, variación en la representación espacial, representación espectral, representación de clases, etc. Más diversidad, más información disponible para que el modelo aprenda.
Una función que toma una muestra de datos (imagen) como entrada y devuelve una puntuación de prioridad/clasificación se denomina función de adquisición.
Leer: Desafíos en IA
Funciones comunes de adquisición
1. Mejor versus segundo mejor (BvSB)
Este método se usa principalmente para algunas clases (3 a 5). La fórmula utilizada considera los valores de probabilidad de la clase más alta y la segunda más alta. y1 y y2 indican los valores de probabilidad más alto y el segundo más alto predichos por el modelo p? para una muestra dada x.

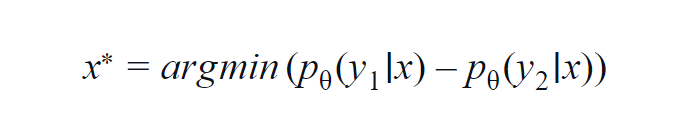
La idea fundamental es minimizar la siguiente ecuación. Cuanto menor sea la diferencia, mayor será la información contenida en la muestra de datos x.
Para facilitar la comprensión, suponga un ejemplo en el que las clases involucradas en la muestra de datos sean perro, gato, caballo y león. Considere el primer escenario en el que la entrada al modelo es una imagen de perro y la probabilidad de salida de la clase de perro (la más probable) es 0,6 y la de la clase de gato (la segunda más probable) es 0,35.
El 0,5 restante se distribuye entre las otras dos clases. En el segundo escenario, para la misma entrada, las probabilidades de salida para las dos clases principales son 0,7 y 0,2. Ahora, a partir de los dos escenarios, podemos inferir que en el segundo escenario, el modelo es más seguro acerca de su predicción (0.7–0.2=0.5).
En el primer escenario, el modelo es más incierto con respecto a la predicción (0.6–0.35=0.25). De este modo, minimizando la ecuación anterior, podemos recopilar una muestra de datos que vale la pena anotar.
2. Entropía
BvSB es adecuado para menos clases. Sin embargo, con un gran número de clases, la entropía se utiliza como función de adquisición. La razón es que la siguiente fórmula considera la información en las clases restantes. La entropía es una medida de impureza o desequilibrio. En términos de aprendizaje automático, se puede definir como una medida de incertidumbre de un modelo. Un alto valor de entropía es una indicación de alta incertidumbre en la asociación de clases.
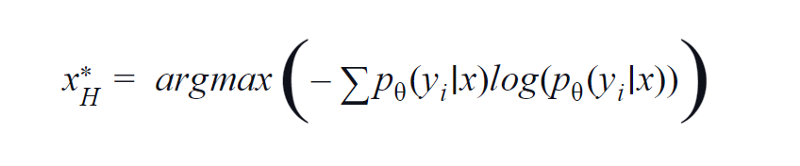
Ecuación de entropía, Imagen por Autor
Por lo tanto, maximizar la ecuación anterior nos dará una muestra de imagen para la cual el modelo es altamente incierto o menos confiable en la tarea de clasificación.
3. Consulta por comité QBC
Al igual que el bosque aleatorio hace uso del aprendizaje conjunto, haciendo uso de varios árboles de decisión. De manera similar, la incertidumbre sobre una muestra de datos x se mide sobre un conjunto de diferentes modelos (que tienen diferentes hiperparámetros o semillas).
Con esto, si para una imagen dada, la salida varía mucho para diferentes modelos, significa que los modelos no se sienten cómodos clasificando esta imagen. Por lo general, la puntuación más probable de cada modelo se apila en un vector. Se calcula la entropía de este vector. Nuevamente, si la entropía es alta, la imagen se etiqueta y anota más.
Un paso adelante
Hasta ahora, hemos utilizado muestras de datos para las que el modelo no es lo suficientemente seguro. Pero, ¿qué pasa con las muestras para las que el modelo es extremadamente seguro o asigna una puntuación de alta probabilidad? Ahora, si podemos usar tales muestras, entonces el modelo mejora su aprendizaje sobre las características que ya ha aprendido.
De esta forma, mejora su rendimiento puliendo su aprendizaje. En general, el ingeniero puede tomar muestras de datos que tienen una puntuación de probabilidad de 0,9 o superior y puede asignarles una etiqueta. Esto se puede anotar y alimentar como una muestra de entrenamiento.
El motivo de tal método es mejorar el aprendizaje existente del modelo sobre las características. De esta manera, el modelo de ML y el ingeniero de ML cooperan entre sí para generar muestras de datos que se van a anotar. Esta técnica se denomina aprendizaje cooperativo.
Lea también: Alcance futuro de la IA
Conclusión
Se ha descubierto que al usar técnicas de aprendizaje activo, los profesionales ahorran alrededor del 80 % del tiempo que de otro modo dedicarían a la anotación y el etiquetado. La ventaja del aprendizaje activo no solo se limita a la reducción del tiempo de entrenamiento del modelo y la anotación eficiente de datos.
También reduce el sobreajuste que ocurre debido a la presencia de una gran cantidad de muestras de un solo tipo que hace que el modelo esté sesgado.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.