
Pembelajaran Aktif Untuk Kecerdasan Buatan [Panduan Komprehensif]
Diterbitkan: 2020-12-01Ikhtisar pembelajaran aktif untuk kecerdasan buatan
Pada artikel ini, kami akan membahas dasar-dasar pembelajaran aktif dan relevansinya dalam dunia Artificial Intelligence.
Daftar isi
pengantar
Dalam pembelajaran mesin, ada dua jenis metode pembelajaran - pembelajaran terawasi dan tidak terawasi. Dalam pembelajaran yang diawasi, kami menyediakan model dengan label untuk setiap sampel pelatihan. Model mempelajari fitur sampel data pelatihan dan memetakannya ke label yang sesuai.
Outputnya adalah probabilitas sampel uji milik kelas tertentu. Pembelajaran tanpa pengawasan, bagaimanapun, tidak memerlukan label dan model mengklasifikasikan sampel uji berdasarkan beberapa pola atau tren yang telah dipelajari selama proses pelatihan.
Sekarang dalam pembelajaran terawasi, ada kebutuhan untuk gambar (anggap sebagai input) dan penjelasannya. Model dapat belajar dari gambar dengan mengoptimalkan cukup baik agar sesuai dengan gambar dan anotasinya.
Namun, secara praktis agar model berkinerja sangat baik pada sampel uji, diperlukan sejumlah besar gambar dan anotasinya. Untuk mengatasi masalah ini, pembelajaran aktif digunakan oleh banyak peneliti.

Motivasi
Dalam banyak kasus, biasanya akan ada jutaan data yang tersedia, tetapi membuat anotasi semuanya tidak mungkin dilakukan dan memakan waktu. Beberapa contoh termasuk:
- Sebuah video yang direkam oleh drone selama penerbangannya
- Gambar medis yang mengandung jutaan sel
- Rekaman CCTV dari sinyal lampu lalu lintas
Untuk menangani data yang berat seperti itu, pembelajaran aktif digunakan yang memberi tahu kita semua data yang tersedia untuk anotasi, membuat anotasi sampel mana yang masuk akal.
Proses Dasar
Insinyur ML/spesialis Oracle memiliki akses ke kumpulan besar data yang tidak berlabel. Katakanlah, tugasnya adalah membuat pengklasifikasi kucing dan anjing. Sekarang dari seluruh kumpulan data ini, insinyur memilih untuk melatih model hanya pada 20% data (memberi label terlebih dahulu) dan menggunakan 80% sisanya untuk tujuan pengujian.
Ini adalah metode berbasis putaran. Dalam setiap iterasi, citra uji diberikan kepada model untuk klasifikasi. Jika model berkinerja buruk, atau jika probabilitas yang diberikan oleh model lebih kecil, katakanlah 0,6, maka model perlu dilatih pada sampel ini untuk meningkatkan kinerja secara keseluruhan. Gambar yang modelnya tidak pasti atau tidak percaya diri mengandung lebih banyak informasi untuk dipelajari model.
Sampel ini kemudian diberi label dan dipilih sebagai sampel pelatihan. Iterasi ini diulang sampai sampel uji terakhir. Dengan cara ini, kami mengumpulkan satu set pelatihan baru yang perlu diberi anotasi. Model dilatih pada data pelatihan selektif yang baru dikumpulkan sehingga mengurangi waktu pelatihan secara keseluruhan. Ini diulang sampai kumpulan anotasi selesai.
Bagaimana cara memilih gambar untuk anotasi?
Pendekatan yang disebutkan di atas hanyalah salah satu cara sederhana untuk memilih sampel untuk anotasi. Dalam praktik nyata, dua metode berikut digunakan, terkadang kombinasi keduanya.
- Pengambilan sampel berdasarkan ketidakpastian : Gambar yang modelnya tidak pasti atau, gambar yang diberi probabilitas rendah oleh model.
- Pengambilan sampel berdasarkan keragaman : Gambar yang mewakili keragaman, yaitu variasi dalam representasi spasial, representasi spektral, representasi kelas, dan sebagainya. Semakin beragam, semakin banyak informasi yang tersedia untuk dipelajari model.
Fungsi yang mengambil sampel data (gambar) sebagai input dan mengembalikan skor prioritas/peringkat disebut sebagai fungsi Akuisisi.
Baca: Tantangan dalam AI
Fungsi Akuisisi Umum
1. Terbaik-versus-Kedua-Terbaik (BvSB)
Metode ini sebagian besar digunakan untuk beberapa kelas (3 hingga 5). Rumus yang digunakan mempertimbangkan nilai probabilitas kelas tertinggi dan tertinggi kedua. y1 dan y2 menunjukkan nilai probabilitas tertinggi dan tertinggi kedua yang diprediksi oleh model p? untuk sampel yang diberikan x.

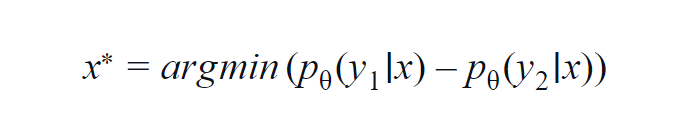
Ide dasarnya adalah untuk meminimalkan persamaan di bawah ini. Semakin kecil selisihnya, semakin banyak informasi yang terkandung dalam sampel data x.
Untuk pemahaman sederhana, anggaplah sebuah contoh di mana kelas-kelas yang terlibat dalam sampel data adalah anjing, kucing, kuda, dan singa. Pertimbangkan skenario pertama di mana input ke model adalah gambar anjing dan probabilitas output kelas anjing (paling mungkin) adalah 0,6 dan kelas kucing (kemungkinan ke-2) adalah 0,35.
Sisa 0,5 didistribusikan antara dua kelas lainnya. Dalam skenario kedua, untuk input yang sama, probabilitas output untuk dua kelas teratas adalah 0,7 dan 0,2. Sekarang dari dua skenario, kita dapat menyimpulkan bahwa pada skenario kedua, model lebih yakin tentang prediksinya (0,7–0,2=0,5).
Dalam skenario pertama, model lebih tidak pasti mengenai prediksi (0,6–0,35=0,25). Dengan meminimalkan persamaan di atas, kita dapat mengumpulkan sampel data yang layak diberi anotasi.
2. Entropi
BvSB cocok untuk kelas yang lebih sedikit. Namun, dengan jumlah kelas yang banyak, entropi digunakan sebagai fungsi akuisisi. Alasannya, rumus di bawah ini mempertimbangkan informasi di kelas yang tersisa. Entropi adalah ukuran ketidakmurnian atau ketidakseimbangan. Dalam hal pembelajaran mesin, itu dapat didefinisikan sebagai ukuran ketidakpastian model. Nilai entropi yang tinggi merupakan indikasi tingginya ketidakpastian dalam asosiasi kelas.
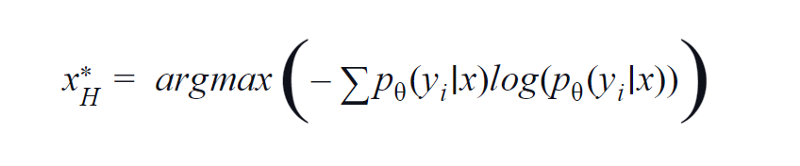
Persamaan entropi, Gambar oleh Penulis
Oleh karena itu, memaksimalkan persamaan di atas akan menghasilkan sampel gambar yang modelnya sangat tidak pasti atau paling tidak percaya diri dalam tugas klasifikasi.
3. Pertanyaan oleh panitia QBC
Sama seperti hutan acak yang menggunakan pembelajaran ensemble — memanfaatkan beberapa pohon keputusan. Demikian pula, ketidakpastian tentang sampel data x diukur melalui ansambel model yang berbeda (memiliki hyperparameter atau seed yang berbeda).
Dengan ini, jika untuk gambar tertentu, outputnya sangat bervariasi untuk model yang berbeda, itu berarti model tersebut tidak nyaman dalam mengklasifikasikan gambar ini. Biasanya, skor yang paling mungkin dari setiap model ditumpuk dalam sebuah vektor. Entropi vektor ini dihitung. Sekali lagi, jika entropi tinggi, gambar selanjutnya diberi label dan diberi keterangan.
Selangkah lebih maju
Sampai sekarang, kami telah menggunakan sampel data yang modelnya tidak cukup yakin. Tapi bagaimana dengan sampel yang modelnya sangat yakin atau memberikan skor probabilitas tinggi? Sekarang, jika kita dapat menggunakan sampel seperti itu, maka model tersebut meningkatkan pembelajarannya tentang fitur-fitur yang telah dipelajarinya.
Dengan cara ini, ia meningkatkan kinerjanya dengan memoles pembelajarannya. Secara keseluruhan, insinyur dapat mengambil sampel data yang memiliki skor probabilitas 0,9 ke atas dan dapat menetapkan label untuk itu. Ini dapat dijelaskan lebih lanjut dan dimasukkan sebagai sampel pelatihan.
Motif dari metode tersebut adalah untuk meningkatkan pembelajaran model yang sudah ada tentang fitur-fiturnya. Dengan cara ini, model ML dan insinyur ML bekerja sama satu sama lain untuk secara efektif menghasilkan sampel data yang akan dianotasi. Teknik seperti itu disebut pembelajaran kooperatif.
Baca Juga: Cakupan AI di Masa Depan
Kesimpulan
Telah ditemukan bahwa dengan menggunakan teknik pembelajaran aktif, praktisi menghemat sekitar 80% dari waktu mereka yang dihabiskan untuk anotasi dan pelabelan. Keuntungan dari pembelajaran aktif tidak hanya terbatas pada penurunan waktu pelatihan model dan anotasi data yang efisien.
Hal ini juga mengurangi overfitting yang terjadi karena adanya sejumlah besar sampel dari satu jenis membuat model menjadi bias.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.