
تنظيم سير عمل في الخلفية في الكرفس للبايثون
نشرت: 2022-03-11أصبحت تطبيقات الويب الحديثة وأنظمتها الأساسية أسرع وأكثر استجابة من أي وقت مضى. ومع ذلك ، لا يزال هناك العديد من الحالات التي تريد فيها إلغاء تحميل تنفيذ مهمة ثقيلة إلى أجزاء أخرى من بنية النظام بالكامل بدلاً من معالجتها في سلسلة المحادثات الرئيسية. تحديد مثل هذه المهام بسيط مثل التحقق لمعرفة ما إذا كانت تنتمي إلى إحدى الفئات التالية:
- المهام الدورية - الوظائف التي ستقوم بجدولتها للتشغيل في وقت محدد أو بعد فترة زمنية ، على سبيل المثال ، إنشاء تقرير شهري أو مكشطة ويب تعمل مرتين في اليوم.
- مهام الجهات الخارجية - يجب أن يخدم تطبيق الويب المستخدمين بسرعة دون انتظار اكتمال الإجراءات الأخرى أثناء تحميل الصفحة ، على سبيل المثال ، إرسال بريد إلكتروني أو إشعار أو نشر التحديثات إلى الأدوات الداخلية (مثل جمع البيانات لاختبار A / B أو تسجيل النظام ).
- الوظائف طويلة الأمد - الوظائف باهظة الثمن في الموارد ، حيث يحتاج المستخدمون إلى الانتظار أثناء حساب نتائجهم ، على سبيل المثال ، تنفيذ سير العمل المعقد (تدفقات عمل DAG) ، وإنشاء الرسم البياني ، وتقليل المهام المشابهة ، وتقديم محتوى الوسائط (فيديو ، صوتي).
سيكون الحل المباشر لتنفيذ مهمة في الخلفية هو تشغيلها ضمن سلسلة أو عملية منفصلة. Python هي لغة برمجة كاملة من Turing عالية المستوى ، والتي للأسف لا توفر التزامًا مدمجًا على مقياس يطابق تلك الموجودة في Erlang أو Go أو Java أو Scala أو Akka. تلك تستند إلى عمليات الاتصال المتسلسلة (CSP) لتوني هور. من ناحية أخرى ، يتم تنسيق خيوط Python وجدولتها بواسطة قفل المترجم العام (GIL) ، والذي يمنع العديد من الخيوط الأصلية من تنفيذ أكواد Python بايت في وقت واحد. يعد التخلص من GIL موضوع نقاش كبير بين مطوري Python ، لكنه ليس محور هذه المقالة. البرمجة المتزامنة في Python من الطراز القديم ، على الرغم من أنه نرحب بقراءتها في Python Multithreading Tutorial بواسطة زميل Toptaler Marcus McCurdy. لذلك ، فإن تصميم الاتصال بين العمليات باستمرار هو عملية عرضة للخطأ ويؤدي إلى اقتران الكود وقابلية صيانة النظام السيئة ، ناهيك عن أنه يؤثر سلبًا على قابلية التوسع. بالإضافة إلى ذلك ، فإن عملية Python هي عملية عادية في ظل نظام التشغيل (OS) ، ومع مكتبة Python القياسية بأكملها ، تصبح عملية ذات وزن ثقيل. مع زيادة عدد العمليات في التطبيق ، يصبح التبديل من عملية إلى أخرى عملية تستغرق وقتًا طويلاً.
لفهم التزامن مع Python بشكل أفضل ، شاهد هذا الخطاب المذهل لديفيد بيزلي في PyCon'15.
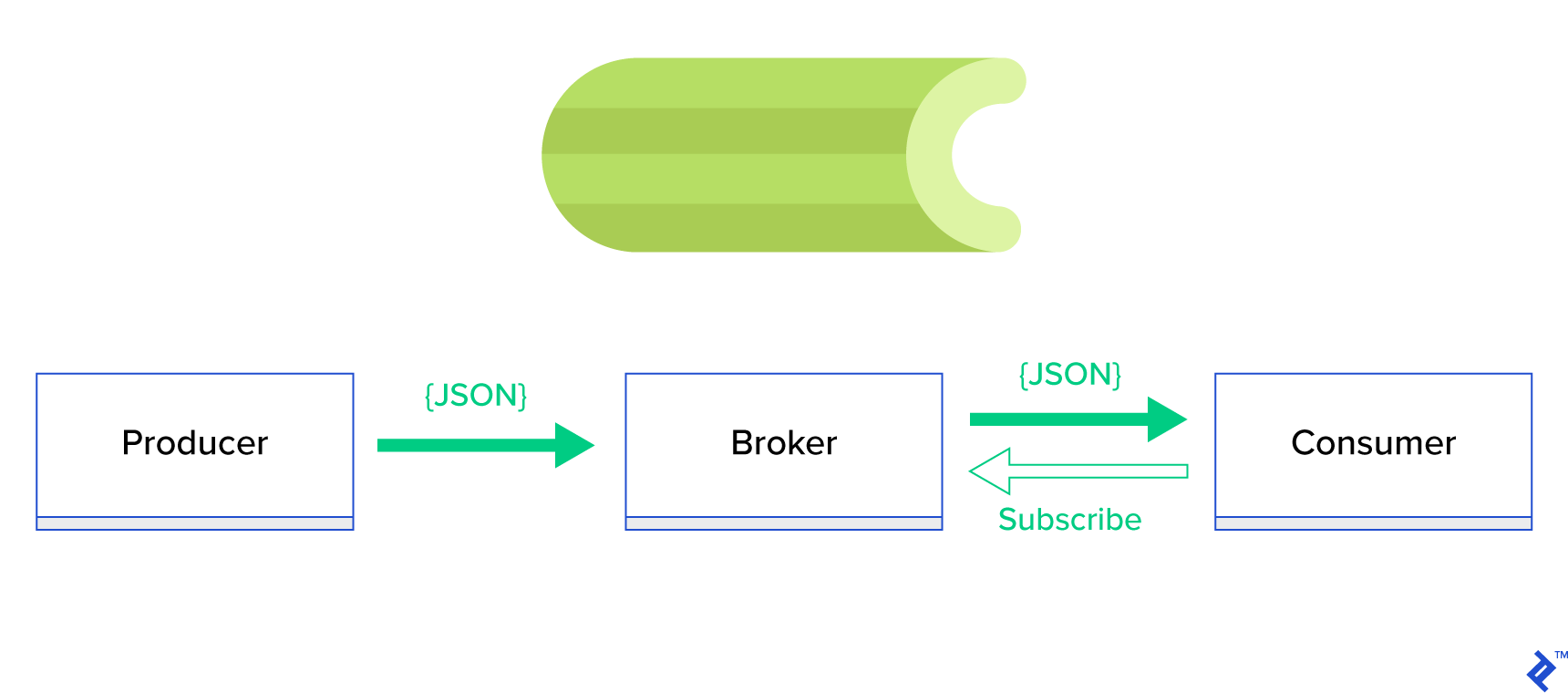
الحل الأفضل هو خدمة قائمة انتظار موزعة أو نموذج أشقائها المعروف المعروف باسم النشر والاشتراك . كما هو موضح في الشكل 1 ، هناك نوعان من التطبيقات ، أحدهما ، يسمى الناشر ، يرسل الرسائل والآخر ، يسمى المشترك ، يتلقى الرسائل. هذان الوكيلان لا يتفاعلان مع بعضهما البعض بشكل مباشر ولا يدركان حتى بعضهما البعض. يرسل الناشرون رسائل إلى قائمة انتظار مركزية ، أو وسيط ، ويتلقى المشتركون رسائل تهم هذا الوسيط. هناك ميزتان رئيسيتان في هذه الطريقة:
- قابلية التوسع - لا يحتاج الوكلاء إلى معرفة بعضهم البعض في الشبكة. هم يركزون حسب الموضوع. لذلك فهذا يعني أنه يمكن لكل منهما الاستمرار في العمل بشكل طبيعي بغض النظر عن الآخر بطريقة غير متزامنة.
- اقتران فضفاض - يمثل كل عامل الجزء الخاص به من النظام (خدمة ، وحدة). نظرًا لأنها مقترنة بشكل غير محكم ، يمكن لكل منها التوسع بشكل فردي خارج مركز البيانات.
هناك الكثير من أنظمة المراسلة التي تدعم مثل هذه النماذج وتوفر واجهة برمجة تطبيقات أنيقة ، مدفوعة إما ببروتوكولات TCP أو HTTP ، على سبيل المثال ، JMS و RabbitMQ و Redis Pub / Sub و Apache ActiveMQ وما إلى ذلك.
ما هو الكرفس؟
يعد الكرفس أحد أشهر مديري الوظائف في الخلفية في عالم بايثون. الكرفس متوافق مع العديد من وسطاء الرسائل مثل RabbitMQ أو Redis ويمكنه العمل كمنتج ومستهلك.
الكرفس عبارة عن قائمة انتظار / قائمة انتظار مهام غير متزامنة تعتمد على تمرير الرسائل الموزعة. إنه يركز على العمليات في الوقت الفعلي ولكنه يدعم الجدولة أيضًا. يتم تنفيذ وحدات التنفيذ ، التي تسمى المهام ، بشكل متزامن على خادم عامل واحد أو أكثر باستخدام المعالجة المتعددة أو Eventlet أو gevent. يمكن تنفيذ المهام بشكل غير متزامن (في الخلفية) أو بشكل متزامن (انتظر حتى تصبح جاهزة). - مشروع الكرفس
لبدء استخدام الكرفس ، ما عليك سوى اتباع دليل تفصيلي في المستندات الرسمية.
تركز هذه المقالة على تزويدك بفهم جيد لحالات الاستخدام التي يمكن تغطيتها بواسطة الكرفس. في هذه المقالة ، لن نعرض أمثلة مثيرة للاهتمام فحسب ، بل سنحاول أيضًا تعلم كيفية تطبيق الكرفس على مهام العالم الحقيقي مثل إرسال الرسائل في الخلفية وإنشاء التقارير والتسجيل والإبلاغ عن الأخطاء. سأشارك طريقي في اختبار المهام التي تتجاوز المحاكاة ، وأخيراً ، سأقدم بعض الحيل التي لم يتم توثيقها (جيدًا) في الوثائق الرسمية التي استغرقت ساعات من البحث لاكتشافها بنفسي.
إذا لم تكن لديك خبرة سابقة مع الكرفس ، فإنني أشجعك أولاً على تجربته باتباع البرنامج التعليمي الرسمي.
شحذ شهيتك
إذا كانت هذه المقالة تثير اهتمامك وتجعلك ترغب في الغوص في الكود على الفور ، فاتبع هذا المستودع GitHub للرمز المستخدم في هذه المقالة. سيمنحك ملف README هناك طريقة سريعة وقذرة للتشغيل واللعب باستخدام تطبيقات الأمثلة.
الخطوات الأولى مع الكرفس
بالنسبة للمبتدئين ، سنستعرض سلسلة من الأمثلة العملية التي ستظهر للقارئ كيف يحل الكرفس ببساطة وأناقة مهام تبدو غير تافهة. سيتم تقديم جميع الأمثلة في إطار عمل Django ؛ ومع ذلك ، يمكن بسهولة نقل معظمها إلى أطر Python الأخرى (Flask ، Pyramid).
تم إنشاء تخطيط المشروع بواسطة Cookiecutter Django ؛ ومع ذلك ، احتفظت فقط ببعض التبعيات التي ، في رأيي ، تسهل تطوير وإعداد حالات الاستخدام هذه. لقد أزلت أيضًا الوحدات غير الضرورية لهذا المنشور والتطبيقات لتقليل الضوضاء وجعل الكود أسهل في الفهم.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}على تطبيقات مختلفة سنغطيها في هذا المنشور. يحتوي كل تطبيق على مجموعة من الأمثلة التي يتم تنظيمها حسب مستوى فهم الكرفس المطلوب. - يعرف
celery_uncovered/celery.pyمثيل الكرفس.
ملف: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() ثم نحتاج إلى التأكد من أن الكرفس سيبدأ مع Django. لهذا السبب ، نقوم باستيراد التطبيق في celery_uncovered/__init__.py .
الملف: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings هي مصدر التكوين لتطبيقنا و Celery. اعتمادًا على بيئة التنفيذ ، سيطلق Django الإعدادات المقابلة: local.py للتطوير أو test.py للاختبار. يمكنك أيضًا تحديد بيئتك الخاصة إذا كنت تريد ذلك عن طريق إنشاء وحدة Python جديدة (على سبيل المثال ، prod.py ). تكون تكوينات الكرفس مسبوقة بـ CELERY_ . بالنسبة لهذا المنشور ، قمت بتكوين RabbitMQ كوسيط و SQLite كنتيجة للبكالوريا.
الملف: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'السيناريو 1 - إنشاء التقرير وتصديره
الحالة الأولى التي سنغطيها هي إنشاء التقارير وتصديرها. في هذا المثال ، ستتعلم كيفية تحديد مهمة ينتج عنها تقرير بتنسيق CSV وجدولتها على فترات منتظمة باستخدام كرفس.
استخدام وصف الحالة: قم بإحضار أهم خمسمائة مستودعات من GitHub لكل فترة محددة (يوم ، أسبوع ، شهر) ، قم بتجميعها حسب الموضوعات ، وقم بتصدير النتيجة إلى ملف CSV.
إذا قدمنا خدمة HTTP ستنفذ هذه الميزة التي يتم تشغيلها بالنقر فوق الزر المسمى "إنشاء تقرير" ، فسيتوقف التطبيق وينتظر حتى تكتمل المهمة قبل إرسال استجابة HTTP مرة أخرى. هذا سيء. نريد أن يكون تطبيق الويب الخاص بنا سريعًا ولا نريد أن ينتظر المستخدمون لدينا بينما تقوم الواجهة الخلفية بحساب النتائج. بدلاً من انتظار ظهور النتائج ، نفضل أن نضع المهمة في قائمة الانتظار لعمليات العمال عبر قائمة انتظار مسجلة في الكرفس ونستجيب بـ task_id الأمامية. ثم تستخدم الواجهة الأمامية task_id للاستعلام عن نتيجة المهمة بطريقة غير متزامنة (على سبيل المثال ، AJAX) وستبقي المستخدم على اطلاع دائم بتقدم المهمة. أخيرًا ، عند انتهاء العملية ، يمكن تقديم النتائج كملف للتنزيل عبر HTTP.
تفاصيل التنفيذ
بادئ ذي بدء ، دعونا نحلل العملية إلى أصغر وحداتها الممكنة وننشئ خط أنابيب:
- الجلبون هم العمال المسؤولون عن الحصول على المستودعات من خدمة GitHub.
- المُجمِّع هو العامل المسؤول عن دمج النتائج في قائمة واحدة.
- المستورد هو العامل الذي ينتج تقارير بتنسيق CSV لأهم المستودعات في GitHub.
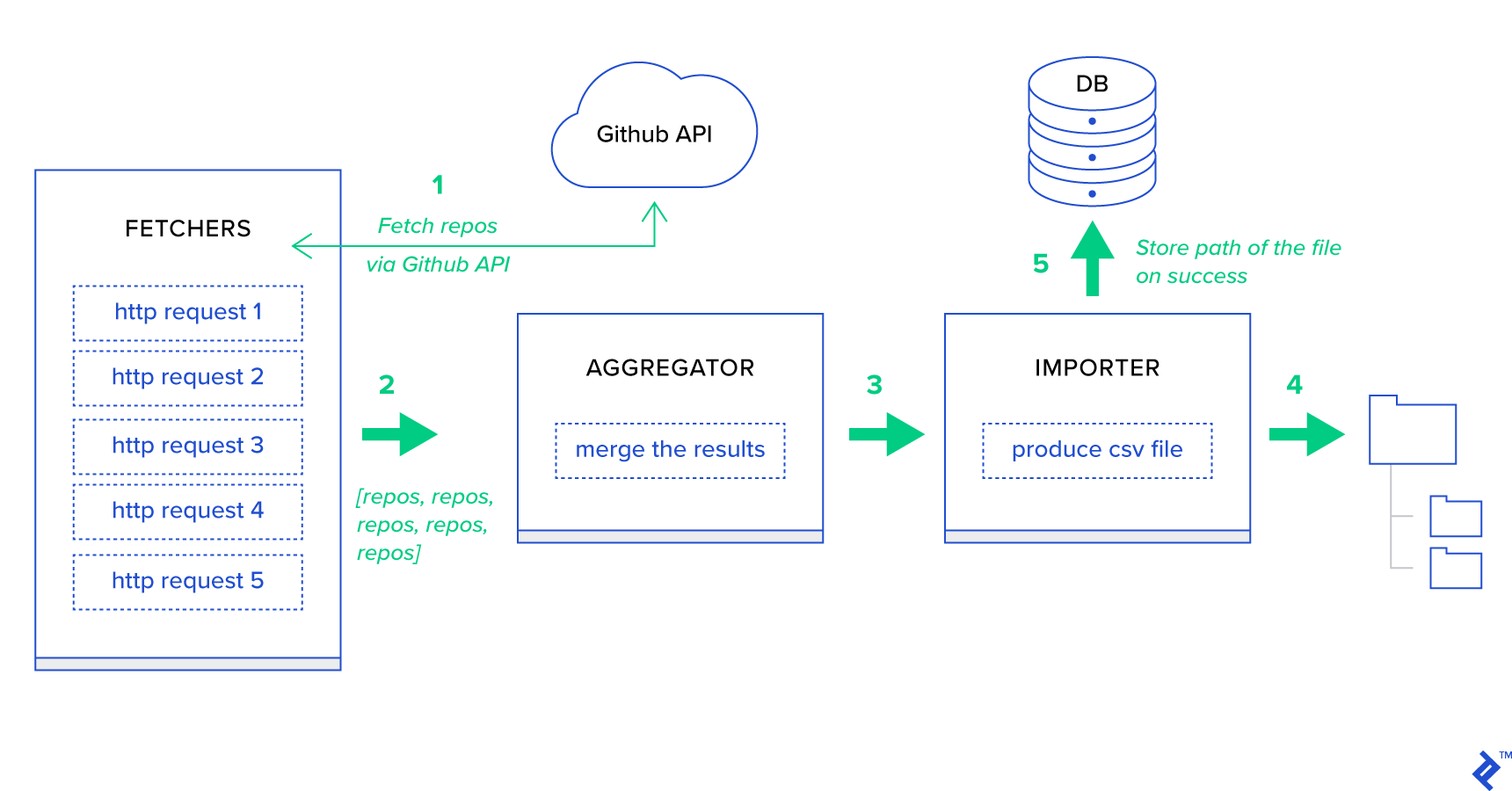
جلب المستودعات هو طلب HTTP يستخدم Git GET /search/repositories GitHub Search API. ومع ذلك ، هناك قيود على خدمة GitHub API التي يجب معالجتها: تقوم واجهة برمجة التطبيقات بإرجاع ما يصل إلى 100 مستودع تخزين لكل طلب بدلاً من 500. يمكننا إرسال خمسة طلبات واحدًا تلو الآخر ، لكننا لا نريد إبقاء مستخدمنا في انتظار لخمسة طلبات فردية نظرًا لأن طلبات HTTP هي عملية مرتبطة بالإدخال / الإخراج. بدلاً من ذلك ، يمكننا تنفيذ خمسة طلبات HTTP متزامنة باستخدام معلمة صفحة مناسبة. لذلك ستكون الصفحة في النطاق [1..5]. دعنا نحدد مهمة تسمى fetch_hot_repos/3 -> list في وحدة toyex/tasks.py :
ملف: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items لذا ، ينشئ fetch_hot_repos طلبًا إلى GitHub API ويستجيب للمستخدم بقائمة من المستودعات. يتلقى ثلاث معلمات ستحدد حمولة طلبنا:
-
since- يتم ترشيح المستودعات في تاريخ الإنشاء. -
per_page- عدد النتائج المراد إرجاعها لكل طلب (محدود بـ 100). -
page—- رقم الصفحة المطلوبة (في النطاق [1..5]).
ملاحظة: من أجل استخدام واجهة برمجة تطبيقات بحث GitHub ، ستحتاج إلى رمز OAuth المميز لاجتياز فحوصات المصادقة. في حالتنا ، يتم حفظه في الإعدادات ضمن GITHUB_OAUTH .
بعد ذلك ، نحتاج إلى تحديد مهمة رئيسية ستكون مسؤولة عن تجميع النتائج وتصديرها إلى ملف CSV: produce_hot_repo_report_task/2->filepath:
ملف: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) تستخدم هذه المهمة celery.canvas.group لتنفيذ خمس استدعاءات متزامنة لـ fetch_hot_repos/3 . يتم انتظار هذه النتائج ثم تقليصها إلى قائمة كائنات المستودع. ثم يتم تجميع مجموعة النتائج الخاصة بنا حسب الموضوع وتصديرها أخيرًا إلى ملف CSV تم إنشاؤه ضمن الدليل MEDIA_ROOT/ .
لجدولة المهمة بشكل دوري ، قد ترغب في إضافة إدخال إلى قائمة الجدول في ملف التكوين:
الملف: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }تجربته
لبدء واختبار كيفية عمل المهمة ، نحتاج أولاً إلى بدء عملية الكرفس:
$ celery -A celery_uncovered worker -l info بعد ذلك ، نحتاج إلى إنشاء دليل celery_uncovered/media/ . بعد ذلك ، ستتمكن من اختبار وظائفه إما عبر Shell أو Celerybeat:
شل :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)الكرفس :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info يمكنك مشاهدة النتائج تحت MEDIA_ROOT/ الدليل.
السيناريو 2 - الإبلاغ عن أخطاء Server 500 عبر البريد الإلكتروني
إحدى حالات الاستخدام الأكثر شيوعًا للكرفس هي إرسال إشعارات بالبريد الإلكتروني. إخطار البريد الإلكتروني هو عملية مرتبطة بإدخال / إخراج غير متصل بالإنترنت تستفيد إما من خادم SMTP محلي أو SES تابع لجهة خارجية. هناك العديد من حالات الاستخدام التي تتضمن إرسال بريد إلكتروني ، وبالنسبة لمعظمها ، لا يحتاج المستخدم إلى الانتظار حتى تنتهي هذه العملية قبل تلقي استجابة HTTP. لهذا السبب يفضل تنفيذ مثل هذه المهام في الخلفية والرد على المستخدم على الفور.
استخدام وصف الحالة: أبلغ عن أخطاء 50X إلى البريد الإلكتروني للمسؤول عبر الكرفس.
يتمتع Python و Django بالخلفية اللازمة لإجراء تسجيل النظام. لن أخوض في تفاصيل كيفية عمل تسجيل بايثون بالفعل. ومع ذلك ، إذا لم تكن قد جربتها من قبل أو كنت بحاجة إلى تجديد معلومات ، فاقرأ وثائق وحدة التسجيل المدمجة. أنت بالتأكيد تريد هذا في بيئة الإنتاج الخاصة بك. لدى Django معالج خاص للمسجل يسمى AdminEmailHandler يقوم بإرسال رسائل البريد الإلكتروني للمسؤولين عن كل رسالة سجل يتلقاها.
تفاصيل التنفيذ
الفكرة الرئيسية هي توسيع طريقة send_mail لفئة AdminEmailHandler بحيث يمكنها إرسال البريد عبر Celery. يمكن القيام بذلك كما هو موضح في الشكل أدناه:
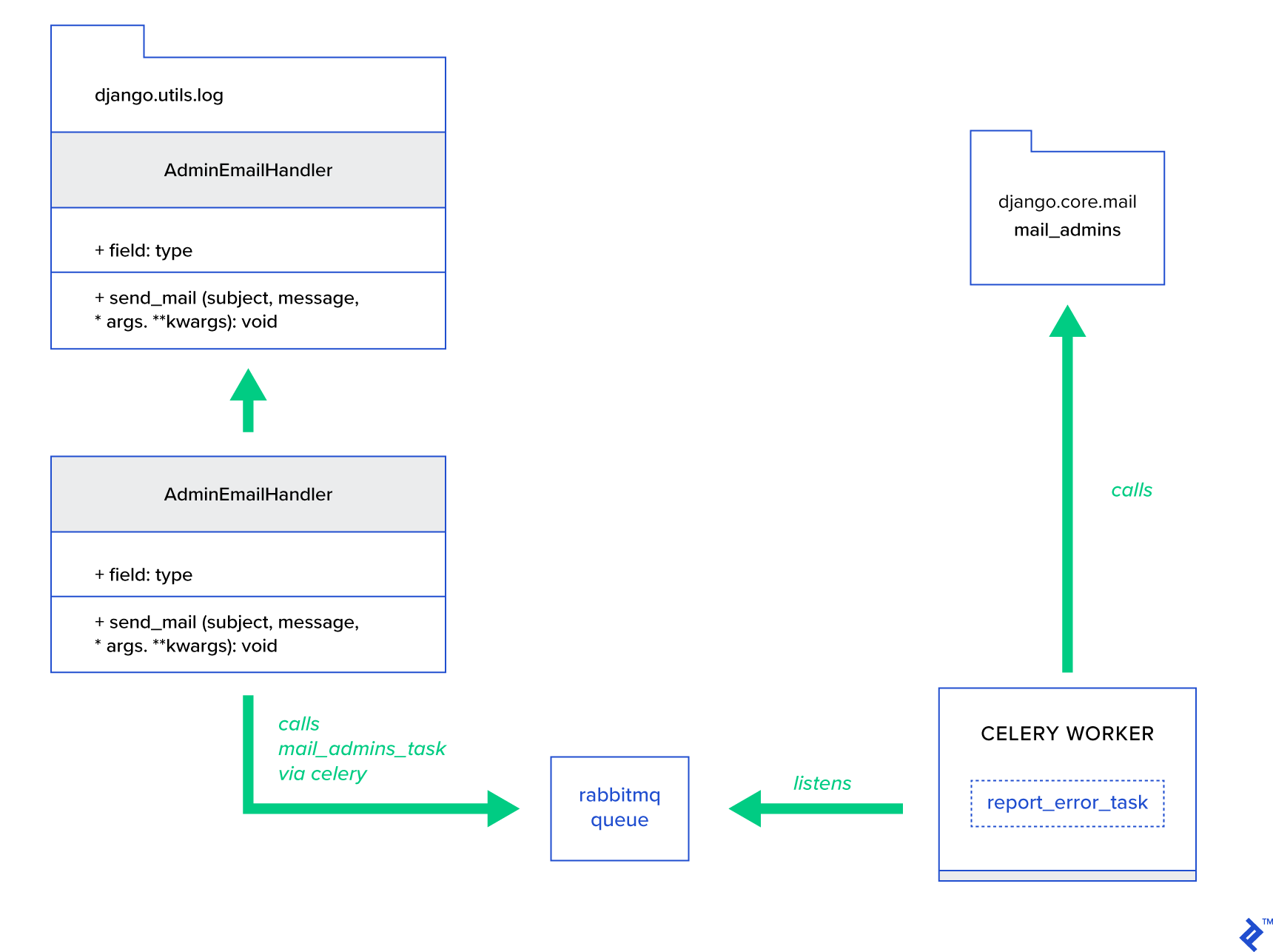
أولاً ، نحتاج إلى إعداد مهمة تسمى report_error_task تستدعي mail_admins المقدمين:
الملف: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)بعد ذلك ، قمنا بالفعل بتوسيع AdminEmailHandler بحيث يستدعي داخليًا مهمة الكرفس المحددة فقط:
الملف: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) أخيرًا ، نحتاج إلى إعداد التسجيل. تكوين التسجيل في Django واضح ومباشر. ما تحتاجه هو تجاوز LOGGING بحيث يبدأ محرك التسجيل باستخدام معالج محدد حديثًا:
ملف config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } لاحظ أنني أقوم بإعداد عوامل تصفية المعالج require_debug_true اختبار هذه الوظيفة أثناء تشغيل التطبيق في وضع التصحيح.
تجربته
لاختباره ، قمت بإعداد وجهة نظر Django التي تخدم عملية "القسمة على صفر" على localhost:8000/report-error . تحتاج أيضًا إلى بدء حاوية MailHog Docker لاختبار إرسال البريد الإلكتروني بالفعل.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)تفاصيل اضافية
كأداة لاختبار البريد ، قمت بإعداد MailHog وقمت بتهيئة بريد Django لاستخدامه لتسليم SMTP. هناك العديد من الطرق لنشر MailHog وتشغيله. قررت الذهاب مع حاوية Docker. يمكنك العثور على التفاصيل في ملف README المقابل:
الملف: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025لتهيئة تطبيقك لاستخدام MailHog ، تحتاج إلى إضافة الأسطر التالية في التكوين الخاص بك:
الملف: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')ما وراء مهام الكرفس الافتراضية
يمكن إنشاء مهام الكرفس من أي وظيفة قابلة للاستدعاء. بشكل افتراضي ، يتم حقن أي مهمة معرّفة من قبل المستخدم مع celery.app.task.Task كفئة أصل (مجردة). تحتوي هذه الفئة على وظائف تشغيل المهام بشكل غير متزامن (تمريرها عبر الشبكة إلى عامل الكرفس) أو بشكل متزامن (لأغراض الاختبار) ، وإنشاء التوقيعات والعديد من الأدوات المساعدة الأخرى. في الأمثلة التالية ، سنحاول توسيع Celery.app.task.Task ثم استخدامها كفئة أساسية لإضافة بعض السلوكيات المفيدة إلى مهامنا.
السيناريو 3 - ملف تسجيل لكل مهمة
في أحد مشاريعي ، كنت أقوم بتطوير تطبيق يزود المستخدم النهائي بأداة تشبه أداة الاستخراج والتحويل والتحميل (ETL) التي كانت قادرة على استيعاب كمية هائلة من البيانات الهرمية ثم تصفيتها. تم تقسيم الواجهة الخلفية إلى وحدتين:
- تنسيق خط أنابيب معالجة البيانات باستخدام الكرفس
- معالجة البيانات مع Go
تم نشر الكرفس مع مثيل Celerybeat واحد وأكثر من 40 عاملاً. كان هناك أكثر من عشرين مهمة مختلفة تتكون من أنشطة خط الأنابيب والتنسيق. قد تفشل كل مهمة من هذا القبيل في مرحلة ما. تم إلقاء كل هذه الإخفاقات في سجل النظام لكل عامل. في مرحلة ما ، أصبح من غير الملائم تصحيح أخطاء طبقة الكرفس والحفاظ عليها. في النهاية ، قررنا عزل سجل المهام إلى ملف مهمة محددة.
استخدام وصف الحالة: قم بتوسيع الكرفس بحيث تسجل كل مهمة مخرجاتها القياسية وأخطاءها في الملفات
يوفر الكرفس لتطبيقات Python تحكمًا كبيرًا فيما تقوم به داخليًا. يأتي مع إطار إشارات مألوف. يمكن للتطبيقات التي تستخدم الكرفس الاشتراك في عدد قليل من هؤلاء من أجل تعزيز سلوك إجراءات معينة. سنستفيد من إشارات مستوى المهمة لتوفير تتبع مطوّل لدورات حياة المهام الفردية. يأتي الكرفس دائمًا بنهاية خلفية للتسجيل ، وسنستفيد منه بينما نتجاوز قليلاً فقط في أماكن قليلة لتحقيق أهدافنا.
تفاصيل التنفيذ
يدعم الكرفس بالفعل التسجيل لكل مهمة. للحفظ في ملف ، من الضروري إرسال إخراج السجل إلى الموقع الصحيح. في حالتنا ، الموقع الصحيح للمهمة هو ملف يطابق اسم المهمة. في مثيل الكرفس ، سوف نتجاوز تكوين التسجيل المدمج مع معالجات التسجيل المستنبطة ديناميكيًا. من الممكن الاشتراك في إشارة celeryd_after_setup ثم تكوين تسجيل النظام هناك:
الملف: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) لاحظ أنه لكل مهمة مسجلة في تطبيق Celery ، نقوم ببناء مسجل مطابق باستخدام معالجها. كل معالج من النوع logging.FileHandler ، وبالتالي يتلقى كل مثيل اسم ملف كمدخل. كل ما تحتاجه لتشغيل هذا هو استيراد هذه الوحدة إلى celery_uncovered/celery.py في نهاية الملف:
import celery_uncovered.tricks.celery_conf يمكن تلقي مسجل مهمة معين عن طريق استدعاء get_task_logger(task_name) . لتعميم مثل هذا السلوك لكل مهمة ، من الضروري تمديد celery.current_app.Task بشكل طفيف. مهمة مع بعض الطرق المساعدة:
الملف: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) الآن ، في حالة استدعاء task.log_msg("Hello, my name is: %s", task.request.id) ، سيتم توجيه إخراج السجل إلى الملف المقابل تحت اسم المهمة.
تجربته
لبدء واختبار كيفية عمل هذه المهمة ، ابدأ أولاً عملية الكرفس:
$ celery -A celery_uncovered worker -l infoستتمكن بعد ذلك من اختبار الوظائف عبر شل:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) أخيرًا ، لمشاهدة النتيجة ، انتقل إلى دليل celery_uncovered/logs وافتح ملف السجل المقابل المسمى celery_uncovered.tricks.tasks.add.log . قد ترى شيئًا مشابهًا على النحو التالي بعد تشغيل هذه المهمة عدة مرات:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...السيناريو 4 - المهام الواعية بالنطاق
دعونا نتخيل تطبيق Python للمستخدمين الدوليين المبني على Celery و Django. يمكن للمستخدمين تعيين اللغة (الإعدادات المحلية) التي يستخدمون التطبيق الخاص بك بها.
يجب عليك تصميم نظام إعلام بالبريد الإلكتروني متعدد اللغات ومعرفة باللغة. لإرسال إشعارات بالبريد الإلكتروني ، لقد قمت بتسجيل مهمة كرفس خاصة تتم معالجتها بواسطة قائمة انتظار معينة. تتلقى هذه المهمة بعض الوسائط الأساسية كمدخلات ولغة المستخدم الحالية بحيث يتم إرسال البريد الإلكتروني باللغة التي يختارها المستخدم.
تخيل الآن أن لدينا العديد من هذه المهام ، لكن كل مهمة من هذه المهام تقبل وسيطة محلية. في هذه الحالة ، أليس من الأفضل حلها على مستوى أعلى من التجريد؟ هنا ، نرى فقط كيف نفعل ذلك.
وصف حالة الاستخدام: يرث النطاق تلقائيًا من سياق تنفيذ واحد ويحقنه في سياق التنفيذ الحالي كمعامل.
تفاصيل التنفيذ
مرة أخرى ، كما فعلنا مع تسجيل المهام ، نريد توسيع فئة مهمة أساسية celery.current_app.Task مهمة وتجاوز بعض الطرق المسؤولة عن استدعاء المهام. لغرض هذا العرض التوضيحي ، تجاوزت طريقة celery.current_app.Task::apply_async . هناك مهام إضافية لهذه الوحدة ستساعدك على إنتاج بديل يعمل بكامل طاقته.
الملف: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)المفتاح المفتاح هو تمرير اللغة الحالية كوسيطة قيمة مفتاح إلى مهمة استدعاء بشكل افتراضي. إذا تم استدعاء مهمة باستخدام إعدادات محلية معينة كوسيطة ، فلن يتم تغييرها.
تجربته
لاختبار هذه الوظيفة ، دعونا نحدد مهمة وهمية من النوع ScopeBasedTask . يحدد موقع ملف بواسطة معرف اللغة ويقرأ محتواه على أنه JSON:
الملف: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) الآن ما عليك القيام به هو تكرار خطوات تشغيل الكرفس ، وبدء الغلاف ، واختبار تنفيذ هذه المهمة في سيناريوهات مختلفة. تقع التركيبات تحت دليل celery_uncovered/tricks/fixtures/locales/ .
خاتمة
يهدف هذا المنشور إلى استكشاف الكرفس من وجهات نظر مختلفة. لقد عرضت الكرفس في أمثلة تقليدية مثل إرسال البريد وإنشاء التقارير بالإضافة إلى الحيل المشتركة لبعض حالات استخدام الأعمال المتخصصة المثيرة للاهتمام. الكرفس مبني على فلسفة قائمة على البيانات وقد يجعل فريقك حياتهم أكثر بساطة من خلال تقديمه كجزء من مكدس النظام الخاص بهم. إن تطوير الخدمات القائمة على الكرفس ليس معقدًا للغاية إذا كانت لديك خبرة أساسية في Python ، ويجب أن تكون قادرًا على الحصول عليها بسرعة إلى حد ما. التكوين الافتراضي جيد بما يكفي لمعظم الاستخدامات ، ولكن إذا لزم الأمر ، يمكن أن تكون مرنة للغاية.
قام فريقنا باختيار استخدام الكرفس كنهاية خلفية منسقة للوظائف في الخلفية والمهام طويلة المدى. نحن نستخدمه على نطاق واسع لمجموعة متنوعة من حالات الاستخدام ، والتي تم ذكر القليل منها فقط في هذا المنشور. نحن نستوعب ونحلل عددًا من الجيجابايت من البيانات كل يوم ، ولكن هذه ليست سوى بداية تقنيات القياس الأفقي.