
Orquestrando um fluxo de trabalho em segundo plano no aipo para Python
Publicados: 2022-03-11Os aplicativos da Web modernos e seus sistemas subjacentes são mais rápidos e responsivos do que nunca. No entanto, ainda existem muitos casos em que você deseja descarregar a execução de uma tarefa pesada para outras partes de toda a arquitetura do sistema, em vez de abordá-las em seu encadeamento principal. Identificar essas tarefas é tão simples quanto verificar se elas pertencem a uma das seguintes categorias:
- Tarefas periódicas — Trabalhos que você agendará para execução em um horário específico ou após um intervalo, por exemplo, geração de relatório mensal ou um web scraper executado duas vezes por dia.
- Tarefas de terceiros — O aplicativo da web deve atender os usuários rapidamente sem esperar que outras ações sejam concluídas enquanto a página carrega, por exemplo, enviar um e-mail ou notificação ou propagar atualizações para ferramentas internas (como coleta de dados para teste A/B ou registro do sistema ).
- Trabalhos de longa duração — Trabalhos que são caros em recursos, onde os usuários precisam esperar enquanto computam seus resultados, por exemplo, execução de fluxo de trabalho complexo (fluxos de trabalho DAG), geração de gráficos, tarefas do tipo Map-Reduce e veiculação de conteúdo de mídia (vídeo, áudio).
Uma solução simples para executar uma tarefa em segundo plano seria executá-la em um thread ou processo separado. Python é uma linguagem de programação Turing completa de alto nível, que infelizmente não fornece simultaneidade integrada em uma escala compatível com Erlang, Go, Java, Scala ou Akka. Esses são baseados nos Processos Seqüenciais de Comunicação (CSP) de Tony Hoare. Os threads do Python, por outro lado, são coordenados e agendados pelo bloqueio do interpretador global (GIL), que impede que vários threads nativos executem bytecodes do Python de uma só vez. Livrar-se do GIL é um tópico de muita discussão entre os desenvolvedores Python, mas não é o foco deste artigo. A programação simultânea em Python é antiquada, embora você possa ler sobre isso no Tutorial de Multithreading em Python pelo colega Toptaler Marcus McCurdy. Portanto, projetar a comunicação entre processos de forma consistente é um processo propenso a erros e leva ao acoplamento de código e à manutenção ruim do sistema, sem mencionar que afeta negativamente a escalabilidade. Além disso, o processo do Python é um processo normal em um sistema operacional (SO) e, com toda a biblioteca padrão do Python, torna-se um peso pesado. À medida que o número de processos no aplicativo aumenta, alternar de um desses processos para outro se torna uma operação demorada.
Para entender melhor a simultaneidade com o Python, assista a este incrível discurso de David Beazley no PyCon'15.
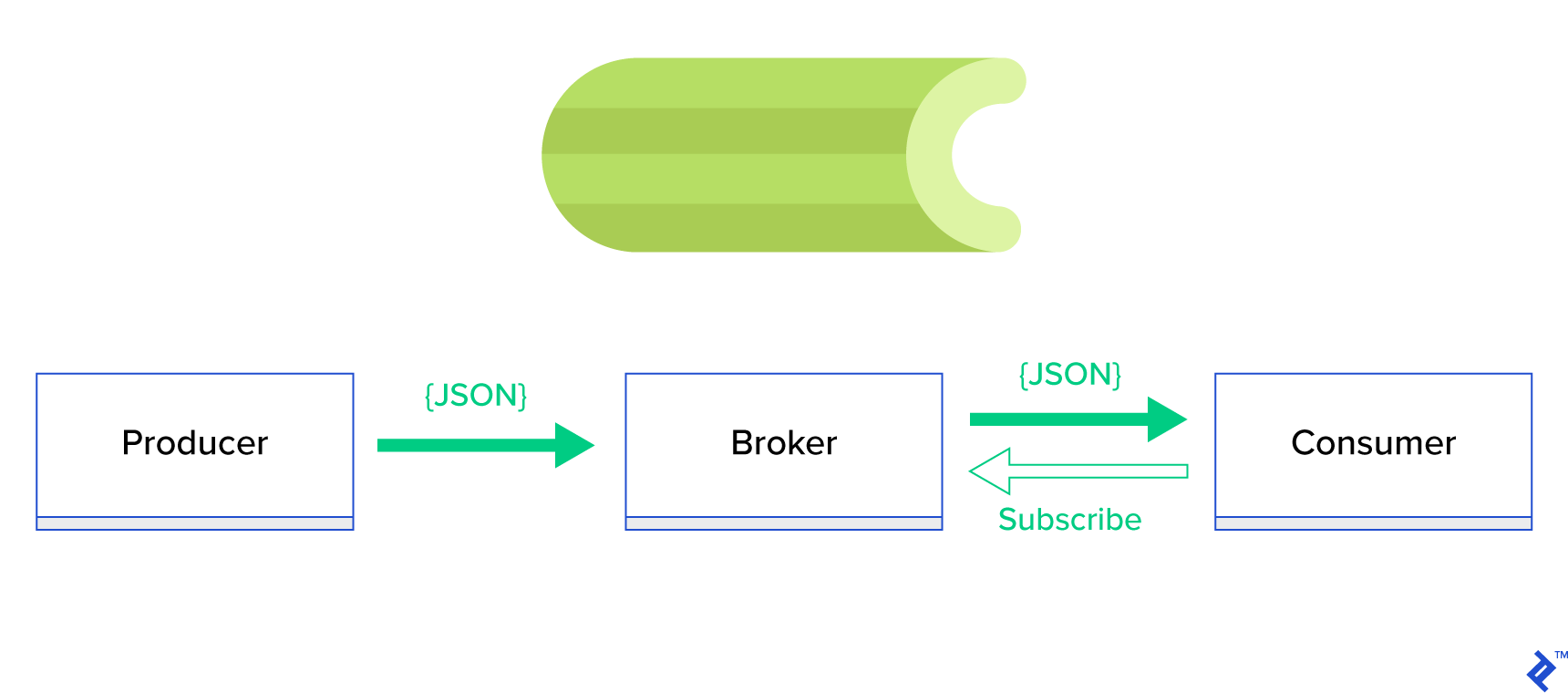
Uma solução muito melhor é servir uma fila distribuída ou seu conhecido paradigma irmão chamado publish-subscribe . Conforme ilustrado na Figura 1, existem dois tipos de aplicativos em que um, chamado de publicador , envia mensagens e o outro, chamado de assinante , recebe mensagens. Esses dois agentes não interagem um com o outro diretamente e nem estão cientes um do outro. Os publicadores enviam mensagens para uma fila central ou intermediário e os assinantes recebem mensagens de interesse desse intermediário. Existem duas vantagens principais neste método:
- Escalabilidade — os agentes não precisam conhecer uns aos outros na rede. Eles são focados por tópico. Portanto, isso significa que cada um pode continuar operando normalmente, independentemente do outro, de maneira assíncrona.
- Acoplamento fraco — cada agente representa sua parte do sistema (serviço, módulo). Como são fracamente acoplados, cada um pode ser dimensionado individualmente além do datacenter.
Existem muitos sistemas de mensagens que suportam esses paradigmas e fornecem uma API elegante, orientada por protocolos TCP ou HTTP, por exemplo, JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ, etc.
O que é aipo?
O aipo é um dos gerenciadores de trabalho em segundo plano mais populares no mundo Python. O aipo é compatível com vários corretores de mensagens como RabbitMQ ou Redis e pode atuar como produtor e consumidor.
O aipo é uma fila de tarefas/fila de tarefas assíncronas com base na passagem de mensagens distribuídas. Ele é focado em operações em tempo real, mas também suporta agendamento. As unidades de execução, chamadas de tarefas, são executadas simultaneamente em um ou mais servidores de trabalho usando multiprocessamento, Eventlet ou gevent. As tarefas podem ser executadas de forma assíncrona (em segundo plano) ou de forma síncrona (aguarde até ficar pronta). – Projeto Aipo
Para começar com o aipo, basta seguir um guia passo a passo nos documentos oficiais.
O foco deste artigo é fornecer uma boa compreensão de quais casos de uso podem ser cobertos pelo Celery. Neste artigo, não apenas mostraremos exemplos interessantes, mas também tentaremos aprender como aplicar o Celery a tarefas do mundo real, como correspondência em segundo plano, geração de relatórios, registro em log e relatório de erros. Compartilharei minha maneira de testar as tarefas além da emulação e, por fim, fornecerei alguns truques que não estão (bem) documentados na documentação oficial que levei horas de pesquisa para descobrir por mim mesmo.
Se você não tem experiência anterior com o aipo, eu o encorajo primeiro a experimentá-lo seguindo o tutorial oficial.
Aguçando seu apetite
Se este artigo o intriga e faz você querer mergulhar no código imediatamente, siga para este repositório do GitHub para obter o código usado neste artigo. O arquivo README lá lhe dará a abordagem rápida e suja para executar e brincar com os aplicativos de exemplo.
Primeiros passos com aipo
Para começar, passaremos por uma série de exemplos práticos que mostrarão ao leitor como o aipo resolve tarefas aparentemente não triviais de forma simples e elegante. Todos os exemplos serão apresentados dentro do framework Django; no entanto, a maioria deles pode ser facilmente portada para outros frameworks Python (Flask, Pyramid).
O layout do projeto foi gerado pelo Cookiecutter Django; porém, mantive apenas algumas dependências que, na minha opinião, facilitam o desenvolvimento e preparação desses casos de uso. Também removi módulos desnecessários para este post e aplicativos para reduzir o ruído e tornar o código mais fácil de entender.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}contém diferentes aplicativos que abordaremos neste post. Cada aplicativo contém um conjunto de exemplos organizados pelo nível de compreensão de aipo necessário. -
celery_uncovered/celery.pydefine uma instância Celery.
Arquivo: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Então precisamos ter certeza de que o Celery começará junto com o Django. Por esse motivo, importamos o aplicativo em celery_uncovered/__init__.py .
Arquivo: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings é a fonte de configuração para nosso aplicativo e Celery. Dependendo do ambiente de execução, o Django iniciará as configurações correspondentes: local.py para desenvolvimento ou test.py para teste. Você também pode definir seu próprio ambiente, se quiser, criando um novo módulo python (por exemplo, prod.py ). As configurações de aipo são prefixadas com CELERY_ . Para este post, configurei o RabbitMQ como o broker e o SQLite como o resultado final.
Arquivo: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Cenário 1 - Geração e exportação de relatórios
O primeiro caso que abordaremos é a geração e exportação de relatórios. Neste exemplo, você aprenderá a definir uma tarefa que produz um relatório CSV e agendá-lo em intervalos regulares com celerybeat.
Descrição do caso de uso: busque os quinhentos repositórios mais quentes do GitHub por período escolhido (dia, semana, mês), agrupe-os por tópicos e exporte o resultado para o arquivo CSV.
Se fornecermos um serviço HTTP que executará esse recurso acionado clicando em um botão rotulado "Gerar relatório", o aplicativo parará e aguardará a conclusão da tarefa antes de enviar uma resposta HTTP de volta. Isto é mau. Queremos que nosso aplicativo da Web seja rápido e não queremos que nossos usuários esperem enquanto nosso back-end calcula os resultados. Em vez de esperar que os resultados sejam produzidos, preferimos enfileirar a tarefa para os processos de trabalho por meio de uma fila registrada no Celery e responder com um task_id ao front-end. Em seguida, o front-end usaria o task_id para consultar o resultado da tarefa de maneira assíncrona (por exemplo, AJAX) e manterá o usuário atualizado com o andamento da tarefa. Finalmente, quando o processo termina, os resultados podem ser servidos como um arquivo para download via HTTP.
Detalhes de implementação
Antes de tudo, vamos decompor o processo em suas menores unidades possíveis e criar um pipeline:
- Os buscadores são os trabalhadores responsáveis por obter repositórios do serviço GitHub.
- O Agregador é o trabalhador responsável por consolidar os resultados em uma lista.
- O Importador é o trabalhador que está produzindo relatórios CSV dos repositórios mais quentes no GitHub.
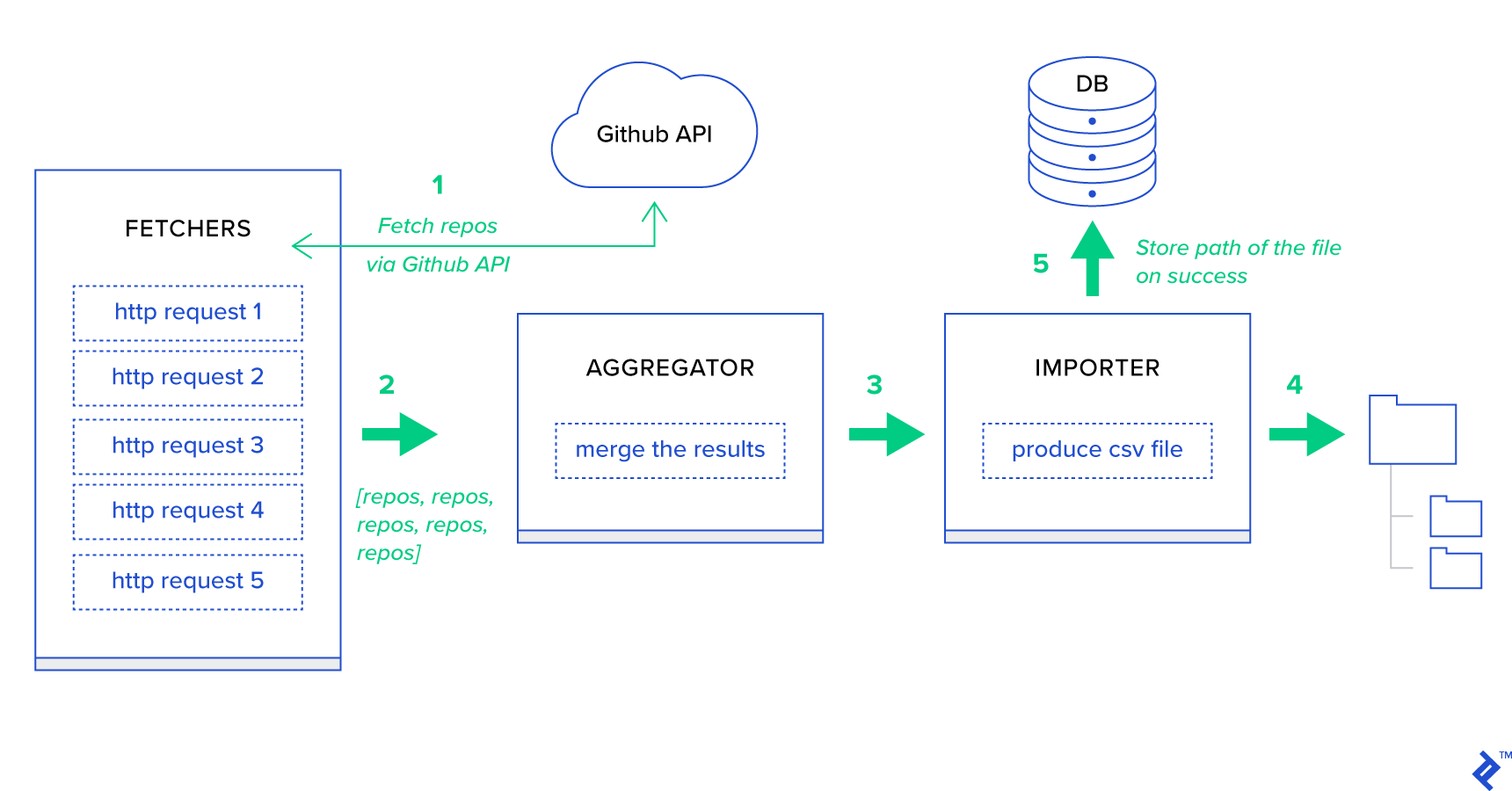
A busca de repositórios é uma solicitação HTTP usando a API de pesquisa do GitHub GET /search/repositories . No entanto, há uma limitação do serviço GitHub API que deve ser tratada: A API retorna até 100 repositórios por solicitação em vez de 500. Poderíamos enviar cinco solicitações uma de cada vez, mas não queremos deixar nosso usuário esperando para cinco solicitações individuais, pois as solicitações HTTP são uma operação vinculada à E/S. Em vez disso, podemos executar cinco solicitações HTTP simultâneas com um parâmetro de página apropriado. Assim, a página estará no intervalo [1..5]. Vamos definir uma tarefa chamada fetch_hot_repos/3 -> list no módulo toyex/tasks.py :
Arquivo: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Então fetch_hot_repos cria uma solicitação para a API do GitHub e responde ao usuário com uma lista de repositórios. Ele recebe três parâmetros que definirão nosso payload de solicitação:
-
since— Filtra os repositórios na data de criação. -
per_page— Número de resultados a serem retornados por solicitação (limitado por 100). -
page—- Número da página solicitada (no intervalo [1..5]).
Observação: para usar a API de pesquisa do GitHub, você precisará de um token OAuth para passar nas verificações de autenticação. No nosso caso, ele é salvo nas configurações em GITHUB_OAUTH .
Em seguida, precisamos definir uma tarefa mestre que será responsável por agregar os resultados e exportá-los para um arquivo CSV: produce_hot_repo_report_task/2->filepath:
Arquivo: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Esta tarefa usa celery.canvas.group para executar cinco chamadas simultâneas de fetch_hot_repos/3 . Esses resultados são esperados e então reduzidos a uma lista de objetos de repositório. Em seguida, nosso conjunto de resultados é agrupado por tópico e finalmente exportado para um arquivo CSV gerado no diretório MEDIA_ROOT/ .
Para agendar a tarefa periodicamente, você pode adicionar uma entrada à lista de agendamento no arquivo de configuração:
Arquivo: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Experimentando
Para iniciar e testar como a tarefa está funcionando, primeiro precisamos iniciar o processo Celery:
$ celery -A celery_uncovered worker -l info Em seguida, precisamos criar o celery_uncovered/media/ . Então, você poderá testar sua funcionalidade via Shell ou Celerybeat:
Escudo :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Batida de aipo :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Você pode assistir aos resultados no diretório MEDIA_ROOT/ .
Cenário 2 - Relatório sobre erros do Server 500 por e-mail
Um dos casos de uso mais comuns do Celery é o envio de notificações por e-mail. A notificação por email é uma operação vinculada à E/S offline que aproveita um servidor SMTP local ou um SES de terceiros. Existem muitos casos de uso que envolvem o envio de um email e, na maioria deles, o usuário não precisa esperar até que esse processo seja concluído antes de receber uma resposta HTTP. É por isso que é preferível executar essas tarefas em segundo plano e responder ao usuário imediatamente.
Descrição do caso de uso: relatar erros 50X ao e-mail do administrador por meio do aipo.
Python e Django têm o background necessário para realizar o log do sistema. Não entrarei em detalhes de como o log do Python realmente funciona. No entanto, se você nunca experimentou antes ou precisa de uma atualização, leia a documentação do módulo de log integrado. Você definitivamente quer isso em seu ambiente de produção. O Django tem um manipulador de logs especial chamado AdminEmailHandler que envia emails aos administradores para cada mensagem de log que recebe.
Detalhes de implementação
A ideia principal é estender o método send_mail da classe AdminEmailHandler de tal forma que ele possa enviar mensagens via Celery. Isso pode ser feito conforme ilustrado na figura abaixo:
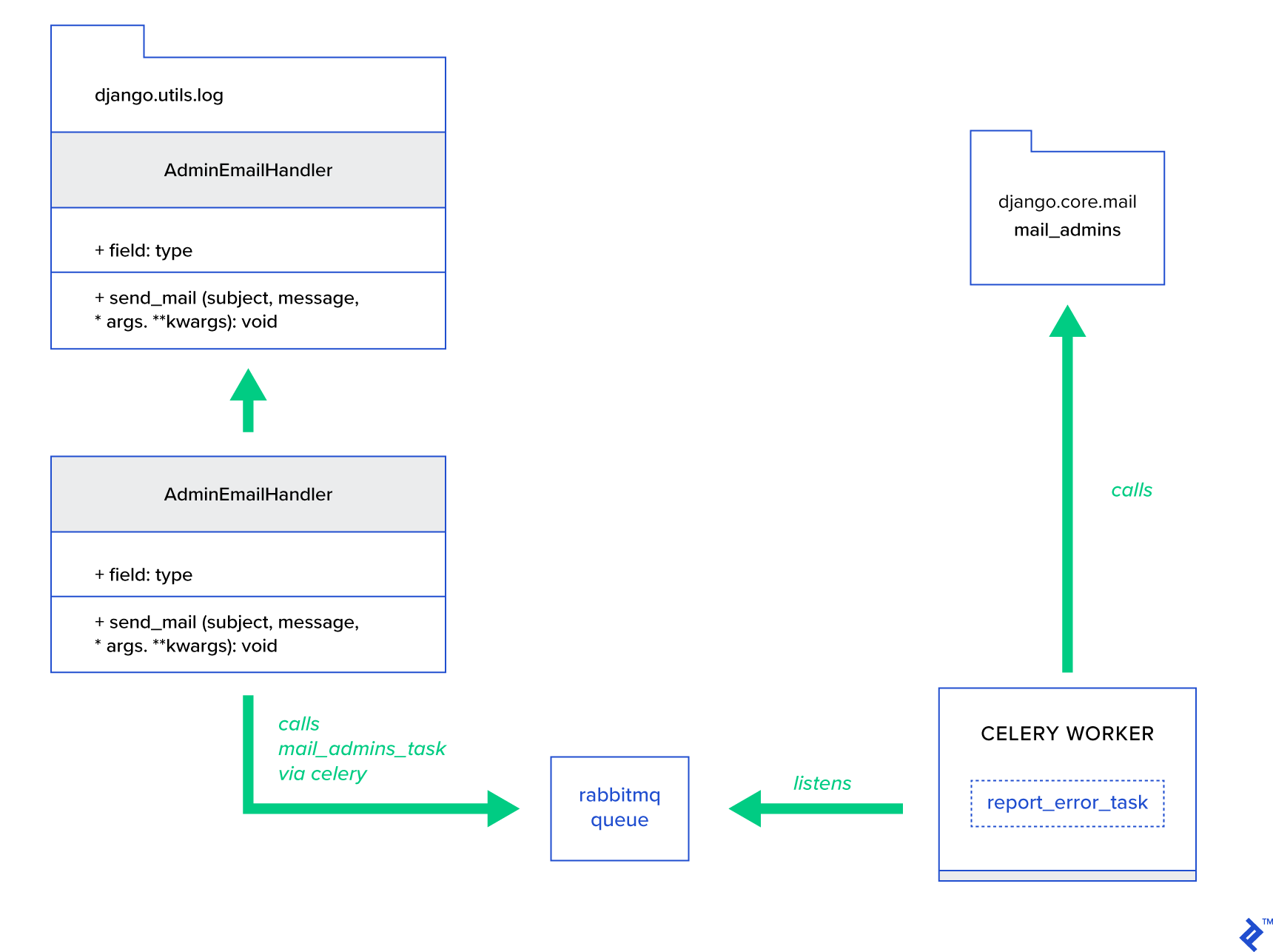
Primeiro, precisamos configurar uma tarefa chamada report_error_task que chama mail_admins com o assunto e a mensagem fornecidos:
Arquivo: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Em seguida, estendemos AdminEmailHandler para que ele chame internamente apenas a tarefa Celery definida:
Arquivo: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Por fim, precisamos configurar o log. A configuração de log no Django é bastante direta. O que você precisa é substituir LOGGING para que o mecanismo de registro comece usando um manipulador recém-definido:
Arquivo config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Observe que configuro intencionalmente filtros de manipulador require_debug_true para testar essa funcionalidade enquanto o aplicativo está sendo executado no modo de depuração.
Experimentando
Para testá-lo, preparei uma view do Django que serve uma operação “division-by-zero” em localhost:8000/report-error . Você também precisa iniciar um contêiner do MailHog Docker para testar se o email é realmente enviado.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Detalhes extras
Como uma ferramenta de teste de correio, configurei o MailHog e configurei o correio Django para usá-lo para entrega SMTP. Há muitas maneiras de implantar e executar o MailHog. Eu decidi ir com um contêiner Docker. Você pode encontrar os detalhes no arquivo README correspondente:
Arquivo: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Para configurar seu aplicativo para usar o MailHog, você precisa adicionar as seguintes linhas em sua configuração:
Arquivo: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Além das tarefas padrão de aipo
As tarefas de aipo podem ser criadas a partir de qualquer função que pode ser chamada. Por padrão, qualquer tarefa definida pelo usuário é injetada com celery.app.task.Task como uma classe pai (abstrata). Essa classe contém a funcionalidade de executar tarefas de forma assíncrona (passando-as pela rede para um trabalhador do Celery) ou de forma síncrona (para fins de teste), criando assinaturas e muitos outros utilitários. Nos próximos exemplos, tentaremos estender Celery.app.task.Task e usá-lo como uma classe base para adicionar alguns comportamentos úteis às nossas tarefas.
Cenário 3 - Registro de arquivos por tarefa
Em um dos meus projetos, eu estava desenvolvendo um aplicativo que fornece ao usuário final uma ferramenta do tipo Extract, Transform, Load (ETL) capaz de ingerir e filtrar uma enorme quantidade de dados hierárquicos. O back-end foi dividido em dois módulos:
- Orquestração de um pipeline de processamento de dados com Celery
- Processamento de dados com Go
O Celery foi implantado com uma instância do Celerybeat e mais de 40 trabalhadores. Havia mais de vinte tarefas diferentes que compunham as atividades de pipeline e orquestração. Cada uma dessas tarefas pode falhar em algum momento. Todas essas falhas foram despejadas no log do sistema de cada trabalhador. Em algum momento, começou a se tornar inconveniente depurar e manter a camada de aipo. Eventualmente, decidimos isolar o log de tarefas para um arquivo específico de tarefa.
Descrição do caso de uso: Estenda o Celery para que cada tarefa registre sua saída padrão e erros em arquivos
O Celery fornece aos aplicativos Python grande controle sobre o que ele faz internamente. Ele vem com uma estrutura de sinais familiar. Os aplicativos que usam o Celery podem se inscrever em alguns deles para aumentar o comportamento de determinadas ações. Vamos aproveitar os sinais de nível de tarefa para fornecer rastreamento detalhado dos ciclos de vida de tarefas individuais. O aipo sempre vem com um back-end de registro, e vamos nos beneficiar dele enquanto apenas substituimos um pouco em alguns lugares para atingir nossos objetivos.
Detalhes de implementação
O aipo já suporta o registro por tarefa. Para salvar em um arquivo, é necessário despachar a saída do log para o local apropriado. No nosso caso, a localização adequada da tarefa é um arquivo que corresponde ao nome da tarefa. Na instância do Celery, substituiremos a configuração de log integrada por manipuladores de log inferidos dinamicamente. É possível assinar o sinal celeryd_after_setup e então configurar o log do sistema lá:
Arquivo: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Observe que para cada tarefa registrada no aplicativo Celery, estamos construindo um registrador correspondente com seu manipulador. Cada manipulador é do tipo logging.FileHandler e, portanto, cada instância recebe um nome de arquivo como entrada. Tudo o que você precisa para executar é importar este módulo para celery_uncovered/celery.py no final do arquivo:
import celery_uncovered.tricks.celery_conf Um registrador de tarefas específico pode ser recebido chamando get_task_logger(task_name) . Para generalizar tal comportamento para cada tarefa, é necessário estender um pouco celery.current_app.Task com alguns métodos utilitários:
Arquivo: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Agora, no caso de uma chamada para task.log_msg("Hello, my name is: %s", task.request.id) , a saída do log será roteada para o arquivo correspondente sob o nome da tarefa.
Experimentando
Para iniciar e testar como esta tarefa está funcionando, primeiro inicie o processo Celery:
$ celery -A celery_uncovered worker -l infoEntão você poderá testar a funcionalidade via Shell:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Por fim, para ver o resultado, navegue até o diretório celery_uncovered/logs e abra o arquivo de log correspondente chamado celery_uncovered.tricks.tasks.add.log . Você pode ver algo semelhante ao abaixo depois de executar esta tarefa várias vezes:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Cenário 4 - Tarefas com reconhecimento de escopo
Vamos imaginar um aplicativo Python para usuários internacionais construído em Celery e Django. Os usuários podem definir em qual idioma (localidade) eles usam seu aplicativo.
Você precisa criar um sistema de notificação por e-mail multilíngue e com reconhecimento de localidade. Para enviar notificações por e-mail, você registrou uma tarefa especial de aipo que é tratada por uma fila específica. Essa tarefa recebe alguns argumentos importantes como entrada e uma localidade do usuário atual para que o email seja enviado no idioma escolhido pelo usuário.
Agora imagine que temos muitas dessas tarefas, mas cada uma dessas tarefas aceita um argumento de localidade. Nesse caso, não seria melhor resolvê-lo em um nível mais alto de abstração? Aqui, vemos exatamente como fazer isso.
Descrição do caso de uso: Herdar automaticamente o escopo de um contexto de execução e injetá-lo no contexto de execução atual como um parâmetro.
Detalhes de implementação
Novamente, como fizemos com o registro de tarefas, queremos estender uma classe de tarefa básica celery.current_app.Task e substituir alguns métodos responsáveis por chamar tarefas. Para fins desta demonstração, estou substituindo o método celery.current_app.Task::apply_async . Existem tarefas extras para este módulo que o ajudarão a produzir uma substituição totalmente funcional.
Arquivo: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)A dica chave é passar a localidade atual como um argumento de valor-chave para uma tarefa de chamada por padrão. Se uma tarefa foi chamada com uma determinada localidade como argumento, ela não será alterada.
Experimentando
Para testar essa funcionalidade, vamos definir uma tarefa fictícia do tipo ScopeBasedTask . Ele localiza um arquivo por código de localidade e lê seu conteúdo como JSON:
Arquivo: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Agora o que você precisa fazer é repetir as etapas de iniciar o Celery, iniciar o shell e testar a execução dessa tarefa em diferentes cenários. As luminárias estão localizadas no celery_uncovered/tricks/fixtures/locales/ .
Conclusão
Este post teve como objetivo explorar o aipo de diferentes perspectivas. Demonstrei o Celery em exemplos convencionais, como envio de correspondência e geração de relatórios, bem como truques compartilhados para alguns casos de uso de negócios de nicho interessantes. O aipo é construído com base em uma filosofia orientada a dados e sua equipe pode tornar suas vidas muito mais simples ao introduzi-lo como parte de sua pilha de sistemas. O desenvolvimento de serviços baseados em Celery não é muito complicado se você tiver experiência básica em Python e deve ser capaz de aprender rapidamente. A configuração padrão é boa o suficiente para a maioria dos usos, mas, se necessário, pode ser muito flexível.
Nossa equipe optou por usar o Celery como back-end de orquestração para trabalhos em segundo plano e tarefas de longa duração. Nós o usamos extensivamente para uma variedade de casos de uso, dos quais apenas alguns foram mencionados neste post. Ingerimos e analisamos gigabytes de dados todos os dias, mas isso é apenas o começo das técnicas de dimensionamento horizontal.