
Orchestrieren eines Hintergrundjob-Workflows in Sellerie für Python
Veröffentlicht: 2022-03-11Moderne Webanwendungen und ihre zugrunde liegenden Systeme sind schneller und reaktionsschneller als je zuvor. Es gibt jedoch immer noch viele Fälle, in denen Sie die Ausführung einer schweren Aufgabe auf andere Teile Ihrer gesamten Systemarchitektur auslagern möchten, anstatt sie in Ihrem Hauptthread anzugehen. Das Identifizieren solcher Aufgaben ist so einfach wie das Überprüfen, ob sie zu einer der folgenden Kategorien gehören:
- Periodische Aufgaben – Jobs, die Sie planen, um zu einer bestimmten Zeit oder nach einem bestimmten Intervall ausgeführt zu werden, z. B. monatliche Berichterstellung oder ein Web Scraper, der zweimal täglich ausgeführt wird.
- Aufgaben von Drittanbietern – Die Web-App muss Benutzer schnell bedienen, ohne auf den Abschluss anderer Aktionen warten zu müssen, während die Seite geladen wird, z. B. das Senden einer E-Mail oder Benachrichtigung oder das Weitergeben von Aktualisierungen an interne Tools (z ).
- Jobs mit langer Laufzeit – Jobs mit hohen Ressourcenkosten, bei denen Benutzer warten müssen, während sie ihre Ergebnisse berechnen, z. B. komplexe Workflowausführung (DAG-Workflows), Diagrammerstellung, Map-Reduce-ähnliche Aufgaben und Bereitstellung von Audio).
Eine einfache Lösung zum Ausführen einer Hintergrundaufgabe wäre die Ausführung in einem separaten Thread oder Prozess. Python ist eine vollständige Turing-Programmiersprache auf hohem Niveau, die leider keine integrierte Parallelität in einem Umfang bietet, der mit dem von Erlang, Go, Java, Scala oder Akka übereinstimmt. Diese basieren auf Tony Hoares Communicating Sequential Processes (CSP). Python-Threads hingegen werden von der globalen Interpretersperre (GIL) koordiniert und geplant, die verhindert, dass mehrere native Threads Python-Bytecodes gleichzeitig ausführen. Die GIL loszuwerden ist ein Thema, das unter Python-Entwicklern viel diskutiert wird, aber es ist nicht der Schwerpunkt dieses Artikels. Gleichzeitiges Programmieren in Python ist altmodisch, obwohl Sie gerne im Python Multithreading Tutorial von Toptaler Marcus McCurdy darüber lesen können. Die konsistente Gestaltung der Kommunikation zwischen Prozessen ist also ein fehleranfälliger Prozess und führt zu Codekopplung und schlechter Wartbarkeit des Systems, ganz zu schweigen davon, dass dies die Skalierbarkeit negativ beeinflusst. Darüber hinaus ist der Python-Prozess ein normaler Prozess unter einem Betriebssystem (OS) und wird mit der gesamten Python-Standardbibliothek zu einem Schwergewicht. Mit zunehmender Anzahl von Prozessen in der App wird das Wechseln von einem solchen Prozess zu einem anderen zu einem zeitaufwändigen Vorgang.
Um die Parallelität mit Python besser zu verstehen, sehen Sie sich diese unglaubliche Rede von David Beazley auf der PyCon'15 an.
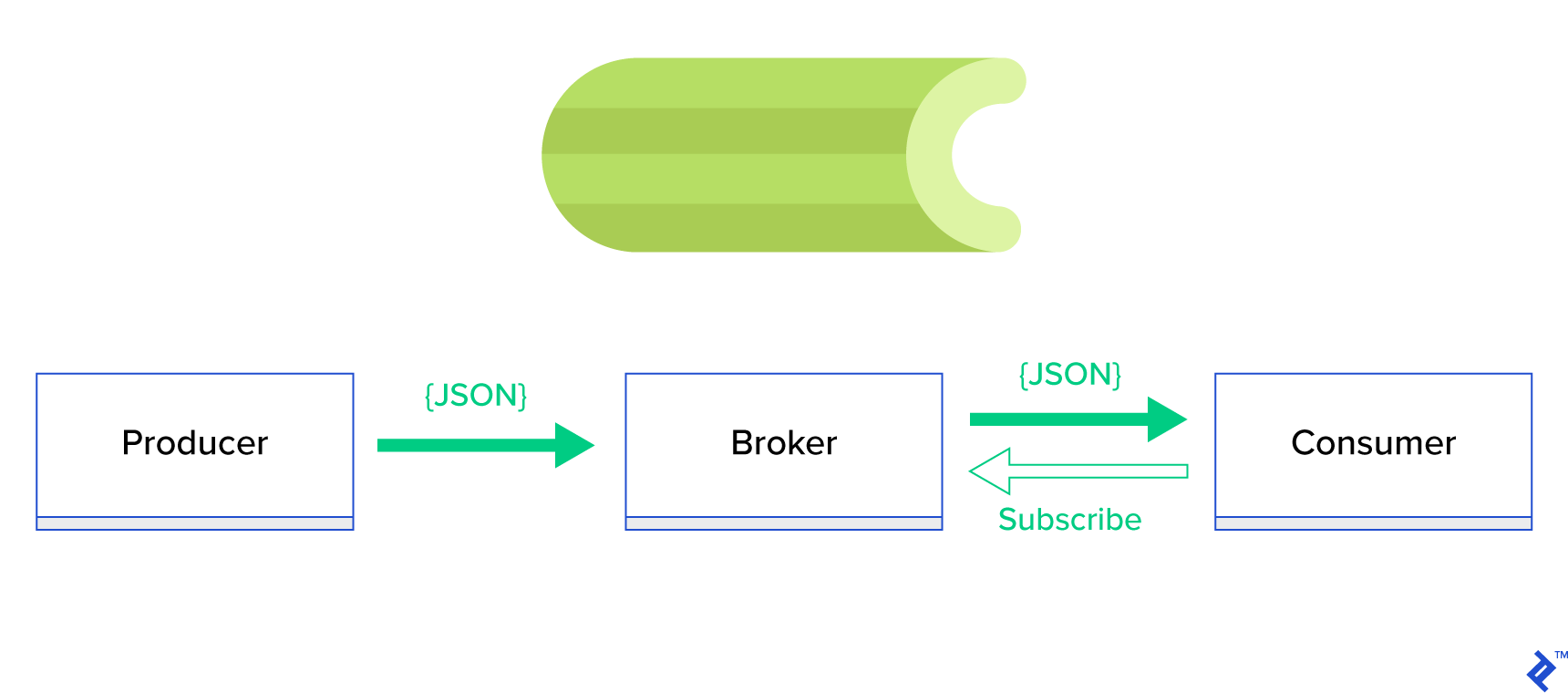
Eine viel bessere Lösung besteht darin, eine verteilte Warteschlange oder ihr bekanntes Geschwisterparadigma namens Publish-Subscribe zu bedienen. Wie in Abbildung 1 dargestellt, gibt es zwei Arten von Anwendungen, bei denen eine, die als Herausgeber bezeichnet wird, Nachrichten sendet und die andere, die als Abonnent bezeichnet wird, Nachrichten empfängt. Diese beiden Agenten interagieren nicht direkt miteinander und sind sich nicht einmal bewusst. Publisher senden Nachrichten an eine zentrale Warteschlange oder einen Broker , und Abonnenten erhalten interessante Nachrichten von diesem Broker. Es gibt zwei Hauptvorteile bei dieser Methode:
- Skalierbarkeit – Agenten müssen im Netzwerk nichts voneinander wissen. Sie sind thematisch fokussiert. Das bedeutet also, dass jeder unabhängig vom anderen in asynchroner Weise normal weiterarbeiten kann.
- Lose Kopplung – jeder Agent repräsentiert seinen Teil des Systems (Service, Modul). Da sie lose gekoppelt sind, können sie einzeln über das Rechenzentrum hinaus skaliert werden.
Es gibt viele Messaging-Systeme, die solche Paradigmen unterstützen und eine ordentliche API bereitstellen, die entweder von TCP- oder HTTP-Protokollen gesteuert wird, z. B. JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ usw.
Was ist Sellerie?
Sellerie ist einer der beliebtesten Hintergrund-Job-Manager in der Python-Welt. Sellerie ist mit mehreren Nachrichtenbrokern wie RabbitMQ oder Redis kompatibel und kann sowohl als Produzent als auch als Konsument fungieren.
Celery ist eine asynchrone Aufgabenwarteschlange/Auftragswarteschlange, die auf verteilter Nachrichtenweitergabe basiert. Es konzentriert sich auf Echtzeitoperationen, unterstützt aber auch die Zeitplanung. Die als Tasks bezeichneten Ausführungseinheiten werden gleichzeitig auf einem oder mehreren Worker-Servern unter Verwendung von Multiprocessing, Eventlet oder Gevent ausgeführt. Aufgaben können asynchron (im Hintergrund) oder synchron (warten bis fertig) ausgeführt werden. – Sellerie-Projekt
Um mit Sellerie zu beginnen, folgen Sie einfach einer Schritt-für-Schritt-Anleitung in den offiziellen Dokumenten.
Der Schwerpunkt dieses Artikels liegt darauf, Ihnen ein gutes Verständnis dafür zu vermitteln, welche Anwendungsfälle von Sellerie abgedeckt werden könnten. In diesem Artikel zeigen wir nicht nur interessante Beispiele, sondern versuchen auch zu lernen, wie man Celery auf reale Aufgaben wie Hintergrund-Mailing, Berichterstellung, Protokollierung und Fehlerberichterstattung anwendet. Ich werde meine Art und Weise teilen, die Aufgaben über die Emulation hinaus zu testen, und schließlich werde ich einige Tricks bereitstellen, die in der offiziellen Dokumentation nicht (gut) dokumentiert sind und für deren Entdeckung ich Stunden der Recherche benötigt habe.
Wenn Sie noch keine Erfahrung mit Sellerie haben, empfehle ich Ihnen, es zuerst nach dem offiziellen Tutorial auszuprobieren.
Appetit anregen
Wenn Sie dieser Artikel fasziniert und Sie sofort in den Code eintauchen möchten, folgen Sie diesem GitHub-Repository für den in diesem Artikel verwendeten Code. Die README -Datei dort gibt Ihnen den schnellen und schmutzigen Ansatz zum Ausführen und Spielen mit den Beispielanwendungen.
Erste Schritte mit Sellerie
Für den Anfang werden wir eine Reihe von praktischen Beispielen durchgehen, die einem Leser zeigen, wie einfach und elegant Celery scheinbar nicht triviale Aufgaben löst. Alle Beispiele werden innerhalb des Django-Frameworks präsentiert; Die meisten von ihnen könnten jedoch problemlos auf andere Python-Frameworks (Flask, Pyramid) portiert werden.
Das Projektlayout wurde von Cookiecutter Django generiert; Ich habe jedoch nur wenige Abhängigkeiten beibehalten, die meiner Meinung nach die Entwicklung und Vorbereitung dieser Anwendungsfälle erleichtern. Ich habe auch unnötige Module für diesen Beitrag und Anwendungen entfernt, um Rauschen zu reduzieren und den Code verständlicher zu machen.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}enthält verschiedene Anwendungen, die wir in diesem Beitrag behandeln werden. Jede Anwendung enthält eine Reihe von Beispielen, die nach dem erforderlichen Verständnis von Sellerie geordnet sind. -
celery_uncovered/celery.pydefiniert eine Celery-Instanz.
Datei: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Dann müssen wir sicherstellen, dass Celery zusammen mit Django startet. Aus diesem Grund importieren wir die App in celery_uncovered/__init__.py .
Datei: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings ist die Konfigurationsquelle für unsere App und Celery. Abhängig von der Ausführungsumgebung startet Django entsprechende Einstellungen: local.py für die Entwicklung oder test.py zum Testen. Sie können auch Ihre eigene Umgebung definieren, wenn Sie möchten, indem Sie ein neues Python-Modul erstellen (z. B. prod.py ). Selleriekonfigurationen haben das Präfix CELERY_ . Für diesen Beitrag habe ich RabbitMQ als Broker und SQLite als Ergebnis-Bac-End konfiguriert.
Datei: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Szenario 1 – Berichterstellung und -export
Der erste Fall, den wir behandeln werden, ist die Erstellung und der Export von Berichten. In diesem Beispiel erfahren Sie, wie Sie eine Aufgabe definieren, die einen CSV-Bericht erstellt, und ihn in regelmäßigen Abständen mit celerybeat planen.
Beschreibung des Anwendungsfalls: Rufen Sie die fünfhundert heißesten Repositories von GitHub pro ausgewähltem Zeitraum (Tag, Woche, Monat) ab, gruppieren Sie sie nach Themen und exportieren Sie das Ergebnis in die CSV-Datei.
Wenn wir einen HTTP-Dienst bereitstellen, der diese Funktion ausführt, ausgelöst durch Klicken auf eine Schaltfläche mit der Bezeichnung „Bericht erstellen“, würde die Anwendung anhalten und warten, bis die Aufgabe abgeschlossen ist, bevor sie eine HTTP-Antwort zurücksendet. Das ist schlecht. Wir möchten, dass unsere Webanwendung schnell ist und wir möchten nicht, dass unsere Benutzer warten, während unser Back-End die Ergebnisse berechnet. Anstatt darauf zu warten, dass die Ergebnisse produziert werden, würden wir die Aufgabe lieber über eine registrierte Warteschlange in Celery in Worker-Prozesse einreihen und mit einer task_id an das Front-End antworten. Dann würde das Front-End die task_id verwenden, um das Task-Ergebnis asynchron abzufragen (z. B. AJAX) und den Benutzer über den Task-Fortschritt auf dem Laufenden halten. Wenn der Prozess abgeschlossen ist, können die Ergebnisse schließlich als Datei zum Herunterladen über HTTP bereitgestellt werden.
Implementierungsdetails
Lassen Sie uns zunächst den Prozess in seine kleinstmöglichen Einheiten zerlegen und eine Pipeline erstellen:
- Abrufer sind die Worker, die dafür verantwortlich sind, Repositories vom GitHub-Dienst abzurufen.
- Der Aggregator ist der Worker, der für die Konsolidierung der Ergebnisse in einer Liste verantwortlich ist.
- Der Importer ist der Arbeiter, der CSV-Berichte der heißesten Repositories in GitHub erstellt.
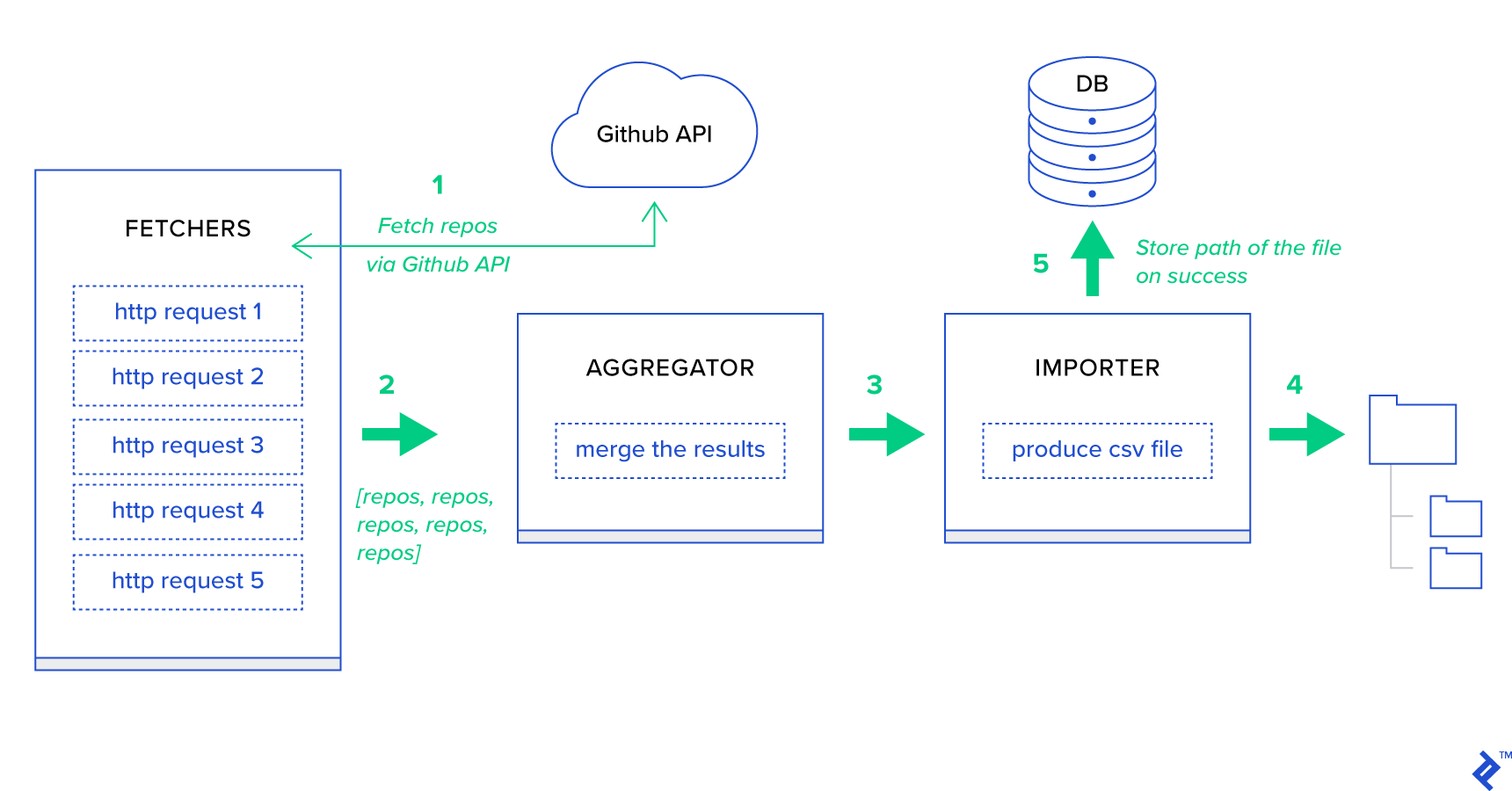
Das Abrufen von Repositories ist eine HTTP-Anforderung mit der GitHub-Such-API GET /search/repositories . Es gibt jedoch eine Einschränkung des GitHub-API-Dienstes, die behandelt werden sollte: Die API gibt bis zu 100 Repositories pro Anfrage statt 500 zurück. Wir könnten fünf Anfragen nacheinander senden, aber wir wollen unseren Benutzer nicht warten lassen für fünf einzelne Anforderungen, da HTTP-Anforderungen eine E/A-gebundene Operation sind. Stattdessen können wir fünf gleichzeitige HTTP-Anforderungen mit einem geeigneten Seitenparameter ausführen. Die Seite liegt also im Bereich [1..5]. Lassen Sie uns eine Aufgabe namens fetch_hot_repos/3 -> list im Modul toyex/tasks.py :
Datei: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items fetch_hot_repos erstellt also eine Anfrage an die GitHub-API und antwortet dem Benutzer mit einer Liste von Repositories. Es erhält drei Parameter, die unsere Anforderungsnutzlast definieren:
-
since— Filtert Repositories nach dem Erstellungsdatum. -
per_page— Anzahl der pro Anfrage zurückzugebenden Ergebnisse (begrenzt auf 100). -
page—- Angeforderte Seitennummer (im Bereich [1..5]).
Hinweis: Um die GitHub-Such-API zu verwenden, benötigen Sie ein OAuth-Token, um Authentifizierungsprüfungen zu bestehen. In unserem Fall wird es in den Einstellungen unter GITHUB_OAUTH .
Als Nächstes müssen wir eine Master-Aufgabe definieren, die für das Aggregieren der Ergebnisse und deren Export in eine CSV-Datei verantwortlich ist: produce_hot_repo_report_task/2->filepath:
Datei: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Diese Aufgabe verwendet celery.canvas.group , um fünf gleichzeitige Aufrufe von fetch_hot_repos/3 auszuführen. Auf diese Ergebnisse wird gewartet und dann auf eine Liste von Repository-Objekten reduziert. Dann wird unser Ergebnissatz nach Themen gruppiert und schließlich in eine generierte CSV-Datei im MEDIA_ROOT/ exportiert.
Um die Aufgabe regelmäßig zu planen, möchten Sie möglicherweise einen Eintrag zur Zeitplanliste in der Konfigurationsdatei hinzufügen:
Datei: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Ausprobieren
Um zu starten und zu testen, wie die Aufgabe funktioniert, müssen wir zuerst den Celery-Prozess starten:
$ celery -A celery_uncovered worker -l info Als nächstes müssen wir das celery_uncovered/media/ erstellen. Anschließend können Sie die Funktionalität entweder über Shell oder Celerybeat testen:
Schale :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Sellerieschlag :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Sie können die Ergebnisse im MEDIA_ROOT/ .
Szenario 2 – Bericht über Server 500 -Fehler per E-Mail
Einer der häufigsten Anwendungsfälle für Sellerie ist das Versenden von E-Mail-Benachrichtigungen. Die E-Mail-Benachrichtigung ist ein Offline-E/A-gebundener Vorgang, der entweder einen lokalen SMTP-Server oder einen SES eines Drittanbieters nutzt. Es gibt viele Anwendungsfälle, bei denen eine E-Mail gesendet wird, und bei den meisten muss der Benutzer nicht warten, bis dieser Vorgang abgeschlossen ist, bevor er eine HTTP-Antwort erhält. Deshalb wird es bevorzugt, solche Aufgaben im Hintergrund auszuführen und dem Benutzer sofort zu antworten.
Beschreibung des Anwendungsfalls: Melden Sie 50X-Fehler per Celery an die Administrator-E-Mail.
Python und Django verfügen über den erforderlichen Hintergrund, um Systemprotokolle durchzuführen. Ich werde nicht näher darauf eingehen, wie Pythons Protokollierung tatsächlich funktioniert. Wenn Sie es jedoch noch nie zuvor ausprobiert haben oder eine Auffrischung benötigen, lesen Sie die Dokumentation des integrierten Protokollierungsmoduls. Sie möchten dies auf jeden Fall in Ihrer Produktionsumgebung. Django verfügt über einen speziellen Logger-Handler namens AdminEmailHandler, der Administratoren für jede empfangene Protokollnachricht eine E-Mail sendet.
Implementierungsdetails
Die Hauptidee besteht darin, die Methode AdminEmailHandler der Klasse send_mail so zu erweitern, dass sie E-Mails über Celery versenden kann. Dies könnte wie in der folgenden Abbildung dargestellt geschehen:
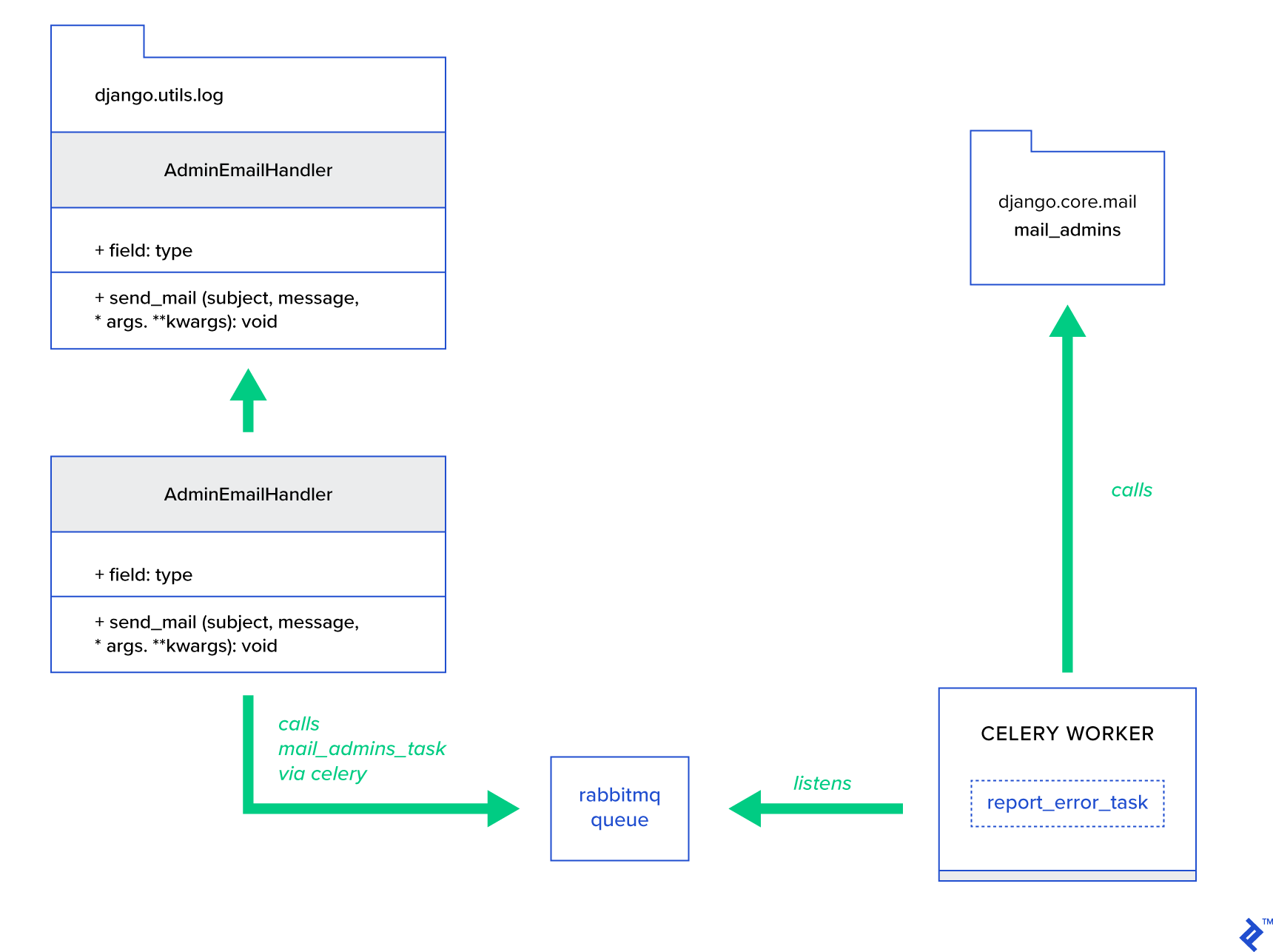
Zuerst müssen wir eine Aufgabe namens report_error_task , die mail_admins mit dem bereitgestellten Betreff und der bereitgestellten Nachricht aufruft:
Datei: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Als nächstes erweitern wir AdminEmailHandler tatsächlich so, dass er intern nur die definierte Celery-Aufgabe aufruft:
Datei: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Schließlich müssen wir die Protokollierung einrichten. Die Konfiguration der Protokollierung in Django ist ziemlich einfach. Sie müssen LOGGING überschreiben, damit die Protokollierungs-Engine mit einem neu definierten Handler startet:
Datei config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Beachten Sie, dass ich absichtlich Handlerfilter require_debug_true eingerichtet habe, um diese Funktionalität zu testen, während die Anwendung im Debugmodus ausgeführt wird.
Ausprobieren
Um es zu testen, habe ich eine Django-Ansicht vorbereitet, die eine „Division-durch-Null“-Operation unter localhost:8000/report-error bedient. Sie müssen auch einen MailHog-Docker-Container starten, um zu testen, ob die E-Mail tatsächlich gesendet wird.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Zusätzliche Details
Als E-Mail-Testtool habe ich MailHog eingerichtet und Django-Mailing so konfiguriert, dass es für die SMTP-Zustellung verwendet wird. Es gibt viele Möglichkeiten, MailHog bereitzustellen und auszuführen. Ich habe mich für einen Docker-Container entschieden. Die Details finden Sie in der entsprechenden README-Datei:
Datei: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Um Ihre Anwendung für die Verwendung von MailHog zu konfigurieren, müssen Sie Ihrer Konfiguration die folgenden Zeilen hinzufügen:
Datei: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Über Standard-Sellerie-Aufgaben hinaus
Sellerieaufgaben können aus jeder aufrufbaren Funktion erstellt werden. Standardmäßig wird jede benutzerdefinierte Aufgabe mit celery.app.task.Task als übergeordnete (abstrakte) Klasse injiziert. Diese Klasse enthält die Funktionalität, Aufgaben asynchron (über das Netzwerk an einen Celery-Worker weiterzuleiten) oder synchron (zu Testzwecken) auszuführen, Signaturen zu erstellen und viele andere Dienstprogramme. In den nächsten Beispielen werden wir versuchen, Celery.app.task.Task zu erweitern und sie dann als Basisklasse zu verwenden, um unseren Aufgaben einige nützliche Verhaltensweisen hinzuzufügen.
Szenario 3 – Dateiprotokollierung pro Task
In einem meiner Projekte habe ich eine App entwickelt, die dem Endbenutzer ein Extrahieren, Transformieren, Laden (ETL)-ähnliches Tool zur Verfügung stellt, das in der Lage ist, eine riesige Menge hierarchischer Daten aufzunehmen und dann zu filtern. Das Backend wurde in zwei Module aufgeteilt:
- Orchestrierung einer Datenverarbeitungspipeline mit Celery
- Datenverarbeitung mit Go
Celery wurde mit einer Celerybeat-Instanz und mehr als 40 Workern bereitgestellt. Es gab mehr als zwanzig verschiedene Aufgaben, aus denen sich die Pipeline- und Orchestrierungsaktivitäten zusammensetzten. Jede dieser Aufgaben kann irgendwann fehlschlagen. All diese Fehler wurden in das Systemprotokoll jedes Workers geschrieben. Irgendwann wurde es unpraktisch, den Celery-Layer zu debuggen und zu warten. Schließlich entschieden wir uns, das Aufgabenprotokoll in einer aufgabenspezifischen Datei zu isolieren.
Beschreibung des Anwendungsfalls: Erweitern Sie Celery so, dass jede Aufgabe ihre Standardausgabe und Fehler in Dateien protokolliert
Celery bietet Python-Anwendungen eine große Kontrolle darüber, was es intern tut. Es wird mit einem vertrauten Signalrahmen ausgeliefert. Anwendungen, die Celery verwenden, können einige davon abonnieren, um das Verhalten bestimmter Aktionen zu verbessern. Wir werden Signale auf Aufgabenebene nutzen, um eine ausführliche Verfolgung der Lebenszyklen einzelner Aufgaben bereitzustellen. Sellerie wird immer mit einem Protokollierungs-Backend geliefert, und wir werden davon profitieren, während wir nur an einigen Stellen leicht überschreiben, um unsere Ziele zu erreichen.
Implementierungsdetails
Sellerie unterstützt bereits die Protokollierung pro Aufgabe. Zum Speichern in einer Datei ist es erforderlich, die Protokollausgabe an den richtigen Speicherort zu senden. In unserem Fall ist der richtige Speicherort der Aufgabe eine Datei, die dem Namen der Aufgabe entspricht. Auf der Celery-Instanz überschreiben wir die integrierte Logging-Konfiguration mit dynamisch abgeleiteten Logging-Handlern. Es ist möglich, das Signal celeryd_after_setup zu abonnieren und dort dann die Systemprotokollierung zu konfigurieren:
Datei: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Beachten Sie, dass wir für jede in der Sellerie-App registrierte Aufgabe einen entsprechenden Logger mit seinem Handler erstellen. Jeder Handler ist vom Typ logging.FileHandler , und daher erhält jede solche Instanz einen Dateinamen als Eingabe. Alles, was Sie brauchen, um dies zum Laufen zu bringen, ist, dieses Modul in celery_uncovered/celery.py am Ende der Datei zu importieren:
import celery_uncovered.tricks.celery_conf Ein bestimmter Task-Logger kann durch Aufrufen von get_task_logger(task_name) werden. Um ein solches Verhalten für jede Aufgabe zu verallgemeinern, ist es notwendig, celery.current_app.Task mit einigen Hilfsmethoden leicht zu erweitern:
Datei: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Nun wird bei einem Aufruf von task.log_msg("Hello, my name is: %s", task.request.id) die Log-Ausgabe in die entsprechende Datei unter dem Task-Namen geroutet.
Ausprobieren
Um zu starten und zu testen, wie diese Aufgabe funktioniert, starten Sie zuerst den Celery-Prozess:
$ celery -A celery_uncovered worker -l infoDann können Sie die Funktionalität über die Shell testen:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Um das Ergebnis anzuzeigen, navigieren Sie schließlich zum celery_uncovered/logs und öffnen Sie die entsprechende Protokolldatei mit dem Namen celery_uncovered.tricks.tasks.add.log . Möglicherweise sehen Sie etwas Ähnliches wie unten, nachdem Sie diese Aufgabe mehrmals ausgeführt haben:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Szenario 4 – Bereichsbezogene Aufgaben
Stellen wir uns eine Python-Anwendung für internationale Benutzer vor, die auf Celery und Django aufbaut. Die Benutzer können festlegen, in welcher Sprache (Gebietsschema) sie Ihre Anwendung verwenden.
Sie müssen ein mehrsprachiges, länderspezifisches E-Mail-Benachrichtigungssystem entwerfen. Um E-Mail-Benachrichtigungen zu senden, haben Sie eine spezielle Celery-Aufgabe registriert, die von einer bestimmten Warteschlange verarbeitet wird. Diese Aufgabe erhält einige Schlüsselargumente als Eingabe und ein aktuelles Benutzergebietsschema, sodass E-Mails in der vom Benutzer ausgewählten Sprache gesendet werden.
Stellen Sie sich nun vor, dass wir viele solcher Aufgaben haben, aber jede dieser Aufgaben akzeptiert ein Locale-Argument. Wäre es in diesem Fall nicht besser, es auf einer höheren Abstraktionsebene zu lösen? Hier sehen wir, wie das geht.
Beschreibung des Anwendungsfalls: Umfang automatisch von einem Ausführungskontext erben und als Parameter in den aktuellen Ausführungskontext einfügen.
Implementierungsdetails
Auch hier wollen wir, wie bei der Aufgabenprotokollierung, eine celery.current_app.Task und einige Methoden überschreiben, die für das Aufrufen von Aufgaben verantwortlich sind. Für diese Demonstration überschreibe ich die Methode celery.current_app.Task::apply_async . Es gibt zusätzliche Aufgaben für dieses Modul, die Ihnen helfen, einen voll funktionsfähigen Ersatz herzustellen.
Datei: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)Der Schlüsselhinweis besteht darin, das aktuelle Gebietsschema standardmäßig als Schlüsselwertargument an eine aufrufende Aufgabe zu übergeben. Wenn eine Aufgabe mit einem bestimmten Gebietsschema als Argument aufgerufen wurde, bleibt es unverändert.
Ausprobieren
Um diese Funktionalität zu testen, definieren wir eine Dummy-Aufgabe vom Typ ScopeBasedTask . Es findet eine Datei anhand der Gebietsschema-ID und liest ihren Inhalt als JSON:
Datei: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Jetzt müssen Sie die Schritte zum Starten von Celery, zum Starten der Shell und zum Testen der Ausführung dieser Aufgabe in verschiedenen Szenarien wiederholen. Fixtures befinden sich im celery_uncovered/tricks/fixtures/locales/ .
Fazit
Dieser Beitrag zielte darauf ab, Sellerie aus verschiedenen Perspektiven zu erkunden. Ich habe Sellerie in konventionellen Beispielen wie Mailing und Berichterstellung demonstriert und Tricks für einige interessante Anwendungsfälle in Nischengeschäften vorgestellt. Celery basiert auf einer datengesteuerten Philosophie und Ihr Team kann sich das Leben viel einfacher machen, indem es es als Teil seines System-Stacks einführt. Die Entwicklung von Celery-basierten Diensten ist nicht sehr kompliziert, wenn Sie über grundlegende Python-Erfahrung verfügen, und Sie sollten in der Lage sein, diese ziemlich schnell zu erlernen. Die Standardkonfiguration ist für die meisten Anwendungen gut genug, aber bei Bedarf können sie sehr flexibel sein.
Unser Team hat sich entschieden, Celery als Orchestrierungs-Back-End für Hintergrundjobs und lang andauernde Aufgaben zu verwenden. Wir verwenden es ausgiebig für eine Vielzahl von Anwendungsfällen, von denen in diesem Beitrag nur einige erwähnt wurden. Wir erfassen und analysieren täglich Gigabyte an Daten, aber dies ist nur der Anfang von horizontalen Skalierungstechniken.