
Apprentissage actif pour l'intelligence artificielle [Guide complet]
Publié: 2020-12-01Aperçu de l'apprentissage actif pour l'intelligence artificielle
Dans cet article, nous aborderons les bases de l'apprentissage actif et sa pertinence dans le monde de l'Intelligence Artificielle.
Table des matières
introduction
Dans l'apprentissage automatique, il existe deux types de méthodes d'apprentissage : l'apprentissage supervisé et l'apprentissage non supervisé. En apprentissage supervisé, nous fournissons au modèle des étiquettes pour chaque échantillon d'apprentissage. Le modèle apprend les caractéristiques des échantillons de données d'apprentissage et les mappe à leurs étiquettes correspondantes.
La sortie est une probabilité qu'un échantillon de test appartienne à une classe particulière. L'apprentissage non supervisé, cependant, ne nécessite aucune étiquette et le modèle classe l'échantillon de test en fonction d'un modèle ou d'une tendance qu'il a appris au cours du processus de formation.
Maintenant, dans l'apprentissage supervisé, il y a un besoin d'images (supposées comme entrée) et de ses annotations. Le modèle peut apprendre des images en s'optimisant suffisamment pour s'adapter aux images et à leur annotation.
Mais, pratiquement pour que le modèle fonctionne extrêmement bien sur des échantillons de test, une pléthore d'images et ses annotations sont nécessaires. Pour résoudre ce problème, l'apprentissage actif a été utilisé par de nombreux chercheurs.

Motivation
Dans de nombreux cas, il y aura généralement des millions de données disponibles, mais les annoter toutes serait irréalisable et prendrait du temps. Quelques exemples incluent:
- Une vidéo enregistrée par un drone pendant son vol
- Une image médicale contenant des millions de cellules
- Un enregistrement CCTV d'un signal de feu de circulation
Pour traiter des données aussi lourdes, un apprentissage actif est utilisé qui nous indique toutes les données disponibles pour l'annotation, en annotant quels échantillons ont du sens.
Processus de base
L'ingénieur ML/spécialiste Oracle a accès à un large pool de données non étiquetées. Supposons que la tâche consiste à créer un classificateur de chats et de chiens. Désormais, sur l'ensemble de ce pool de données, l'ingénieur choisit de former le modèle sur seulement 20 % des données (les étiquette en premier) et utilise les 80 % restants à des fins de test.
Il s'agit d'une méthode basée sur les rondes. A chaque itération, une image de test est donnée au modèle pour la classification. Si le modèle fonctionne mal, ou si la probabilité attribuée par le modèle est inférieure, disons 0,6, alors le modèle doit être formé sur cet échantillon pour améliorer la performance globale. L'image pour laquelle le modèle est incertain ou non fiable contient plus d'informations que le modèle doit apprendre.
Cet échantillon est ensuite étiqueté et sélectionné comme échantillon d'apprentissage. Cette itération est répétée jusqu'au dernier échantillon d'essai. De cette façon, nous assemblons un nouvel ensemble de formation qui mérite d'être annoté. Le modèle est entraîné sur les données d'entraînement sélectives nouvellement collectées, réduisant ainsi le temps d'entraînement global. Ceci est répété jusqu'à ce que le jeu d'annotations soit terminé.
Comment sélectionner l'image pour l'annotation ?
L'approche mentionnée ci-dessus n'est qu'un moyen simple de choisir un échantillon pour l'annotation. En pratique, les deux méthodes suivantes sont utilisées, parfois une combinaison des deux.
- Échantillonnage basé sur l'incertitude : images dont le modèle est incertain ou images auxquelles le modèle a attribué une faible probabilité.
- Échantillonnage basé sur la diversité : Images qui représentent la diversité, c'est-à-dire la variation de la représentation spatiale, la représentation spectrale, la représentation des classes, etc. Plus la diversité, plus d'informations disponibles pour le modèle à apprendre.
Une fonction qui prend un échantillon de données (image) en entrée et renvoie un score de priorité/classement est appelée fonction d' acquisition.
Lire : Les défis de l'IA
Fonctions d'acquisition courantes
1. Meilleur contre deuxième meilleur (BvSB)
Cette méthode est surtout utilisée pour quelques classes (3 à 5). La formule utilisée tient compte des valeurs de probabilité de la classe la plus élevée et de la deuxième classe la plus élevée. y1 et y2 indiquent les valeurs de probabilité les plus élevées et les deuxièmes les plus élevées prédites par le modèle p? pour un échantillon donné x.

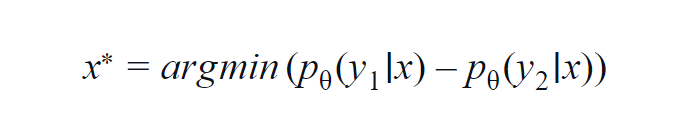
L'idée fondamentale est de minimiser l'équation ci-dessous. Plus la différence est faible, plus l'information contenue dans l'échantillon de données x est importante.
Pour une compréhension simple, supposons un exemple où les classes impliquées dans l'échantillon de données sont chien, chat, cheval et lion. Considérons le premier scénario où l'entrée du modèle est une image de chien et la probabilité de sortie de la classe chien (la plus probable) est de 0,6 et de la classe chat (2e plus probable) est de 0,35.
Les 0,5 restants sont répartis entre les deux autres classes. Dans le deuxième scénario, pour la même entrée, les probabilités de sortie pour les deux premières classes sont de 0,7 et 0,2. Maintenant, à partir des deux scénarios, nous pouvons déduire que dans le deuxième scénario, le modèle est plus certain de sa prédiction (0,7–0,2=0,5).
Dans le premier scénario, le modèle est plus incertain quant à la prédiction (0,6–0,35=0,25). En minimisant ainsi l'équation ci-dessus, nous pouvons collecter un échantillon de données digne d'être annoté.
2. Entropie
BvSB convient à moins de classes. Cependant, avec un grand nombre de classes, l'entropie est utilisée comme fonction d'acquisition. La raison en est que la formule ci-dessous prend en compte les informations dans les classes restantes. L'entropie est une mesure d'impureté ou de déséquilibre. En termes d'apprentissage automatique, il peut être défini comme une mesure de l'incertitude d'un modèle. Une valeur élevée d'entropie est une indication d'une grande incertitude dans l'association de classe.
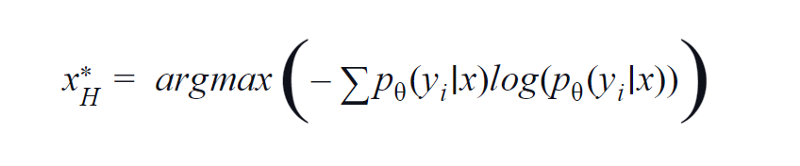
Équation d'entropie, image de l'auteur
Par conséquent, la maximisation de l'équation ci-dessus nous donnera un échantillon d'image pour lequel le modèle est très incertain ou le moins confiant dans la tâche de classification.
3. Requête par le comité QBC
Tout comme la forêt aléatoire utilise l'apprentissage d'ensemble - en utilisant plusieurs arbres de décision. De même, l'incertitude sur un échantillon de données x est mesurée sur un ensemble de modèles différents (ayant différents hyperparamètres ou germes).
Avec cela, si pour une image donnée, la sortie varie beaucoup pour différents modèles, cela signifie que les modèles ne sont pas à l'aise pour classer cette image. Habituellement, le score le plus probable de chaque modèle est empilé dans un vecteur. L'entropie de ce vecteur est calculée. Encore une fois, si l'entropie est élevée, l'image est en outre étiquetée et annotée.
Une longueur d'avance
Jusqu'à présent, nous avons utilisé des échantillons de données pour lesquels le modèle n'est pas suffisamment sûr. Mais qu'en est-il des échantillons pour lesquels le modèle est extrêmement sûr ou attribue un score de probabilité élevé ? Maintenant, si nous pouvons utiliser de tels échantillons, alors le modèle améliore son apprentissage des fonctionnalités qu'il a déjà apprises.
De cette façon, il améliore ses performances en peaufinant son apprentissage. Dans l'ensemble, l'ingénieur peut prélever des échantillons de données qui ont un score de probabilité de 0,9 et plus et peut leur attribuer une étiquette. Cela peut être encore annoté et alimenté en tant qu'échantillon d'apprentissage.
Le but d'une telle méthode est d'améliorer l'apprentissage existant du modèle sur les caractéristiques. De cette manière, le modèle ML et l'ingénieur ML coopèrent pour trouver efficacement des échantillons de données à annoter. Une telle technique est appelée apprentissage coopératif.
Lisez aussi: Portée future de l'IA
Conclusion
Il a été constaté qu'en utilisant des techniques d'apprentissage actif, les praticiens économisent environ 80% de leur temps qui serait autrement consacré à l'annotation et à l'étiquetage. L'avantage de l'apprentissage actif ne se limite pas seulement à la réduction du temps d'apprentissage du modèle et à l'annotation efficace des données.
Cela réduit également le surajustement qui se produit en raison de la présence d'un grand nombre d'échantillons d'un seul type, ce qui biaise le modèle.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.