
Python için Kereviz'de Arka Plan İş Akışını Düzenleme
Yayınlanan: 2022-03-11Modern web uygulamaları ve bunların altında yatan sistemler, her zamankinden daha hızlı ve daha duyarlı. Bununla birlikte, ağır bir görevin yürütülmesini ana iş parçacığınızda ele almak yerine tüm sistem mimarinizin diğer bölümlerine devretmek istediğiniz birçok durum vardır. Bu tür görevleri belirlemek, aşağıdaki kategorilerden birine ait olup olmadıklarını kontrol etmek kadar basittir:
- Periyodik görevler — Belirli bir zamanda veya belirli bir aralıktan sonra çalışacak şekilde planlayacağınız işler, örneğin aylık rapor oluşturma veya günde iki kez çalışan bir web kazıyıcı.
- Üçüncü taraf görevleri — Web uygulaması, sayfa yüklenirken, örneğin bir e-posta veya bildirim gönderme veya dahili araçlara güncellemeler yayma (A/B testi veya sistem günlüğü için veri toplama gibi) gibi diğer işlemlerin tamamlanmasını beklemeden kullanıcılara hızlı bir şekilde hizmet vermelidir. ).
- Uzun süreli işler — Kaynakları pahalı olan ve kullanıcıların sonuçlarını hesaplarken beklemesi gereken işler, örneğin, karmaşık iş akışı yürütme (DAG iş akışları), grafik oluşturma, Eşleme-Küçültme benzeri görevler ve medya içeriğinin sunulması (video, ses).
Bir arka plan görevini yürütmek için basit bir çözüm, onu ayrı bir iş parçacığı veya işlem içinde çalıştırmak olacaktır. Python, ne yazık ki Erlang, Go, Java, Scala veya Akka ile eşleşen bir ölçekte yerleşik eşzamanlılık sağlamayan üst düzey bir Turing eksiksiz programlama dilidir. Bunlar Tony Hoare'nin Communicating Sequential Processes'e (CSP) dayanmaktadır. Öte yandan Python iş parçacıkları, birden çok yerel iş parçacığının Python bayt kodlarını aynı anda yürütmesini engelleyen genel yorumlayıcı kilidi (GIL) tarafından koordine edilir ve planlanır. GIL'den kurtulmak Python geliştiricileri arasında çok tartışılan bir konudur, ancak bu makalenin odak noktası bu değildir. Python'da eşzamanlı programlama eski modadır, ancak bununla ilgili Toptaler Marcus McCurdy tarafından yazılan Python Çoklu Okuma Eğitiminde okuyabilirsiniz. Bu nedenle, süreçler arasındaki iletişimi tutarlı bir şekilde tasarlamak hataya açık bir süreçtir ve ölçeklenebilirliği olumsuz etkilediğinden bahsetmeye gerek yok, kod eşleşmesine ve kötü sistem bakımına yol açar. Ek olarak, Python işlemi, bir İşletim Sistemi (OS) altında normal bir işlemdir ve Python standart kitaplığının tamamıyla birlikte ağır bir hal alır. Uygulamadaki işlemlerin sayısı arttıkça, bu tür bir işlemden diğerine geçiş yapmak zaman alan bir işlem haline gelir.
Python ile eşzamanlılığı daha iyi anlamak için David Beazley'nin PyCon'15'te yaptığı bu inanılmaz konuşmayı izleyin.
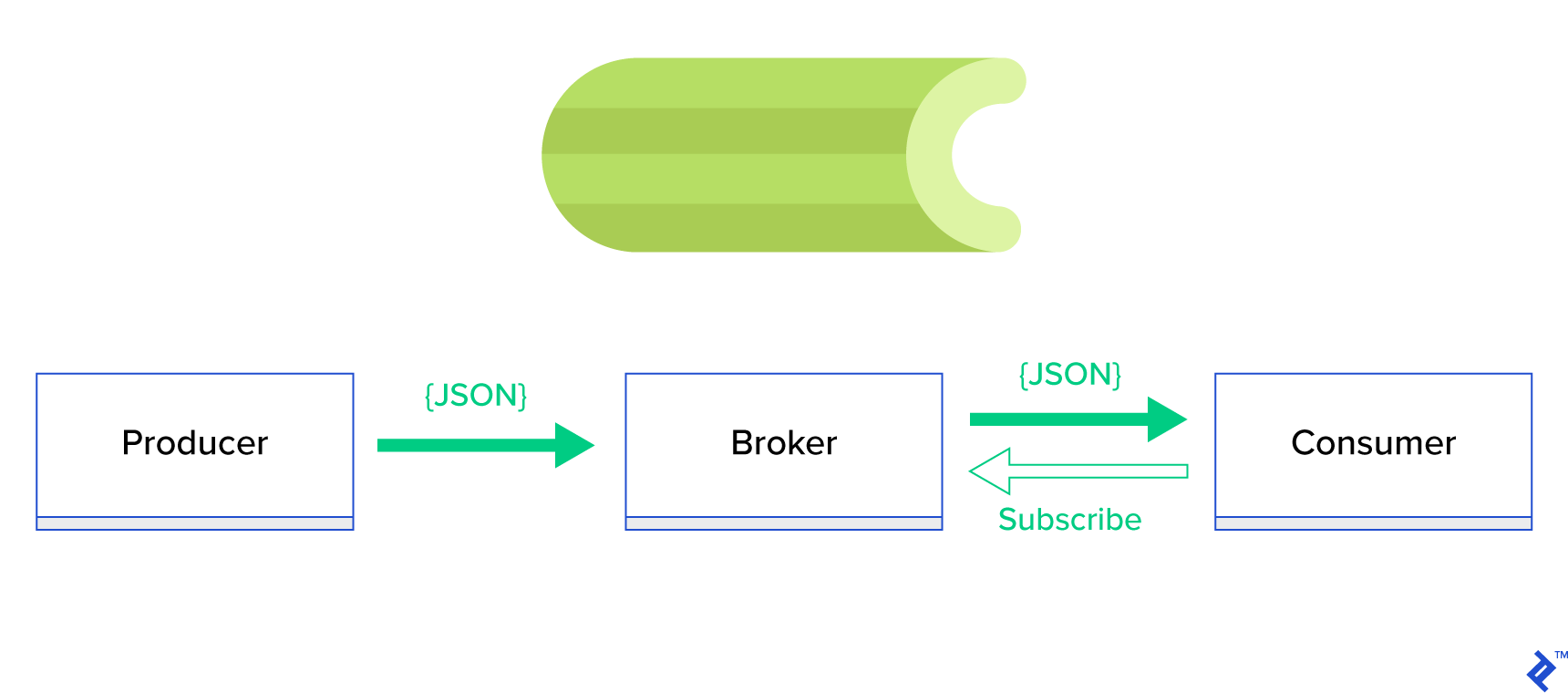
Çok daha iyi bir çözüm, dağıtılmış bir kuyruğa veya onun yayınla-abone ol adı verilen iyi bilinen kardeş paradigmasına hizmet etmektir. Şekil 1'de gösterildiği gibi, yayıncı olarak adlandırılan birinin mesaj gönderdiği ve abone adı verilen diğerinin mesaj aldığı iki tür uygulama vardır. Bu iki ajan birbirleriyle doğrudan etkileşime girmezler ve birbirlerinden haberdar bile değildirler. Yayıncılar merkezi bir kuyruğa veya aracıya mesaj gönderir ve aboneler bu aracıdan ilgilendikleri mesajları alır. Bu yöntemin iki ana avantajı vardır:
- Ölçeklenebilirlik — aracıların ağda birbirleri hakkında bilgi sahibi olmaları gerekmez. Konuya göre odaklanırlar. Bu, her birinin diğerinden bağımsız olarak asenkron bir şekilde normal şekilde çalışmaya devam edebileceği anlamına gelir.
- Gevşek bağlantı — her aracı sistemin kendi bölümünü temsil eder (servis, modül). Gevşek bağlı olduklarından, her biri veri merkezinin ötesinde ayrı ayrı ölçeklenebilir.
Bu tür paradigmaları destekleyen ve TCP veya HTTP protokolleri tarafından yönlendirilen düzgün bir API sağlayan çok sayıda mesajlaşma sistemi vardır, örneğin JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ, vb.
Kereviz Nedir?
Kereviz, Python dünyasındaki en popüler arka plan iş yöneticilerinden biridir. Kereviz, RabbitMQ veya Redis gibi çeşitli mesaj simsarları ile uyumludur ve hem üretici hem de tüketici olarak hareket edebilir.
Kereviz, dağıtılmış ileti geçişine dayalı eşzamansız bir görev kuyruğu/iş kuyruğudur. Gerçek zamanlı işlemlere odaklanır ancak zamanlamayı da destekler. Görevler olarak adlandırılan yürütme birimleri, çoklu işlem, Eventlet veya gevent kullanılarak bir veya daha fazla işçi sunucusunda eşzamanlı olarak yürütülür. Görevler eşzamansız olarak (arka planda) veya eşzamanlı olarak (hazır olana kadar bekleyin) yürütülebilir. – Kereviz Projesi
Kereviz kullanmaya başlamak için resmi belgelerdeki adım adım kılavuzu izlemeniz yeterlidir.
Bu makalenin odak noktası, Kereviz'in hangi kullanım durumlarını kapsadığı konusunda size iyi bir fikir vermektir. Bu makalede, sadece ilginç örnekler göstermekle kalmayacak, aynı zamanda Kereviz'i arka plan postalama, rapor oluşturma, günlüğe kaydetme ve hata raporlama gibi gerçek dünyadaki görevlere nasıl uygulayacağınızı öğrenmeye çalışacağız. Görevleri öykünmenin ötesinde test etme yöntemimi paylaşacağım ve son olarak, resmi belgelerde (iyi) belgelenmemiş ve kendim keşfetmem için saatlerce araştırmamı gerektiren birkaç püf noktası sunacağım.
Kereviz ile daha önce deneyiminiz yoksa, önce resmi öğreticiyi izleyerek denemenizi tavsiye ederim.
İştahınızı Açmak
Bu makale ilginizi çekiyorsa ve hemen koda dalmak istemenizi sağlıyorsa, bu makalede kullanılan kod için bu GitHub deposunu izleyin. Oradaki README dosyası, örnek uygulamaları çalıştırmak ve oynatmak için size hızlı ve kirli bir yaklaşım sağlayacaktır.
Kereviz ile İlk Adımlar
Başlangıç olarak, Kereviz'in görünüşte önemsiz olmayan görevleri ne kadar basit ve zarif bir şekilde çözdüğünü okuyucuya gösterecek bir dizi pratik örnek üzerinden geçeceğiz. Tüm örnekler Django çerçevesinde sunulacaktır; ancak bunların çoğu kolaylıkla diğer Python çerçevelerine (Flask, Pyramid) taşınabilir.
Proje düzeni, Cookieecutter Django tarafından oluşturulmuştur; ancak, bence, bu kullanım durumlarının geliştirilmesini ve hazırlanmasını kolaylaştıran sadece birkaç bağımlılık tuttum. Ayrıca gürültüyü azaltmak ve kodun anlaşılmasını kolaylaştırmak için bu gönderi için gereksiz modülleri ve uygulamaları kaldırdım.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}bu gönderide ele alacağımız farklı uygulamalar içeriyor. Her uygulama, gereken Kereviz anlayışı düzeyine göre düzenlenmiş bir dizi örnek içerir. -
celery_uncovered/celery.pybir Celery örneğini tanımlar.
Dosya: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() O zaman Kereviz'in Django ile birlikte başlayacağından emin olmamız gerekiyor. Bu nedenle, uygulamayı celery_uncovered/__init__.py .
Dosya: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings , uygulamamız ve Kereviz için yapılandırma kaynağıdır. Yürütme ortamına bağlı olarak, Django ilgili ayarları başlatır: geliştirme için local.py veya test için test.py İsterseniz yeni bir python modülü (örn. prod.py ) oluşturarak kendi ortamınızı da tanımlayabilirsiniz. Kereviz konfigürasyonlarının önüne CELERY_ eklenir. Bu gönderi için, aracı olarak RabbitMQ'yu ve sonuç olarak da SQLite'ı yapılandırdım.
Dosya: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Senaryo 1 - Rapor oluşturma ve dışa aktarma
Ele alacağımız ilk vaka rapor oluşturma ve ihracattır. Bu örnekte, bir CSV raporu oluşturan bir görevi nasıl tanımlayacağınızı ve bunu celerybeat ile düzenli aralıklarla nasıl planlayacağınızı öğreneceksiniz.
Vaka açıklamasını kullanın: Seçilen dönem (gün, hafta, ay) başına GitHub'dan en popüler beş yüz havuzu alın, bunları konulara göre gruplayın ve sonucu CSV dosyasına aktarın.
"Rapor Oluştur" etiketli bir düğme tıklanarak tetiklenen bu özelliği çalıştıracak bir HTTP hizmeti sağlarsak, uygulama bir HTTP yanıtı göndermeden önce duracak ve görevin tamamlanmasını bekleyecektir. Bu kötü. Web uygulamamızın hızlı olmasını istiyoruz ve kullanıcılarımızın arka ucumuz sonuçları hesaplarken beklemesini istemiyoruz. Sonuçların üretilmesini beklemek yerine, Celery'de kayıtlı bir kuyruk aracılığıyla görevi çalışan işlemlere sıraya koymayı ve ön uca bir task_id ile yanıt vermeyi tercih ederiz. Ardından ön uç, görev sonucunu eşzamansız bir şekilde (örneğin, AJAX) sorgulamak için task_id kullanır ve kullanıcıyı görevin ilerleyişiyle güncel tutar. Son olarak, işlem bittiğinde, sonuçlar HTTP aracılığıyla indirilecek bir dosya olarak sunulabilir.
Uygulama ayrıntıları
Her şeyden önce, süreci mümkün olan en küçük birimlerine ayıralım ve bir ardışık düzen oluşturalım:
- Getiriciler , GitHub hizmetinden depo almaktan sorumlu çalışanlardır.
- Toplayıcı , sonuçları tek bir listede birleştirmekten sorumlu çalışandır.
- İçe Aktarıcı , GitHub'daki en sıcak depoların CSV raporlarını üreten çalışandır.
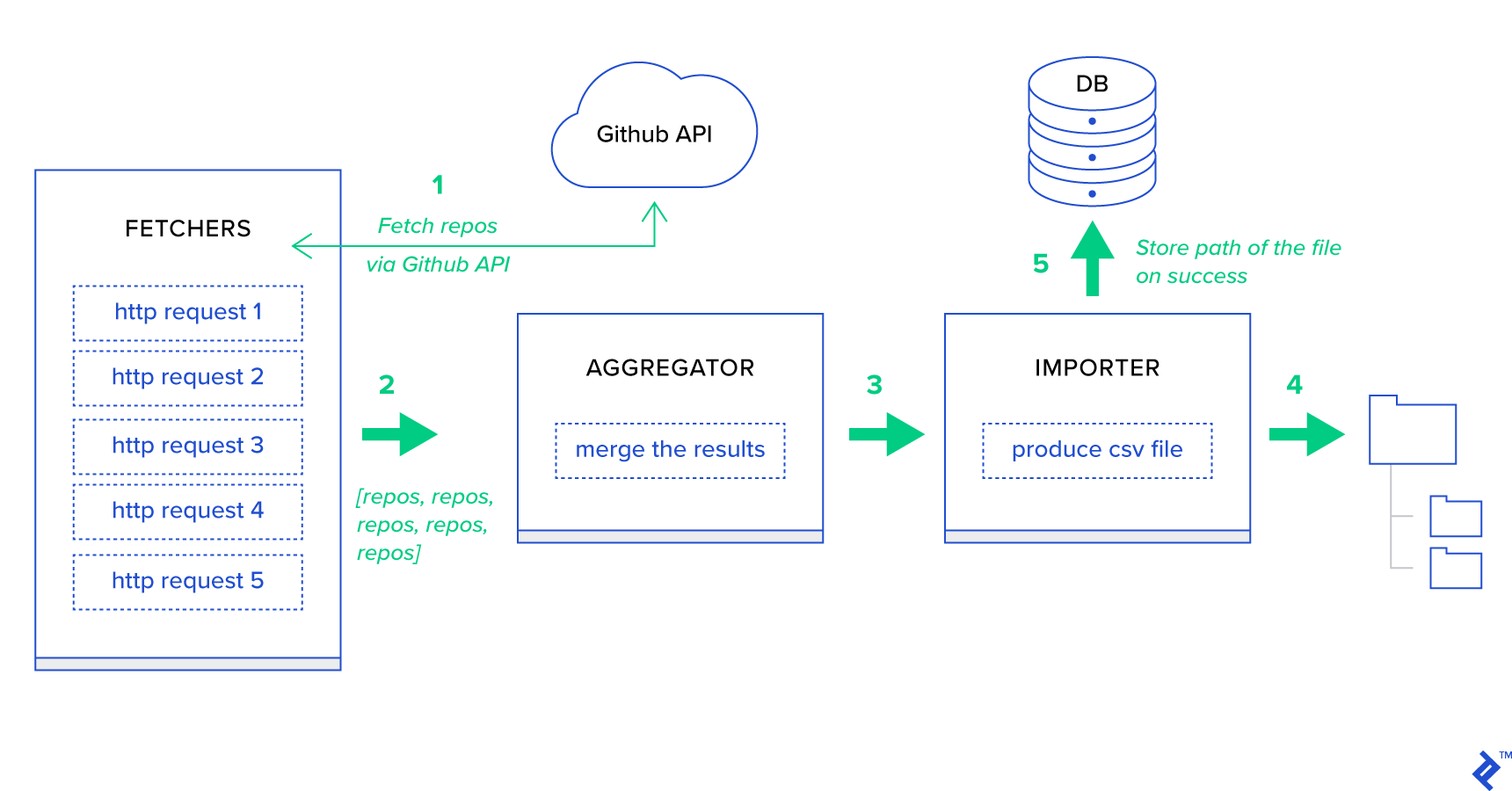
Depoları almak, GitHub Arama API'sı GET /search/repositories kullanan bir HTTP isteğidir. Ancak, GitHub API hizmetinin işlenmesi gereken bir sınırlaması vardır: API, istek başına 500 yerine 100'e kadar depo döndürür. Bir seferde bir tane olmak üzere beş istek gönderebiliriz, ancak kullanıcımızı bekletmek istemiyoruz. HTTP istekleri G/Ç'ye bağlı bir işlem olduğundan, beş ayrı istek için. Bunun yerine, uygun bir sayfa parametresiyle beş eşzamanlı HTTP isteği yürütebiliriz. Yani sayfa [1..5] aralığında olacaktır. toyex/tasks.py modülünde fetch_hot_repos/3 -> list adında bir görev tanımlayalım:
Dosya: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items fetch_hot_repos , GitHub API'sine bir istek oluşturur ve kullanıcıya bir depo listesiyle yanıt verir. İstek yükümüzü tanımlayacak üç parametre alır:
-
since— Depoları oluşturulma tarihine göre filtreler. -
per_page— İstek başına döndürülecek sonuç sayısı (100 ile sınırlıdır). -
page—- İstenen sayfa numarası ([1..5] aralığında).
Not: GitHub Arama API'sını kullanmak için, kimlik doğrulama kontrollerini geçmek üzere bir OAuth Simgesine ihtiyacınız olacak. Bizim durumumuzda, GITHUB_OAUTH altındaki ayarlara kaydedilir.
Ardından, sonuçları toplamaktan ve bunları bir CSV dosyasına aktarmaktan sorumlu olacak bir ana görev tanımlamamız gerekiyor: produce_hot_repo_report_task/2->filepath:
Dosya: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Bu görev, beş eşzamanlı fetch_hot_repos/3 çağrısını yürütmek için celery.canvas.group kullanır. Bu sonuçlar beklenir ve ardından bir depo nesneleri listesine indirgenir. Daha sonra sonuç kümemiz konuya göre gruplandırılır ve son olarak MEDIA_ROOT/ dizini altında oluşturulan bir CSV dosyasına aktarılır.
Görevi periyodik olarak zamanlamak için, yapılandırma dosyasındaki zamanlama listesine bir giriş eklemek isteyebilirsiniz:
Dosya: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Denemek
Başlatmak ve görevin nasıl çalıştığını test etmek için önce Kereviz sürecini başlatmamız gerekiyor:
$ celery -A celery_uncovered worker -l info Ardından, celery_uncovered/media/ dizinini oluşturmamız gerekiyor. Ardından, Shell veya Celerybeat aracılığıyla işlevselliğini test edebileceksiniz:
Kabuk :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)kereviz :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Sonuçları MEDIA_ROOT/ dizini altından izleyebilirsiniz.
Senaryo 2 - E-posta ile Sunucu 500 Hatalarını Raporlama
Kereviz için en yaygın kullanım durumlarından biri e-posta bildirimleri göndermektir. E-posta bildirimi, yerel bir SMTP sunucusundan veya bir üçüncü taraf SES'ten yararlanan çevrimdışı bir G/Ç bağlantılı işlemdir. Bir e-posta göndermeyi içeren birçok kullanım durumu vardır ve bunların çoğu için kullanıcının bir HTTP yanıtı almadan önce bu işlemin bitmesini beklemesi gerekmez. Bu nedenle bu tür görevlerin arka planda yürütülmesi ve kullanıcıya anında yanıt verilmesi tercih edilir.
Vaka açıklamasını kullanın: 50X hatalarını Kereviz aracılığıyla yönetici e-postasına bildirin.
Python ve Django, sistem günlüğü gerçekleştirmek için gerekli arka plana sahiptir. Python'un günlük kaydının gerçekte nasıl çalıştığına dair ayrıntılara girmeyeceğim. Ancak, daha önce hiç denemediyseniz veya tazelemeye ihtiyacınız varsa, yerleşik günlük modülünün belgelerini okuyun. Bunu kesinlikle üretim ortamınızda istersiniz. Django, aldığı her günlük mesajı için yöneticilere e-posta gönderen AdminEmailHandler adlı özel bir günlükçü işleyicisine sahiptir.
Uygulama ayrıntıları
Ana fikir, AdminEmailHandler sınıfının send_mail yöntemini, Kereviz yoluyla posta gönderebilecek şekilde genişletmektir. Bu, aşağıdaki şekilde gösterildiği gibi yapılabilir:
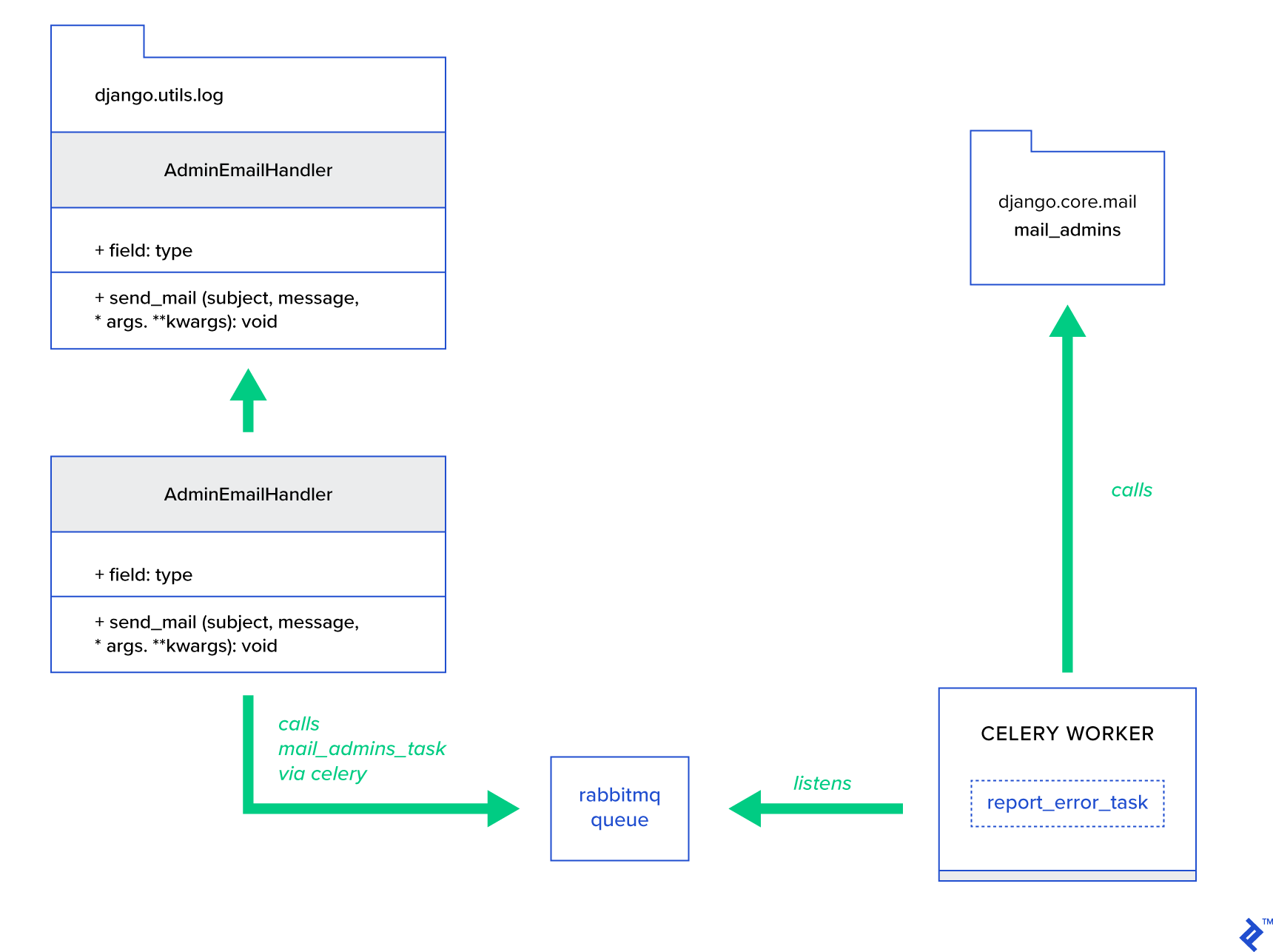
İlk olarak, sağlanan konu ve mesajla mail_admins çağıran report_error_task adlı bir görev oluşturmamız gerekiyor:
Dosya: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Daha sonra, AdminEmailHandler'ı dahili olarak yalnızca tanımlanmış Kereviz görevini çağıracak şekilde genişletiriz:
Dosya: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Son olarak, loglamayı ayarlamamız gerekiyor. Django'da oturum açma yapılandırması oldukça basittir. İhtiyacınız olan şey, LOGGING geçersiz kılmaktır, böylece günlük motoru yeni tanımlanmış bir işleyiciyi kullanmaya başlar:
Dosya config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Uygulama hata ayıklama modunda çalışırken bu işlevi sınamak için kasıtlı olarak require_debug_true dikkat edin.
Denemek
Test etmek için localhost:8000/report-error "sıfıra bölme" işlemine hizmet eden bir Django görünümü hazırladım. Ayrıca, e-postanın gerçekten gönderildiğini test etmek için bir MailHog Docker kapsayıcı başlatmanız gerekir.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Ekstra Detaylar
Bir posta test aracı olarak, MailHog'u kurdum ve Django postasını SMTP dağıtımı için kullanmak üzere yapılandırdım. MailHog'u dağıtmanın ve çalıştırmanın birçok yolu vardır. Bir Docker konteyneri ile gitmeye karar verdim. Ayrıntıları ilgili README dosyasında bulabilirsiniz:
Dosya: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Uygulamanızı MailHog kullanacak şekilde yapılandırmak için yapılandırmanıza aşağıdaki satırları eklemeniz gerekir:
Dosya: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Varsayılan Kereviz Görevlerinin Ötesinde
Kereviz görevleri herhangi bir çağrılabilir işlevden oluşturulabilir. Varsayılan olarak, herhangi bir kullanıcı tanımlı görev, bir üst (soyut) sınıf olarak celery.app.task.Task ile enjekte edilir. Bu sınıf, görevleri eşzamansız olarak (ağ üzerinden bir Kereviz çalışanına ileterek) veya eşzamanlı olarak (test amacıyla) çalıştırma, imzalar oluşturma ve diğer birçok yardımcı programı içerir. Sonraki örneklerde, Celery.app.task.Task genişletmeye çalışacağız ve ardından görevlerimize birkaç yararlı davranış eklemek için onu temel sınıf olarak kullanacağız.
Senaryo 3 - Görev Başına Dosya Günlüğü
Projelerimden birinde, son kullanıcıya büyük miktarda hiyerarşik veriyi alıp filtreleyebilen Ayıkla, Dönüştür, Yükle (ETL) benzeri bir araç sağlayan bir uygulama geliştiriyordum. Arka uç iki modüle ayrıldı:
- Kereviz ile bir veri işleme hattının düzenlenmesi
- Go ile veri işleme
Kereviz, bir Celerybeat örneği ve 40'tan fazla işçiyle konuşlandırıldı. Ardışık düzen ve orkestrasyon etkinliklerini oluşturan yirmiden fazla farklı görev vardı. Bu tür görevlerin her biri bir noktada başarısız olabilir. Tüm bu hatalar, her çalışanın sistem günlüğüne döküldü. Bir noktada, Kereviz katmanını hata ayıklamak ve sürdürmek elverişsiz olmaya başladı. Sonunda, görev günlüğünü göreve özel bir dosyaya ayırmaya karar verdik.
Örnek açıklamayı kullanın: Kereviz'i, her görevin standart çıktısını ve hataları dosyalara kaydedecek şekilde genişletin
Kereviz, Python uygulamalarına dahili olarak yaptıkları üzerinde büyük kontrol sağlar. Tanıdık bir sinyal çerçevesiyle birlikte gelir. Kereviz kullanan uygulamalar, belirli eylemlerin davranışını artırmak için bunlardan birkaçına abone olabilir. Bireysel görev yaşam döngülerinin ayrıntılı bir şekilde izlenmesini sağlamak için görev düzeyinde sinyallerden yararlanacağız. Kereviz her zaman bir kütük arka ucu ile gelir ve hedeflerimize ulaşmak için birkaç yerde sadece biraz geçersiz kılarak bundan faydalanacağız.
Uygulama ayrıntıları
Kereviz zaten görev başına günlüğe kaydetmeyi destekliyor. Bir dosyaya kaydetmek için günlük çıktısını uygun konuma göndermek gerekir. Bizim durumumuzda, görevin uygun konumu, görevin adıyla eşleşen bir dosyadır. Kereviz örneğinde, dinamik olarak çıkarılan günlük işleyicileri ile yerleşik günlük yapılandırmasını geçersiz kılacağız. celeryd_after_setup sinyaline abone olmak ve ardından sistem günlüğünü burada yapılandırmak mümkündür:
Dosya: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Kereviz uygulamasında kaydedilen her görev için, işleyicisiyle birlikte karşılık gelen bir günlükçü oluşturduğumuza dikkat edin. Her işleyici logging.FileHandler ve bu nedenle bu tür her bir örnek girdi olarak bir dosya adı alır. Bunu çalıştırmak için ihtiyacınız olan tek şey, bu modülü dosyanın sonunda celery_uncovered/celery.py dosyasına içe aktarmaktır:
import celery_uncovered.tricks.celery_conf get_task_logger(task_name) çağrılarak belirli bir görev kaydedici alınabilir. Bu tür davranışları her görev için genelleştirmek için, celery.current_app.Task birkaç yardımcı yöntem ile biraz genişletmek gerekir:
Dosya: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Şimdi, task.log_msg("Hello, my name is: %s", task.request.id) , günlük çıktısı, görev adı altındaki ilgili dosyaya yönlendirilecektir.
Denemek
Bu görevin nasıl çalıştığını başlatmak ve test etmek için önce Kereviz işlemini başlatın:
$ celery -A celery_uncovered worker -l infoArdından, Shell aracılığıyla işlevselliği test edebileceksiniz:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Son olarak, sonucu görmek için celery_uncovered/logs dizinine gidin ve celery_uncovered.tricks.tasks.add.log adlı ilgili günlük dosyasını açın. Bu görevi birden çok kez çalıştırdıktan sonra aşağıdakine benzer bir şey görebilirsiniz:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Senaryo 4 - Kapsam Duyarlı Görevler
Uluslararası kullanıcılar için Kereviz ve Django üzerine kurulu bir Python uygulaması hayal edelim. Kullanıcılar, uygulamanızı hangi dilde (yerel) kullanacaklarını ayarlayabilirler.
Çok dilli, yerel ayarlara duyarlı bir e-posta bildirim sistemi tasarlamanız gerekir. E-posta bildirimleri göndermek için, belirli bir sıra tarafından gerçekleştirilen özel bir Kereviz görevi kaydettiniz. Bu görev, giriş olarak bazı temel argümanları ve e-postanın kullanıcının seçtiği dilde gönderilmesi için geçerli bir kullanıcı yerel ayarı alır.
Şimdi böyle birçok görevimiz olduğunu hayal edin, ancak bu görevlerin her biri bir yerel argümanı kabul ediyor. Bu durumda, daha yüksek bir soyutlama düzeyinde çözmek daha iyi olmaz mıydı? Burada, bunu nasıl yapacağımızı görüyoruz.
Vaka açıklamasını kullanın: Kapsamı bir yürütme bağlamından otomatik olarak devralın ve bunu bir parametre olarak geçerli yürütme bağlamına enjekte edin.
Uygulama ayrıntıları
Yine, görev günlüğünde yaptığımız gibi, celery.current_app.Task temel görev sınıfını genişletmek ve görevleri çağırmaktan sorumlu birkaç yöntemi geçersiz kılmak istiyoruz. Bu gösterim amacıyla, celery.current_app.Task::apply_async yöntemini geçersiz kılıyorum. Bu modül için, tam işlevli bir yedek üretmenize yardımcı olacak ek görevler vardır.
Dosya: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)Anahtar ipucu, geçerli yerel ayarı varsayılan olarak bir çağrı görevine bir anahtar/değer bağımsız değişkeni olarak iletmektir. Bir görev, argüman olarak belirli bir yerel ayar ile çağrıldıysa, değişmez.
Denemek
Bu işlevi test etmek için ScopeBasedTask türünde yapay bir görev tanımlayalım. Yerel ayar kimliğine göre bir dosyayı bulur ve içeriğini JSON olarak okur:
Dosya: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Şimdi yapmanız gereken, Kereviz'i başlatma, kabuğu başlatma ve bu görevin farklı senaryolarda yürütülmesini test etme adımlarını tekrarlamaktır. Fikstürler, celery_uncovered/tricks/fixtures/locales/ dizini altında bulunur.
Çözüm
Bu yazı Kereviz'i farklı açılardan keşfetmeyi amaçladı. Kereviz'i postalama ve rapor oluşturma gibi geleneksel örneklerde ve bazı ilginç niş iş kullanım durumlarına yönelik paylaşılan hileleri gösterdim. Kereviz, veri odaklı bir felsefe üzerine kuruludur ve ekibiniz, sistem yığınının bir parçası olarak sunarak hayatlarını çok daha basit hale getirebilir. Temel Python deneyiminiz varsa Kereviz tabanlı hizmetler geliştirmek çok karmaşık değildir ve bunu oldukça hızlı bir şekilde alabilmeniz gerekir. Varsayılan yapılandırma çoğu kullanım için yeterince iyidir, ancak gerekirse çok esnek olabilirler.
Ekibimiz, Kereviz'i arka plan işleri ve uzun süren görevler için bir düzenleme arka ucu olarak kullanmayı tercih etti. Bunu, bu yazıda yalnızca birkaçından bahsedilmiş olan çeşitli kullanım durumları için yoğun bir şekilde kullanıyoruz. Her gün gigabaytlarca veriyi alıyor ve analiz ediyoruz, ancak bu, yatay ölçekleme tekniklerinin yalnızca başlangıcıdır.