
Învățare activă pentru inteligența artificială [Ghid cuprinzător]
Publicat: 2020-12-01Prezentare generală a învățării active pentru inteligența artificială
În acest articol, vom acoperi elementele de bază ale învățării active și relevanța acesteia în lumea inteligenței artificiale.
Cuprins
Introducere
În învățarea automată, există două tipuri de metode de învățare - învățare supravegheată și nesupravegheată. În învățarea supravegheată, oferim modelului etichete pentru fiecare eșantion de antrenament. Modelul învață caracteristicile eșantioanelor de date de antrenament și le mapează la etichetele corespunzătoare.
Rezultatul este o probabilitate ca un eșantion de testare să aparțină unei anumite clase. Învățarea nesupravegheată, totuși, nu necesită etichete, iar modelul clasifică eșantionul de testare pe baza unui model sau tendință pe care a învățat-o în timpul procesului de formare.
Acum, în învățarea supravegheată, este nevoie de imagini (să presupunem ca intrare) și adnotările acesteia. Modelul poate învăța din imagini optimizându-se suficient de bine pentru a se potrivi imaginilor și adnotărilor acestora.
Dar, practic, pentru ca modelul să funcționeze extrem de bine pe mostrele de testare, sunt necesare o multitudine de imagini și adnotările sale. Pentru a rezolva această problemă, mulți cercetători au folosit învățarea activă.

Motivația
În multe cazuri, vor fi de obicei milioane de date disponibile, dar adnotarea tuturor ar fi imposibilă și ar consuma mult timp. Câteva exemple includ:
- Un videoclip înregistrat de o dronă în timpul zborului acesteia
- O imagine medicală care conține milioane de celule
- O înregistrare CCTV de la un semnal de semafor
Pentru a face față unor astfel de date grele, se folosește învățarea activă care ne indică toate datele disponibile pentru adnotare, adnotând care probe au sens.
Proces de bază
Inginerul ML/specialist Oracle are acces la o mare cantitate de date neetichetate. Să spunem, sarcina este de a construi un clasificator de pisici și câini. Acum, din acest întreg grup de date, inginerul alege să antreneze modelul pe doar 20% din date (le etichetează mai întâi) și folosește restul de 80% în scopul testării.
Aceasta este o metodă rotundă. În fiecare iterație, modelului i se oferă o imagine de testare pentru clasificare. Dacă modelul are performanțe slabe sau dacă probabilitatea atribuită de model este mai mică, să zicem 0,6, atunci modelul trebuie antrenat pe acest eșantion pentru a îmbunătăți performanța generală. Imaginea pentru care modelul este incert sau neîncrezător conține mai multe informații pe care modelul le poate învăța.
Acest eșantion este apoi etichetat și selectat ca eșantion de antrenament. Această iterație se repetă până la ultima probă de testare. În acest fel, asamblam un nou set de antrenament care merită adnotat. Modelul este antrenat pe baza datelor de antrenament selective nou colectate, reducând astfel timpul general de antrenament. Acest lucru se repetă până la încheierea setului de adnotări.
Cum se selectează imaginea pentru adnotare?
Abordarea menționată mai sus este doar o modalitate simplă de a alege un eșantion pentru adnotare. În practica reală, se folosesc următoarele două metode, uneori o combinație a celor două.
- Eșantionarea bazată pe incertitudine : imagini despre care modelul este incert sau imagini cărora modelul le-a atribuit probabilitate scăzută.
- Eșantionarea bazată pe diversitate : imagini care reprezintă diversitatea, adică variația reprezentării spațiale, reprezentarea spectrală, reprezentarea clasei și așa mai departe. Mai multă diversitate, mai multe informații disponibile pentru ca modelul să învețe.
O funcție care ia un eșantion de date (imagine) ca intrare și returnează un scor de prioritate/clasare este denumită funcție de achiziție.
Citiți: Provocări în AI
Funcții comune de achiziție
1. Cel mai bun versus al doilea cel mai bun (BvSB)
Această metodă este folosită în principal pentru câteva clase (3 până la 5). Formula utilizată ia în considerare valorile de probabilitate ale celei mai mari și ale celei de-a doua clase. y1 și y2 indică cea mai mare și a doua cea mai mare valoare a probabilității prezise de modelul p? pentru un eșantion dat x.

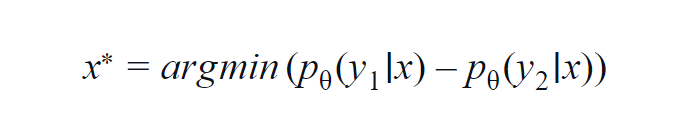
Ideea fundamentală este de a minimiza ecuația de mai jos. Cu cât diferența este mai mică, cu atât informațiile conținute în eșantionul de date x sunt mai mari.
Pentru o înțelegere simplă, să presupunem un exemplu în care clasele implicate în eșantionul de date sunt câine, pisică, cal și leu. Luați în considerare primul scenariu în care intrarea în model este o imagine de câine și probabilitatea de ieșire a clasei de câine (cel mai probabil) este 0,6 și a clasei de pisică (a doua cea mai probabilă) este 0,35.
Cele 0,5 rămase sunt distribuite între celelalte două clase. În al doilea scenariu, pentru aceeași intrare, probabilitățile de ieșire pentru primele două clase sunt 0,7 și 0,2. Acum, din cele două scenarii, putem deduce că, în al doilea scenariu, modelul este mai sigur de predicția sa (0,7–0,2=0,5).
În primul scenariu, modelul este mai incert în ceea ce privește predicția (0,6–0,35=0,25). Minimând astfel ecuația de mai sus, putem colecta un eșantion de date care merită adnotat.
2. Entropie
BvSB este potrivit pentru mai puține clase. Cu toate acestea, cu un număr mare de clase, entropia este utilizată ca funcție de achiziție. Motivul fiind că formula de mai jos ia în considerare informațiile din clasele rămase. Entropia este o măsură a impurității sau a dezechilibrului. În ceea ce privește învățarea automată, aceasta poate fi definită ca o măsură a incertitudinii unui model. O valoare mare a entropiei este un indiciu al incertitudinii mari în asocierea clasei.
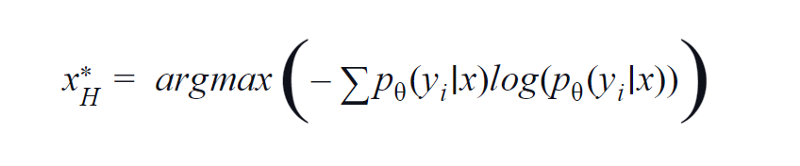
Ecuația de entropie, imagine după autor
Prin urmare, maximizarea ecuației de mai sus ne va oferi un eșantion de imagine pentru care modelul este foarte incert sau mai puțin încrezător în sarcina de clasificare.
3. Interogare de către comisia QBC
La fel cum pădurea aleatoare folosește învățarea ansamblului - folosind mai mulți arbori de decizie. În mod similar, incertitudinea cu privire la un eșantion de date x este măsurată pe un ansamblu de modele diferite (având hiperparametri sau semințe diferiți).
Cu aceasta, dacă pentru o imagine dată, ieșirea variază foarte mult pentru diferite modele, înseamnă că modelele nu sunt confortabile în clasificarea acestei imagini. De obicei, scorul cel mai probabil din fiecare model este stivuit într-un vector. Se calculează entropia acestui vector. Din nou, dacă entropia este mare, imaginea este etichetată și adnotată în continuare.
Un pas inainte
Până acum, am folosit mostre de date pentru care modelul nu este suficient de sigur. Dar cum rămâne cu eșantioanele pentru care modelul este extrem de sigur sau atribuie un scor de probabilitate mare? Acum, dacă putem folosi astfel de mostre, atunci modelul își îmbunătățește învățarea despre caracteristicile pe care le-a învățat deja.
În acest fel, își îmbunătățește performanța prin lustruirea învățării. Una peste alta, inginerul poate lua mostre de date care au un scor de probabilitate de 0,9 și mai mult și îi poate atribui o etichetă. Acest lucru poate fi adnotat în continuare și alimentat ca un eșantion de antrenament.
Motivul unei astfel de metode este de a îmbunătăți învățarea existentă a modelului despre caracteristici. În acest fel, modelul ML și inginerul ML cooperează unul cu celălalt pentru a veni eficient cu mostre de date care urmează să fie adnotate. O astfel de tehnică se numește învățare prin cooperare.
Citește și: Scopul viitor al AI
Concluzie
S-a descoperit că, folosind tehnici de învățare activă, practicienii economisesc aproximativ 80% din timpul lor petrecut altfel în adnotare și etichetare. Avantajul învățării active nu se limitează doar la reducerea timpului de antrenament al modelului și la adnotarea eficientă a datelor.
De asemenea, reduce supraadaptarea care apare din cauza prezenței unui număr mare de mostre de un singur tip, ceea ce face ca modelul să fie părtinitor.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.