
Apprendimento attivo per l'intelligenza artificiale [Guida completa]
Pubblicato: 2020-12-01Panoramica dell'apprendimento attivo per l'intelligenza artificiale
In questo articolo tratteremo le basi dell'apprendimento attivo e la sua rilevanza nel mondo dell'Intelligenza Artificiale.
Sommario
introduzione
Nell'apprendimento automatico esistono due tipi di metodi di apprendimento: apprendimento supervisionato e non supervisionato. Nell'apprendimento supervisionato, forniamo al modello etichette per ogni campione di addestramento. Il modello apprende le caratteristiche dei campioni di dati di addestramento e li associa alle etichette corrispondenti.
L'output è una probabilità di un campione di prova appartenente a una particolare classe. L'apprendimento non supervisionato, tuttavia, non richiede etichette e il modello classifica il campione di prova in base a un modello oa una tendenza appresa durante il processo di formazione.
Ora nell'apprendimento supervisionato, c'è bisogno di immagini (assumete come input) e delle sue annotazioni. Il modello può imparare dalle immagini ottimizzando abbastanza bene da adattarsi alle immagini e alla loro annotazione.
Ma, in pratica, affinché il modello funzioni molto bene sui campioni di prova, è necessaria una pletora di immagini e le sue annotazioni. Per risolvere questo problema, molti ricercatori hanno utilizzato l'apprendimento attivo.

Motivazione
In molti casi, di solito ci saranno milioni di dati disponibili, ma annotarli tutti sarebbe impossibile e richiederebbe molto tempo. Alcuni esempi includono:
- Un video registrato da un drone durante il suo volo
- Un'immagine medica contenente milioni di cellule
- Una registrazione CCTV da un semaforo
Per gestire dati così pesanti, viene impiegato l'apprendimento attivo che ci dice di tutti i dati disponibili per l'annotazione, annotando quali campioni hanno senso.
Processo di base
L'ingegnere ML/specialista Oracle ha accesso a un ampio pool di dati senza etichetta. Supponiamo che il compito sia costruire un classificatore di cani e gatti. Ora da questo intero pool di dati, l'ingegnere sceglie di addestrare il modello solo sul 20% dei dati (li etichetta prima) e utilizza il restante 80% a scopo di test.
Questo è un metodo a base rotonda. In ogni iterazione, al modello viene assegnata un'immagine di prova per la classificazione. Se il modello funziona male, o se la probabilità assegnata dal modello è inferiore, diciamo 0,6, allora il modello deve essere addestrato su questo campione per migliorare le prestazioni complessive. L'immagine per la quale il modello è incerto o non sicuro contiene ulteriori informazioni che il modello deve apprendere.
Questo campione viene quindi etichettato e selezionato come campione di addestramento. Questa iterazione viene ripetuta fino all'ultimo campione di prova. In questo modo, assembliamo un nuovo set di formazione che vale la pena annotare. Il modello viene addestrato sui dati di addestramento selettivo appena raccolti, riducendo così il tempo di addestramento complessivo. Questa operazione viene ripetuta fino al termine del set di annotazioni.
Come selezionare l'immagine per l'annotazione?
L'approccio sopra menzionato è solo un modo semplice per scegliere un campione per l'annotazione. Nella pratica reale, vengono utilizzati i seguenti due metodi, a volte una combinazione dei due.
- Campionamento basato sull'incertezza : immagini su cui il modello è incerto o immagini a cui è stata assegnata una bassa probabilità dal modello.
- Campionamento basato sulla diversità : immagini che rappresentano la diversità, ovvero variazioni nella rappresentazione spaziale, rappresentazione spettrale, rappresentazione di classe e così via. Più la diversità, più informazioni disponibili per il modello da apprendere.
Una funzione che prende un campione di dati (immagine) come input e restituisce un punteggio di priorità/classifica è definita funzione di acquisizione.
Leggi: Sfide nell'IA
Funzioni di acquisizione comuni
1. Best-versus-Second-Best (BvSB)
Questo metodo viene utilizzato principalmente per alcune classi (da 3 a 5). La formula utilizzata considera i valori di probabilità della classe più alta e della seconda classe più alta. y1 e y2 indicano il valore di probabilità più alto e il secondo più alto previsto dal modello p? per un dato campione x.

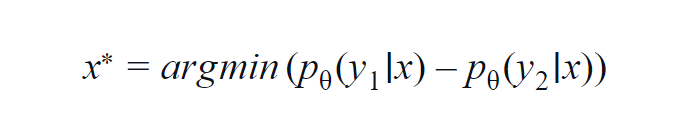
L'idea fondamentale è di minimizzare l'equazione seguente. Minore è la differenza, maggiore è l'informazione contenuta nel campione di dati x.
Per semplice comprensione, supponiamo un esempio in cui le classi coinvolte nel campione di dati sono cane, gatto, cavallo e leone. Si consideri il primo scenario in cui l'input del modello è un'immagine del cane e la probabilità di uscita della classe del cane (più probabile) è 0,6 e della classe del gatto (la seconda più probabile) è 0,35.
Il restante 0,5 è distribuito tra le altre due classi. Nel secondo scenario, per lo stesso input, le probabilità di output per le prime due classi sono 0,7 e 0,2. Ora dai due scenari possiamo dedurre che nel secondo scenario il modello è più certo della sua previsione (0,7–0,2=0,5).
Nel primo scenario, il modello è più incerto per quanto riguarda la previsione (0,6–0,35=0,25). Riducendo così al minimo l'equazione di cui sopra, possiamo raccogliere un campione di dati che vale la pena annotare.
2. Entropia
BvSB è adatto a meno classi. Tuttavia, con un gran numero di classi, l'entropia viene utilizzata come funzione di acquisizione. Il motivo è che la formula seguente considera le informazioni nelle classi rimanenti. L'entropia è una misura di impurità o squilibrio. In termini di machine learning, può essere definito come una misura dell'incertezza di un modello. Un alto valore di entropia è un'indicazione di elevata incertezza nell'associazione di classe.
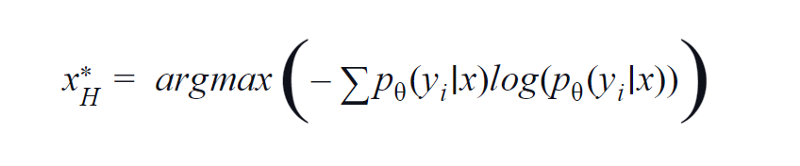
Equazione dell'entropia, Immagine dell'autore
Pertanto, massimizzare l'equazione di cui sopra ci darà un campione di immagine per il quale il modello è altamente incerto o meno sicuro nell'attività di classificazione.
3. Interrogazione del comitato QBC
Proprio come la foresta casuale fa uso dell'apprendimento d'insieme, facendo uso di diversi alberi decisionali. Allo stesso modo, l'incertezza su un campione di dati x viene misurata su un insieme di modelli diversi (con iperparametri o semi diversi).
Con questo, se per una data immagine l'output varia molto per i diversi modelli, significa che i modelli non sono a proprio agio nel classificare questa immagine. Di solito, il punteggio più probabile di ciascun modello è impilato in un vettore. Viene calcolata l'entropia di questo vettore. Di nuovo, se l'entropia è alta, l'immagine viene ulteriormente etichettata e annotata.
Un passo avanti
Finora abbiamo utilizzato campioni di dati per i quali il modello non è abbastanza sicuro. Ma che dire dei campioni per i quali il modello è estremamente sicuro o assegna un punteggio di alta probabilità? Ora, se possiamo utilizzare tali campioni, il modello migliora l'apprendimento delle funzionalità che ha già appreso.
In questo modo, migliora le sue prestazioni perfezionando il suo apprendimento. Tutto sommato, l'ingegnere può prelevare campioni di dati che hanno un punteggio di probabilità di 0,9 e superiore e può assegnargli un'etichetta. Questo può essere ulteriormente annotato e alimentato come un campione di addestramento.
Il motivo di tale metodo è migliorare l'apprendimento esistente del modello sulle caratteristiche. In questo modo, il modello ML e l'ingegnere ML cooperano tra loro per elaborare efficacemente campioni di dati da annotare. Tale tecnica è chiamata apprendimento cooperativo.
Leggi anche: Ambito futuro dell'IA
Conclusione
È stato riscontrato che utilizzando tecniche di apprendimento attivo, i professionisti risparmiano circa l'80% del tempo che altrimenti sarebbe stato speso per annotare ed etichettare. Il vantaggio dell'apprendimento attivo non si limita solo alla riduzione del tempo di addestramento del modello e all'efficiente annotazione dei dati.
Riduce anche l'overfitting che si verifica a causa della presenza di un gran numero di campioni di un unico tipo che rendono il modello distorto.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.