
การเรียนรู้เชิงรุกสำหรับปัญญาประดิษฐ์ [คู่มือฉบับสมบูรณ์]
เผยแพร่แล้ว: 2020-12-01ภาพรวมของการเรียนรู้เชิงรุกสำหรับปัญญาประดิษฐ์
ในบทความนี้ เราจะพูดถึงพื้นฐานของการเรียนรู้เชิงรุกและความเกี่ยวข้องในโลกของปัญญาประดิษฐ์
สารบัญ
บทนำ
ในแมชชีนเลิร์นนิงมีวิธีการเรียนรู้สองประเภท — การเรียนรู้แบบมีผู้ดูแลและการเรียนรู้แบบไม่มีผู้ดูแล ในการเรียนรู้ภายใต้การดูแล เราจัดเตรียมโมเดลพร้อมป้ายกำกับสำหรับตัวอย่างการฝึกอบรมแต่ละรายการ โมเดลจะเรียนรู้คุณสมบัติของตัวอย่างข้อมูลการฝึกและจับคู่กับป้ายกำกับที่เกี่ยวข้อง
ผลลัพธ์คือความน่าจะเป็นของตัวอย่างทดสอบที่เป็นของคลาสใดคลาสหนึ่ง อย่างไรก็ตาม การเรียนรู้แบบไม่มีผู้ดูแลไม่จำเป็นต้องมีป้ายกำกับ และแบบจำลองจะจำแนกตัวอย่างการทดสอบตามรูปแบบหรือแนวโน้มบางอย่างที่ได้เรียนรู้ในระหว่างกระบวนการฝึกอบรม
ขณะนี้ในการเรียนรู้ภายใต้การดูแล มีความจำเป็นสำหรับรูปภาพ (สมมติว่าเป็นอินพุต) และคำอธิบายประกอบ ตัวแบบสามารถเรียนรู้จากภาพโดยปรับให้เหมาะสมพอที่จะพอดีกับภาพและคำอธิบายประกอบ
แต่ในทางปฏิบัติแล้ว เพื่อให้โมเดลทำงานได้ดีมากกับตัวอย่างทดสอบ จำเป็นต้องมีรูปภาพมากมายและคำอธิบายประกอบ เพื่อแก้ปัญหานี้ นักวิจัยหลายคนใช้การเรียนรู้เชิงรุก

แรงจูงใจ
ในหลายกรณี โดยปกติจะมีข้อมูลนับล้าน แต่การทำหมายเหตุประกอบทั้งหมดนั้นเป็นไปไม่ได้และใช้เวลานาน ตัวอย่างบางส่วน ได้แก่:
- วิดีโอที่โดรนบันทึกระหว่างเที่ยวบิน
- ภาพทางการแพทย์ที่มีเซลล์นับล้าน
- กล้องวงจรปิดบันทึกสัญญาณไฟจราจร
ในการจัดการกับข้อมูลจำนวนมากดังกล่าว การเรียนรู้เชิงรุกถูกนำมาใช้เพื่อบอกเราถึงข้อมูลที่มีอยู่ทั้งหมดสำหรับการทำหมายเหตุประกอบ โดยระบุว่าตัวอย่างใดเหมาะสม
กระบวนการพื้นฐาน
วิศวกร ML/ผู้เชี่ยวชาญของ Oracle มีสิทธิ์เข้าถึงกลุ่มข้อมูลขนาดใหญ่ที่ไม่มีป้ายกำกับ สมมติว่างานคือสร้างตัวแยกประเภทแมวและสุนัข จากแหล่งรวมข้อมูลทั้งหมดนี้ วิศวกรเลือกที่จะฝึกแบบจำลองกับข้อมูลเพียง 20% (ติดป้ายกำกับก่อน) และใช้ส่วนที่เหลืออีก 80% เพื่อวัตถุประสงค์ในการทดสอบ
นี่เป็นวิธีการแบบปัดเศษ ในการทำซ้ำทุกครั้ง รูปภาพทดสอบจะถูกกำหนดให้กับแบบจำลองสำหรับการจัดประเภท หากแบบจำลองมีประสิทธิภาพต่ำ หรือหากความน่าจะเป็นที่กำหนดโดยแบบจำลองนั้นน้อยกว่า ให้พูด 0.6 แบบจำลองนั้นจะต้องได้รับการฝึกอบรมจากตัวอย่างนี้เพื่อปรับปรุงประสิทธิภาพโดยรวม ภาพที่โมเดลไม่แน่นอนหรือไม่มั่นใจมีข้อมูลเพิ่มเติมสำหรับโมเดลที่จะเรียนรู้
ตัวอย่างนี้จะถูกติดฉลากและเลือกเป็นตัวอย่างการฝึกอบรม ทำซ้ำนี้ซ้ำจนกระทั่งตัวอย่างทดสอบล่าสุด ด้วยวิธีนี้ เราจึงได้รวบรวมชุดการฝึกใหม่ที่ควรค่าแก่การอธิบายประกอบ โมเดลนี้ได้รับการฝึกอบรมเกี่ยวกับข้อมูลการฝึกอบรมแบบคัดเลือกที่เพิ่งรวบรวมซึ่งจะช่วยลดเวลาการฝึกอบรมโดยรวม ทำซ้ำจนกว่าชุดคำอธิบายประกอบจะสิ้นสุดลง
วิธีการเลือกรูปภาพสำหรับคำอธิบายประกอบ?
วิธีการดังกล่าวเป็นเพียงวิธีง่ายๆ ในการเลือกตัวอย่างสำหรับคำอธิบายประกอบ ในทางปฏิบัติจะใช้สองวิธีต่อไปนี้ บางครั้งใช้ทั้งสองวิธีร่วมกัน
- การสุ่มตัวอย่างโดยพิจารณาจากความไม่แน่นอน : ภาพที่โมเดลมีความไม่แน่นอนหรือภาพที่ได้รับความน่าจะเป็นต่ำจากตัวแบบ
- การสุ่มตัวอย่างตามความหลากหลาย : ภาพที่แสดงถึงความหลากหลาย กล่าวคือ การแปรผันของการแสดงเชิงพื้นที่ การแสดงสเปกตรัม การเป็นตัวแทนของชั้นเรียน และอื่นๆ มีความหลากหลายมากขึ้น มีข้อมูลให้โมเดลเรียนรู้มากขึ้น
ฟังก์ชันที่ใช้ตัวอย่างข้อมูล (รูปภาพ) เป็นอินพุตและส่งกลับคะแนนลำดับความสำคัญ/อันดับจะเรียกว่า ฟังก์ชันการได้มา
อ่าน: ความท้าทายใน AI
ฟังก์ชันการได้มาร่วมกัน
1. Best-versus-Second-Best (BvSB)
วิธีนี้ส่วนใหญ่จะใช้สำหรับบางคลาส (3 ถึง 5) สูตรที่ใช้พิจารณาค่าความน่าจะเป็นของคลาสสูงสุดและอันดับสองสูงสุด y1 และ y2 ระบุค่าความน่าจะเป็นสูงสุดและสูงสุดอันดับสองที่คาดการณ์โดยแบบจำลอง p? สำหรับตัวอย่างที่กำหนด x

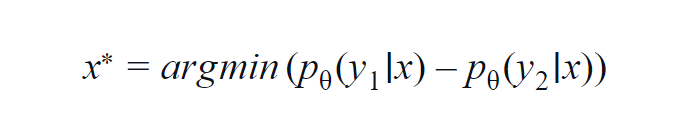
แนวคิดพื้นฐานคือการย่อสมการด้านล่างให้น้อยที่สุด ยิ่งความแตกต่างต่ำ ข้อมูลในตัวอย่างข้อมูล x ก็จะยิ่งมากขึ้นเท่านั้น
เพื่อความเข้าใจอย่างง่าย สมมติว่าตัวอย่างที่คลาสที่เกี่ยวข้องกับตัวอย่างข้อมูลคือ สุนัข แมว ม้า และสิงโต พิจารณาสถานการณ์สมมติแรกที่อินพุตไปยังโมเดลเป็นภาพสุนัข และความน่าจะเป็นของเอาต์พุตของคลาสสุนัข (เป็นไปได้มากที่สุด) คือ 0.6 และของคลาส cat (น่าจะเป็นอันดับ 2 มากที่สุด) คือ 0.35
0.5 ที่เหลือจะถูกแจกจ่ายระหว่างสองคลาสที่เหลือ ในสถานการณ์สมมติที่สอง สำหรับอินพุตเดียวกัน ความน่าจะเป็นของเอาต์พุตสำหรับคลาสสองอันดับแรกคือ 0.7 และ 0.2 จากสองสถานการณ์นี้ เราสามารถอนุมานได้ว่าในสถานการณ์ที่สอง โมเดลมีความแน่นอนมากขึ้นเกี่ยวกับการคาดคะเนของมัน (0.7–0.2=0.5)
ในสถานการณ์แรก โมเดลมีความไม่แน่นอนมากขึ้นเกี่ยวกับการคาดคะเน (0.6–0.35=0.25) โดยการย่อสมการข้างต้นให้เหลือน้อยที่สุด เราสามารถรวบรวมตัวอย่างข้อมูลที่ควรค่าแก่การทำหมายเหตุประกอบ
2. เอนโทรปี
BvSB เหมาะสำหรับชั้นเรียนที่น้อยกว่า อย่างไรก็ตาม ด้วยคลาสจำนวนมาก เอนโทรปีจึงถูกใช้เป็นฟังก์ชันการได้มา เหตุผลคือ สูตรด้านล่างพิจารณาข้อมูลในชั้นเรียนที่เหลือ เอนโทรปีเป็นตัววัดสิ่งเจือปนหรือความไม่สมดุล ในแง่ของแมชชีนเลิร์นนิง สามารถกำหนดเป็นการวัดความไม่แน่นอนของแบบจำลองได้ ค่าเอนโทรปีที่สูงเป็นตัวบ่งชี้ถึงความไม่แน่นอนสูงในความสัมพันธ์ของคลาส
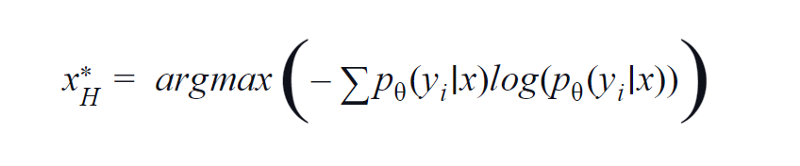
สมการเอนโทรปี รูปภาพโดย Author
ดังนั้น การเพิ่มสมการข้างต้นให้ได้มากที่สุดจะได้ภาพตัวอย่างซึ่งตัวแบบมีความไม่แน่นอนสูงหรือมีความมั่นใจน้อยที่สุดในงานจำแนกประเภท
3. แบบสอบถามโดยคณะกรรมการ QBC
เช่นเดียวกับป่าสุ่มใช้ประโยชน์จากการเรียนรู้ทั้งมวล โดยใช้ต้นไม้ตัดสินใจหลายต้น ในทำนองเดียวกัน ความไม่แน่นอนเกี่ยวกับตัวอย่างข้อมูล x ถูกวัดโดยกลุ่มของแบบจำลองต่างๆ (มีไฮเปอร์พารามิเตอร์หรือเมล็ดพืชต่างกัน)
ด้วยเหตุนี้ หากสำหรับรูปภาพที่กำหนด ผลลัพธ์จะแตกต่างกันมากสำหรับรุ่นต่างๆ ซึ่งหมายความว่าโมเดลต่างๆ ไม่สะดวกในการจำแนกรูปภาพนี้ โดยปกติ คะแนนที่น่าจะเป็นไปได้มากที่สุดจากแต่ละโมเดลจะเรียงซ้อนกันในเวกเตอร์ คำนวณเอนโทรปีของเวกเตอร์นี้ อีกครั้ง หากเอนโทรปีสูง รูปภาพจะมีป้ายกำกับและใส่คำอธิบายประกอบเพิ่มเติม
ก้าวไปข้างหน้าหนึ่งก้าว
จนถึงขณะนี้เราได้ใช้ตัวอย่างข้อมูลที่แบบจำลองไม่เพียงพอนั่นเอง แล้วตัวอย่างที่โมเดลมีความแน่นอนอย่างยิ่งหรือให้คะแนนความน่าจะเป็นสูงล่ะ ตอนนี้ ถ้าเราสามารถใช้ตัวอย่างดังกล่าวได้ โมเดลจะปรับปรุงการเรียนรู้เกี่ยวกับคุณลักษณะที่ได้เรียนรู้ไปแล้ว
ด้วยวิธีนี้ จะปรับปรุงประสิทธิภาพโดยการขัดเกลาการเรียนรู้ โดยรวมแล้ว วิศวกรสามารถเก็บตัวอย่างข้อมูลที่มีคะแนนความน่าจะเป็นตั้งแต่ 0.9 ขึ้นไป และสามารถกำหนดป้ายกำกับได้ สามารถใส่คำอธิบายประกอบเพิ่มเติมและป้อนเป็นตัวอย่างการฝึกอบรมได้
แรงจูงใจของวิธีการดังกล่าวคือการปรับปรุงการเรียนรู้ที่มีอยู่ของโมเดลเกี่ยวกับคุณลักษณะต่างๆ ด้วยวิธีนี้ โมเดล ML และวิศวกร ML จะทำงานร่วมกันเพื่อสร้างตัวอย่างข้อมูลที่จะใส่คำอธิบายประกอบอย่างมีประสิทธิภาพ เทคนิคดังกล่าวเรียกว่าการเรียนรู้แบบมีส่วนร่วม
อ่านเพิ่มเติม: ขอบเขตในอนาคตของ AI
บทสรุป
พบว่าการใช้เทคนิคการเรียนรู้เชิงรุก ผู้ปฏิบัติงานสามารถประหยัดเวลาได้ประมาณ 80% ที่ใช้ไปกับการทำคำอธิบายประกอบและการติดฉลาก ข้อได้เปรียบของการเรียนรู้เชิงรุกไม่ได้จำกัดอยู่เพียงเวลาการฝึกอบรมที่ลดลงของแบบจำลองและการใส่คำอธิบายประกอบข้อมูลที่มีประสิทธิภาพเท่านั้น
นอกจากนี้ยังช่วยลดการใส่มากเกินไปที่เกิดขึ้นเนื่องจากการมีอยู่ของตัวอย่างประเภทเดียวจำนวนมากทำให้แบบจำลองมีอคติ
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ