
Aprendizagem ativa para inteligência artificial [Guia abrangente]
Publicados: 2020-12-01Visão geral do aprendizado ativo para inteligência artificial
Neste artigo, abordaremos os fundamentos da aprendizagem ativa e sua relevância no mundo da Inteligência Artificial.
Índice
Introdução
No aprendizado de máquina, existem dois tipos de métodos de aprendizado – aprendizado supervisionado e não supervisionado. No aprendizado supervisionado, fornecemos ao modelo rótulos para cada amostra de treinamento. O modelo aprende os recursos das amostras de dados de treinamento e os mapeia para seus rótulos correspondentes.
A saída é uma probabilidade de uma amostra de teste pertencente a uma determinada classe. O aprendizado não supervisionado, no entanto, não requer rótulos e o modelo classifica a amostra de teste com base em algum padrão ou tendência que aprendeu durante o processo de treinamento.
Agora, no aprendizado supervisionado, há a necessidade de imagens (assumir como entrada) e suas anotações. O modelo pode aprender com as imagens otimizando o suficiente para ajustar as imagens e suas anotações.
Mas, praticamente para que o modelo tenha um desempenho extremamente bom em amostras de teste, é necessária uma infinidade de imagens e suas anotações. Para resolver este problema, a aprendizagem ativa foi empregada por muitos pesquisadores.

Motivação
Em muitos casos, normalmente haverá milhões de dados disponíveis, mas anotar todos eles seria inviável e demorado. Alguns exemplos incluem:
- Um vídeo gravado por um drone durante seu voo
- Uma imagem médica contendo milhões de células
- Uma gravação CCTV de um sinal de semáforo
Para lidar com dados tão pesados, é empregado o aprendizado ativo que nos informa de todos os dados disponíveis para anotação, anotando quais amostras fazem sentido.
Processo Básico
O engenheiro de ML/especialista da Oracle tem acesso a um grande conjunto de dados não rotulados. Digamos, a tarefa é construir um classificador de cães e gatos. Agora, de todo esse conjunto de dados, o engenheiro escolhe treinar o modelo em apenas 20% dos dados (rotula-os primeiro) e usa os 80% restantes para fins de teste.
Este é um método baseado em rodadas. A cada iteração, uma imagem de teste é fornecida ao modelo para classificação. Se o modelo tiver um desempenho ruim ou se a probabilidade atribuída pelo modelo for menor, digamos 0,6, o modelo precisará ser treinado nessa amostra para melhorar o desempenho geral. A imagem para a qual o modelo é incerto ou não confiável contém mais informações para o modelo aprender.
Essa amostra é então rotulada e selecionada como uma amostra de treinamento. Essa iteração é repetida até a última amostra de teste. Dessa forma, montamos um novo conjunto de treinamento que vale a pena anotar. O modelo é treinado nos dados de treinamento seletivo recém-coletados, reduzindo assim o tempo geral de treinamento. Isso é repetido até que o conjunto de anotações termine.
Como selecionar a imagem para anotação?
A abordagem acima mencionada é apenas uma maneira simples de escolher uma amostra para anotação. Na prática real, os dois métodos a seguir são usados, às vezes uma combinação dos dois.
- Amostragem baseada na incerteza : Imagens sobre as quais o modelo não tem certeza ou imagens que foram atribuídas com baixa probabilidade pelo modelo.
- Amostragem baseada na diversidade : Imagens que representam a diversidade, ou seja, variação na representação espacial, representação espectral, representação de classe e assim por diante. Mais diversidade, mais informação disponível para o modelo aprender.
Uma função que recebe uma amostra de dados (imagem) como entrada e retorna uma pontuação de prioridade/classificação é denominada função de aquisição.
Leia: Desafios na IA
Funções comuns de aquisição
1. Melhor versus Segundo Melhor (BvSB)
Este método é usado principalmente para algumas classes (3 a 5). A fórmula utilizada considera os valores de probabilidade da classe mais alta e da segunda mais alta. y1 e y2 indicam o maior e o segundo maior valor de probabilidade previsto pelo modelo p? para uma dada amostra x.

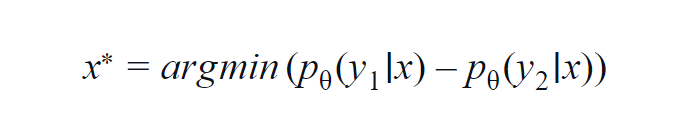
A ideia fundamental é minimizar a equação abaixo. Quanto menor a diferença, maior é a informação contida na amostra de dados x.
Para uma compreensão simples, suponha um exemplo em que as classes envolvidas na amostra de dados sejam cachorro, gato, cavalo e leão. Considere o primeiro cenário onde a entrada para o modelo é uma imagem de cachorro e a probabilidade de saída da classe do cachorro (mais provável) é 0,6 e da classe do gato (2ª mais provável) é 0,35.
O restante 0,5 é distribuído entre as outras duas classes. No segundo cenário, para a mesma entrada, as probabilidades de saída para as duas primeiras classes são 0,7 e 0,2. Agora, a partir dos dois cenários, podemos inferir que no segundo cenário, o modelo tem mais certeza sobre sua previsão (0,7–0,2=0,5).
No primeiro cenário, o modelo é mais incerto quanto à previsão (0,6–0,35=0,25). Minimizando assim a equação acima, podemos coletar uma amostra de dados que vale a pena anotar.
2. Entropia
BvSB é adequado para menos classes. No entanto, com um grande número de classes, a entropia é usada como função de aquisição. Por isso, a fórmula abaixo considera as informações das demais classes. A entropia é uma medida de impureza ou desequilíbrio. Em termos de aprendizado de máquina, ele pode ser definido como uma medida de incerteza de um modelo. Um alto valor de entropia é uma indicação de alta incerteza na associação de classe.
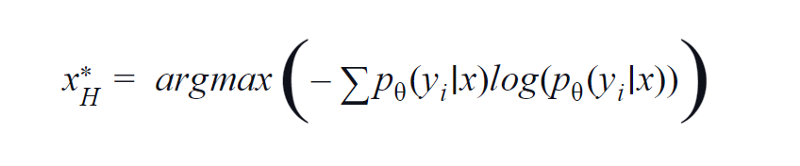
Equação de entropia, imagem do autor
Portanto, maximizar a equação acima nos renderá uma amostra de imagem para a qual o modelo é altamente incerto ou menos confiável na tarefa de classificação.
3. Consulta pelo comitê QBC
Assim como a floresta aleatória faz uso do aprendizado conjunto - fazendo uso de várias árvores de decisão. Da mesma forma, a incerteza sobre uma amostra de dados x é medida em um conjunto de modelos diferentes (com diferentes hiperparâmetros ou sementes).
Com isso, se para uma determinada imagem, a saída varia muito para diferentes modelos, significa que os modelos não se sentem confortáveis em classificar essa imagem. Normalmente, a pontuação mais provável de cada modelo é empilhada em um vetor. A entropia deste vetor é calculada. Novamente, se a entropia for alta, a imagem é ainda rotulada e anotada.
Um passo à frente
Até agora, usamos amostras de dados para as quais o modelo não tem certeza suficiente. Mas e as amostras para as quais o modelo é extremamente seguro ou atribui uma pontuação de alta probabilidade? Agora, se pudermos usar tais amostras, o modelo melhorará seu aprendizado sobre os recursos que já aprendeu.
Dessa forma, melhora seu desempenho polindo seu aprendizado. Em suma, o engenheiro pode coletar amostras de dados com pontuação de probabilidade de 0,9 ou superior e atribuir um rótulo a elas. Isso pode ser anotado e alimentado como uma amostra de treinamento.
O motivo de tal método é melhorar o aprendizado existente do modelo sobre os recursos. Dessa forma, o modelo de ML e o engenheiro de ML cooperam entre si para criar efetivamente amostras de dados que devem ser anotadas. Tal técnica é chamada de aprendizagem cooperativa.
Leia também: Escopo futuro da IA
Conclusão
Verificou-se que, usando técnicas de aprendizado ativo, os profissionais economizam cerca de 80% do tempo gasto em anotação e rotulagem. A vantagem do aprendizado ativo não se limita apenas à diminuição do tempo de treinamento do modelo e à anotação de dados eficiente.
Também reduz o overfitting que ocorre devido à presença de um grande número de amostras de um único tipo tornando o modelo tendencioso.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.