
Aktywne uczenie się na rzecz sztucznej inteligencji [Kompleksowy przewodnik]
Opublikowany: 2020-12-01Przegląd aktywnego uczenia się dla sztucznej inteligencji
W tym artykule omówimy podstawy aktywnego uczenia się i jego znaczenie w świecie sztucznej inteligencji.
Spis treści
Wstęp
W uczeniu maszynowym istnieją dwa rodzaje metod uczenia — uczenie nadzorowane i nienadzorowane. W uczeniu nadzorowanym dostarczamy model z etykietami dla każdej próbki szkoleniowej. Model uczy się funkcji próbek danych uczących i mapuje je na odpowiadające im etykiety.
Wynikiem jest prawdopodobieństwo przynależności próbki testowej do określonej klasy. Jednak uczenie nienadzorowane nie wymaga etykiet, a model klasyfikuje próbkę testową na podstawie pewnego wzorca lub trendu, którego nauczył się podczas procesu uczenia.
Teraz w nadzorowanym uczeniu się potrzebne są obrazy (przyjmowane jako dane wejściowe) i ich adnotacje. Model może uczyć się na podstawie obrazów, optymalizując je na tyle dobrze, aby pasowały do obrazów i ich adnotacji.
Jednak praktycznie, aby model działał wyjątkowo dobrze na próbkach testowych, wymagany jest mnóstwo obrazów i jego adnotacji. Aby rozwiązać ten problem, wielu badaczy zastosowało aktywne uczenie się.

Motywacja
W wielu przypadkach dostępne są zwykle miliony danych, ale adnotacja do nich wszystkich byłaby niewykonalna i czasochłonna. Kilka przykładów to:
- Film nagrany przez drona podczas lotu
- Obraz medyczny zawierający miliony komórek
- Nagranie CCTV z sygnalizacji świetlnej
Aby poradzić sobie z tak dużymi danymi, stosuje się aktywne uczenie, które mówi nam o wszystkich dostępnych danych do adnotacji, zaznaczając, które próbki mają sens.
Podstawowy proces
Inżynier ML/specjalista Oracle ma dostęp do dużej puli nieoznakowanych danych. Powiedzmy, że zadaniem jest zbudowanie klasyfikatora kota i psa. Teraz z tej całej puli danych inżynier wybiera trenowanie modelu tylko na 20% danych (oznacza je jako pierwsze) i wykorzystuje pozostałe 80% do celów testowych.
Jest to metoda oparta na rundach. W każdej iteracji do modelu przekazywany jest obraz testowy do klasyfikacji. Jeśli model działa słabo lub jeśli prawdopodobieństwo przypisane przez model jest mniejsze, powiedzmy 0,6, model musi zostać przeszkolony na tej próbce, aby poprawić ogólną wydajność. Obraz, w przypadku którego model jest niepewny lub niepewny, zawiera więcej informacji do nauczenia się modelu.
Ta próbka jest następnie oznaczana i wybierana jako próbka ucząca. Ta iteracja jest powtarzana aż do ostatniej próbki testowej. W ten sposób montujemy nowy zestaw treningowy, który warto opisać. Model jest uczony na nowo zebranych selektywnych danych uczących, co skraca ogólny czas uczenia. Powtarza się to aż do zakończenia zestawu adnotacji.
Jak wybrać obraz do adnotacji?
Powyższe podejście to tylko jeden prosty sposób wyboru próbki do adnotacji. W praktyce stosuje się następujące dwie metody, czasem ich kombinację.
- Próbkowanie oparte na niepewności : obrazy, co do których model jest niepewny, lub obrazy, którym model przypisał niskie prawdopodobieństwo.
- Próbkowanie oparte na różnorodności : obrazy, które reprezentują różnorodność, to znaczy zmienność reprezentacji przestrzennej, reprezentacji spektralnej, reprezentacji klasy i tak dalej. Więcej różnorodności, więcej dostępnych informacji dla modelu do nauki.
Funkcja, która pobiera próbkę danych (obraz) jako dane wejściowe i zwraca wynik priorytetu/rankingu, jest określana jako funkcja pozyskiwania.
Przeczytaj: Wyzwania w AI
Wspólne funkcje akwizycji
1. Najlepszy kontra drugi najlepszy (BvSB)
Ta metoda jest najczęściej używana w kilku klasach (3 do 5). Zastosowana formuła uwzględnia wartości prawdopodobieństwa najwyższej i drugiej najwyższej klasy. y1 i y2 wskazują najwyższą i drugą pod względem wartości wartość prawdopodobieństwa przewidywaną przez model p? dla danej próbki x.

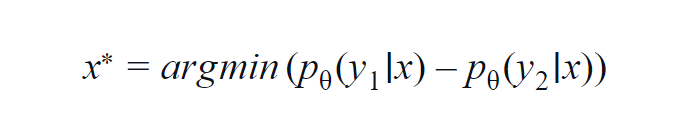
Podstawową ideą jest zminimalizowanie poniższego równania. Im mniejsza różnica, tym więcej informacji zawiera próbka danych x.
Aby ułatwić zrozumienie, załóżmy przykład, w którym klasy biorące udział w próbce danych to pies, kot, koń i lew. Rozważmy pierwszy scenariusz, w którym dane wejściowe do modelu to obraz psa, a prawdopodobieństwo wyjścia klasy psa (najbardziej prawdopodobne) wynosi 0,6, a klasy kota (2. najbardziej prawdopodobne) wynosi 0,35.
Pozostałe 0,5 jest rozdzielone między dwie pozostałe klasy. W drugim scenariuszu, dla tego samego wejścia, prawdopodobieństwa wyjścia dla dwóch najwyższych klas wynoszą 0,7 i 0,2. Teraz z tych dwóch scenariuszy możemy wywnioskować, że w drugim scenariuszu model jest bardziej pewny swoich przewidywań (0,7–0,2=0,5).
W pierwszym scenariuszu model jest bardziej niepewny co do predykcji (0,6–0,35=0,25). W ten sposób minimalizując powyższe równanie, możemy zebrać próbkę danych, którą warto opisać.
2. Entropia
BvSB jest odpowiedni dla mniejszej liczby klas. Jednak przy dużej liczbie klas entropia jest wykorzystywana jako funkcja akwizycji. Poniższy wzór uwzględnia informacje w pozostałych klasach. Entropia jest miarą nieczystości lub braku równowagi. W aspekcie uczenia maszynowego można go zdefiniować jako miarę niepewności modelu. Wysoka wartość entropii wskazuje na dużą niepewność w powiązaniu klas.
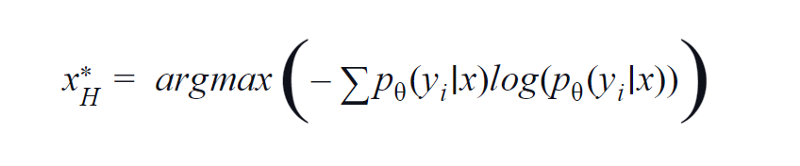
Równanie entropii, obraz autora
Dlatego maksymalizacja powyższego równania da nam próbkę obrazu, dla której model jest wysoce niepewny lub najmniej pewny w zadaniu klasyfikacji.
3. Zapytanie przez komisję QBC
Podobnie jak losowy las wykorzystuje uczenie zespołowe — wykorzystuje kilka drzew decyzyjnych. Podobnie niepewność dotycząca próbki danych x jest mierzona na zestawie różnych modeli (mających różne hiperparametry lub nasiona).
Dzięki temu, jeśli dla danego obrazu wynik jest bardzo różny dla różnych modeli, oznacza to, że modele nie są wygodne w klasyfikowaniu tego obrazu. Zwykle najbardziej prawdopodobny wynik z każdego modelu jest ułożony w wektorze. Obliczana jest entropia tego wektora. Ponownie, jeśli entropia jest wysoka, obraz jest dalej etykietowany i opatrywany adnotacjami.
O krok do przodu
Do tej pory korzystaliśmy z próbek danych, dla których model nie jest wystarczająco pewny. Ale co z próbkami, dla których model jest niezwykle pewny lub przypisuje wynik o wysokim prawdopodobieństwie? Teraz, jeśli możemy korzystać z takich próbek, to model usprawnia poznawanie cech, które już poznał.
W ten sposób poprawia swoją wydajność poprzez doszlifowanie jej uczenia się. Ogólnie rzecz biorąc, inżynier może pobrać próbki danych, które mają wynik prawdopodobieństwa równy 0,9 i więcej i przypisać im etykietę. Można to dalej opisywać i podawać jako próbkę szkoleniową.
Motywem takiej metody jest poprawa dotychczasowej wiedzy modelu o cechach. W ten sposób model ML i inżynier ML współpracują ze sobą, aby skutecznie wypracować próbki danych, które mają być opatrzone adnotacjami. Taka technika nazywana jest uczeniem się kooperatywnym.
Przeczytaj także: Przyszły zakres AI
Wniosek
Stwierdzono, że stosując techniki aktywnego uczenia się, praktycy oszczędzają około 80% czasu, który w innym przypadku byłby spędzany na adnotacjach i etykietach. Zaleta aktywnego uczenia się nie ogranicza się tylko do skrócenia czasu uczenia modelu i efektywnej adnotacji danych.
Zmniejsza również nadmierne dopasowanie, które występuje z powodu obecności dużej liczby próbek jednego typu, co powoduje, że model jest tendencyjny.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.