
Активное обучение для искусственного интеллекта [Полное руководство]
Опубликовано: 2020-12-01Обзор активного обучения для искусственного интеллекта
В этой статье мы рассмотрим основы активного обучения и его значение в мире искусственного интеллекта.
Оглавление
Введение
В машинном обучении существует два типа методов обучения — контролируемое и неконтролируемое обучение. В обучении с учителем мы предоставляем модели метки для каждой обучающей выборки. Модель изучает особенности образцов обучающих данных и сопоставляет их с соответствующими метками.
Результатом является вероятность того, что тестовая выборка принадлежит определенному классу. Однако неконтролируемое обучение не требует меток, и модель классифицирует тестовую выборку на основе некоторого шаблона или тенденции, которую она изучила в процессе обучения.
Теперь в обучении с учителем необходимы изображения (предположим, что они являются входными данными) и их аннотации. Модель может учиться на изображениях, достаточно хорошо оптимизируя их, чтобы они соответствовали изображениям и их аннотациям.
Но практически для того, чтобы модель работала очень хорошо на тестовых образцах, требуется множество изображений и их аннотаций. Для решения этой проблемы многие исследователи использовали активное обучение.

Мотивация
Во многих случаях, как правило, будут доступны миллионы данных, но аннотирование их всех будет неосуществимым и потребует много времени. Несколько примеров включают:
- Видео, снятое дроном во время его полета
- Медицинское изображение, содержащее миллионы клеток
- Запись видеонаблюдения с сигнала светофора
Чтобы иметь дело с такими тяжелыми данными, используется активное обучение, которое сообщает нам обо всех доступных данных для аннотирования, аннотируя, какие образцы имеют смысл.
Основной процесс
Инженер по машинному обучению/специалист по Oracle имеет доступ к большому пулу неразмеченных данных. Скажем, задача состоит в том, чтобы построить классификатор кошек и собак. Теперь из всего этого пула данных инженер выбирает для обучения модели только 20% данных (сначала помечает их), а остальные 80% использует для целей тестирования.
Это круговой метод. На каждой итерации тестовое изображение передается модели для классификации. Если модель работает плохо или вероятность, приписываемая моделью, меньше, скажем, 0,6, то модель необходимо обучить на этом образце, чтобы улучшить общую производительность. Изображение, для которого модель неопределенна или неуверенна, содержит больше информации для изучения модели.
Затем эта выборка помечается и выбирается в качестве обучающей выборки. Эта итерация повторяется до последнего тестового образца. Таким образом, мы собираем новую обучающую выборку, которую стоит аннотировать. Модель обучается на недавно собранных данных выборочного обучения, тем самым сокращая общее время обучения. Это повторяется до тех пор, пока набор аннотаций не закончится.
Как выбрать изображение для аннотации?
Вышеупомянутый подход является лишь одним из простых способов выбора образца для аннотации. В реальной практике используются следующие два метода, иногда их комбинация.
- Выборка на основе неопределенности : изображения, в отношении которых модель не уверена, или изображения, которым модель присвоила низкую вероятность.
- Выборка на основе разнообразия : изображения, представляющие разнообразие, то есть вариации в пространственном представлении, спектральном представлении, представлении классов и т. д. Больше разнообразия, больше доступной информации для изучения модели.
Функция, которая принимает образец данных (изображение) в качестве входных данных и возвращает оценку приоритета/рейтинга, называется функцией сбора данных.
Читайте: Проблемы в ИИ
Общие функции сбора данных
1. Лучший против второго лучшего (BvSB)
Этот метод в основном используется для нескольких классов (от 3 до 5). В используемой формуле учитываются значения вероятности высшего и второго по величине класса. y1 и y2 указывают самое высокое и второе по величине значение вероятности, предсказанное моделью p? для данного образца х.

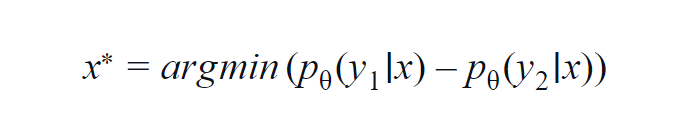
Основная идея состоит в том, чтобы минимизировать приведенное ниже уравнение. Чем меньше разница, тем больше информации содержится в выборке данных x.
Для простоты предположим пример, в котором классы, участвующие в выборке данных, — собака, кошка, лошадь и лев. Рассмотрим первый сценарий, в котором входными данными для модели является изображение собаки, а выходная вероятность класса собаки (наиболее вероятная) равна 0,6, а класса кошки (вторая наиболее вероятная) равна 0,35.
Оставшиеся 0,5 распределяются между двумя другими классами. Во втором сценарии для тех же входных данных вероятности выхода для двух верхних классов равны 0,7 и 0,2. Теперь из двух сценариев мы можем сделать вывод, что во втором сценарии модель более уверена в своем прогнозе (0,7–0,2 = 0,5).
В первом сценарии модель более неопределенна в отношении прогноза (0,6–0,35 = 0,25). Таким образом, минимизируя приведенное выше уравнение, мы можем собрать выборку данных, которую стоит аннотировать.
2. Энтропия
BvSB подходит для меньшего количества классов. Однако при большом количестве классов в качестве функции приобретения используется энтропия. Причина в том, что приведенная ниже формула учитывает информацию в остальных классах. Энтропия является мерой примеси или дисбаланса. С точки зрения машинного обучения его можно определить как меру неопределенности модели. Высокое значение энтропии указывает на высокую неопределенность в ассоциации классов.
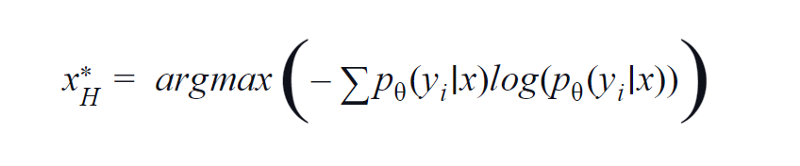
Уравнение энтропии, изображение автора
Следовательно, максимизация приведенного выше уравнения даст нам образец изображения, для которого модель очень неопределенна или наименее уверена в задаче классификации.
3. Запрос комитета QBC
Так же, как в случайном лесу используется ансамблевое обучение — использование нескольких деревьев решений. Точно так же неопределенность выборки данных x измеряется для ансамбля различных моделей (с разными гиперпараметрами или начальными значениями).
При этом, если для данного изображения вывод сильно различается для разных моделей, это означает, что моделям неудобно классифицировать это изображение. Обычно наиболее вероятная оценка каждой модели складывается в вектор. Вычисляется энтропия этого вектора. Опять же, если энтропия высока, изображение дополнительно маркируется и аннотируется.
На шаг впереди
До сих пор мы использовали выборки данных, для которых модель недостаточно надежна. Но как насчет выборок, для которых модель абсолютно уверена или присваивает высокую оценку вероятности? Теперь, если мы сможем использовать такие образцы, то модель улучшит свое изучение уже изученных признаков.
Таким образом, он улучшает свою производительность, совершенствуя свое обучение. В целом, инженер может взять выборки данных с оценкой вероятности 0,9 и выше и присвоить им метку. Это может быть дополнительно аннотировано и подано в качестве обучающей выборки.
Мотив такого метода состоит в том, чтобы улучшить существующие знания модели о функциях. Таким образом, модель ML и инженер ML сотрудничают друг с другом, чтобы эффективно создавать образцы данных, которые необходимо аннотировать. Такой метод называется кооперативным обучением.
Читайте также: Будущие возможности ИИ
Заключение
Было обнаружено, что, используя методы активного обучения, практики экономят около 80% своего времени, которое в противном случае тратилось на аннотирование и маркировку. Преимущество активного обучения не ограничивается только сокращением времени обучения модели и эффективной аннотацией данных.
Это также уменьшает переобучение, возникающее из-за наличия большого количества выборок одного типа, что делает модель необъективной.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.