
在 Celery for Python 中编排后台作业工作流
已发表: 2022-03-11现代 Web 应用程序及其底层系统比以往任何时候都更快、响应更快。 但是,仍然有很多情况下,您希望将繁重任务的执行转移到整个系统架构的其他部分,而不是在主线程上处理它们。 识别此类任务就像检查它们是否属于以下类别之一一样简单:
- 定期任务 - 您将安排在特定时间或间隔后运行的作业,例如,每月报告生成或每天运行两次的网络爬虫。
- 第三方任务——Web 应用程序必须快速为用户提供服务,而无需在页面加载时等待其他操作完成,例如,发送电子邮件或通知或将更新传播到内部工具(例如为 A/B 测试或系统日志收集数据) )。
- 长时间运行的作业——资源昂贵的作业,用户在计算结果时需要等待,例如,复杂的工作流执行(DAG 工作流)、图形生成、类似 Map-Reduce 的任务以及提供媒体内容(视频、声音的)。
执行后台任务的直接解决方案是在单独的线程或进程中运行它。 Python 是一种高级图灵完备的编程语言,遗憾的是它没有提供与 Erlang、Go、Java、Scala 或 Akka 相匹配的规模的内置并发。 这些基于 Tony Hoare 的通信顺序过程 (CSP)。 另一方面,Python 线程由全局解释器锁 (GIL) 协调和调度,这可以防止多个本机线程同时执行 Python 字节码。 摆脱 GIL 是 Python 开发人员经常讨论的话题,但这不是本文的重点。 Python 中的并发编程是过时的,尽管欢迎您在 Toptaler Marcus McCurdy 的Python 多线程教程中阅读它。 因此,一致地设计进程之间的通信是一个容易出错的过程,会导致代码耦合和系统可维护性差,更不用说它会对可伸缩性产生负面影响。 此外,Python 进程是操作系统(OS)下的正常进程,与整个 Python 标准库一起成为重量级。 随着应用程序中进程数量的增加,从一个这样的进程切换到另一个进程变得非常耗时。
为了更好地理解 Python 的并发性,请观看 David Beazley 在 PyCon'15 上的精彩演讲。
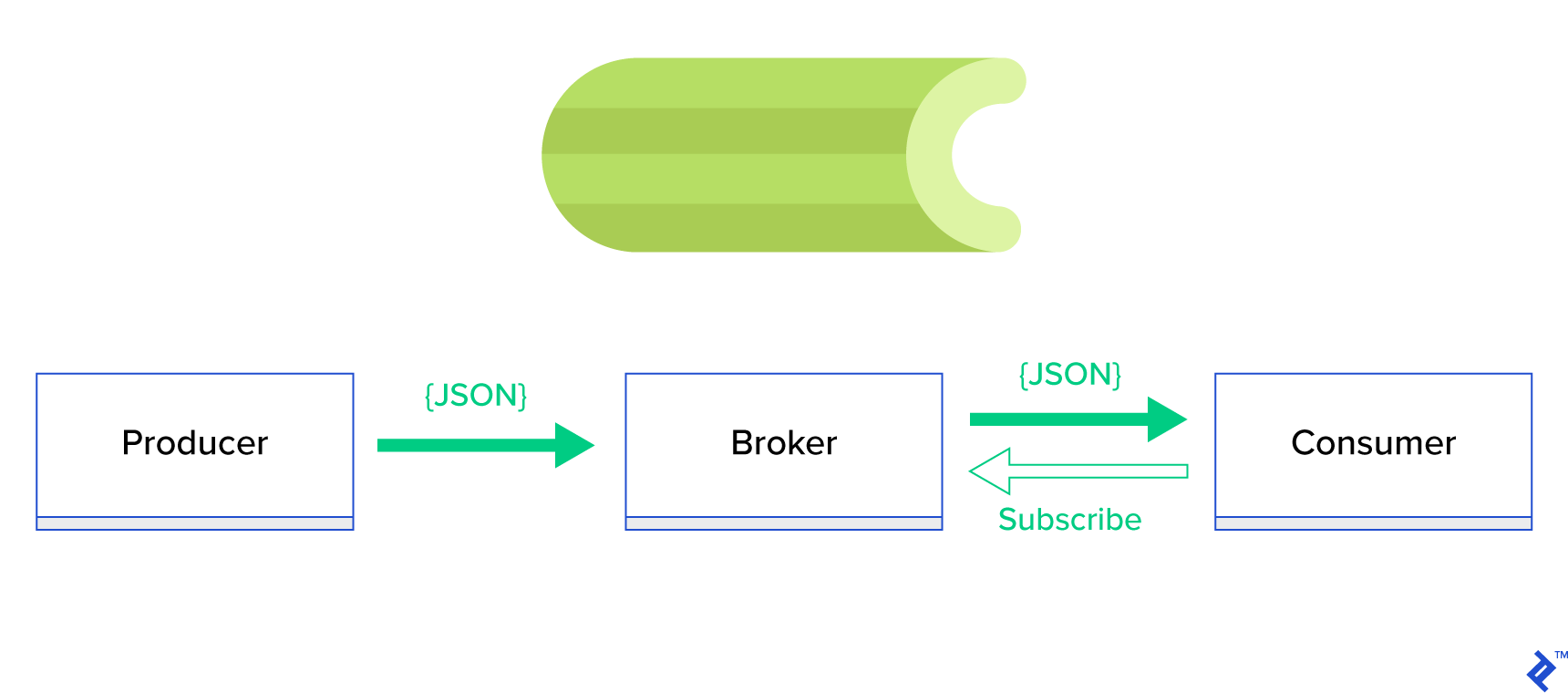
一个更好的解决方案是服务于分布式队列或其众所周知的兄弟范式,称为发布-订阅。 如图 1 所示,有两种类型的应用程序,其中一种称为发布者发送消息,另一种称为订阅者接收消息。 这两个代理不直接相互交互,甚至不知道彼此。 发布者将消息发送到中央队列或代理,订阅者从该代理接收感兴趣的消息。 这种方法有两个主要优点:
- 可扩展性——代理不需要在网络中相互了解。 他们以主题为重点。 因此,这意味着每个都可以以异步方式继续正常运行,而不管对方如何。
- 松耦合——每个代理都代表系统的一部分(服务、模块)。 由于它们是松散耦合的,因此每个都可以在数据中心之外单独扩展。
有很多消息系统支持这种范式并提供简洁的 API,由 TCP 或 HTTP 协议驱动,例如 JMS、RabbitMQ、Redis Pub/Sub、Apache ActiveMQ 等。
什么是芹菜?
Celery 是 Python 世界中最受欢迎的后台作业管理器之一。 Celery 与 RabbitMQ 或 Redis 等多个消息代理兼容,并且可以充当生产者和消费者。
Celery 是一个基于分布式消息传递的异步任务队列/作业队列。 它专注于实时操作,但也支持调度。 执行单元,称为任务,使用多处理、Eventlet 或 gevent 在一个或多个工作服务器上同时执行。 任务可以异步执行(在后台)或同步执行(等到准备好)。 – 芹菜项目
要开始使用 Celery,只需按照官方文档中的分步指南进行操作。
本文的重点是让您更好地了解 Celery 可以涵盖哪些用例。 在本文中,我们不仅会展示有趣的示例,还会尝试学习如何将 Celery 应用到实际任务中,例如后台邮件、报告生成、日志记录和错误报告。 我将分享我在模拟之外测试任务的方法,最后,我将提供一些官方文档中没有(很好)记录的技巧,这些技巧我花了几个小时的研究才自己发现。
如果您之前没有使用过 Celery,我鼓励您先按照官方教程进行尝试。
激起你的食欲
如果这篇文章引起了您的兴趣并让您想立即深入研究代码,那么请关注此 GitHub 存储库以获取本文中使用的代码。 那里的README文件将为您提供运行和使用示例应用程序的快速而肮脏的方法。
芹菜的第一步
首先,我们将通过一系列实际示例向读者展示 Celery 如何简单而优雅地解决看似不平凡的任务。 所有示例都将在 Django 框架内呈现; 但是,它们中的大多数可以很容易地移植到其他 Python 框架(Flask、Pyramid)。
项目布局由 Cookiecutter Django 生成; 但是,我只保留了一些依赖项,在我看来,这些依赖项有助于这些用例的开发和准备。 我还为这篇文章和应用程序删除了不必要的模块,以减少噪音并使代码更易于理解。
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}包含我们将在这篇文章中介绍的不同应用程序。 每个应用程序都包含一组按所需的 Celery 理解水平组织的示例。 -
celery_uncovered/celery.py定义了一个 Celery 实例。
文件: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() 然后我们需要确保 Celery 将与 Django 一起启动。 出于这个原因,我们将应用程序导入到celery_uncovered/__init__.py中。
文件: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings是我们的应用和 Celery 的配置来源。 根据执行环境,Django 会启动相应的设置: local.py用于开发或test.py用于测试。 如果需要,您还可以通过创建新的 python 模块(例如prod.py )来定义自己的环境。 芹菜配置以CELERY_为前缀。 对于这篇文章,我将 RabbitMQ 配置为代理,将 SQLite 配置为结果 bac-end。
文件: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'场景 1 - 报告生成和导出
我们将介绍的第一个案例是报告生成和导出。 在此示例中,您将学习如何定义一个生成 CSV 报告的任务,并使用 celerybeat 定期安排它。
用例描述:从 GitHub 获取每个选定时间段(日、周、月)的 500 个最热门的存储库,按主题对它们进行分组,并将结果导出到 CSV 文件。
如果我们提供的 HTTP 服务将执行通过单击标有“生成报告”的按钮触发的此功能,则应用程序将停止并等待任务完成,然后再发送回 HTTP 响应。 这是不好的。 我们希望我们的 Web 应用程序速度快,并且我们不希望我们的用户在后端计算结果时等待。 与其等待结果产生,我们宁愿通过 Celery 中的注册队列将任务排队到工作进程,并用task_id响应前端。 然后前端将使用task_id以异步方式(例如,AJAX)查询任务结果,并让用户随时了解任务进度。 最后,当该过程完成时,可以将结果作为文件提供,以便通过 HTTP 下载。
实施细节
首先,让我们将流程分解为尽可能小的单元并创建一个管道:
- Fetchers是负责从 GitHub 服务获取存储库的工作人员。
- 聚合器是负责将结果合并到一个列表中的工作人员。
- Importer是生成 GitHub 中最热门存储库的 CSV 报告的工作人员。
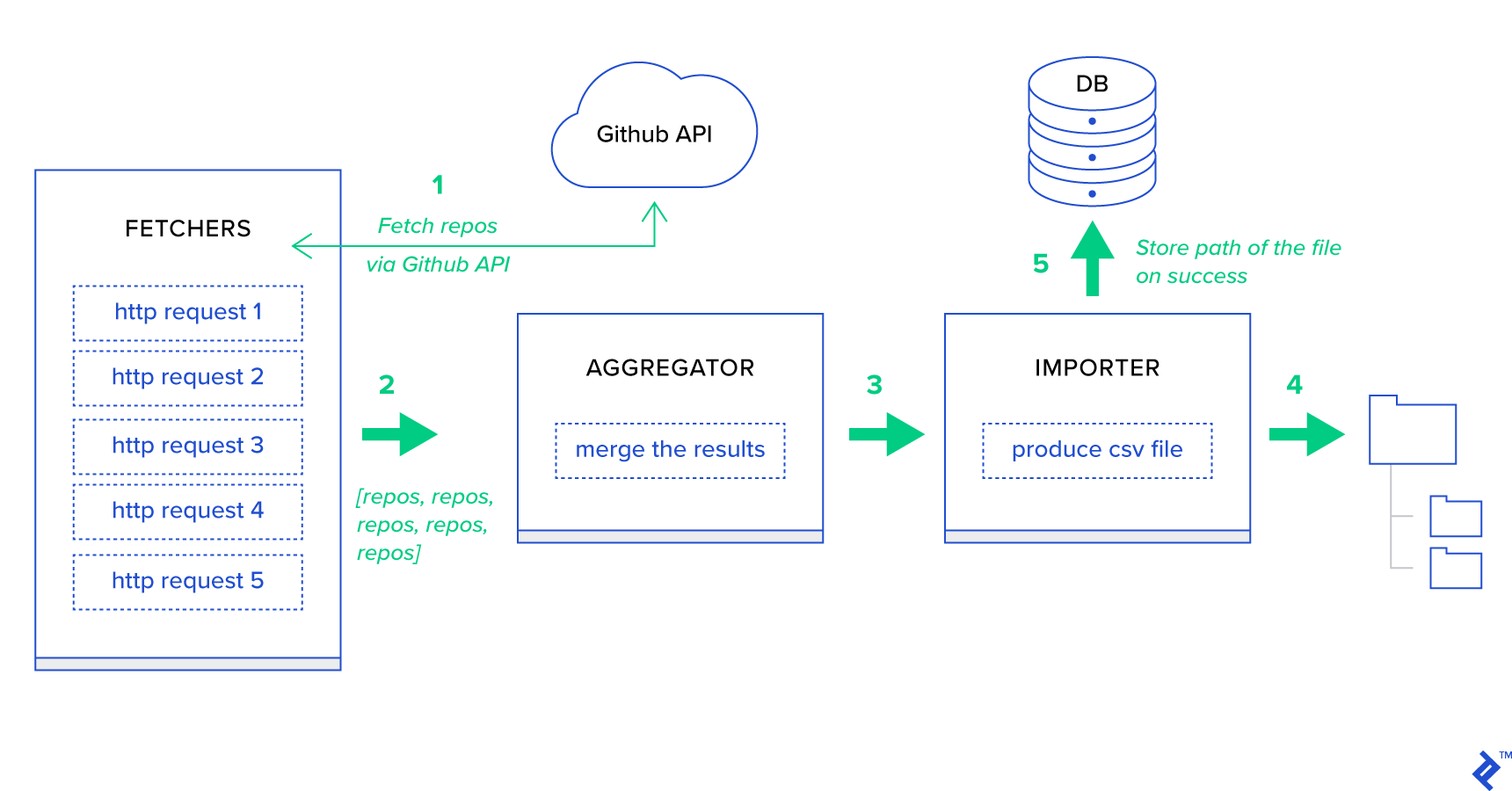
获取存储库是使用 GitHub 搜索 API GET /search/repositories的 HTTP 请求。 但是,应该处理 GitHub API 服务的一个限制:该 API 每个请求最多返回 100 个存储库,而不是 500 个。我们可以一次发送 5 个请求,但我们不想让用户等待五个单独的请求,因为 HTTP 请求是 I/O 绑定操作。 相反,我们可以使用适当的页面参数执行五个并发 HTTP 请求。 所以页面将在 [1..5] 范围内。 让我们在toyex/tasks.py模块中定义一个名为fetch_hot_repos/3 -> list的任务:
文件: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items 所以fetch_hot_repos创建一个对 GitHub API 的请求,并用一个存储库列表来响应用户。 它接收三个参数来定义我们的请求负载:
-
since- 在创建日期过滤存储库。 -
per_page— 每个请求返回的结果数(限制为 100)。 -
page--- 请求的页码(在 [1..5] 范围内)。
注意:为了使用 GitHub Search API,您需要一个 OAuth 令牌来通过身份验证检查。 在我们的例子中,它保存在GITHUB_OAUTH下的设置中。
接下来,我们需要定义一个主任务,负责汇总结果并将其导出到 CSV 文件中: produce_hot_repo_report_task/2->filepath:
文件: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) 此任务使用celery.canvas.group执行fetch_hot_repos/3的五个并发调用。 等待这些结果,然后简化为存储库对象列表。 然后我们的结果集按主题分组,最后导出到MEDIA_ROOT/目录下生成的 CSV 文件。
为了定期调度任务,您可能需要在配置文件的调度列表中添加一个条目:
文件: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }试一试
为了启动和测试任务是如何工作的,首先我们需要启动 Celery 进程:
$ celery -A celery_uncovered worker -l info 接下来,我们需要创建celery_uncovered/media/目录。 然后,您将能够通过 Shell 或 Celerybeat 测试其功能:
壳牌:
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)芹菜节拍:
# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info 您可以在MEDIA_ROOT/目录下查看结果。
场景 2 - 通过电子邮件报告服务器 500错误
Celery 最常见的用例之一是发送电子邮件通知。 电子邮件通知是一种离线 I/O 绑定操作,它利用本地 SMTP 服务器或第三方 SES。 有许多涉及发送电子邮件的用例,对于其中的大多数,用户无需等到此过程完成即可接收 HTTP 响应。 这就是为什么首选在后台执行此类任务并立即响应用户的原因。

用例描述:通过 Celery 向管理员电子邮件报告 50X 错误。
Python 和 Django 具有执行系统日志记录的必要背景。 我不会详细介绍 Python 的日志记录实际上是如何工作的。 但是,如果您以前从未尝试过或需要复习,请阅读内置日志记录模块的文档。 您肯定希望在您的生产环境中使用它。 Django 有一个名为 AdminEmailHandler 的特殊记录器处理程序,它会为它收到的每条日志消息向管理员发送电子邮件。
实施细节
主要思想是扩展AdminEmailHandler类的send_mail方法,使其可以通过 Celery 发送邮件。 这可以如下图所示完成:
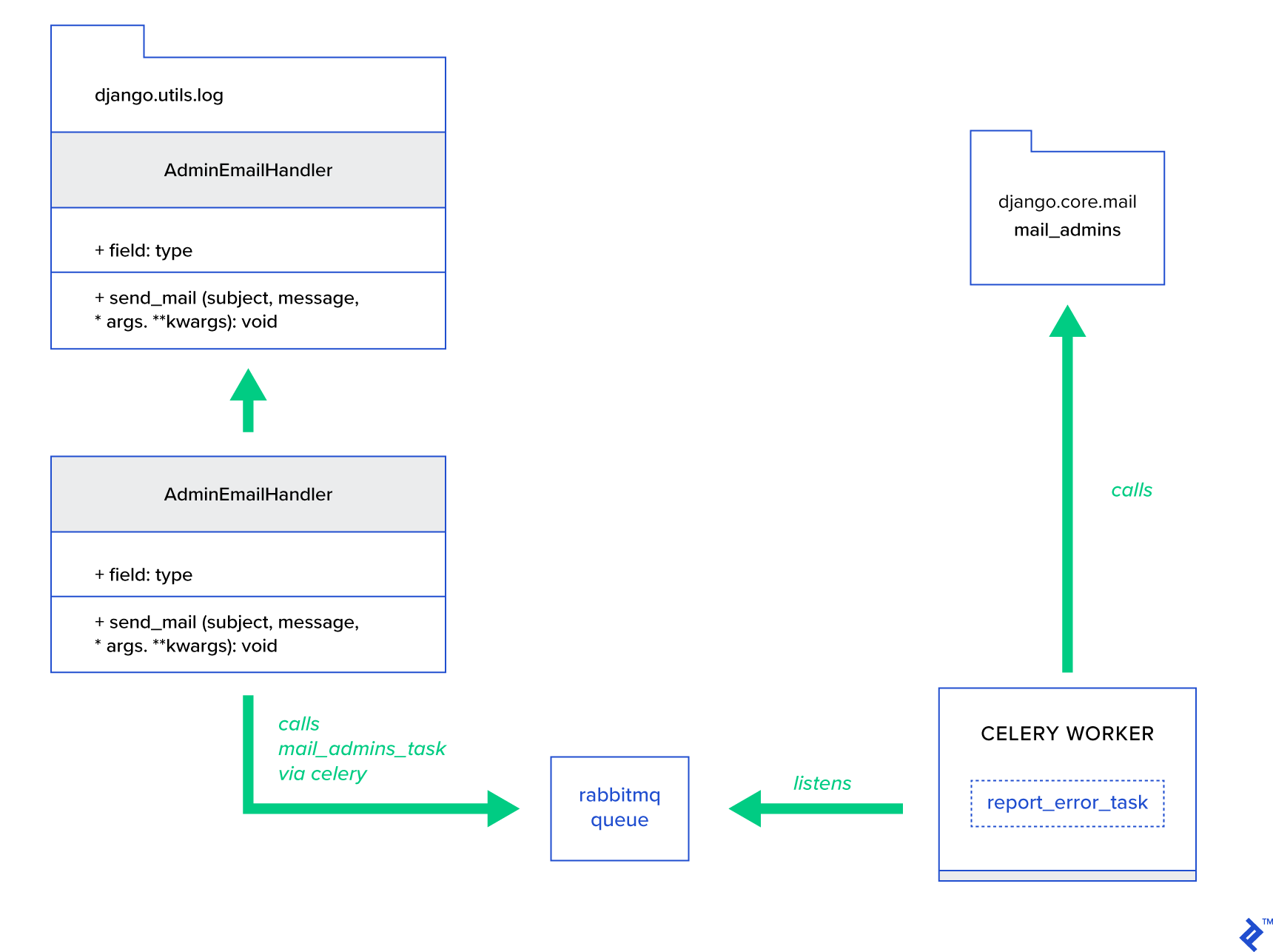
首先,我们需要设置一个名为report_error_task的任务,它使用提供的主题和消息调用mail_admins :
文件: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)接下来,我们实际上扩展了 AdminEmailHandler 以便它在内部只调用定义的 Celery 任务:
文件: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) 最后,我们需要设置日志记录。 Django 中的日志配置相当简单。 您需要覆盖LOGGING以便日志引擎开始使用新定义的处理程序:
文件config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } 请注意,我有意设置处理程序过滤器require_debug_true以便在应用程序在调试模式下运行时测试此功能。
试一试
为了测试它,我准备了一个 Django 视图,它在localhost:8000/report-error提供“除零”操作。 您还需要启动 MailHog Docker 容器来测试电子邮件是否实际发送。
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)额外细节
作为一个邮件测试工具,我设置了 MailHog 并配置了 Django 邮件以将其用于 SMTP 传递。 有很多方法可以部署和运行 MailHog。 我决定使用 Docker 容器。 您可以在相应的 README 文件中找到详细信息:
文件: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025要将您的应用程序配置为使用 MailHog,您需要在配置中添加以下行:
文件: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')超越默认的 Celery 任务
Celery 任务可以由任何可调用函数创建。 默认情况下,任何用户定义的任务都被注入celery.app.task.Task作为父(抽象)类。 此类包含异步运行任务(通过网络将其传递给 Celery worker)或同步(用于测试目的)、创建签名和许多其他实用程序的功能。 在接下来的示例中,我们将尝试扩展Celery.app.task.Task ,然后将其用作基类,以便为我们的任务添加一些有用的行为。
场景 3 - 每个任务的文件记录
在我的一个项目中,我正在开发一个应用程序,该应用程序为最终用户提供类似于提取、转换、加载 (ETL) 的工具,该工具能够摄取并过滤大量分层数据。 后端分为两个模块:
- 用 Celery 编排数据处理管道
- 使用 Go 进行数据处理
Celery 部署了一个 Celerybeat 实例和 40 多个工作人员。 有 20 多个不同的任务组成了管道和编排活动。 每个这样的任务都可能在某个时候失败。 所有这些故障都被转储到每个工人的系统日志中。 在某些时候,调试和维护 Celery 层开始变得不方便。 最终,我们决定将任务日志隔离到一个特定于任务的文件中。
用例描述:扩展 Celery 以便每个任务将其标准输出和错误记录到文件中
Celery 为 Python 应用程序提供了对其内部工作的极大控制。 它附带一个熟悉的信号框架。 使用 Celery 的应用程序可以订阅其中的一些,以增强某些操作的行为。 我们将利用任务级信号来提供对单个任务生命周期的详细跟踪。 Celery 总是带有一个日志记录后端,我们将从它中受益,同时只在少数几个地方稍微覆盖以实现我们的目标。
实施细节
Celery 已经支持每个任务的日志记录。 要保存到文件,有必要将日志输出分派到正确的位置。 在我们的例子中,任务的正确位置是与任务名称匹配的文件。 在 Celery 实例上,我们将使用动态推断的日志处理程序覆盖内置的日志配置。 可以订阅celeryd_after_setup信号,然后在那里配置系统日志记录:
文件: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) 请注意,对于在 Celery 应用程序中注册的每个任务,我们正在构建一个相应的记录器及其处理程序。 每个处理程序都是logging.FileHandler类型,因此每个这样的实例都接收一个文件名作为输入。 运行此程序所需要做的就是将此模块导入文件末尾的celery_uncovered/celery.py :
import celery_uncovered.tricks.celery_conf 可以通过调用get_task_logger(task_name)来接收特定的任务记录器。 为了概括每个任务的这种行为,有必要使用一些实用方法稍微扩展celery.current_app.Task :
文件: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) 现在,在调用task.log_msg("Hello, my name is: %s", task.request.id)的情况下,日志输出将被路由到任务名称下的相应文件。
试一试
为了启动和测试这个任务是如何工作的,首先启动 Celery 进程:
$ celery -A celery_uncovered worker -l info然后您将能够通过 Shell 测试功能:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) 最后,要查看结果,导航到celery_uncovered/logs目录并打开名为celery_uncovered.tricks.tasks.add.log的相应日志文件。 多次运行此任务后,您可能会看到类似以下内容:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...场景 4 - 范围感知任务
让我们想象一个基于 Celery 和 Django 构建的面向国际用户的 Python 应用程序。 用户可以设置他们使用您的应用程序的语言(区域设置)。
您必须设计一个多语言、区域感知的电子邮件通知系统。 要发送电子邮件通知,您已经注册了一个由特定队列处理的特殊 Celery 任务。 此任务接收一些关键参数作为输入和当前用户区域设置,以便以用户选择的语言发送电子邮件。
现在想象我们有很多这样的任务,但是每个任务都接受一个语言环境参数。 在这种情况下,在更高的抽象层次上解决它不是更好吗? 在这里,我们看到了如何做到这一点。
用例描述:自动从一个执行上下文继承作用域,并将其作为参数注入到当前执行上下文中。
实施细节
同样,正如我们对任务日志所做的那样,我们想要扩展一个基本任务类celery.current_app.Task并覆盖一些负责调用任务的方法。 出于本演示的目的,我将覆盖celery.current_app.Task::apply_async方法。 该模块还有一些额外的任务可以帮助您制作功能齐全的替代品。
文件: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)关键线索是默认将当前语言环境作为键值参数传递给调用任务。 如果使用特定语言环境作为参数调用任务,则它不会更改。
试一试
为了测试这个功能,让我们定义一个ScopeBasedTask类型的虚拟任务。 它通过语言环境 ID 定位文件并将其内容读取为 JSON:
文件: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) 现在您需要做的是重复启动 Celery、启动 shell 以及在不同场景下测试此任务的执行的步骤。 Fixtures 位于celery_uncovered/tricks/fixtures/locales/目录下。
结论
这篇文章旨在从不同的角度探索 Celery。 我在常规示例中演示了 Celery,例如邮件和报告生成,以及一些有趣的小众业务用例的共享技巧。 Celery 建立在数据驱动的理念之上,您的团队可以通过将其作为系统堆栈的一部分来简化他们的生活。 如果你有基本的 Python 经验,开发基于 Celery 的服务并不是很复杂,而且你应该能够很快上手。 默认配置足以满足大多数用途,但如果需要,它们可以非常灵活。
我们的团队选择使用 Celery 作为后台作业和长时间运行任务的编排后端。 我们将它广泛用于各种用例,本文中只提到了其中的几个。 我们每天摄取和分析千兆字节的数据,但这只是水平扩展技术的开始。