
Aktives Lernen für künstliche Intelligenz [Umfassender Leitfaden]
Veröffentlicht: 2020-12-01Überblick über aktives Lernen für künstliche Intelligenz
In diesem Artikel behandeln wir die Grundlagen des aktiven Lernens und seine Relevanz in der Welt der künstlichen Intelligenz.
Inhaltsverzeichnis
Einführung
Beim maschinellen Lernen gibt es zwei Arten von Lernmethoden – überwachtes und unüberwachtes Lernen. Beim überwachten Lernen versehen wir das Modell mit Labels für jedes Trainingsbeispiel. Das Modell lernt die Merkmale der Trainingsdatenbeispiele und ordnet sie den entsprechenden Bezeichnungen zu.
Die Ausgabe ist eine Wahrscheinlichkeit dafür, dass eine Testprobe zu einer bestimmten Klasse gehört. Unüberwachtes Lernen erfordert jedoch keine Bezeichnungen, und das Modell klassifiziert die Testprobe auf der Grundlage eines Musters oder Trends, das es während des Trainingsprozesses gelernt hat.
Beim überwachten Lernen werden nun Bilder (als Eingabe angenommen) und ihre Anmerkungen benötigt. Das Modell kann von den Bildern lernen, indem es gut genug optimiert, um zu den Bildern und ihrer Anmerkung zu passen.
Aber damit das Modell auf Testmustern praktisch sehr gut funktioniert, ist eine Fülle von Bildern und deren Anmerkungen erforderlich. Um dieses Problem zu lösen, wurde von vielen Forschern aktives Lernen eingesetzt.

Motivation
In vielen Fällen sind in der Regel Millionen von Daten verfügbar, aber es wäre undurchführbar und zeitaufwändig, alle zu kommentieren. Einige Beispiele sind:
- Ein Video, das von einer Drohne während ihres Fluges aufgenommen wurde
- Ein medizinisches Bild, das Millionen von Zellen enthält
- Eine CCTV-Aufnahme von einem Ampelsignal
Um mit solch umfangreichen Daten umzugehen, wird aktives Lernen eingesetzt, das uns aus allen verfügbaren Daten für die Annotation sagt, welche Proben sinnvoll sind.
Grundlegender Prozess
Der ML-Ingenieur/Oracle-Spezialist hat Zugriff auf einen großen Pool an unbeschrifteten Daten. Angenommen, die Aufgabe besteht darin, einen Katze-und-Hund-Klassifikator zu bauen. Aus diesem gesamten Datenpool entscheidet sich der Ingenieur nun dafür, das Modell mit nur 20 % der Daten zu trainieren (kennzeichnet sie zuerst) und verwendet die restlichen 80 % für Testzwecke.
Dies ist eine rundenbasierte Methode. In jeder Iteration wird dem Modell ein Testbild zur Klassifizierung gegeben. Wenn das Modell schlecht abschneidet oder wenn die vom Modell zugewiesene Wahrscheinlichkeit geringer ist, z. B. 0,6, muss das Modell mit dieser Stichprobe trainiert werden, um die Gesamtleistung zu verbessern. Das Bild, bei dem sich das Modell unsicher oder nicht sicher ist, enthält weitere Informationen, die das Modell lernen kann.
Dieses Beispiel wird dann gekennzeichnet und als Trainingsbeispiel ausgewählt. Diese Iteration wird bis zum letzten Testmuster wiederholt. Auf diese Weise stellen wir ein neues Trainingsset zusammen, das es wert ist, kommentiert zu werden. Das Modell wird mit den neu gesammelten selektiven Trainingsdaten trainiert, wodurch die Gesamttrainingszeit reduziert wird. Dies wird wiederholt, bis der Anmerkungssatz beendet ist.
Wie wähle ich das Bild für die Anmerkung aus?
Der oben erwähnte Ansatz ist nur eine einfache Möglichkeit, ein Beispiel für die Annotation auszuwählen. In der Praxis werden die beiden folgenden Methoden verwendet, manchmal auch eine Kombination aus beiden.
- Stichproben basierend auf Ungewissheit : Bilder, bei denen das Modell unsicher ist, oder Bilder, denen vom Modell eine geringe Wahrscheinlichkeit zugewiesen wurde.
- Auf Diversität basierendes Sampling : Bilder, die die Diversität darstellen, d. h. Variationen in der räumlichen Darstellung, spektralen Darstellung, Klassendarstellung und so weiter. Mehr Vielfalt, mehr verfügbare Informationen, die das Modell lernen kann.
Eine Funktion, die ein Datenmuster (Bild) als Eingabe verwendet und eine Prioritäts-/Rangordnungspunktzahl zurückgibt, wird als Erfassungsfunktion bezeichnet.
Lesen Sie: Herausforderungen in der KI
Allgemeine Erfassungsfunktionen
1. Bester gegen Zweitbester (BvSB)
Diese Methode wird hauptsächlich für wenige Klassen (3 bis 5) verwendet. Die verwendete Formel berücksichtigt die Wahrscheinlichkeitswerte der höchsten und der zweithöchsten Klasse. y1 und y2 geben die höchsten und zweithöchsten vom Modell vorhergesagten Wahrscheinlichkeitswerte an p? für eine gegebene Probe x.

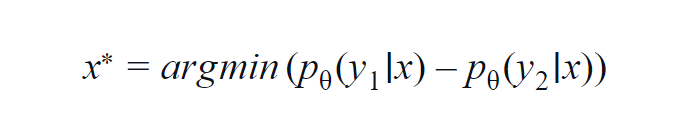
Die Grundidee besteht darin, die folgende Gleichung zu minimieren. Je geringer die Differenz, desto mehr Informationen enthält die Datenprobe x.
Stellen Sie sich zum einfachen Verständnis ein Beispiel vor, bei dem die an der Datenstichprobe beteiligten Klassen Hund, Katze, Pferd und Löwe sind. Betrachten Sie das erste Szenario, in dem die Eingabe in das Modell ein Hundebild ist und die Ausgabewahrscheinlichkeit der Hundeklasse (höchstwahrscheinlich) 0,6 und der Katzenklasse (zweitwahrscheinlichste) 0,35 beträgt.
Die restlichen 0,5 werden auf die beiden anderen Klassen verteilt. Im zweiten Szenario betragen für die gleiche Eingabe die Ausgabewahrscheinlichkeiten für die beiden obersten Klassen 0,7 und 0,2. Aus den beiden Szenarien können wir nun schließen, dass das Modell im zweiten Szenario sicherer in Bezug auf seine Vorhersage ist (0,7–0,2 = 0,5).
Im ersten Szenario ist das Modell bezüglich der Vorhersage unsicherer (0,6–0,35=0,25). Indem wir die obige Gleichung minimieren, können wir eine Datenprobe sammeln, die es wert ist, kommentiert zu werden.
2. Entropie
BvSB eignet sich für weniger Klassen. Bei einer großen Anzahl von Klassen wird jedoch die Entropie als Erfassungsfunktion verwendet. Der Grund dafür ist, dass die folgende Formel die Informationen in den verbleibenden Klassen berücksichtigt. Entropie ist ein Maß für Unreinheit oder Ungleichgewicht. In Bezug auf maschinelles Lernen kann es als Maß für die Unsicherheit eines Modells definiert werden. Ein hoher Entropiewert ist ein Hinweis auf eine hohe Unsicherheit in der Klassenzugehörigkeit.
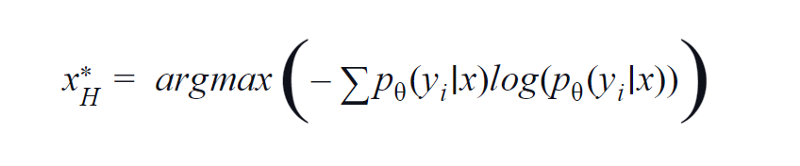
Entropiegleichung, Bild vom Autor
Daher wird uns die Maximierung der obigen Gleichung eine Bildprobe liefern, für die das Modell in Bezug auf die Klassifizierungsaufgabe höchst unsicher oder am wenigsten sicher ist.
3. Anfrage des Ausschusses QBC
Genauso wie Random Forest Ensemble-Lernen nutzt – unter Verwendung mehrerer Entscheidungsbäume. In ähnlicher Weise wird die Unsicherheit über eine Datenprobe x über ein Ensemble unterschiedlicher Modelle (mit unterschiedlichen Hyperparametern oder Startwerten) gemessen.
Wenn also die Ausgabe für ein bestimmtes Bild für verschiedene Modelle stark variiert, bedeutet dies, dass die Modelle dieses Bild nicht gut klassifizieren können. Üblicherweise wird die wahrscheinlichste Punktzahl von jedem Modell in einem Vektor gestapelt. Die Entropie dieses Vektors wird berechnet. Wenn die Entropie hoch ist, wird das Bild wiederum weiter beschriftet und kommentiert.
Einen Schritt voraus
Bisher haben wir Datenstichproben verwendet, für die das Modell nicht sicher genug ist. Aber was ist mit den Stichproben, für die das Modell extrem sicher ist oder eine hohe Wahrscheinlichkeitsbewertung zuweist? Wenn wir nun solche Beispiele verwenden können, verbessert das Modell sein Lernen über die Merkmale, die es bereits gelernt hat.
Auf diese Weise verbessert es seine Leistung, indem es sein Lernen aufpoliert. Alles in allem kann der Ingenieur Datenproben mit einem Wahrscheinlichkeitswert von 0,9 und höher nehmen und diesen ein Label zuweisen. Dies kann weiter kommentiert und als Trainingsbeispiel gefüttert werden.
Das Motiv eines solchen Verfahrens besteht darin, das vorhandene Lernen des Modells über die Merkmale zu verbessern. Auf diese Weise arbeiten das ML-Modell und der ML-Ingenieur zusammen, um effektiv zu kommentierende Datenbeispiele zu erstellen. Eine solche Technik wird als kooperatives Lernen bezeichnet.
Lesen Sie auch: Zukünftiger Umfang der KI
Fazit
Es wurde festgestellt, dass Praktiker durch die Verwendung aktiver Lerntechniken etwa 80 % ihrer Zeit einsparen, die sonst für Anmerkungen und Beschriftungen aufgewendet wurde. Der Vorteil des aktiven Lernens beschränkt sich nicht nur auf die verkürzte Trainingszeit des Modells und die effiziente Datenannotation.
Es reduziert auch eine Überanpassung, die aufgrund des Vorhandenseins einer großen Anzahl von Stichproben eines einzelnen Typs auftritt, wodurch das Modell verzerrt wird.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.