
Orchestration d'un flux de travail en arrière-plan dans Celery pour Python
Publié: 2022-03-11Les applications Web modernes et leurs systèmes sous-jacents sont plus rapides et plus réactifs que jamais. Cependant, il existe encore de nombreux cas où vous souhaitez décharger l'exécution d'une tâche lourde sur d'autres parties de l'ensemble de votre architecture système au lieu de les aborder sur votre thread principal. Pour identifier ces tâches, il suffit de vérifier si elles appartiennent à l'une des catégories suivantes :
- Tâches périodiques — Travaux que vous planifierez pour s'exécuter à une heure précise ou après un intervalle, par exemple, la génération de rapports mensuels ou un grattoir Web qui s'exécute deux fois par jour.
- Tâches tierces - L'application Web doit servir les utilisateurs rapidement sans attendre que d'autres actions se terminent pendant le chargement de la page, par exemple, envoyer un e-mail ou une notification ou propager des mises à jour vers des outils internes (comme la collecte de données pour les tests A/B ou la journalisation du système). ).
- Tâches de longue durée — Tâches coûteuses en ressources, où les utilisateurs doivent attendre pendant qu'ils calculent leurs résultats, par exemple, l'exécution de flux de travail complexes (flux de travail DAG), la génération de graphiques, les tâches de type Map-Reduce et la diffusion de contenu multimédia (vidéo, l'audio).
Une solution simple pour exécuter une tâche en arrière-plan serait de l'exécuter dans un thread ou un processus séparé. Python est un langage de programmation complet de Turing de haut niveau, qui ne fournit malheureusement pas de simultanéité intégrée à une échelle correspondant à celle d'Erlang, Go, Java, Scala ou Akka. Ceux-ci sont basés sur les processus séquentiels de communication (CSP) de Tony Hoare. Les threads Python, d'autre part, sont coordonnés et planifiés par le verrou d'interpréteur global (GIL), qui empêche plusieurs threads natifs d'exécuter des bytecodes Python à la fois. Se débarrasser du GIL fait l'objet de nombreuses discussions parmi les développeurs Python, mais ce n'est pas l'objet de cet article. La programmation simultanée en Python est démodée, bien que vous soyez invités à lire à ce sujet dans Python Multithreading Tutorial par son collègue Toptaler Marcus McCurdy. Ainsi, la conception cohérente de la communication entre les processus est un processus sujet aux erreurs et conduit à un couplage de code et à une mauvaise maintenabilité du système, sans oublier qu'il affecte négativement l'évolutivité. De plus, le processus Python est un processus normal sous un système d'exploitation (OS) et, avec l'ensemble de la bibliothèque standard Python, il devient un poids lourd. À mesure que le nombre de processus dans l'application augmente, le passage d'un processus à un autre devient une opération chronophage.
Pour mieux comprendre la concurrence avec Python, regardez cet incroyable discours de David Beazley à PyCon'15.
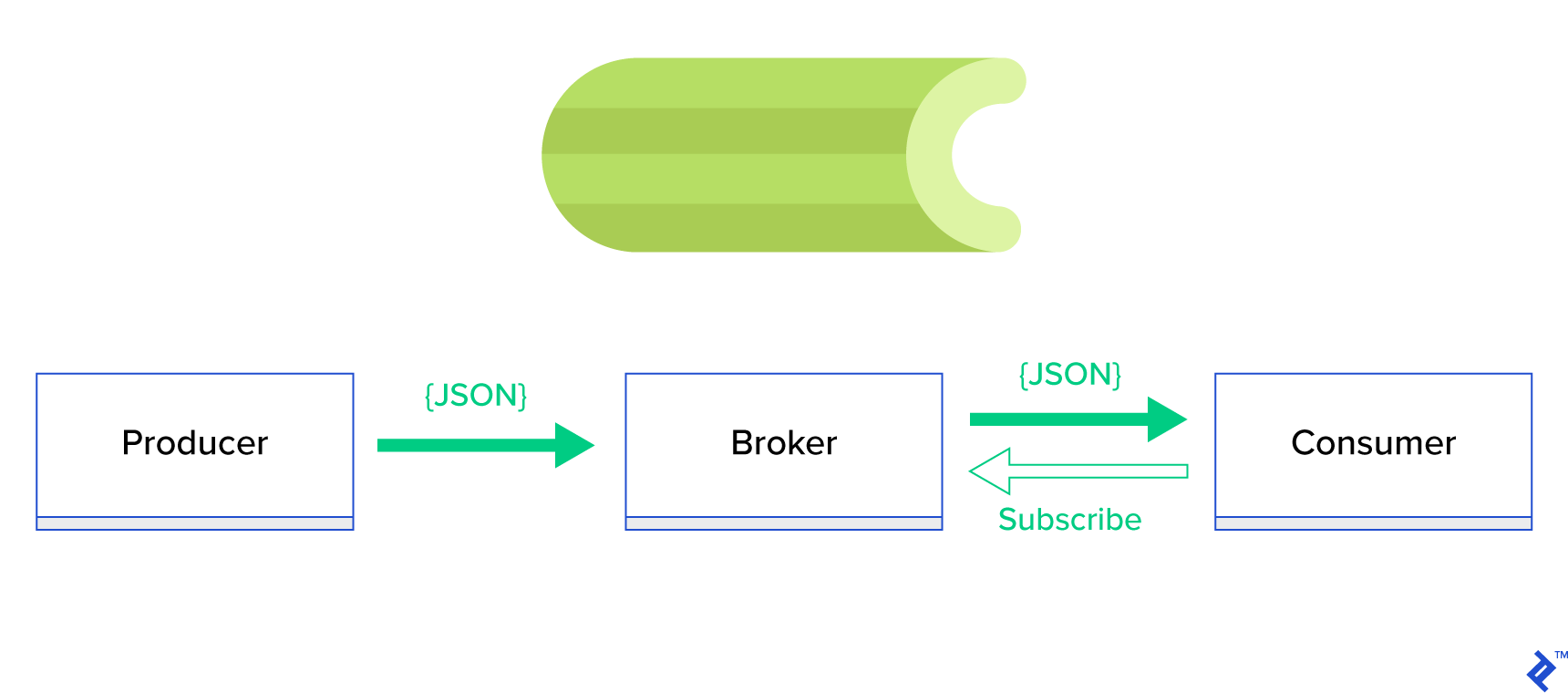
Une bien meilleure solution consiste à servir une file d' attente distribuée ou son paradigme frère bien connu appelé publish-subscribe . Comme le montre la figure 1, il existe deux types d'applications dans lesquelles l'une, appelée éditeur , envoie des messages et l'autre, appelée abonné , reçoit des messages. Ces deux agents n'interagissent pas directement l'un avec l'autre et ne sont même pas conscients l'un de l'autre. Les éditeurs envoient des messages à une file d'attente centrale, ou courtier , et les abonnés reçoivent les messages qui les intéressent de ce courtier. Il y a deux avantages principaux à cette méthode :
- Évolutivité — les agents n'ont pas besoin de se connaître dans le réseau. Ils sont ciblés par thème. Cela signifie donc que chacun peut continuer à fonctionner normalement indépendamment de l'autre de manière asynchrone.
- Couplage lâche — chaque agent représente sa partie du système (service, module). Puisqu'ils sont faiblement couplés, chacun peut évoluer individuellement au-delà du centre de données.
Il existe de nombreux systèmes de messagerie qui prennent en charge de tels paradigmes et fournissent une API soignée, pilotée par des protocoles TCP ou HTTP, par exemple, JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ, etc.
Qu'est-ce que le céleri ?
Celery est l'un des gestionnaires de tâches d'arrière-plan les plus populaires dans le monde Python. Celery est compatible avec plusieurs courtiers de messages comme RabbitMQ ou Redis et peut agir à la fois en tant que producteur et consommateur.
Celery est une file d'attente de tâches/de travaux asynchrone basée sur le passage de messages distribués. Il est axé sur les opérations en temps réel, mais prend également en charge la planification. Les unités d'exécution, appelées tâches, sont exécutées simultanément sur un ou plusieurs serveurs de travail à l'aide du multitraitement, d'Eventlet ou de gevent. Les tâches peuvent s'exécuter de manière asynchrone (en arrière-plan) ou synchrone (attendre d'être prête). – Projet Céleri
Pour commencer avec Celery, suivez simplement un guide étape par étape dans la documentation officielle.
L'objectif de cet article est de vous donner une bonne compréhension des cas d'utilisation qui pourraient être couverts par Celery. Dans cet article, nous allons non seulement montrer des exemples intéressants, mais également essayer d'apprendre à appliquer Celery à des tâches réelles telles que l'envoi de courrier en arrière-plan, la génération de rapports, la journalisation et le rapport d'erreurs. Je partagerai ma façon de tester les tâches au-delà de l'émulation et, enfin, je fournirai quelques astuces qui ne sont pas (bien) documentées dans la documentation officielle qui m'ont demandé des heures de recherche pour les découvrir par moi-même.
Si vous n'avez aucune expérience préalable avec Celery, je vous encourage d'abord à l'essayer en suivant le tutoriel officiel.
Aiguiser votre appétit
Si cet article vous intrigue et vous donne envie de plonger immédiatement dans le code, suivez ce référentiel GitHub pour le code utilisé dans cet article. Le fichier README vous donnera l'approche rapide et sale pour exécuter et jouer avec les exemples d'applications.
Premiers pas avec le céleri
Pour commencer, nous allons parcourir une série d'exemples pratiques qui montreront au lecteur à quel point Celery résout simplement et avec élégance des tâches apparemment non triviales. Tous les exemples seront présentés dans le cadre de Django ; cependant, la plupart d'entre eux pourraient facilement être portés sur d'autres frameworks Python (Flask, Pyramid).
La mise en page du projet a été générée par Cookiecutter Django ; cependant, je n'ai gardé que quelques dépendances qui, à mon avis, facilitent le développement et la préparation de ces cas d'utilisation. J'ai également supprimé les modules inutiles pour cet article et les applications afin de réduire le bruit et de rendre le code plus facile à comprendre.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}contient différentes applications que nous aborderons dans cet article. Chaque application contient un ensemble d'exemples organisés par le niveau de compréhension du céleri requis. -
celery_uncovered/celery.pydéfinit une instance Celery.
Fichier : celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Ensuite, nous devons nous assurer que Celery démarrera avec Django. Pour cette raison, nous importons l'application dans celery_uncovered/__init__.py .
Fichier : celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings est la source de configuration de notre application et de Celery. Selon l'environnement d'exécution, Django lancera les paramètres correspondants : local.py pour le développement ou test.py pour les tests. Vous pouvez également définir votre propre environnement si vous le souhaitez en créant un nouveau module python (par exemple, prod.py ). Les configurations Celery sont préfixées par CELERY_ . Pour cet article, j'ai configuré RabbitMQ en tant que courtier et SQLite en tant que résultat bac-end.
Fichier : config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Scénario 1 - Génération et exportation de rapports
Le premier cas que nous allons couvrir est la génération et l'exportation de rapports. Dans cet exemple, vous apprendrez à définir une tâche qui produit un rapport CSV et à la programmer à intervalles réguliers avec celerybeat.
Description du cas d'utilisation : récupérez les cinq cents référentiels les plus populaires de GitHub par période choisie (jour, semaine, mois), regroupez-les par thèmes et exportez le résultat vers le fichier CSV.
Si nous fournissons un service HTTP qui exécutera cette fonctionnalité déclenchée en cliquant sur un bouton intitulé "Générer un rapport", l'application s'arrêtera et attendra que la tâche soit terminée avant de renvoyer une réponse HTTP. C'est mauvais. Nous voulons que notre application Web soit rapide et nous ne voulons pas que nos utilisateurs attendent pendant que notre back-end calcule les résultats. Au lieu d'attendre que les résultats soient produits, nous préférons mettre la tâche en file d'attente dans les processus de travail via une file d'attente enregistrée dans Celery et répondre avec un task_id au front-end. Ensuite, le frontal utiliserait le task_id pour interroger le résultat de la tâche de manière asynchrone (par exemple, AJAX) et tiendra l'utilisateur informé de la progression de la tâche. Enfin, lorsque le processus est terminé, les résultats peuvent être servis sous forme de fichier à télécharger via HTTP.
Détails d'implémentation
Tout d'abord, décomposons le processus en ses plus petites unités possibles et créons un pipeline :
- Les récupérateurs sont les travailleurs chargés d'obtenir les référentiels du service GitHub.
- L' agrégateur est le travailleur responsable de la consolidation des résultats dans une seule liste.
- L' importateur est le travailleur qui produit des rapports CSV des référentiels les plus chauds dans GitHub.
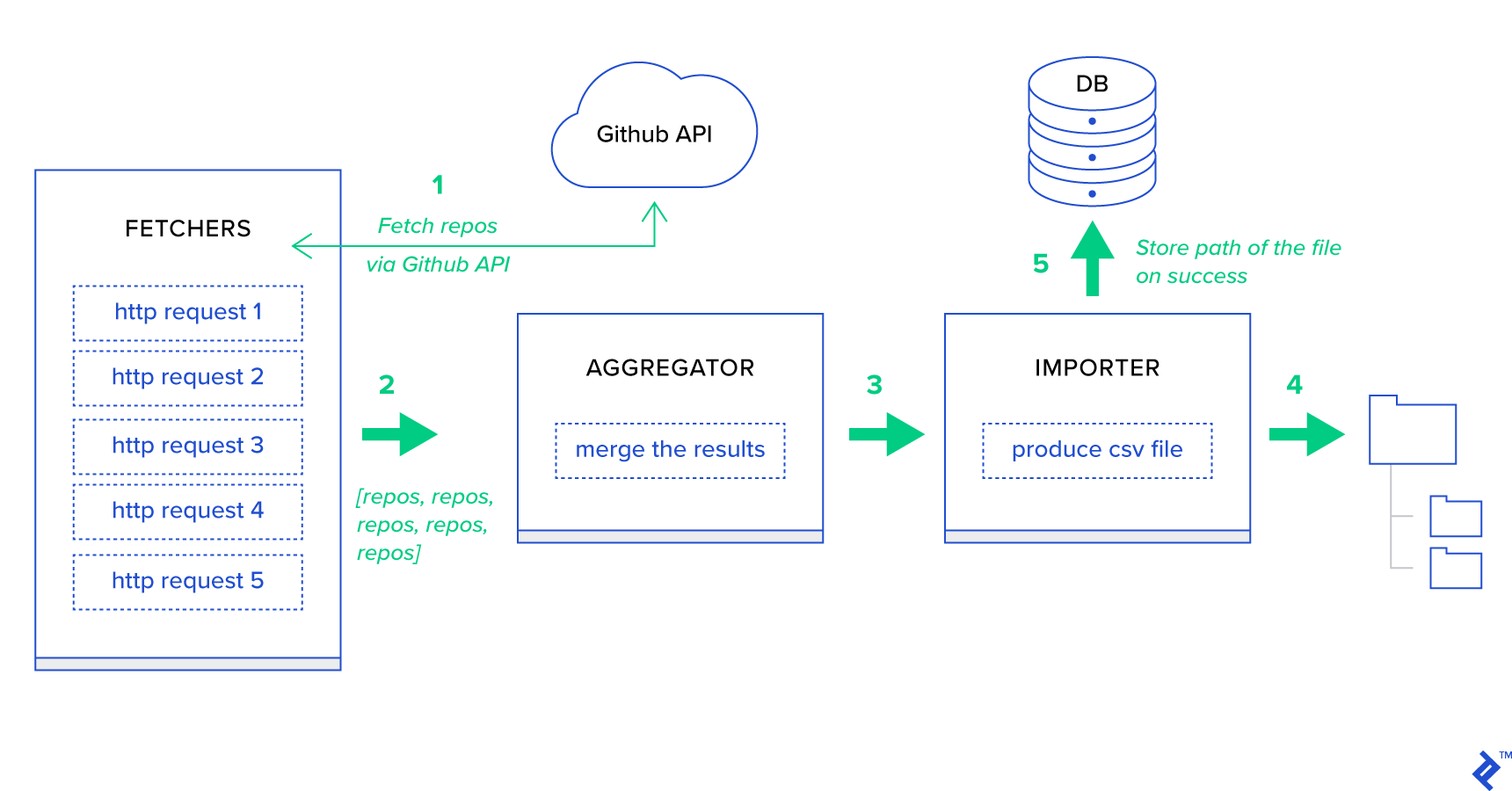
La récupération des référentiels est une requête HTTP utilisant l'API de recherche GitHub GET /search/repositories . Cependant, il existe une limitation du service de l'API GitHub qui doit être gérée : l'API renvoie jusqu'à 100 dépôts par requête au lieu de 500. Nous pourrions envoyer cinq requêtes une à la fois, mais nous ne voulons pas faire attendre notre utilisateur. pour cinq requêtes individuelles puisque les requêtes HTTP sont une opération liée aux E/S. Au lieu de cela, nous pouvons exécuter cinq requêtes HTTP simultanées avec un paramètre de page approprié. Ainsi, la page sera dans la plage [1..5]. Définissons une tâche appelée fetch_hot_repos/3 -> list dans le module toyex/tasks.py :
Fichier : celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Ainsi, fetch_hot_repos crée une requête à l'API GitHub et répond à l'utilisateur avec une liste de référentiels. Il reçoit trois paramètres qui définiront notre charge utile de requête :
-
since— Filtre les référentiels à la date de création. -
per_page— Nombre de résultats à renvoyer par requête (limité à 100). -
page—- Numéro de page demandé (dans la plage [1..5]).
Remarque : Pour utiliser l'API de recherche GitHub, vous aurez besoin d'un jeton OAuth pour passer les contrôles d'authentification. Dans notre cas, il est enregistré dans les paramètres sous GITHUB_OAUTH .
Ensuite, nous devons définir une tâche maître qui se chargera d'agréger les résultats et de les exporter dans un fichier CSV : produce_hot_repo_report_task/2->filepath:
Fichier : celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Cette tâche utilise celery.canvas.group pour exécuter cinq appels simultanés de fetch_hot_repos/3 . Ces résultats sont attendus puis réduits à une liste d'objets du référentiel. Ensuite, notre ensemble de résultats est regroupé par sujet et finalement exporté dans un fichier CSV généré sous le MEDIA_ROOT/ .
Afin de planifier la tâche périodiquement, vous pouvez ajouter une entrée à la liste de planification dans le fichier de configuration :
Fichier : config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Essayer
Afin de lancer et de tester le fonctionnement de la tâche, nous devons d'abord démarrer le processus Celery :
$ celery -A celery_uncovered worker -l info Ensuite, nous devons créer le celery_uncovered/media/ . Ensuite, vous pourrez tester sa fonctionnalité soit via Shell ou Celerybeat :
Coque :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Battement de céleri :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Vous pouvez regarder les résultats sous le MEDIA_ROOT/ .
Scénario 2 - Signaler les erreurs du serveur 500 par e-mail
L'un des cas d'utilisation les plus courants de Celery est l'envoi de notifications par e-mail. La notification par e-mail est une opération liée aux E/S hors ligne qui exploite soit un serveur SMTP local, soit un SES tiers. Il existe de nombreux cas d'utilisation impliquant l'envoi d'un e-mail et, pour la plupart d'entre eux, l'utilisateur n'a pas besoin d'attendre la fin de ce processus pour recevoir une réponse HTTP. C'est pourquoi il est préférable d'exécuter ces tâches en arrière-plan et de répondre immédiatement à l'utilisateur.
Description du cas d'utilisation : signalez les erreurs 50X à l'adresse e-mail de l'administrateur via Celery.
Python et Django ont les connaissances nécessaires pour effectuer la journalisation du système. Je n'entrerai pas dans les détails du fonctionnement réel de la journalisation de Python. Cependant, si vous ne l'avez jamais essayé auparavant ou si vous avez besoin d'un rappel, lisez la documentation du module de journalisation intégré. Vous voulez certainement cela dans votre environnement de production. Django a un gestionnaire de journalisation spécial appelé AdminEmailHandler qui envoie des e-mails aux administrateurs pour chaque message de journal qu'il reçoit.
Détails d'implémentation
L'idée principale est d'étendre la méthode send_mail de la classe AdminEmailHandler de telle sorte qu'elle puisse envoyer du courrier via Celery. Cela pourrait être fait comme illustré dans la figure ci-dessous :
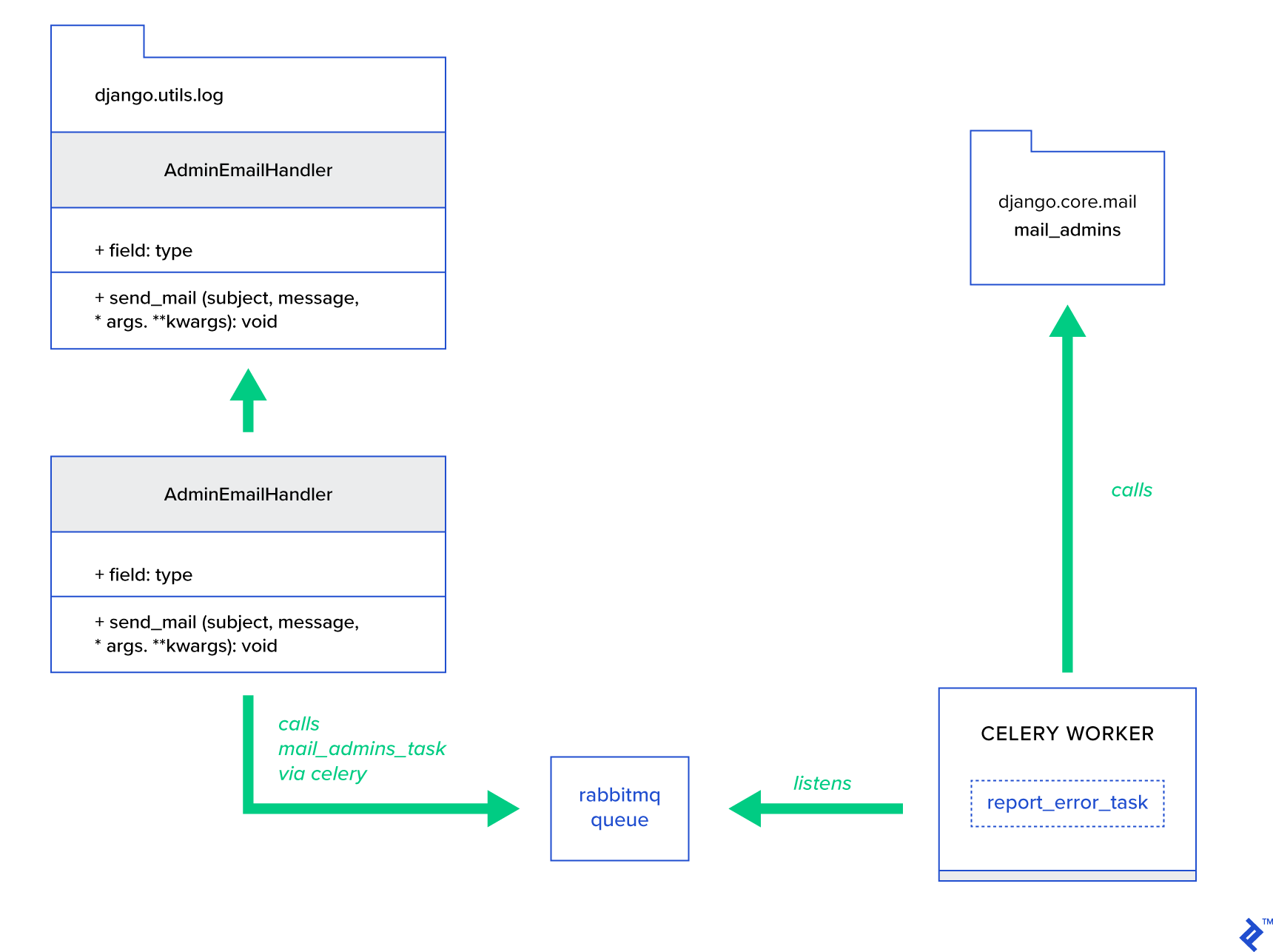
Tout d'abord, nous devons configurer une tâche appelée report_error_task qui appelle mail_admins avec le sujet et le message fournis :
Fichier : celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Ensuite, nous étendons en fait AdminEmailHandler afin qu'il n'appelle en interne que la tâche Celery définie :
Fichier : celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Enfin, nous devons configurer la journalisation. La configuration de la journalisation dans Django est assez simple. Ce dont vous avez besoin est de remplacer LOGGING afin que le moteur de journalisation commence à utiliser un gestionnaire nouvellement défini :
Fichier config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Notez que j'ai intentionnellement configuré des filtres de gestionnaire require_debug_true afin de tester cette fonctionnalité pendant que l'application s'exécute en mode débogage.
Essayer
Pour le tester, j'ai préparé une vue Django qui sert une opération de "division par zéro" sur localhost:8000/report-error . Vous devez également démarrer un conteneur MailHog Docker pour tester que l'e-mail est réellement envoyé.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Détails supplémentaires
En tant qu'outil de test de messagerie, j'ai configuré MailHog et configuré la messagerie Django pour l'utiliser pour la livraison SMTP. Il existe de nombreuses façons de déployer et d'exécuter MailHog. J'ai décidé d'utiliser un conteneur Docker. Vous pouvez trouver les détails dans le fichier README correspondant :
Fichier : docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Pour configurer votre application pour utiliser MailHog, vous devez ajouter les lignes suivantes dans votre config :
Fichier : config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Au-delà des tâches de céleri par défaut
Les tâches de céleri peuvent être créées à partir de n'importe quelle fonction appelable. Par défaut, toute tâche définie par l'utilisateur est injectée avec celery.app.task.Task en tant que classe parente (abstraite). Cette classe contient la fonctionnalité d'exécuter des tâches de manière asynchrone (en les transmettant via le réseau à un travailleur Celery) ou de manière synchrone (à des fins de test), en créant des signatures et de nombreux autres utilitaires. Dans les exemples suivants, nous allons essayer d'étendre Celery.app.task.Task puis de l'utiliser comme classe de base afin d'ajouter quelques comportements utiles à nos tâches.
Scénario 3 - Journalisation de fichiers par tâche
Dans l'un de mes projets, je développais une application qui fournit à l'utilisateur final un outil de type Extract, Transform, Load (ETL) capable d'ingérer puis de filtrer une énorme quantité de données hiérarchiques. Le back-end a été divisé en deux modules :
- Orchestration d'un pipeline de traitement de données avec Celery
- Traitement des données avec Go
Celery a été déployé avec une instance Celerybeat et plus de 40 travailleurs. Il y avait plus de vingt tâches différentes qui composaient les activités de pipeline et d'orchestration. Chacune de ces tâches peut échouer à un moment donné. Tous ces échecs ont été vidés dans le journal système de chaque travailleur. À un moment donné, le débogage et la maintenance de la couche Celery ont commencé à devenir gênants. Finalement, nous avons décidé d'isoler le journal des tâches dans un fichier spécifique à la tâche.
Description du cas d'utilisation : étendez Celery afin que chaque tâche consigne sa sortie standard et ses erreurs dans des fichiers
Celery fournit aux applications Python un grand contrôle sur ce qu'il fait en interne. Il est livré avec un cadre de signaux familier. Les applications qui utilisent Celery peuvent s'abonner à quelques-unes d'entre elles afin d'augmenter le comportement de certaines actions. Nous allons tirer parti des signaux au niveau des tâches pour fournir un suivi détaillé des cycles de vie des tâches individuelles. Le céleri est toujours livré avec un back-end de journalisation, et nous allons en tirer parti tout en ne remplaçant que légèrement à quelques endroits pour atteindre nos objectifs.
Détails d'implémentation
Celery prend déjà en charge la journalisation par tâche. Pour enregistrer dans un fichier, il est nécessaire d'envoyer la sortie du journal à l'emplacement approprié. Dans notre cas, l'emplacement correct de la tâche est un fichier correspondant au nom de la tâche. Sur l'instance Celery, nous remplacerons la configuration de journalisation intégrée par des gestionnaires de journalisation déduits dynamiquement. Il est possible de s'abonner au signal celeryd_after_setup puis d'y configurer la journalisation système :
Fichier : celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Notez que pour chaque tâche enregistrée dans l'application Celery, nous construisons un enregistreur correspondant avec son gestionnaire. Chaque gestionnaire est du type logging.FileHandler , et par conséquent chacune de ces instances reçoit un nom de fichier en entrée. Tout ce dont vous avez besoin pour que cela fonctionne est d'importer ce module dans celery_uncovered/celery.py à la fin du fichier :
import celery_uncovered.tricks.celery_conf Un journal de tâches particulier peut être reçu en appelant get_task_logger(task_name) . Afin de généraliser un tel comportement pour chaque tâche, il est nécessaire d'étendre légèrement celery.current_app.Task avec quelques méthodes utilitaires :
Fichier : celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Désormais, dans le cas d'un appel à task.log_msg("Hello, my name is: %s", task.request.id) , la sortie du journal sera acheminée vers le fichier correspondant sous le nom de la tâche.
Essayer
Pour lancer et tester le fonctionnement de cette tâche, démarrez d'abord le processus Celery :
$ celery -A celery_uncovered worker -l infoEnsuite, vous pourrez tester les fonctionnalités via Shell :
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Enfin, pour voir le résultat, accédez au celery_uncovered/logs et ouvrez le fichier journal correspondant appelé celery_uncovered.tricks.tasks.add.log . Vous pouvez voir quelque chose de similaire à celui ci-dessous après avoir exécuté cette tâche plusieurs fois :
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Scénario 4 - Tâches sensibles à la portée
Imaginons une application Python pour les utilisateurs internationaux basée sur Celery et Django. Les utilisateurs peuvent définir la langue (locale) dans laquelle ils utilisent votre application.
Vous devez concevoir un système de notification par e-mail multilingue et compatible avec les paramètres régionaux. Pour envoyer des notifications par e-mail, vous avez enregistré une tâche Celery spéciale qui est gérée par une file d'attente spécifique. Cette tâche reçoit des arguments clés en entrée et des paramètres régionaux actuels de l'utilisateur afin que l'e-mail soit envoyé dans la langue choisie par l'utilisateur.
Imaginons maintenant que nous ayons de nombreuses tâches de ce type, mais que chacune de ces tâches accepte un argument de paramètres régionaux. Dans ce cas, ne serait-il pas préférable de le résoudre à un niveau d'abstraction supérieur ? Ici, nous voyons juste comment faire cela.
Description du cas d'utilisation : hériter automatiquement de la portée d'un contexte d'exécution et l'injecter dans le contexte d'exécution actuel en tant que paramètre.
Détails d'implémentation
Encore une fois, comme nous l'avons fait avec la journalisation des tâches, nous souhaitons étendre une classe de tâches de base celery.current_app.Task et remplacer quelques méthodes responsables de l'appel des tâches. Pour les besoins de cette démonstration, je remplace la méthode celery.current_app.Task::apply_async . Il y a des tâches supplémentaires pour ce module qui vous aideront à produire un remplacement entièrement fonctionnel.
Fichier : celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)L'indice clé est de transmettre les paramètres régionaux actuels en tant qu'argument clé-valeur dans une tâche appelante par défaut. Si une tâche a été appelée avec une certaine locale comme argument, alors elle reste inchangée.
Essayer
Pour tester cette fonctionnalité, définissons une tâche factice de type ScopeBasedTask . Il localise un fichier par ID de paramètres régionaux et lit son contenu au format JSON :
Fichier : celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Maintenant, ce que vous devez faire est de répéter les étapes de lancement de Celery, de démarrage du shell et de test de l'exécution de cette tâche sur différents scénarios. Les luminaires sont situés sous le celery_uncovered/tricks/fixtures/locales/ .
Conclusion
Cet article visait à explorer le céleri sous différents angles. J'ai démontré Celery dans des exemples conventionnels tels que le publipostage et la génération de rapports, ainsi que des astuces partagées pour certains cas d'utilisation commerciaux de niche intéressants. Celery est construit sur une philosophie axée sur les données et votre équipe peut se simplifier la vie en l'introduisant dans sa pile système. Développer des services basés sur Celery n'est pas très compliqué si vous avez une expérience de base de Python, et vous devriez pouvoir l'acquérir assez rapidement. La configuration par défaut est suffisante pour la plupart des utilisations, mais si nécessaire, elle peut être très flexible.
Notre équipe a fait le choix d'utiliser Celery comme back-end d'orchestration pour les tâches d'arrière-plan et les tâches de longue durée. Nous l'utilisons largement pour une variété de cas d'utilisation, dont seuls quelques-uns ont été mentionnés dans cet article. Nous ingérons et analysons des gigaoctets de données chaque jour, mais ce n'est que le début des techniques de mise à l'échelle horizontale.