
Yapay Zeka İçin Aktif Öğrenme [Kapsamlı Kılavuz]
Yayınlanan: 2020-12-01Yapay zeka için aktif öğrenmeye genel bakış
Bu yazıda, aktif öğrenmenin temellerini ve Yapay Zeka dünyası ile ilişkisini ele alacağız.
İçindekiler
Tanıtım
Makine öğreniminde denetimli ve denetimsiz öğrenme olmak üzere iki tür öğrenme yöntemi vardır. Denetimli öğrenmede, modele her eğitim örneği için etiketler sağlarız. Model, eğitim veri örneklerinin özelliklerini öğrenir ve bunları karşılık gelen etiketlerine eşler.
Çıktı, belirli bir sınıfa ait bir test örneğinin olasılığıdır. Bununla birlikte, denetimsiz öğrenme, etiket gerektirmez ve model, test örneğini, eğitim süreci sırasında öğrendiği bir model veya eğilime göre sınıflandırır.
Artık denetimli öğrenmede, görüntülere (girdi olarak varsayın) ve açıklamalarına ihtiyaç vardır. Model, resimlere ve açıklamalarına uyacak kadar iyi optimize ederek resimlerden öğrenebilir.
Ancak, pratikte modelin test örneklerinde son derece iyi performans göstermesi için çok sayıda görüntü ve ek açıklamaları gereklidir. Bu sorunu çözmek için birçok araştırmacı tarafından aktif öğrenme kullanılmıştır.

Motivasyon
Çoğu durumda, genellikle milyonlarca veri mevcut olacaktır, ancak bunların tümüne açıklama eklemek mümkün olmayacak ve zaman alıcı olacaktır. Birkaç örnek şunları içerir:
- Uçuş sırasında bir drone tarafından kaydedilen bir video
- Milyonlarca hücre içeren tıbbi bir görüntü
- Trafik ışığı sinyalinden alınan bir CCTV kaydı
Bu tür ağır verilerle başa çıkmak için, açıklama için mevcut tüm verileri bize bildiren ve hangi örneklerin anlamlı olduğunu açıklayan aktif öğrenme kullanılır.
Temel Süreç
Makine öğrenimi mühendisi/Oracle uzmanı, büyük bir etiketlenmemiş veri havuzuna erişebilir. Diyelim ki görev bir kedi ve köpek sınıflandırıcısı oluşturmak. Şimdi, tüm bu veri havuzundan mühendis, modeli verilerin yalnızca %20'si üzerinde eğitmeyi seçer (önce bunları etiketler) ve kalan %80'ini test amacıyla kullanır.
Bu, yuvarlak tabanlı bir yöntemdir. Her yinelemede, sınıflandırma için modele bir test görüntüsü verilir. Model düşük performans gösteriyorsa veya model tarafından atanan olasılık daha düşükse, örneğin 0,6 ise, genel performansı iyileştirmek için modelin bu örnek üzerinde eğitilmesi gerekir. Modelin belirsiz olduğu veya emin olmadığı görüntü, modelin öğrenmesi için daha fazla bilgi içerir.
Bu örnek daha sonra etiketlenir ve eğitim örneği olarak seçilir. Bu yineleme, son test örneğine kadar tekrarlanır. Bu şekilde, açıklama yapmaya değer yeni bir eğitim seti oluşturuyoruz. Model, yeni toplanan seçici eğitim verileri üzerinde eğitilir ve böylece genel eğitim süresini azaltır. Bu, açıklama kümesi bitene kadar tekrarlanır.
Açıklama için resim nasıl seçilir?
Yukarıda bahsedilen yaklaşım, açıklama için bir örnek seçmenin basit bir yoludur. Gerçek uygulamada, bazen ikisinin bir kombinasyonu olmak üzere aşağıdaki iki yöntem kullanılır.
- Belirsizliğe dayalı örnekleme : Modelin belirsiz olduğu veya model tarafından düşük olasılık atanmış görüntüler.
- Çeşitliliğe dayalı örnekleme : Çeşitliliği temsil eden görüntüler, yani uzamsal temsil, spektral temsil, sınıf temsili vb. Modelin öğreneceği daha fazla çeşitlilik, daha fazla mevcut bilgi.
Girdi olarak bir veri örneğini (görüntü) alan ve bir öncelik/sıralama puanı döndüren bir işlev, Toplama işlevi olarak adlandırılır.
Okuyun: Yapay Zekadaki Zorluklar
Ortak Edinme İşlevleri
1. En İyi-İkinci En İyi (BvSB)
Bu yöntem çoğunlukla birkaç sınıf için kullanılır (3 ila 5). Kullanılan formül, en yüksek ve ikinci en yüksek sınıfın olasılık değerlerini dikkate alır. y1 ve y2, p modeli tarafından tahmin edilen en yüksek ve ikinci en yüksek olasılık değerlerini gösterir? belirli bir örnek için x.

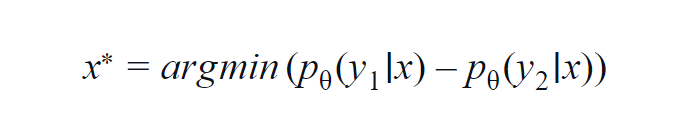
Temel fikir aşağıdaki denklemi en aza indirmektir. Fark ne kadar düşükse, x veri örneğinde yer alan bilgi o kadar fazladır.
Basit bir anlayış için, veri örneğinde yer alan sınıfların köpek, kedi, at ve aslan olduğu bir örnek varsayalım. Modele girdinin bir köpek görüntüsü olduğu ve köpek sınıfının (en olası) çıktı olasılığının 0,6 ve kedi sınıfının (2. en olası) çıktı olasılığının 0,35 olduğu ilk senaryoyu düşünün.
Kalan 0,5, diğer iki sınıf arasında dağıtılır. İkinci senaryoda, aynı girdi için, ilk iki sınıf için çıktı olasılıkları 0,7 ve 0,2'dir. Şimdi iki senaryodan, ikinci senaryoda modelin tahmininden daha emin olduğu sonucunu çıkarabiliriz (0,7–0,2=0,5).
İlk senaryoda, model tahminle ilgili olarak daha belirsizdir (0,6-0,35=0,25). Böylece yukarıdaki denklemi en aza indirerek, açıklama yapmaya değer bir veri örneği toplayabiliriz.
2. Entropi
BvSB daha az sınıf için uygundur. Bununla birlikte, çok sayıda sınıfla, entropi bir edinme işlevi olarak kullanılır. Bunun nedeni, aşağıdaki formül, kalan sınıflardaki bilgileri dikkate almaktadır. Entropi, kirlilik veya dengesizliğin bir ölçüsüdür. Makine öğrenimi açısından, bir modelin belirsizliğinin bir ölçüsü olarak tanımlanabilir. Yüksek bir entropi değeri, sınıf ilişkisindeki yüksek belirsizliğin bir göstergesidir.
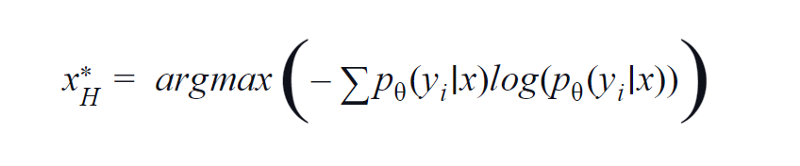
Entropi denklemi, Yazara göre resim
Bu nedenle, yukarıdaki denklemi maksimize etmek, bize, modelin sınıflandırma görevinde oldukça belirsiz veya en az güvenilir olduğu bir görüntü örneğini verecektir.
3. QBC komitesinin sorgulaması
Tıpkı rastgele ormanın topluluk öğrenmesini kullanması gibi - birkaç karar ağacından yararlanarak. Benzer şekilde, bir veri örneği x hakkındaki belirsizlik, farklı modellerden oluşan bir topluluk (farklı hiperparametrelere veya tohumlara sahip) üzerinden ölçülür.
Bununla, belirli bir görüntü için çıktı farklı modeller için çok değişiyorsa, bu, modellerin bu görüntüyü sınıflandırmada rahat olmadığı anlamına gelir. Genellikle, her modelden elde edilen en olası puan bir vektörde istiflenir. Bu vektörün entropisi hesaplanır. Yine, entropi yüksekse, görüntü daha fazla etiketlenir ve açıklama eklenir.
Bir adım önde
Şimdiye kadar, modelin yeterince emin olmadığı veri örneklerini kullandık. Ancak, modelin son derece emin olduğu veya yüksek olasılık puanı atadığı örnekler ne olacak? Şimdi, eğer bu tür örnekleri kullanabilirsek, o zaman model, zaten öğrendiği özellikler hakkında öğrenmesini geliştirir.
Bu sayede öğrenmesini parlatarak performansını artırır. Sonuç olarak, mühendis 0,9 ve üzeri olasılık puanına sahip veri örneklerini alabilir ve buna bir etiket atayabilir. Bu, daha fazla açıklama eklenebilir ve bir eğitim örneği olarak beslenebilir.
Böyle bir yöntemin amacı, modelin özellikler hakkında mevcut öğrenmesini iyileştirmektir. Bu şekilde, ML modeli ve ML mühendisi, açıklama eklenecek veri örneklerini etkili bir şekilde ortaya çıkarmak için birbirleriyle işbirliği yapar. Böyle bir tekniğe işbirlikli öğrenme denir.
Ayrıca Okuyun: Yapay Zekanın Gelecekteki Kapsamı
Çözüm
Aktif öğrenme tekniklerini kullanarak, uygulayıcıların, aksi halde açıklama ve etiketleme için harcadıkları zamanın yaklaşık %80'ini kurtardıkları bulunmuştur. Aktif öğrenmenin avantajı, yalnızca modelin eğitim süresinin azalması ve verimli veri açıklaması ile sınırlı değildir.
Aynı zamanda, modeli taraflı hale getiren tek tipte çok sayıda örneğin varlığından dolayı oluşan fazla uyumu da azaltır.
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT- sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka PG Diplomasına göz atın. B Mezun statüsü, 5+ pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.