
Organización de un flujo de trabajo de trabajo en segundo plano en Celery para Python
Publicado: 2022-03-11Las aplicaciones web modernas y sus sistemas subyacentes son más rápidos y receptivos que nunca. Sin embargo, todavía hay muchos casos en los que desea descargar la ejecución de una tarea pesada a otras partes de la arquitectura de su sistema completo en lugar de abordarlas en su hilo principal. Identificar tales tareas es tan simple como verificar si pertenecen a una de las siguientes categorías:
- Tareas periódicas: trabajos que programará para que se ejecuten a una hora específica o después de un intervalo, por ejemplo, la generación de informes mensuales o un web scraper que se ejecuta dos veces al día.
- Tareas de terceros: la aplicación web debe atender a los usuarios rápidamente sin esperar a que se completen otras acciones mientras se carga la página, por ejemplo, enviar un correo electrónico o una notificación o propagar actualizaciones a herramientas internas (como recopilar datos para pruebas A/B o registro del sistema). ).
- Trabajos de ejecución prolongada: trabajos que son costosos en recursos, donde los usuarios deben esperar mientras calculan sus resultados, por ejemplo, ejecución de flujo de trabajo complejo (flujos de trabajo DAG), generación de gráficos, tareas similares a Map-Reduce y servicio de contenido multimedia (video, audio).
Una solución sencilla para ejecutar una tarea en segundo plano sería ejecutarla dentro de un hilo o proceso separado. Python es un lenguaje de programación completo de Turing de alto nivel, que desafortunadamente no proporciona una concurrencia integrada en una escala que coincida con la de Erlang, Go, Java, Scala o Akka. Estos se basan en los procesos secuenciales de comunicación (CSP) de Tony Hoare. Los subprocesos de Python, por otro lado, están coordinados y programados por el bloqueo de intérprete global (GIL), que evita que varios subprocesos nativos ejecuten códigos de bytes de Python a la vez. Deshacerse de GIL es un tema de mucha discusión entre los desarrolladores de Python, pero no es el enfoque de este artículo. La programación concurrente en Python es anticuada, aunque le invitamos a leer sobre ella en el Tutorial de subprocesos múltiples de Python del compañero Toptaler Marcus McCurdy. Por lo tanto, diseñar la comunicación entre procesos de manera consistente es un proceso propenso a errores y conduce a un acoplamiento de código y una mala capacidad de mantenimiento del sistema, sin mencionar que afecta negativamente la escalabilidad. Además, el proceso de Python es un proceso normal bajo un sistema operativo (SO) y, con toda la biblioteca estándar de Python, se convierte en un peso pesado. A medida que aumenta la cantidad de procesos en la aplicación, cambiar de uno a otro se convierte en una operación que requiere mucho tiempo.
Para comprender mejor la concurrencia con Python, vea este increíble discurso de David Beazley en PyCon'15.
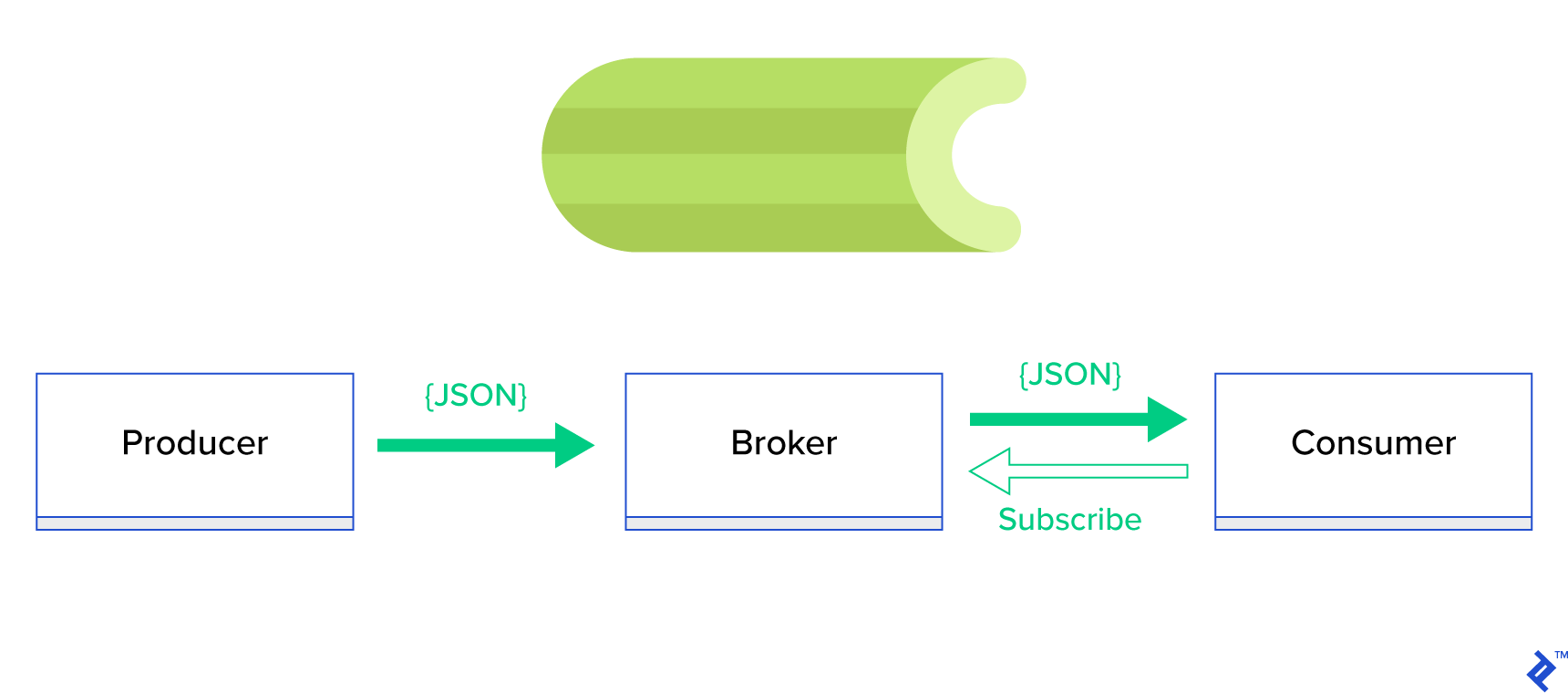
Una solución mucho mejor es servir una cola distribuida o su conocido paradigma hermano llamado publicación-suscripción . Como se muestra en la Figura 1, hay dos tipos de aplicaciones en las que una, llamada publicador , envía mensajes y la otra, llamada suscriptor , recibe mensajes. Esos dos agentes no interactúan entre sí directamente y ni siquiera se conocen. Los editores envían mensajes a una cola central o intermediario y los suscriptores reciben mensajes de interés de este intermediario. Hay dos ventajas principales en este método:
- Escalabilidad: no es necesario que los agentes se conozcan entre sí en la red. Están enfocados por tema. Por lo tanto, significa que cada uno puede continuar funcionando normalmente independientemente del otro de manera asíncrona.
- Bajo acoplamiento: cada agente representa su parte del sistema (servicio, módulo). Dado que están poco acoplados, cada uno puede escalar individualmente más allá del centro de datos.
Hay muchos sistemas de mensajería que admiten dichos paradigmas y proporcionan una API ordenada, impulsada por protocolos TCP o HTTP, por ejemplo, JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ, etc.
¿Qué es el apio?
Celery es uno de los administradores de trabajos en segundo plano más populares en el mundo de Python. Celery es compatible con varios intermediarios de mensajes como RabbitMQ o Redis y puede actuar tanto como productor como consumidor.
El apio es una cola de tareas/cola de trabajos asíncrona basada en el paso de mensajes distribuidos. Se centra en las operaciones en tiempo real, pero también admite la programación. Las unidades de ejecución, denominadas tareas, se ejecutan simultáneamente en uno o más servidores de trabajo mediante multiprocesamiento, Eventlet o gevent. Las tareas se pueden ejecutar de forma asincrónica (en segundo plano) o sincrónicamente (esperar hasta que estén listas). – Proyecto Apio
Para comenzar con Celery, simplemente siga una guía paso a paso en los documentos oficiales.
El enfoque de este artículo es brindarle una buena comprensión de qué casos de uso podría cubrir Celery. En este artículo, no solo mostraremos ejemplos interesantes, sino que también intentaremos aprender cómo aplicar Celery a tareas del mundo real, como el envío de correos en segundo plano, la generación de informes, el registro y el informe de errores. Compartiré mi forma de probar las tareas más allá de la emulación y, finalmente, proporcionaré algunos trucos que no están (bien) documentados en la documentación oficial y que me llevó horas de investigación descubrir por mí mismo.
Si no tienes experiencia previa con Celery, te animo a probarlo primero siguiendo el tutorial oficial.
Abriendo su apetito
Si este artículo te intriga y te hace querer sumergirte en el código de inmediato, sigue este repositorio de GitHub para ver el código utilizado en este artículo. El archivo README allí le dará el enfoque rápido y sucio para ejecutar y jugar con las aplicaciones de ejemplo.
Primeros pasos con apio
Para empezar, veremos una serie de ejemplos prácticos que mostrarán al lector con qué sencillez y elegancia Celery resuelve tareas aparentemente no triviales. Todos los ejemplos se presentarán dentro del marco Django; sin embargo, la mayoría de ellos podrían migrarse fácilmente a otros marcos de Python (Flask, Pyramid).
El diseño del proyecto fue generado por Cookiecutter Django; sin embargo, solo mantuve algunas dependencias que, en mi opinión, facilitan el desarrollo y preparación de estos casos de uso. También eliminé módulos innecesarios para esta publicación y aplicaciones para reducir el ruido y hacer que el código sea más fácil de entender.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}contiene diferentes aplicaciones que cubriremos en esta publicación. Cada aplicación contiene un conjunto de ejemplos organizados por el nivel de comprensión del apio requerido. -
celery_uncovered/celery.pydefine una instancia de Celery.
Archivo: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Entonces debemos estar seguros de que Celery comenzará junto con Django. Por esa razón, importamos la aplicación en celery_uncovered/__init__.py .
Archivo: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings es la fuente de configuración de nuestra aplicación y Celery. Según el entorno de ejecución, Django lanzará la configuración correspondiente: local.py para desarrollo o test.py para prueba. También puede definir su propio entorno si lo desea creando un nuevo módulo de python (por ejemplo, prod.py ). Las configuraciones de apio tienen el prefijo CELERY_ . Para esta publicación, configuré RabbitMQ como intermediario y SQLite como resultado final.
Archivo: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Escenario 1: generación y exportación de informes
El primer caso que cubriremos es la generación y exportación de informes. En este ejemplo, aprenderá a definir una tarea que genera un informe CSV y a programarla a intervalos regulares con celerybeat.
Descripción del caso de uso: obtenga los quinientos repositorios más populares de GitHub por período elegido (día, semana, mes), agrúpelos por temas y exporte el resultado al archivo CSV.
Si proporcionamos un servicio HTTP que ejecutará esta función activada al hacer clic en un botón con la etiqueta "Generar informe", la aplicación se detendría y esperaría a que se completara la tarea antes de enviar una respuesta HTTP. Esto es malo. Queremos que nuestra aplicación web sea rápida y no queremos que nuestros usuarios esperen mientras nuestro back-end calcula los resultados. En lugar de esperar a que se produzcan los resultados, preferimos poner en cola la tarea en los procesos de trabajo a través de una cola registrada en Celery y responder con un task_id al front-end. Luego, el front-end usaría task_id para consultar el resultado de la tarea de manera asincrónica (por ejemplo, AJAX) y mantendrá al usuario actualizado con el progreso de la tarea. Finalmente, cuando finaliza el proceso, los resultados se pueden servir como un archivo para descargar a través de HTTP.
Detalles de implementacion
En primer lugar, descompongamos el proceso en sus unidades más pequeñas posibles y creemos una canalización:
- Los buscadores son los trabajadores responsables de obtener repositorios del servicio de GitHub.
- El agregador es el trabajador responsable de consolidar los resultados en una lista.
- El importador es el trabajador que produce informes CSV de los repositorios más populares en GitHub.
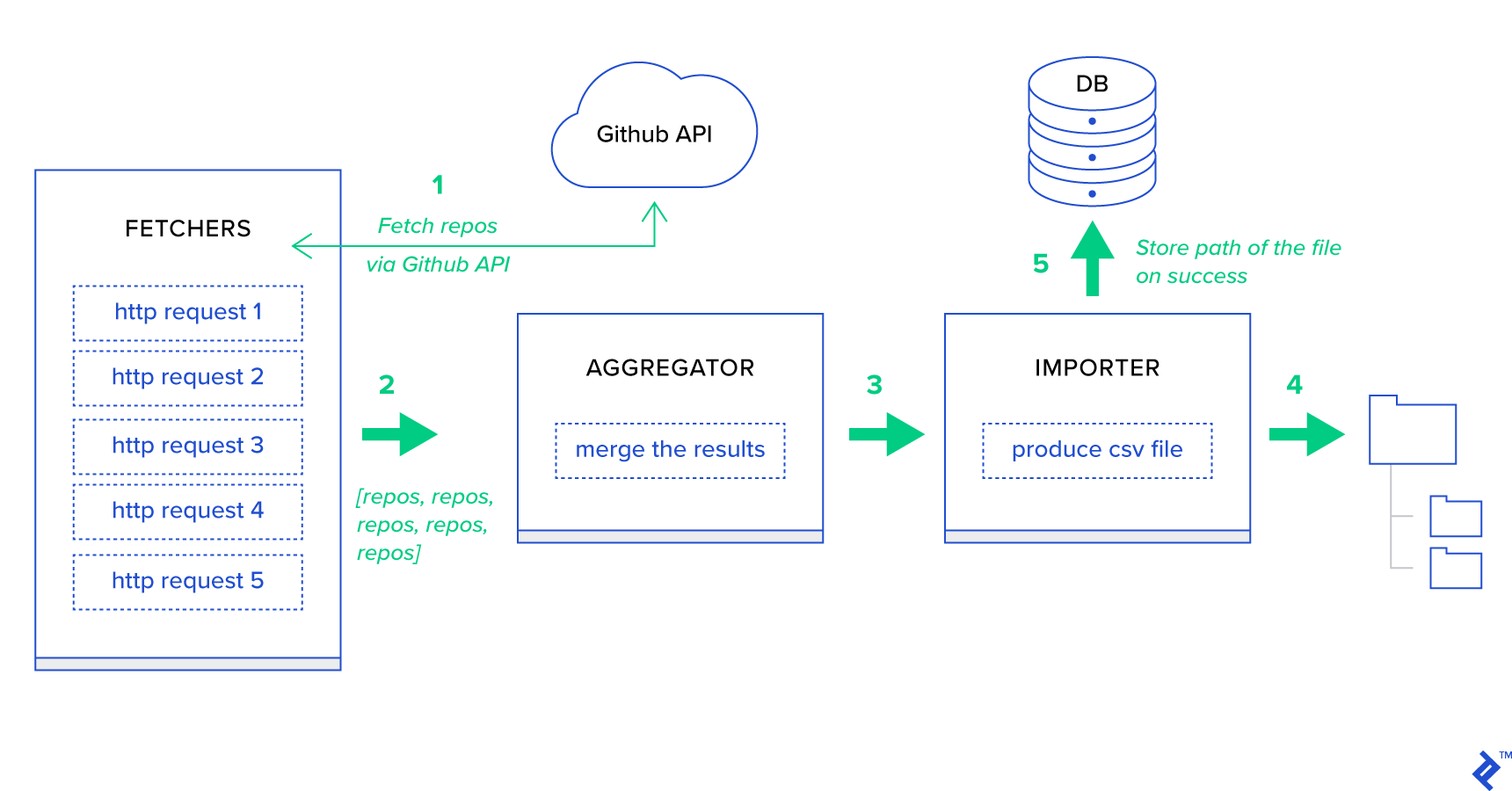
La obtención de repositorios es una solicitud HTTP que utiliza la API de búsqueda de GitHub GET /search/repositories . Sin embargo, hay una limitación del servicio API de GitHub que debe manejarse: la API devuelve hasta 100 repositorios por solicitud en lugar de 500. Podríamos enviar cinco solicitudes una a la vez, pero no queremos hacer esperar a nuestro usuario. para cinco solicitudes individuales, ya que las solicitudes HTTP son una operación vinculada de E/S. En su lugar, podemos ejecutar cinco solicitudes HTTP simultáneas con un parámetro de página adecuado. Entonces la página estará en el rango [1..5]. Definamos una tarea llamada fetch_hot_repos/3 -> list en el módulo toyex/tasks.py :
Archivo: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Entonces, fetch_hot_repos crea una solicitud a la API de GitHub y responde al usuario con una lista de repositorios. Recibe tres parámetros que definirán el payload de nuestra solicitud:
-
since— Filtra los repositorios en la fecha de creación. -
per_page— Número de resultados a devolver por solicitud (limitado por 100). -
page—- Número de página solicitado (en el rango [1..5]).
Nota: para utilizar la API de búsqueda de GitHub, necesitará un token de OAuth para pasar las comprobaciones de autenticación. En nuestro caso, se guarda en la configuración en GITHUB_OAUTH .
A continuación, debemos definir una tarea maestra que será responsable de agregar los resultados y exportarlos a un archivo CSV: produce_hot_repo_report_task/2->filepath:
Archivo: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Esta tarea usa celery.canvas.group para ejecutar cinco llamadas simultáneas de fetch_hot_repos/3 . Esos resultados se esperan y luego se reducen a una lista de objetos del repositorio. Luego, nuestro conjunto de resultados se agrupa por tema y finalmente se exporta a un archivo CSV generado en el directorio MEDIA_ROOT/ .
Para programar la tarea periódicamente, es posible que desee agregar una entrada a la lista de programación en el archivo de configuración:
Archivo: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }probandolo
Para iniciar y probar cómo funciona la tarea, primero debemos iniciar el proceso Celery:
$ celery -A celery_uncovered worker -l info A continuación, debemos crear el celery_uncovered/media/ . Luego, podrá probar su funcionalidad a través de Shell o Celerybeat:
Concha :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Batido de apio :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Puede ver los resultados en el directorio MEDIA_ROOT/ .
Escenario 2: informe sobre errores del servidor 500 por correo electrónico
Uno de los casos de uso más comunes de Celery es el envío de notificaciones por correo electrónico. La notificación por correo electrónico es una operación enlazada de E/S fuera de línea que aprovecha un servidor SMTP local o un SES de terceros. Hay muchos casos de uso que involucran el envío de un correo electrónico y, para la mayoría de ellos, el usuario no necesita esperar hasta que finalice este proceso para recibir una respuesta HTTP. Es por eso que se prefiere ejecutar dichas tareas en segundo plano y responder al usuario de inmediato.
Descripción del caso de uso: informe de errores 50X al correo electrónico del administrador a través de Celery.
Python y Django tienen la experiencia necesaria para realizar el registro del sistema. No entraré en detalles sobre cómo funciona realmente el registro de Python. Sin embargo, si nunca lo ha probado antes o necesita una actualización, lea la documentación del módulo de registro integrado. Definitivamente quiere esto en su entorno de producción. Django tiene un controlador de registro especial llamado AdminEmailHandler que envía correos electrónicos a los administradores por cada mensaje de registro que recibe.
Detalles de implementacion
La idea principal es extender el método send_mail de la clase AdminEmailHandler de tal manera que pueda enviar correo a través de Celery. Esto podría hacerse como se ilustra en la siguiente figura:
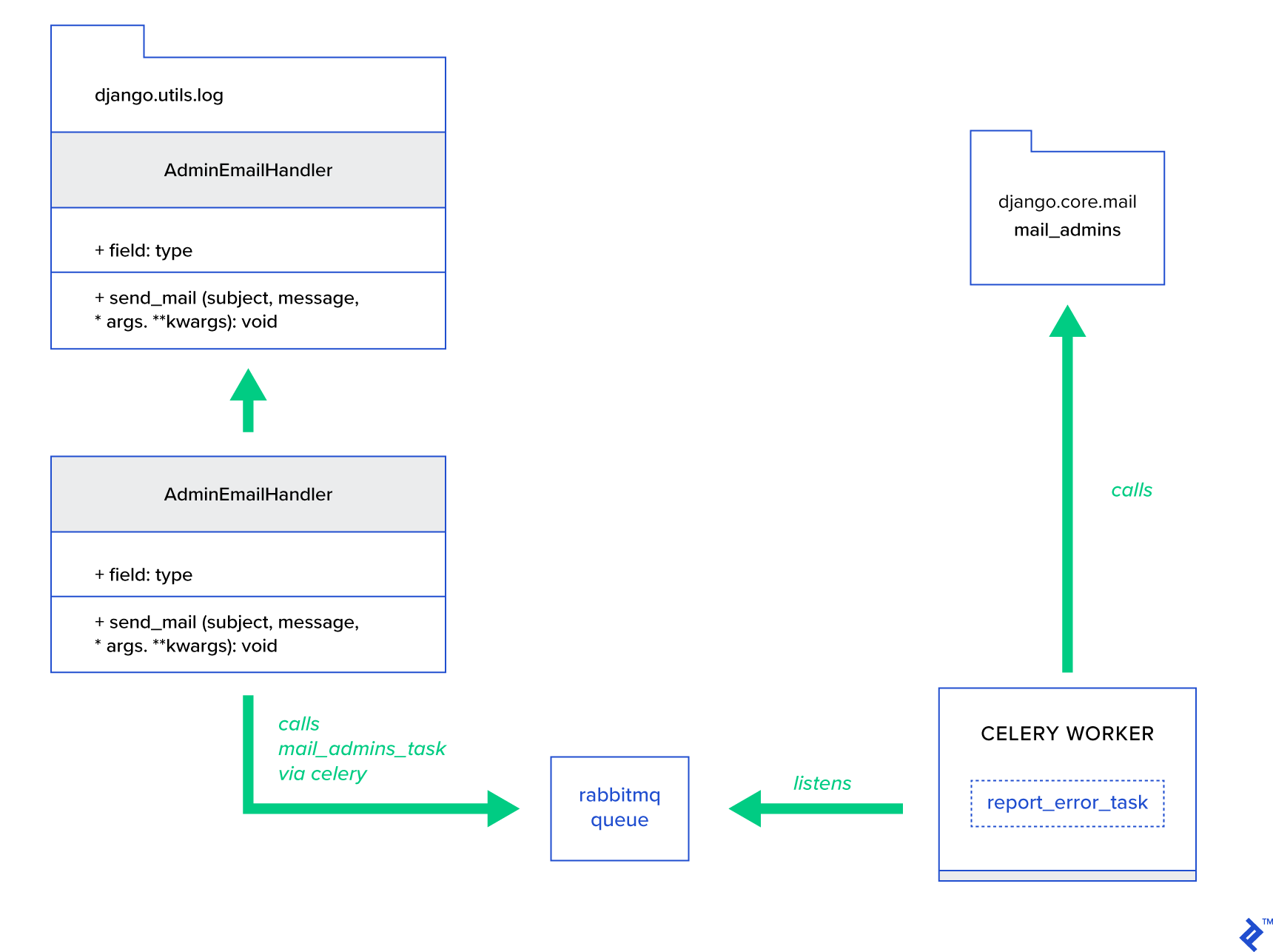
Primero, debemos configurar una tarea llamada report_error_task que llame a mail_admins con el asunto y el mensaje provistos:
Archivo: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)A continuación, en realidad ampliamos AdminEmailHandler para que llame internamente solo a la tarea Celery definida:
Archivo: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Finalmente, necesitamos configurar el registro. La configuración del inicio de sesión en Django es bastante sencilla. Lo que necesita es anular LOGGING para que el motor de registro comience a usar un controlador recién definido:
Archivo config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Tenga en cuenta que intencionalmente configuré los filtros de controlador require_debug_true para probar esta funcionalidad mientras la aplicación se ejecuta en modo de depuración.
probandolo
Para probarlo, preparé una vista de Django que sirve una operación de "división por cero" en localhost:8000/report-error . También debe iniciar un contenedor MailHog Docker para probar que el correo electrónico se envió realmente.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Detalles adicionales
Como herramienta de prueba de correo, configuré MailHog y configuré el correo de Django para usarlo para la entrega SMTP. Hay muchas formas de implementar y ejecutar MailHog. Decidí ir con un contenedor Docker. Puede encontrar los detalles en el archivo README correspondiente:
Archivo: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Para configurar su aplicación para usar MailHog, debe agregar las siguientes líneas en su configuración:
Archivo: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Más allá de las tareas de apio predeterminadas
Las tareas de apio se pueden crear a partir de cualquier función invocable. De forma predeterminada, cualquier tarea definida por el usuario se inyecta con celery.app.task.Task como clase principal (abstracta). Esta clase contiene la funcionalidad de ejecutar tareas de forma asincrónica (pasándola a través de la red a un trabajador de Celery) o sincrónicamente (con fines de prueba), creando firmas y muchas otras utilidades. En los siguientes ejemplos, intentaremos extender Celery.app.task.Task y luego usarlo como clase base para agregar algunos comportamientos útiles a nuestras tareas.
Escenario 3: registro de archivos por tarea
En uno de mis proyectos, estaba desarrollando una aplicación que brinda al usuario final una herramienta similar a Extraer, Transformar, Cargar (ETL) que podía ingerir y luego filtrar una gran cantidad de datos jerárquicos. El back-end se dividió en dos módulos:
- Orquestación de una canalización de procesamiento de datos con Celery
- Procesamiento de datos con Go
Celery se implementó con una instancia de Celerybeat y más de 40 trabajadores. Había más de veinte tareas diferentes que componían las actividades de canalización y orquestación. Cada una de estas tareas puede fallar en algún momento. Todas estas fallas se volcaron en el registro del sistema de cada trabajador. En algún momento, comenzó a ser un inconveniente depurar y mantener la capa Celery. Finalmente, decidimos aislar el registro de tareas en un archivo específico de tareas.
Descripción del caso de uso: Amplíe Celery para que cada tarea registre su salida estándar y los errores en los archivos
Celery proporciona a las aplicaciones de Python un gran control sobre lo que hace internamente. Se envía con un marco de señales familiar. Las aplicaciones que usan Celery pueden suscribirse a algunas de ellas para aumentar el comportamiento de ciertas acciones. Vamos a aprovechar las señales a nivel de tareas para proporcionar un seguimiento detallado de los ciclos de vida de las tareas individuales. El apio siempre viene con un back-end de registro, y vamos a aprovecharlo mientras solo lo anulamos ligeramente en algunos lugares para lograr nuestros objetivos.
Detalles de implementacion
Celery ya admite el registro por tarea. Para guardar en un archivo, es necesario enviar la salida del registro a la ubicación adecuada. En nuestro caso, la ubicación adecuada de la tarea es un archivo que coincida con el nombre de la tarea. En la instancia de Celery, anularemos la configuración de registro integrada con controladores de registro inferidos dinámicamente. Es posible suscribirse a la señal celeryd_after_setup y luego configurar el registro del sistema allí:
Archivo: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Tenga en cuenta que para cada tarea registrada en la aplicación Celery, estamos creando un registrador correspondiente con su controlador. Cada controlador es del tipo logging.FileHandler y, por lo tanto, cada instancia recibe un nombre de archivo como entrada. Todo lo que necesita para que esto funcione es importar este módulo a celery_uncovered/celery.py al final del archivo:
import celery_uncovered.tricks.celery_conf Se puede recibir un registrador de tareas en particular llamando a get_task_logger(task_name) . Para generalizar tal comportamiento para cada tarea, es necesario extender ligeramente celery.current_app.Task con algunos métodos de utilidad:
Archivo: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Ahora, en el caso de una llamada a task.log_msg("Hello, my name is: %s", task.request.id) , la salida del registro se enrutará al archivo correspondiente bajo el nombre de la tarea.
probandolo
Para iniciar y probar cómo funciona esta tarea, primero inicie el proceso Celery:
$ celery -A celery_uncovered worker -l infoEntonces podrá probar la funcionalidad a través de Shell:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Finalmente, para ver el resultado, navegue hasta el directorio celery_uncovered/logs y abra el archivo de registro correspondiente llamado celery_uncovered.tricks.tasks.add.log . Es posible que vea algo similar a lo siguiente después de ejecutar esta tarea varias veces:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Escenario 4: tareas conscientes del alcance
Imaginemos una aplicación de Python para usuarios internacionales que se basa en Celery y Django. Los usuarios pueden establecer en qué idioma (configuración regional) usan su aplicación.
Tiene que diseñar un sistema de notificación por correo electrónico multilingüe que tenga en cuenta la configuración regional. Para enviar notificaciones por correo electrónico, ha registrado una tarea especial de Celery que es manejada por una cola específica. Esta tarea recibe algunos argumentos clave como entrada y una configuración regional actual del usuario para que el correo electrónico se envíe en el idioma elegido por el usuario.
Ahora imagine que tenemos muchas tareas de este tipo, pero cada una de esas tareas acepta un argumento local. En este caso, ¿no sería mejor resolverlo en un mayor nivel de abstracción? Aquí vemos cómo hacerlo.
Descripción del caso de uso: Herede automáticamente el alcance de un contexto de ejecución e inyéctelo en el contexto de ejecución actual como un parámetro.
Detalles de implementacion
Nuevamente, como hicimos con el registro de tareas, queremos extender una clase de tarea base celery.current_app.Task y anular algunos métodos responsables de llamar a las tareas. Para el propósito de esta demostración, anularé el método celery.current_app.Task::apply_async . Hay tareas adicionales para este módulo que lo ayudarán a producir un reemplazo completamente funcional.
Archivo: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)La pista clave es pasar la configuración regional actual como un argumento clave-valor en una tarea de llamada de forma predeterminada. Si se llamó a una tarea con una configuración regional determinada como argumento, no se modifica.
probandolo
Para probar esta funcionalidad, definamos una tarea ficticia de tipo ScopeBasedTask . Localiza un archivo por ID de configuración regional y lee su contenido como JSON:
Archivo: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Ahora, lo que debe hacer es repetir los pasos de iniciar Celery, iniciar el shell y probar la ejecución de esta tarea en diferentes escenarios. Los accesorios se encuentran en el celery_uncovered/tricks/fixtures/locales/ .
Conclusión
Esta publicación tuvo como objetivo explorar el apio desde diferentes perspectivas. Demostré Celery en ejemplos convencionales, como correo y generación de informes, así como trucos compartidos para algunos casos de uso de negocios de nicho interesantes. Celery se basa en una filosofía basada en datos y su equipo puede hacer sus vidas mucho más simples al introducirlo como parte de su pila de sistema. El desarrollo de servicios basados en Celery no es muy complicado si tiene experiencia básica en Python, y debería poder aprenderlo con bastante rapidez. La configuración predeterminada es lo suficientemente buena para la mayoría de los usos, pero si es necesario, pueden ser muy flexibles.
Nuestro equipo tomó la decisión de usar Celery como back-end de orquestación para trabajos en segundo plano y tareas de ejecución prolongada. Lo usamos ampliamente para una variedad de casos de uso, de los cuales solo algunos se mencionaron en esta publicación. Ingresamos y analizamos gigabytes de datos todos los días, pero esto es solo el comienzo de las técnicas de escalado horizontal.