
Orchestrare un flusso di lavoro in background in Celery per Python
Pubblicato: 2022-03-11Le moderne applicazioni Web e i relativi sistemi sottostanti sono più veloci e reattivi che mai. Tuttavia, ci sono ancora molti casi in cui si desidera scaricare l'esecuzione di un'attività pesante su altre parti dell'intera architettura del sistema invece di affrontarle sul thread principale. Identificare tali attività è semplice come verificare se appartengono a una delle seguenti categorie:
- Attività periodiche: attività pianificate per l'esecuzione a un'ora specifica o dopo un intervallo, ad esempio la generazione di report mensili o un web scraper che viene eseguito due volte al giorno.
- Attività di terze parti: l'app Web deve servire rapidamente gli utenti senza attendere il completamento di altre azioni durante il caricamento della pagina, ad esempio l'invio di un'e-mail o una notifica o la propagazione di aggiornamenti a strumenti interni (come la raccolta di dati per i test A/B o la registrazione del sistema ).
- Lavori di lunga durata — Lavori che sono costosi in termini di risorse, in cui gli utenti devono attendere mentre calcolano i loro risultati, ad esempio, esecuzione di flussi di lavoro complessi (flussi di lavoro DAG), generazione di grafici, attività simili a Map-Reduce e pubblicazione di contenuti multimediali (video, Audio).
Una soluzione semplice per eseguire un'attività in background sarebbe eseguirla all'interno di un thread o processo separato. Python è un linguaggio di programmazione completo Turing di alto livello, che sfortunatamente non fornisce concorrenza integrata su una scala corrispondente a quella di Erlang, Go, Java, Scala o Akka. Questi sono basati sui processi di comunicazione sequenziali (CSP) di Tony Hoare. I thread Python, d'altra parte, sono coordinati e programmati dal blocco dell'interprete globale (GIL), che impedisce a più thread nativi di eseguire bytecode Python contemporaneamente. Sbarazzarsi del GIL è un argomento di molte discussioni tra gli sviluppatori Python, ma non è il fulcro di questo articolo. La programmazione simultanea in Python è antiquata, anche se puoi leggerla in Python Multithreading Tutorial del collega Toptaler Marcus McCurdy. Quindi, progettare la comunicazione tra processi in modo coerente è un processo soggetto a errori e porta all'accoppiamento del codice e a una cattiva manutenibilità del sistema, per non parlare del fatto che influisce negativamente sulla scalabilità. Inoltre, il processo Python è un processo normale in un sistema operativo (OS) e, con l'intera libreria standard Python, diventa un peso massimo. Con l'aumento del numero di processi nell'app, il passaggio da uno di questi processi all'altro diventa un'operazione che richiede tempo.
Per comprendere meglio la concorrenza con Python, guarda questo incredibile discorso di David Beazley al PyCon'15.
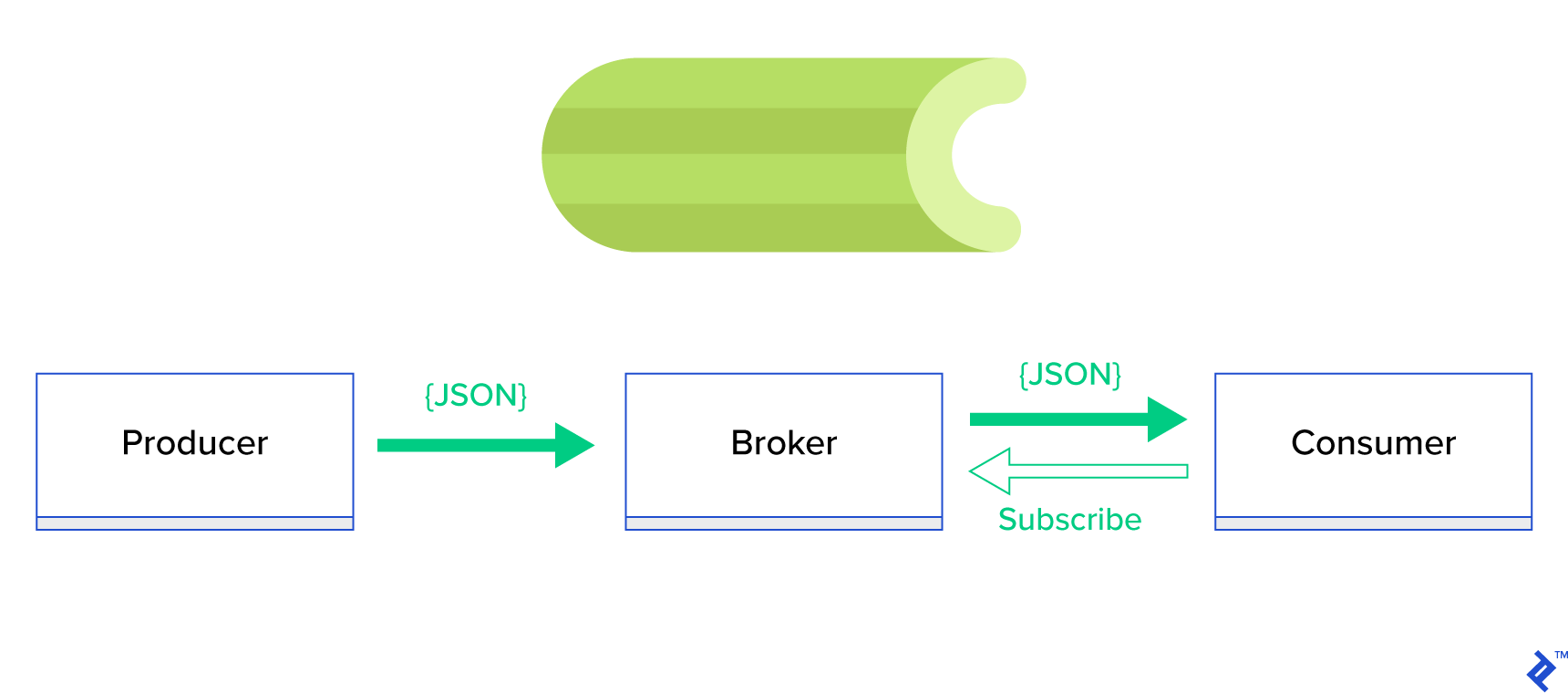
Una soluzione molto migliore consiste nel servire una coda distribuita o il suo noto paradigma di pari livello chiamato publish-subscribe . Come illustrato nella Figura 1, esistono due tipi di applicazioni in cui una, denominata editore , invia messaggi e l'altra, denominata abbonato , riceve messaggi. Quei due agenti non interagiscono direttamente tra loro e non sono nemmeno consapevoli l'uno dell'altro. Gli editori inviano messaggi a una coda centrale o broker e gli abbonati ricevono messaggi di interesse da questo broker. Ci sono due vantaggi principali in questo metodo:
- Scalabilità: gli agenti non hanno bisogno di conoscersi nella rete. Sono focalizzati per argomento. Quindi significa che ciascuno può continuare a funzionare normalmente indipendentemente dall'altro in modo asincrono.
- Accoppiamento sciolto: ogni agente rappresenta la sua parte del sistema (servizio, modulo). Poiché sono accoppiati in modo lasco, ciascuno può scalare individualmente oltre il data center.
Esistono molti sistemi di messaggistica che supportano tali paradigmi e forniscono un'API ordinata, guidata da protocolli TCP o HTTP, ad esempio JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ, ecc.
Cos'è il sedano?
Celery è uno dei gestori di lavori in background più popolari nel mondo Python. Celery è compatibile con diversi broker di messaggi come RabbitMQ o Redis e può fungere sia da produttore che da consumatore.
Celery è una coda di attività/coda di lavoro asincrona basata sul passaggio di messaggi distribuito. Si concentra sulle operazioni in tempo reale ma supporta anche la pianificazione. Le unità di esecuzione, denominate attività, vengono eseguite contemporaneamente su uno o più server di lavoro utilizzando multiprocessing, Eventlet o gevent. Le attività possono essere eseguite in modo asincrono (in background) o in modo sincrono (attendere fino a quando non sono pronte). – Progetto sedano
Per iniziare con Celery, basta seguire una guida passo passo nei documenti ufficiali.
L'obiettivo di questo articolo è darti una buona comprensione di quali casi d'uso potrebbero essere coperti da Celery. In questo articolo, non mostreremo solo esempi interessanti, ma cercheremo anche di imparare come applicare Celery ad attività del mondo reale come l'invio di posta in background, la generazione di report, la registrazione e la segnalazione di errori. Condividerò il mio modo di testare i compiti oltre l'emulazione e, infine, fornirò alcuni trucchi che non sono (ben) documentati nella documentazione ufficiale che mi hanno richiesto ore di ricerca per scoprire da solo.
Se non hai precedenti esperienze con Celery, ti consiglio di provarlo prima seguendo il tutorial ufficiale.
Stuzzicare l'appetito
Se questo articolo ti incuriosisce e ti fa venire voglia di immergerti immediatamente nel codice, segui questo repository GitHub per il codice utilizzato in questo articolo. Il file README lì ti darà l'approccio rapido e sporco per eseguire e giocare con le applicazioni di esempio.
Primi passi con il sedano
Per cominciare, illustreremo una serie di esempi pratici che mostreranno al lettore come in modo semplice ed elegante Celery risolva compiti apparentemente non banali. Tutti gli esempi saranno presentati all'interno del framework Django; tuttavia, la maggior parte di essi potrebbe essere facilmente trasferita su altri framework Python (Flask, Pyramid).
Il layout del progetto è stato generato da Cookiecutter Django; tuttavia, ho mantenuto solo alcune dipendenze che, a mio avviso, facilitano lo sviluppo e la preparazione di questi casi d'uso. Ho anche rimosso i moduli non necessari per questo post e le applicazioni per ridurre il rumore e rendere il codice più facile da capire.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}contiene diverse applicazioni che tratteremo in questo post. Ogni applicazione contiene una serie di esempi organizzati in base al livello di comprensione del sedano richiesto. -
celery_uncovered/celery.pydefinisce un'istanza di Celery.
File: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Quindi dobbiamo assicurarci che Celery inizi insieme a Django. Per questo motivo, importiamo l'app in celery_uncovered/__init__.py .
File: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings è la fonte di configurazione per la nostra app e Celery. A seconda dell'ambiente di esecuzione, Django avvierà le impostazioni corrispondenti: local.py per lo sviluppo o test.py per il test. Puoi anche definire il tuo ambiente, se lo desideri, creando un nuovo modulo python (ad esempio, prod.py ). Le configurazioni del sedano sono precedute da CELERY_ . Per questo post, ho configurato RabbitMQ come broker e SQLite come risultato bac-end.
File: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Scenario 1 - Generazione ed esportazione di report
Il primo caso che tratteremo è la generazione e l'esportazione di report. In questo esempio imparerai come definire un'attività che produca un report CSV e programmarlo a intervalli regolari con celerybeat.
Descrizione del caso d'uso: recupera i cinquecento repository più importanti da GitHub per il periodo prescelto (giorno, settimana, mese), raggruppali per argomenti ed esporta il risultato nel file CSV.
Se forniamo un servizio HTTP che eseguirà questa funzione attivata facendo clic su un pulsante con l'etichetta "Genera rapporto", l'applicazione si fermerà e attenderà il completamento dell'attività prima di inviare una risposta HTTP. Questo non va bene. Vogliamo che la nostra applicazione web sia veloce e non vogliamo che i nostri utenti aspettino mentre il nostro back-end calcola i risultati. Invece di attendere la produzione dei risultati, preferiremmo mettere in coda l'attività ai processi di lavoro tramite una coda registrata in Celery e rispondere con un task_id al front-end. Quindi il front-end utilizzerà task_id per interrogare il risultato dell'attività in modo asincrono (ad esempio, AJAX) e manterrà l'utente aggiornato con l'avanzamento dell'attività. Infine, al termine del processo, i risultati possono essere serviti come file da scaricare tramite HTTP.
Dettagli di implementazione
Prima di tutto, scomponiamo il processo nelle sue unità più piccole possibili e creiamo una pipeline:
- I Fetcher sono i lavoratori responsabili dell'ottenimento dei repository dal servizio GitHub.
- L' aggregatore è il lavoratore responsabile del consolidamento dei risultati in un unico elenco.
- L' importatore è il lavoratore che sta producendo report CSV dei repository più importanti in GitHub.
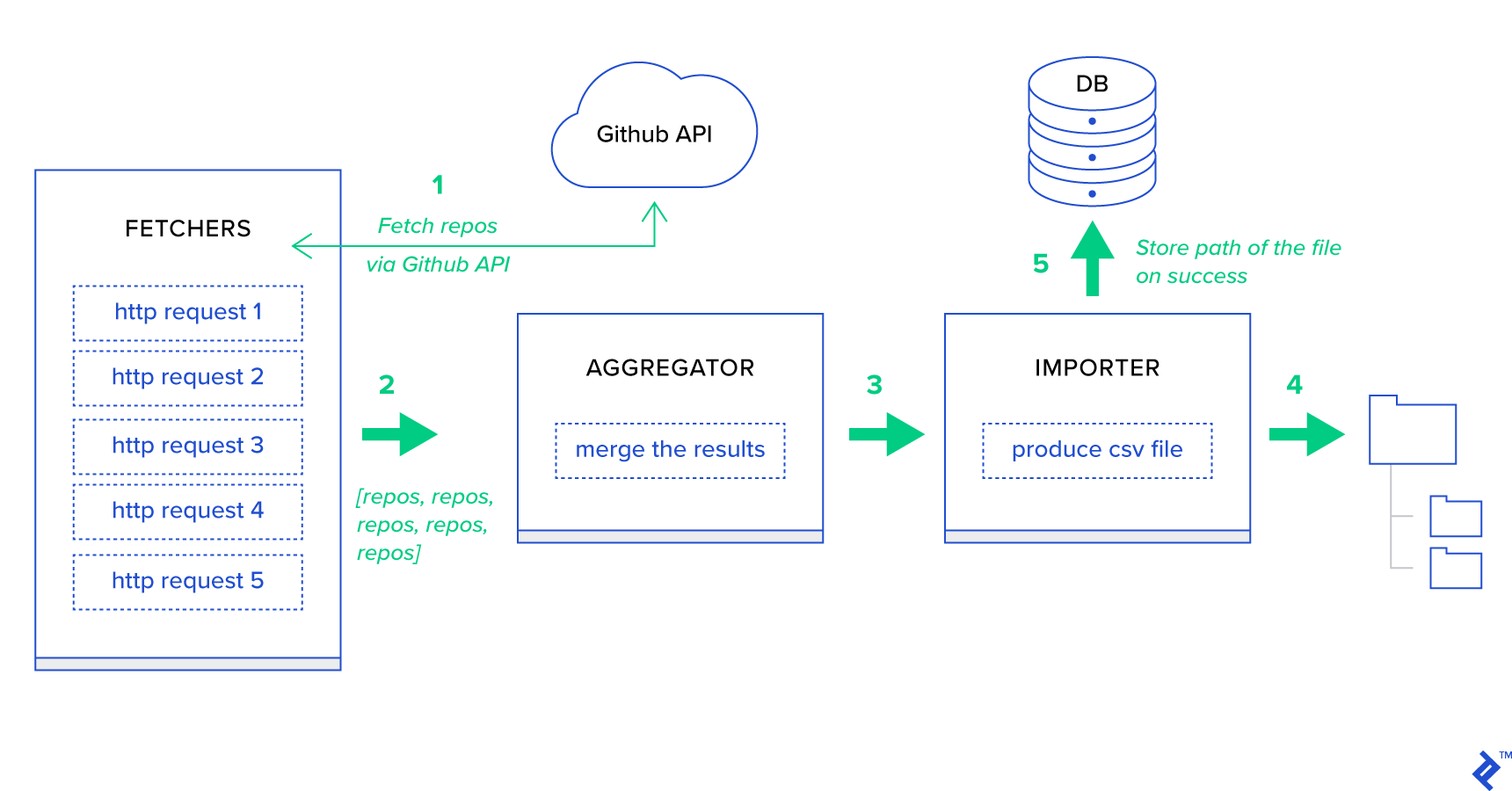
Il recupero dei repository è una richiesta HTTP che utilizza l'API di ricerca GitHub GET /search/repositories . Tuttavia, esiste una limitazione del servizio API GitHub che dovrebbe essere gestito: l'API restituisce fino a 100 repository per richiesta invece di 500. Potremmo inviare cinque richieste una alla volta, ma non vogliamo far aspettare il nostro utente per cinque richieste individuali poiché le richieste HTTP sono un'operazione legata all'I/O. Invece, possiamo eseguire cinque richieste HTTP simultanee con un parametro di pagina appropriato. Quindi la pagina sarà nell'intervallo [1..5]. Definiamo un'attività chiamata fetch_hot_repos/3 -> list nel modulo toyex/tasks.py :
File: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Quindi fetch_hot_repos crea una richiesta all'API GitHub e risponde all'utente con un elenco di repository. Riceve tre parametri che definiranno il payload della nostra richiesta:
-
since— Filtra i repository alla data di creazione. -
per_page— Numero di risultati da restituire per richiesta (limitato a 100). -
page—- Numero di pagina richiesto (nell'intervallo [1..5]).
Nota: per utilizzare l'API di ricerca GitHub, avrai bisogno di un token OAuth per superare i controlli di autenticazione. Nel nostro caso, viene salvato nelle impostazioni in GITHUB_OAUTH .
Successivamente, dobbiamo definire un'attività principale che sarà responsabile dell'aggregazione dei risultati e dell'esportazione in un file CSV: produce_hot_repo_report_task/2->filepath:
File: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Questa attività utilizza celery.canvas.group per eseguire cinque chiamate simultanee di fetch_hot_repos/3 . Questi risultati vengono attesi e quindi ridotti a un elenco di oggetti del repository. Quindi il nostro set di risultati viene raggruppato per argomento e infine esportato in un file CSV generato nella directory MEDIA_ROOT/ .
Per pianificare periodicamente l'attività, potresti voler aggiungere una voce all'elenco di pianificazione nel file di configurazione:
File: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Provarlo
Per avviare e testare il funzionamento dell'attività, è necessario prima avviare il processo Celery:
$ celery -A celery_uncovered worker -l info Successivamente, dobbiamo creare la celery_uncovered/media/ . Quindi, sarai in grado di testarne la funzionalità tramite Shell o Celerybeat:
Conchiglia :

from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Battito di sedano :
# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Puoi guardare i risultati nella directory MEDIA_ROOT/ .
Scenario 2 - Segnala errori del server 500 tramite e-mail
Uno dei casi d'uso più comuni per Celery è l'invio di notifiche e-mail. La notifica e-mail è un'operazione legata all'I/O offline che sfrutta un server SMTP locale o un SES di terze parti. Esistono molti casi d'uso che implicano l'invio di un'e-mail e, per la maggior parte di essi, l'utente non deve attendere il termine di questo processo prima di ricevere una risposta HTTP. Ecco perché è preferibile eseguire tali attività in background e rispondere immediatamente all'utente.
Descrizione del caso d'uso: segnala 50 volte gli errori all'e-mail dell'amministratore tramite Celery.
Python e Django hanno il background necessario per eseguire la registrazione del sistema. Non entrerò nei dettagli di come funziona effettivamente la registrazione di Python. Tuttavia, se non l'hai mai provato prima o hai bisogno di un aggiornamento, leggi la documentazione del modulo di registrazione integrato. Lo vuoi sicuramente nel tuo ambiente di produzione. Django ha uno speciale gestore di logger chiamato AdminEmailHandler che invia e-mail agli amministratori per ogni messaggio di registro che riceve.
Dettagli di implementazione
L'idea principale è estendere il metodo send_mail della classe AdminEmailHandler in modo tale che possa inviare posta tramite Celery. Questo potrebbe essere fatto come illustrato nella figura seguente:
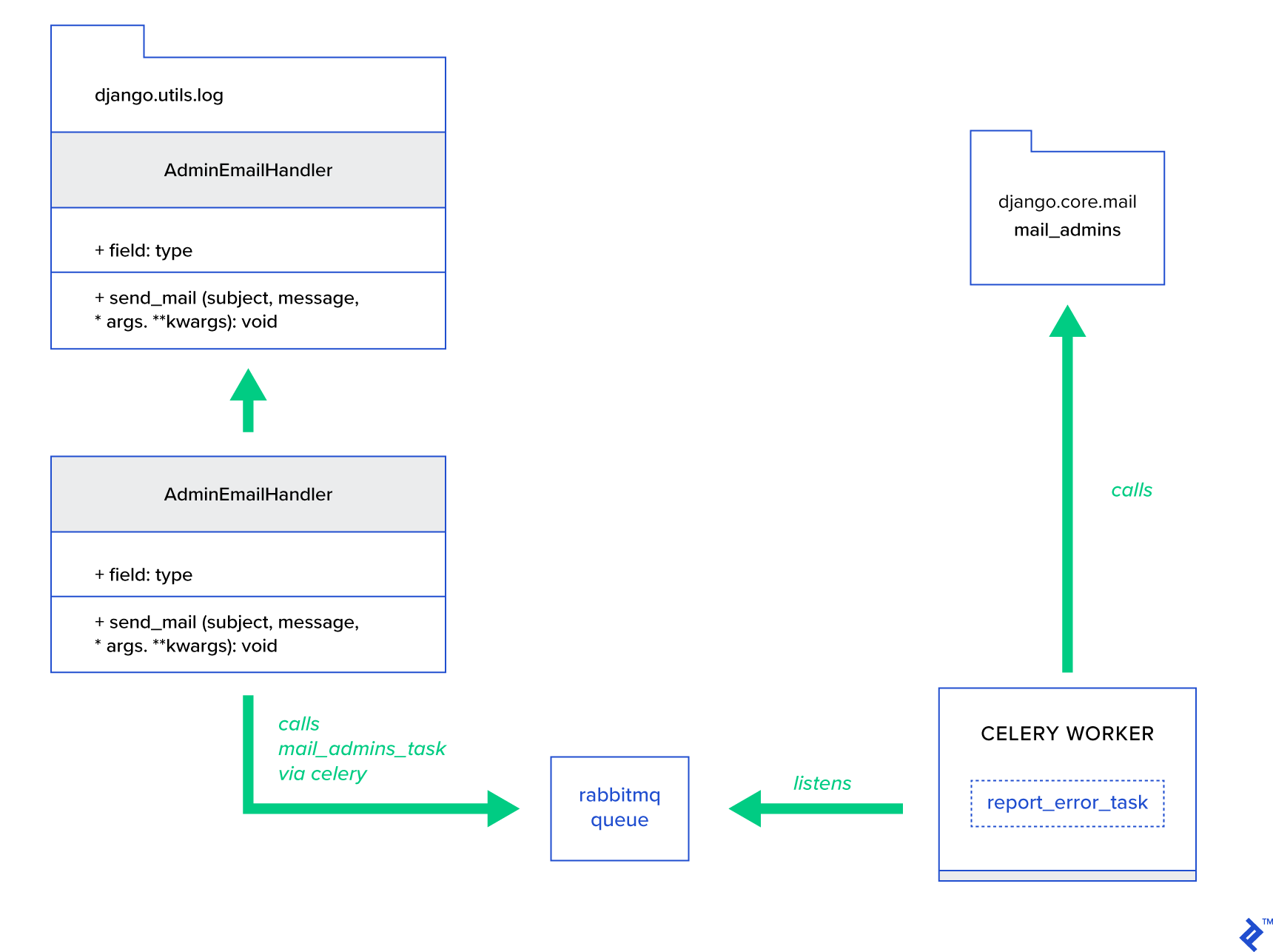
Innanzitutto, dobbiamo impostare un'attività chiamata report_error_task che chiama mail_admins con l'oggetto e il messaggio forniti:
File: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Successivamente, estendiamo effettivamente AdminEmailHandler in modo che chiami internamente solo l'attività Celery definita:
File: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Infine, dobbiamo impostare la registrazione. La configurazione dell'accesso a Django è abbastanza semplice. Ciò di cui hai bisogno è sovrascrivere LOGGING in modo che il motore di registrazione inizi a utilizzare un gestore appena definito:
File config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Si noti che ho impostato intenzionalmente i filtri del gestore require_debug_true per testare questa funzionalità mentre l'applicazione è in esecuzione in modalità di debug.
Provarlo
Per testarlo, ho preparato una vista Django che serve un'operazione di "divisione per zero" su localhost:8000/report-error . Devi anche avviare un contenitore MailHog Docker per verificare che l'e-mail sia effettivamente inviata.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Dettagli extra
Come strumento di test della posta, ho configurato MailHog e configurato Django mailing per usarlo per la consegna SMTP. Esistono molti modi per distribuire ed eseguire MailHog. Ho deciso di utilizzare un container Docker. Puoi trovare i dettagli nel file README corrispondente:
File: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Per configurare la tua applicazione per utilizzare MailHog, devi aggiungere le seguenti righe nella tua configurazione:
File: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Oltre le attività di sedano predefinite
Le attività di sedano possono essere create da qualsiasi funzione richiamabile. Per impostazione predefinita, qualsiasi attività definita dall'utente viene iniettata con celery.app.task.Task come classe padre (astratta). Questa classe contiene la funzionalità di eseguire attività in modo asincrono (passandolo tramite la rete a un lavoratore Celery) o in modo sincrono (a scopo di test), creando firme e molte altre utilità. Nei prossimi esempi, cercheremo di estendere Celery.app.task.Task e quindi usarlo come classe base per aggiungere alcuni comportamenti utili alle nostre attività.
Scenario 3 - Registrazione file per attività
In uno dei miei progetti, stavo sviluppando un'app che fornisce all'utente finale uno strumento simile a Extract, Transform, Load (ETL) in grado di ingerire e quindi filtrare un'enorme quantità di dati gerarchici. Il back-end è stato suddiviso in due moduli:
- Orchestrazione di una pipeline di elaborazione dati con Celery
- Elaborazione dati con Go
Celery è stato distribuito con un'istanza Celerybeat e più di 40 dipendenti. C'erano più di venti attività diverse che componevano la pipeline e le attività di orchestrazione. Ciascuna di queste attività potrebbe fallire a un certo punto. Tutti questi errori sono stati scaricati nel registro di sistema di ogni lavoratore. Ad un certo punto, ha iniziato a diventare scomodo eseguire il debug e mantenere il livello Celery. Alla fine, abbiamo deciso di isolare il registro delle attività in un file specifico dell'attività.
Descrizione del caso d'uso: estendere Celery in modo che ogni attività registri l'output standard e gli errori nei file
Celery fornisce alle applicazioni Python un grande controllo su ciò che fa internamente. Viene fornito con un framework di segnali familiare. Le applicazioni che utilizzano Celery possono iscriversi ad alcune di esse per aumentare il comportamento di determinate azioni. Sfrutteremo i segnali a livello di attività per fornire un monitoraggio dettagliato dei cicli di vita delle singole attività. Il sedano viene sempre fornito con un back-end di registrazione e ne trarremo vantaggio, sovrascrivendo solo leggermente in alcuni punti i nostri obiettivi.
Dettagli di implementazione
Celery supporta già la registrazione per attività. Per salvare in un file, è necessario inviare l'output del registro nella posizione corretta. Nel nostro caso, la posizione corretta dell'attività è un file che corrisponde al nome dell'attività. Nell'istanza di Celery, sovrascriveremo la configurazione di registrazione incorporata con gestori di registrazione dedotti dinamicamente. È possibile iscriversi al segnale celeryd_after_setup e quindi configurare la registrazione del sistema lì:
File: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Si noti che per ogni attività registrata nell'app Celery, stiamo creando un logger corrispondente con il relativo gestore. Ogni gestore è del tipo logging.FileHandler e quindi ciascuna di queste istanze riceve un nome file come input. Tutto ciò che serve per farlo funzionare è importare questo modulo in celery_uncovered/celery.py alla fine del file:
import celery_uncovered.tricks.celery_conf È possibile ricevere un determinato task logger chiamando get_task_logger(task_name) . Per generalizzare tale comportamento per ogni attività, è necessario estendere leggermente celery.current_app.Task con alcuni metodi di utilità:
File: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Ora, nel caso di una chiamata a task.log_msg("Hello, my name is: %s", task.request.id) , l'output del log verrà instradato al file corrispondente sotto il nome dell'attività.
Provarlo
Per avviare e testare il funzionamento di questa attività, avviare prima il processo Celery:
$ celery -A celery_uncovered worker -l infoQuindi sarai in grado di testare la funzionalità tramite Shell:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Infine, per vedere il risultato, vai alla directory celery_uncovered/logs e apri il file di registro corrispondente chiamato celery_uncovered.tricks.tasks.add.log . Potresti vedere qualcosa di simile come di seguito dopo aver eseguito questa attività più volte:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Scenario 4 - Attività sensibili all'ambito
Immaginiamo un'applicazione Python per utenti internazionali basata su Celery e Django. Gli utenti possono impostare la lingua (locale) in cui usano la tua applicazione.
È necessario progettare un sistema di notifica e-mail multilingue e compatibile con le impostazioni locali. Per inviare notifiche e-mail, hai registrato un'attività Sedano speciale gestita da una coda specifica. Questa attività riceve alcuni argomenti chiave come input e una locale utente corrente in modo che l'e-mail venga inviata nella lingua scelta dall'utente.
Ora immagina di avere molti di questi compiti, ma ognuno di questi compiti accetta un argomento locale. In questo caso, non sarebbe meglio risolverlo a un livello di astrazione più elevato? Qui, vediamo come farlo.
Descrizione del caso d'uso: eredita automaticamente l'ambito da un contesto di esecuzione e lo inserisce nel contesto di esecuzione corrente come parametro.
Dettagli di implementazione
Ancora una volta, come abbiamo fatto con la registrazione delle attività, vogliamo estendere una classe di attività di base celery.current_app.Task e sovrascrivere alcuni metodi responsabili della chiamata delle attività. Ai fini di questa dimostrazione, sto sovrascrivendo il metodo celery.current_app.Task::apply_async . Ci sono attività extra per questo modulo che ti aiuteranno a produrre un sostituto completamente funzionante.
File: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)L'indizio chiave è passare la locale corrente come argomento valore-chiave in un'attività chiamante per impostazione predefinita. Se un'attività è stata chiamata con una determinata locale come argomento, non viene modificata.
Provarlo
Per testare questa funzionalità, definiamo un'attività fittizia di tipo ScopeBasedTask . Individua un file in base all'ID locale e ne legge il contenuto come JSON:
File: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Ora quello che devi fare è ripetere i passaggi per avviare Celery, avviare la shell e testare l'esecuzione di questa attività in diversi scenari. Le Fixtures si trovano nella celery_uncovered/tricks/fixtures/locales/ .
Conclusione
Questo post mirava a esplorare il sedano da diverse prospettive. Ho dimostrato Celery in esempi convenzionali come mailing e generazione di report, nonché trucchi condivisi per alcuni casi d'uso aziendali di nicchia interessanti. Celery si basa su una filosofia basata sui dati e il tuo team potrebbe semplificarsi la vita introducendolo come parte dello stack di sistema. Lo sviluppo di servizi basati su Celery non è molto complicato se hai un'esperienza di base con Python e dovresti essere in grado di raccoglierla abbastanza rapidamente. La configurazione predefinita è abbastanza buona per la maggior parte degli usi, ma se necessario, possono essere molto flessibili.
Il nostro team ha scelto di utilizzare Celery come back-end di orchestrazione per lavori in background e attività di lunga durata. Lo usiamo ampiamente per una varietà di casi d'uso, di cui solo alcuni sono stati menzionati in questo post. Acquisiamo e analizziamo gigabyte di dati ogni giorno, ma questo è solo l'inizio delle tecniche di ridimensionamento orizzontale.