
التعلم النشط للذكاء الاصطناعي [دليل شامل]
نشرت: 2020-12-01نظرة عامة على التعلم النشط للذكاء الاصطناعي
في هذه المقالة ، سوف نغطي أساسيات التعلم النشط وأهميته في عالم الذكاء الاصطناعي.
جدول المحتويات
مقدمة
في التعلم الآلي ، يوجد نوعان من أساليب التعلم - التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف. في التعلم الخاضع للإشراف ، نقوم بتزويد النموذج بملصقات لكل عينة تدريب. يتعلم النموذج ميزات عينات بيانات التدريب ويرسمها على الملصقات المقابلة لها.
الناتج هو احتمال لعينة اختبار تنتمي إلى فئة معينة. ومع ذلك ، لا يتطلب التعلم غير الخاضع للإشراف أي تسميات ويصنف النموذج عينة الاختبار بناءً على نمط أو اتجاه ما تعلمه أثناء عملية التدريب.
الآن في التعلم الخاضع للإشراف ، هناك حاجة للصور (افترض كمدخلات) وشروحها. يمكن للنموذج التعلم من الصور عن طريق التحسين الجيد بما يكفي لملاءمة الصور والتعليقات التوضيحية الخاصة بها.
ولكن من الناحية العملية ، لكي يعمل النموذج جيدًا للغاية في عينات الاختبار ، يلزم وجود عدد كبير من الصور وشروحه. لحل هذه المشكلة ، تم استخدام التعلم النشط من قبل العديد من الباحثين.

تحفيز
في كثير من الحالات ، عادة ما تكون هناك ملايين البيانات المتاحة ، ولكن وضع تعليقات توضيحية عليها جميعًا سيكون غير عملي ويستغرق وقتًا طويلاً. بعض الأمثلة تشمل:
- فيديو سجلته طائرة بدون طيار أثناء تحليقها
- صورة طبية تحتوي على ملايين الخلايا
- تسجيل CCTV من إشارة ضوئية
للتعامل مع مثل هذه البيانات الثقيلة ، يتم استخدام التعلم النشط الذي يخبرنا عن جميع البيانات المتاحة للتعليق التوضيحي ، مع توضيح العينات التي تكون منطقية.
العملية الأساسية
يتمتع مهندس ML / متخصص Oracle بإمكانية الوصول إلى مجموعة كبيرة من البيانات غير المسماة. لنفترض أن المهمة هي بناء مصنف القطط والكلاب. الآن من بين هذه المجموعة الكاملة من البيانات ، يختار المهندس تدريب النموذج على 20٪ فقط من البيانات (يسميها أولاً) ويستخدم الباقي 80٪ لغرض الاختبار.
هذه طريقة مستديرة. في كل تكرار ، يتم إعطاء صورة اختبارية للنموذج من أجل التصنيف. إذا كان أداء النموذج ضعيفًا ، أو إذا كان الاحتمال المحدد بواسطة النموذج أقل ، على سبيل المثال 0.6 ، فإن النموذج يحتاج إلى التدريب على هذه العينة لتحسين الأداء العام. تحتوي الصورة التي يكون النموذج فيها غير مؤكد أو غير واثق على مزيد من المعلومات للنموذج ليتعلمها.
ثم يتم تصنيف هذه العينة واختيارها كعينة تدريب. يتكرر هذا التكرار حتى آخر عينة اختبار. بهذه الطريقة ، نقوم بتجميع مجموعة تدريب جديدة تستحق التعليق التوضيحي. يتم تدريب النموذج على بيانات التدريب الانتقائية التي تم جمعها حديثًا وبالتالي تقليل وقت التدريب الإجمالي. يتكرر هذا حتى تنتهي مجموعة التعليقات التوضيحية.
كيف تختار الصورة للتعليق؟
النهج المذكور أعلاه هو مجرد طريقة واحدة بسيطة لاختيار عينة للتعليق التوضيحي. في الممارسة الواقعية ، يتم استخدام الطريقتين التاليتين ، وأحيانًا مزيج من الطريقتين.
- أخذ العينات على أساس عدم اليقين : الصور التي النموذج غير مؤكد حولها أو الصور التي تم تعيين احتمالية منخفضة بواسطة النموذج.
- أخذ العينات على أساس التنوع : الصور التي تمثل التنوع ، أي التباين في التمثيل المكاني ، والتمثيل الطيفي ، والتمثيل الطبقي ، وما إلى ذلك. المزيد من التنوع ، المزيد من المعلومات المتاحة للنموذج للتعلم.
تسمى الوظيفة التي تأخذ عينة بيانات (صورة) كمدخلات وترجع درجة الأولوية / التصنيف كوظيفة اكتساب.

اقرأ: التحديات في الذكاء الاصطناعي
وظائف الاستحواذ المشتركة
1. الأفضل مقابل ثاني أفضل (BvSB)
تستخدم هذه الطريقة في الغالب لفئات قليلة (من 3 إلى 5). تأخذ الصيغة المستخدمة في الاعتبار القيم الاحتمالية لأعلى وثاني أعلى فئة. تشير y1 و y2 إلى أعلى وثاني أعلى قيم احتمالية تنبأ بها النموذج p؟ لعينة معينة x.
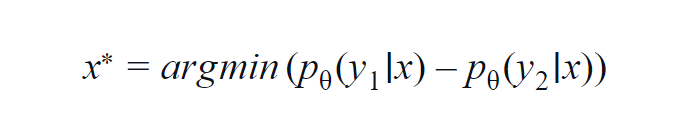
الفكرة الأساسية هي تقليل المعادلة أدناه. كلما انخفض الاختلاف ، زادت المعلومات الموجودة في عينة البيانات x.
لفهم بسيط ، افترض مثالًا حيث تكون الفئات المشاركة في عينة البيانات هي الكلب والقط والحصان والأسد. ضع في اعتبارك السيناريو الأول حيث يكون الإدخال إلى النموذج عبارة عن صورة كلب ويكون احتمال إخراج فئة الكلب (الأكثر احتمالًا) هو 0.6 وفئة القط (ثانيًا على الأرجح) هو 0.35.
يتم توزيع 0.5 المتبقية بين الفئتين الأخريين. في السيناريو الثاني ، لنفس المدخلات ، تكون احتمالات المخرجات لأعلى فئتين 0.7 و 0.2. الآن من السيناريوهين ، يمكننا أن نستنتج أنه في السيناريو الثاني ، يكون النموذج أكثر ثقة بشأن توقعه (0.7–0.2 = 0.5).
في السيناريو الأول ، النموذج غير مؤكد فيما يتعلق بالتنبؤ (0.6-0.35 = 0.25). من خلال تصغير المعادلة أعلاه ، يمكننا جمع عينة بيانات تستحق التعليق.
2. الانتروبيا
BvSB مناسب لفئات أقل. ومع ذلك ، مع وجود عدد كبير من الفئات ، يتم استخدام الانتروبيا كوظيفة اكتساب. السبب هو أن الصيغة أدناه تأخذ في الاعتبار المعلومات الموجودة في الفئات المتبقية. الانتروبيا هو مقياس للشوائب أو عدم التوازن. من حيث التعلم الآلي ، يمكن تعريفه على أنه مقياس لعدم اليقين في النموذج. تعتبر القيمة العالية للإنتروبيا مؤشرًا على عدم اليقين الكبير في ارتباط الطبقة.
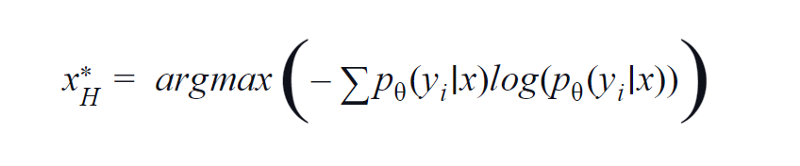
معادلة الانتروبيا ، صورة المؤلف
لذلك ، سيؤدي تعظيم المعادلة أعلاه إلى منحنا عينة صورة يكون النموذج فيها غير مؤكد بدرجة كبيرة أو أقل ثقة في مهمة التصنيف.
3. الاستعلام من قبل لجنة QBC
تمامًا مثل Random Forest ، تستفيد من التعلم الجماعي - باستخدام العديد من أشجار القرار. وبالمثل ، يتم قياس عدم اليقين بشأن عينة البيانات x عبر مجموعة من النماذج المختلفة (لها معلمات أو بذور مختلفة).
مع هذا ، إذا كان الإخراج لصورة معينة يختلف كثيرًا بالنسبة لنماذج مختلفة ، فهذا يعني أن النماذج ليست مريحة في تصنيف هذه الصورة. عادةً ما تكون النتيجة الأكثر احتمالية من كل نموذج مكدسة في متجه. يتم حساب إنتروبيا هذا المتجه. مرة أخرى ، إذا كانت الأنتروبيا عالية ، فسيتم تصنيف الصورة وإضافة تعليقات توضيحية إليها.
خطوة للأمام
حتى الآن ، استخدمنا عينات بيانات لم يكن النموذج مؤكدًا بدرجة كافية. ولكن ماذا عن العينات التي يكون النموذج مؤكدًا للغاية لها أو يمنح درجة احتمالية عالية؟ الآن ، إذا تمكنا من استخدام مثل هذه العينات ، فإن النموذج يحسن معرفته بالميزات التي تعلمها بالفعل.
بهذه الطريقة ، فإنه يحسن أدائه من خلال صقل تعلمه. بشكل عام ، يمكن للمهندس أن يأخذ عينات من البيانات ذات درجة احتمالية تبلغ 0.9 وما فوق ويمكنه تعيين ملصق لها. يمكن إضافة تعليق توضيحي لهذا الأمر وتغذيته كعينة تدريب.
الدافع من مثل هذه الطريقة هو تحسين التعلم الحالي للنموذج حول الميزات. بهذه الطريقة ، يتعاون نموذج ML ومهندس ML مع بعضهما البعض للتوصل بشكل فعال إلى عينات البيانات التي سيتم شرحها. مثل هذا الأسلوب يسمى التعلم التعاوني.
اقرأ أيضًا: نطاق المستقبل للذكاء الاصطناعي
خاتمة
لقد وجد أنه باستخدام تقنيات التعلم النشط ، يوفر الممارسون حوالي 80 ٪ من وقتهم الذي كان يقضونه في التعليقات التوضيحية ووضع العلامات. لا تقتصر ميزة التعلم النشط على تقليل وقت تدريب النموذج وكفاءة شرح البيانات.
كما أنه يقلل من فرط التخصيص الذي يحدث بسبب وجود عدد كبير من العينات من نوع واحد مما يجعل النموذج متحيزًا.
إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع دبلوم PG في IIIT-B & upGrad في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT- حالة الخريجين B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع أفضل الشركات.