
Python用Celeryでのバックグラウンドジョブワークフローの調整
公開: 2022-03-11最新のWebアプリケーションとその基盤となるシステムは、これまでになく高速で応答性が高くなっています。 ただし、メインスレッドでそれらに取り組むのではなく、システムアーキテクチャ全体の他の部分に重いタスクの実行をオフロードしたい場合がまだ多くあります。 このようなタスクの識別は、それらが次のカテゴリのいずれかに属しているかどうかを確認するのと同じくらい簡単です。
- 定期的なタスク—特定の時間または間隔の後に実行するようにスケジュールするジョブ。たとえば、月次レポートの生成や1日2回実行されるWebスクレイパー。
- サードパーティのタスク— Webアプリは、ページの読み込み中に他のアクションが完了するのを待たずに、ユーザーに迅速にサービスを提供する必要があります。たとえば、メールや通知の送信、内部ツールへの更新の伝達(A / Bテストやシステムロギングのためのデータの収集など) )。
- 長時間実行されるジョブ—リソースが高価なジョブで、ユーザーが結果を計算するまで待つ必要があります。たとえば、複雑なワークフローの実行(DAGワークフロー)、グラフの生成、Map-Reduceのようなタスク、メディアコンテンツの提供(ビデオ、オーディオ)。
バックグラウンドタスクを実行する簡単なソリューションは、別のスレッドまたはプロセス内でタスクを実行することです。 Pythonは高レベルのチューリング完全プログラミング言語であり、残念ながら、Erlang、Go、Java、Scala、またはAkkaに匹敵する規模の組み込みの同時実行性を提供していません。 これらは、TonyHoareのCommunicatingSequential Processes(CSP)に基づいています。 一方、Pythonスレッドは、グローバルインタープリターロック(GIL)によって調整およびスケジュールされます。これにより、複数のネイティブスレッドがPythonバイトコードを一度に実行できなくなります。 GILを取り除くことは、Python開発者の間で多くの議論のトピックですが、この記事の焦点ではありません。 Pythonでの並行プログラミングは古風ですが、ToptalerMarcusMcCurdyによるPythonマルチスレッドチュートリアルでそれについて読むことを歓迎します。 したがって、プロセス間の通信を一貫して設計することはエラーが発生しやすいプロセスであり、スケーラビリティに悪影響を与えることは言うまでもなく、コードの結合とシステムの保守性の低下につながります。 さらに、Pythonプロセスはオペレーティングシステム(OS)での通常のプロセスであり、Python標準ライブラリ全体を使用すると非常に重要になります。 アプリ内のプロセスの数が増えると、そのようなプロセスから別のプロセスへの切り替えは時間のかかる操作になります。
Pythonとの並行性をよりよく理解するには、PyCon'15でのDavidBeazleyによるこの素晴らしいスピーチをご覧ください。
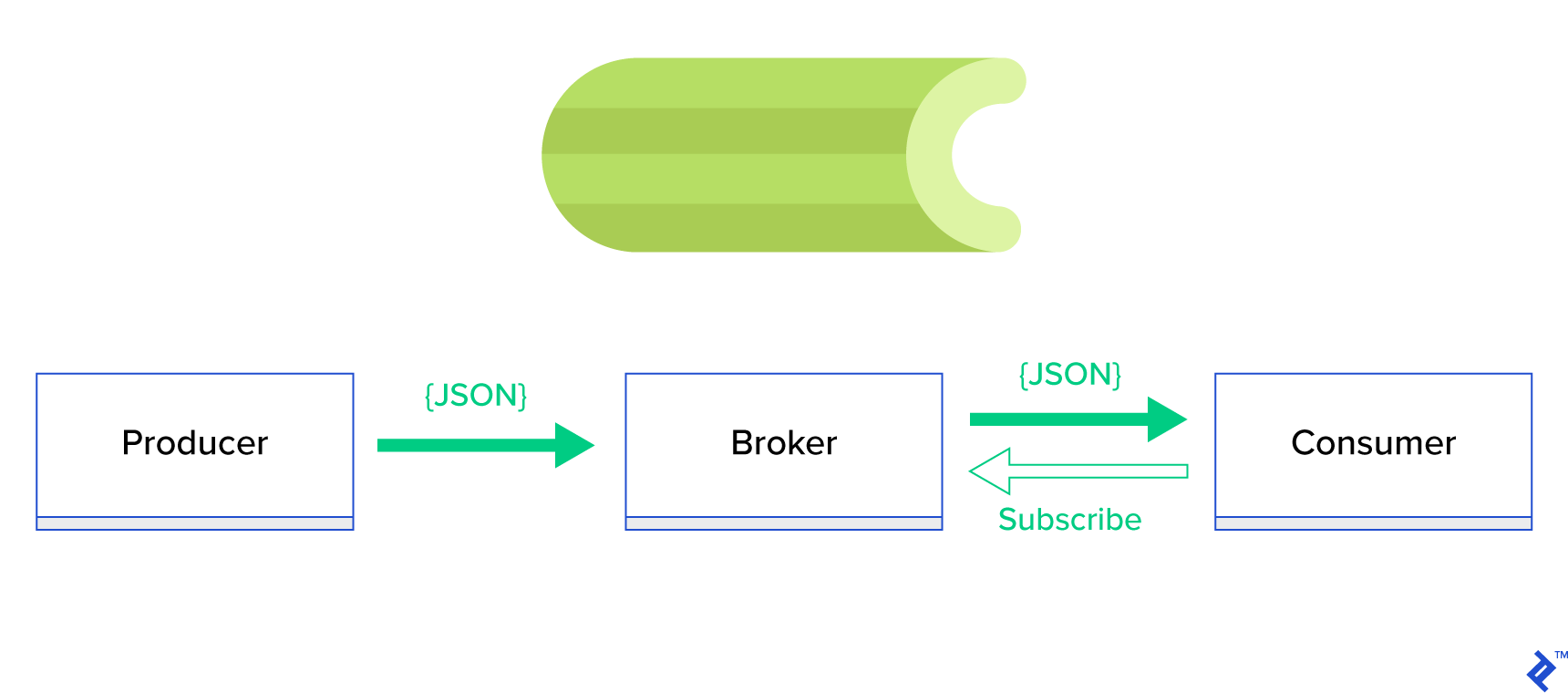
はるかに優れたソリューションは、分散キューまたはそのよく知られた兄弟パラダイムであるpublish-subscribeを提供することです。 図1に示すように、アプリケーションには2つのタイプがあり、1つはパブリッシャーと呼ばれ、メッセージを送信し、もう1つはサブスクライバーと呼ばれ、メッセージを受信します。 これらの2つのエージェントは互いに直接相互作用せず、互いに気づいていません。 パブリッシャーは中央キューまたはブローカーにメッセージを送信し、サブスクライバーはこのブローカーから関心のあるメッセージを受信します。 この方法には2つの主な利点があります。
- スケーラビリティ—エージェントはネットワーク内でお互いについて知る必要はありません。 それらはトピックによって焦点を合わせられます。 つまり、それぞれが非同期的に他方に関係なく正常に動作し続けることができるということです。
- 緩い結合—各エージェントはシステムのその部分(サービス、モジュール)を表します。 それらは緩く結合されているため、それぞれがデータセンターを超えて個別に拡張できます。
このようなパラダイムをサポートし、TCPまたはHTTPプロトコルのいずれかによって駆動されるきちんとしたAPIを提供するメッセージングシステムがたくさんあります。たとえば、JMS、RabbitMQ、Redis Pub / Sub、ApacheActiveMQなどです。
セロリとは?
Celeryは、Pythonの世界で最も人気のあるバックグラウンドジョブマネージャーの1人です。 Celeryは、RabbitMQやRedisなどのいくつかのメッセージブローカーと互換性があり、プロデューサーとコンシューマーの両方として機能できます。
Celeryは、分散メッセージパッシングに基づく非同期タスクキュー/ジョブキューです。 リアルタイム操作に重点を置いていますが、スケジューリングもサポートしています。 タスクと呼ばれる実行ユニットは、マルチプロセッシング、Eventlet、またはgeventを使用して1つ以上のワーカーサーバーで同時に実行されます。 タスクは、非同期(バックグラウンドで)または同期(準備ができるまで待機)で実行できます。 –セロリプロジェクト
Celeryの使用を開始するには、公式ドキュメントのステップバイステップガイドに従ってください。
この記事の焦点は、Celeryがカバーできるユースケースをよく理解することです。 この記事では、興味深い例を示すだけでなく、バックグラウンドメーリング、レポート生成、ロギング、エラーレポートなどの実際のタスクにCeleryを適用する方法を学びます。 エミュレーションを超えてタスクをテストする方法を共有し、最後に、公式ドキュメントに(十分に)文書化されていないいくつかのトリックを提供します。
Celeryの使用経験がない場合は、最初に公式チュートリアルに従って試してみることをお勧めします。
食欲をそそる
この記事に興味をそそられ、すぐにコードに飛び込みたいと思う場合は、この記事で使用されているコードについて、このGitHubリポジトリをフォローしてください。 そこにあるREADMEファイルは、サンプルアプリケーションを実行および操作するための迅速で汚いアプローチを提供します。
セロリの最初のステップ
手始めに、Celeryが一見重要なタスクをいかにシンプルかつエレガントに解決するかを読者に示す一連の実用的な例を見ていきます。 すべての例はDjangoフレームワーク内に表示されます。 ただし、それらのほとんどは、他のPythonフレームワーク(Flask、Pyramid)に簡単に移植できます。
プロジェクトのレイアウトはCookiecutterDjangoによって生成されました。 ただし、私の意見では、これらのユースケースの開発と準備を容易にするいくつかの依存関係のみを保持しました。 また、ノイズを減らし、コードを理解しやすくするために、この投稿とアプリケーションに不要なモジュールを削除しました。
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}には、この投稿で取り上げるさまざまなアプリケーションが含まれています。 各アプリケーションには、必要なCeleryの理解レベル別に整理された一連の例が含まれています。 -
celery_uncovered/celery.pyは、Celeryインスタンスを定義します。
ファイル: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() 次に、CeleryがDjangoと一緒に起動することを確認する必要があります。 そのため、アプリをcelery_uncovered/__init__.pyにインポートします。
ファイル: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settingsは、アプリとCeleryの構成のソースです。 実行環境に応じて、Djangoは対応する設定を起動します:開発用のlocal.pyまたはテスト用のtest.py 必要に応じて、新しいpythonモジュール( prod.py )を作成して、独自の環境を定義することもできます。 セロリ構成の接頭辞はCELERY_です。 この投稿では、RabbitMQをブローカーとして構成し、SQLiteを結果のbac-endとして構成しました。
ファイル: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'シナリオ1-レポートの生成とエクスポート
最初に取り上げるのは、レポートの生成とエクスポートです。 この例では、CSVレポートを生成するタスクを定義し、celerybeatを使用して定期的にスケジュールする方法を学習します。
ユースケースの説明:選択した期間(日、週、月)ごとにGitHubから500の最もホットなリポジトリをフェッチし、トピックごとにグループ化して、結果をCSVファイルにエクスポートします。
「レポートの生成」というラベルの付いたボタンをクリックしてトリガーされるこの機能を実行するHTTPサービスを提供する場合、アプリケーションは停止し、タスクが完了するのを待ってからHTTP応答を送り返します。 これは悪いです。 Webアプリケーションを高速にし、バックエンドが結果を計算する間、ユーザーを待たせたくありません。 結果が生成されるのを待つ代わりに、Celeryに登録されたキューを介してワーカープロセスにタスクをキューに入れ、フロントエンドにtask_idで応答します。 次に、フロントエンドはtask_idを使用して非同期方式(AJAXなど)でタスク結果を照会し、ユーザーにタスクの進行状況を最新の状態に保ちます。 最後に、プロセスが終了すると、結果をファイルとして提供し、HTTP経由でダウンロードできます。
実装の詳細
まず、プロセスを可能な限り最小の単位に分解し、パイプラインを作成しましょう。
- Fetchersは、GitHubサービスからリポジトリを取得する責任があるワーカーです。
- アグリゲーターは、結果を1つのリストに統合する責任があるワーカーです。
- インポーターは、GitHubで最もホットなリポジトリのCSVレポートを作成しているワーカーです。
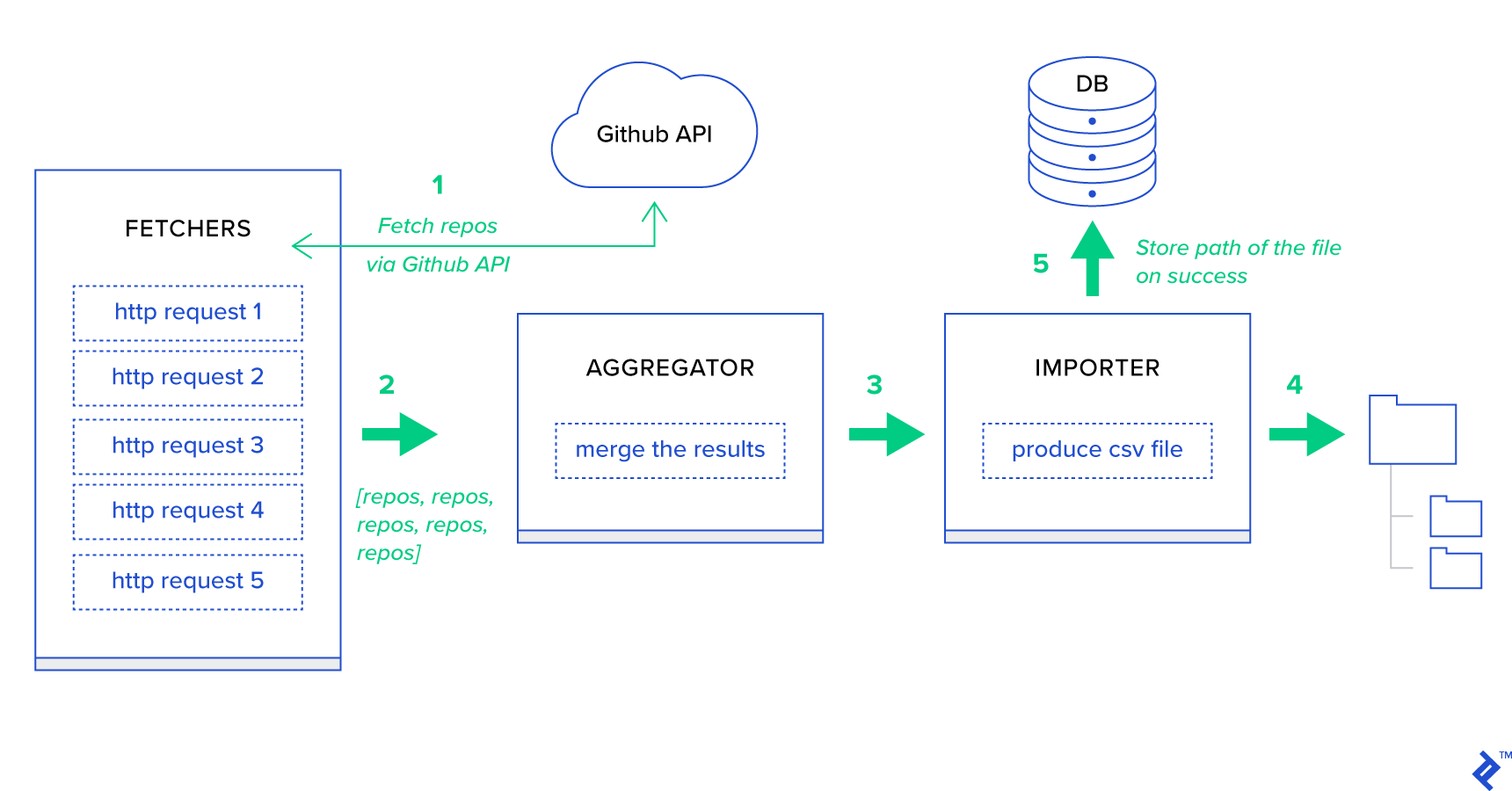
リポジトリの取得は、GitHub Search API GET /search/repositoriesを使用したHTTPリクエストです。 ただし、処理する必要のあるGitHub APIサービスには制限があります。APIはリクエストごとに500ではなく最大100のリポジトリを返します。一度に5つのリクエストを送信できますが、ユーザーを待たせたくありません。 HTTPリクエストはI/Oバウンド操作であるため、5つの個別のリクエストに対して。 代わりに、適切なページパラメータを使用して5つの同時HTTPリクエストを実行できます。 したがって、ページは[1..5]の範囲になります。 toyex/tasks.py fetch_hot_repos/3 -> listというタスクを定義しましょう。
ファイル: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items そのため、 fetch_hot_reposはGitHub APIへのリクエストを作成し、リポジトリのリストでユーザーに応答します。 リクエストペイロードを定義する3つのパラメータを受け取ります。
-
since—作成日にリポジトリをフィルタリングします。 -
per_page—リクエストごとに返す結果の数(100に制限)。 -
page-要求されたページ番号([1..5]の範囲内)。
注: GitHub Search APIを使用するには、認証チェックに合格するためのOAuthトークンが必要です。 この場合、 GITHUB_OAUTHの下の設定に保存されます。
次に、結果を集約してCSVファイルにエクスポートするマスタータスクを定義する必要がありますproduce_hot_repo_report_task/2->filepath:
ファイル: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) このタスクは、 celery.canvas.groupを使用して、 fetch_hot_repos/3の5つの同時呼び出しを実行します。 これらの結果は待機されてから、リポジトリオブジェクトのリストにまとめられます。 次に、結果セットがトピックごとにグループ化され、最終的にMEDIA_ROOT/ディレクトリの下に生成されたCSVファイルにエクスポートされます。
タスクを定期的にスケジュールするために、構成ファイルのスケジュールリストにエントリを追加することをお勧めします。
ファイル: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }試してみる
タスクがどのように機能しているかを起動してテストするには、最初にCeleryプロセスを開始する必要があります。
$ celery -A celery_uncovered worker -l info 次に、 celery_uncovered/media/ディレクトリを作成する必要があります。 次に、ShellまたはCelerybeatのいずれかを介してその機能をテストできるようになります。
シェル:
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)セレリービート:
# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info 結果は、 MEDIA_ROOT/ディレクトリで確認できます。
シナリオ2-電子メールによるサーバー500エラーのレポート
Celeryの最も一般的な使用例の1つは、電子メール通知の送信です。 電子メール通知は、ローカルSMTPサーバーまたはサードパーティのSESのいずれかを利用するオフラインI/Oバウンド操作です。 電子メールの送信を伴う多くのユースケースがあり、それらのほとんどの場合、ユーザーはHTTP応答を受信する前にこのプロセスが終了するまで待つ必要はありません。 そのため、このようなタスクをバックグラウンドで実行し、ユーザーにすぐに応答することが推奨されます。

ユースケースの説明: Celeryを介して管理者の電子メールに50Xエラーを報告します。
PythonとDjangoには、システムロギングを実行するために必要なバックグラウンドがあります。 Pythonのロギングが実際にどのように機能するかについては詳しく説明しません。 ただし、これまでに試したことがない場合や、復習が必要な場合は、組み込みのロギングモジュールのドキュメントをお読みください。 実稼働環境では間違いなくこれが必要です。 DjangoにはAdminEmailHandlerと呼ばれる特別なロガーハンドラーがあり、受信したログメッセージごとに管理者にメールを送信します。
実装の詳細
主なアイデアは、 AdminEmailHandlerクラスのsend_mailメソッドを拡張して、Celery経由でメールを送信できるようにすることです。 これは、次の図に示すように実行できます。
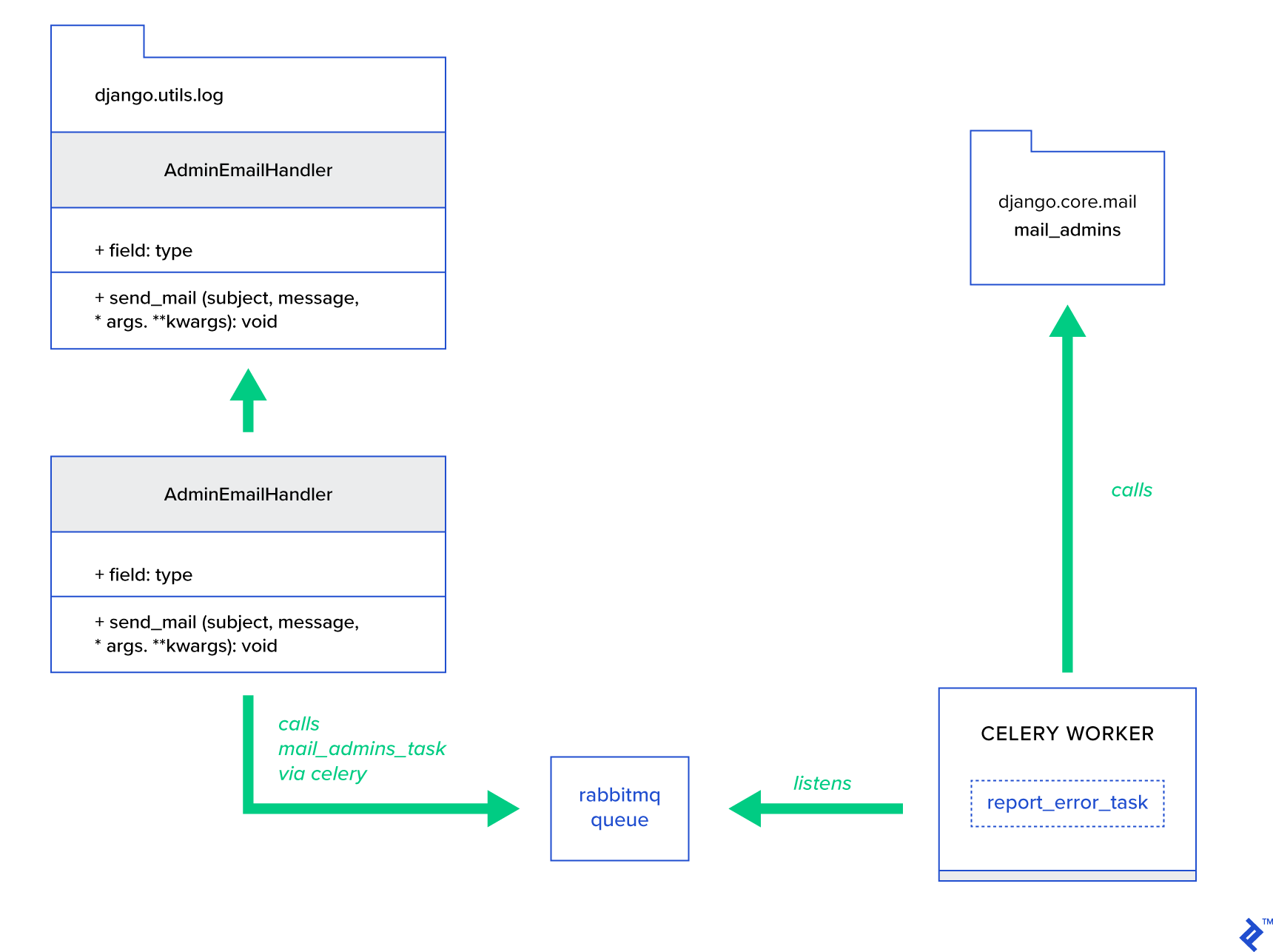
まず、提供された件名とメッセージを使用してreport_error_taskを呼び出すmail_adminsというタスクを設定する必要があります。
ファイル: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)次に、実際にAdminEmailHandlerを拡張して、定義されたCeleryタスクのみを内部的に呼び出すようにします。
ファイル: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) 最後に、ロギングを設定する必要があります。 Djangoでのロギングの設定はかなり簡単です。 必要なのは、 LOGGINGをオーバーライドして、ロギングエンジンが新しく定義されたハンドラーの使用を開始するようにすることです。
ファイルconfig/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } アプリケーションがデバッグモードで実行されているときにこの機能をテストするために、ハンドラーフィルターrequire_debug_trueを意図的に設定していることに注意してください。
試してみる
それをテストするために、 localhost:8000/report-errorで「ゼロ除算」操作を提供するDjangoビューを準備しました。 また、メールが実際に送信されることをテストするには、MailHogDockerコンテナを起動する必要があります。
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)追加の詳細
メールテストツールとして、MailHogをセットアップし、SMTP配信に使用するようにDjangoメーリングを構成しました。 MailHogをデプロイして実行する方法はたくさんあります。 Dockerコンテナーを使用することにしました。 詳細は、対応するREADMEファイルに記載されています。
ファイル: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025MailHogを使用するようにアプリケーションを構成するには、構成に次の行を追加する必要があります。
ファイル: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')デフォルトのセロリタスクを超えて
セロリタスクは、呼び出し可能な関数から作成できます。 デフォルトでは、ユーザー定義のタスクには、親(抽象)クラスとしてcelery.app.task.Taskが注入されます。 このクラスには、タスクを非同期(ネットワーク経由でCeleryワーカーに渡す)または同期(テスト目的)で実行し、署名や他の多くのユーティリティを作成する機能が含まれています。 次の例では、 Celery.app.task.Taskを拡張し、それを基本クラスとして使用して、タスクにいくつかの便利な動作を追加します。
シナリオ3-タスクごとのファイルログ
私のプロジェクトの1つでは、大量の階層データを取り込んでフィルタリングできる、抽出、変換、読み込み(ETL)のようなツールをエンドユーザーに提供するアプリを開発していました。 バックエンドは2つのモジュールに分割されました。
- Celeryによるデータ処理パイプラインのオーケストレーション
- Goによるデータ処理
Celeryは、1つのCelerybeatインスタンスと40を超えるワーカーでデプロイされました。 パイプラインとオーケストレーションのアクティビティを構成する20以上の異なるタスクがありました。 そのような各タスクは、ある時点で失敗する可能性があります。 これらの障害はすべて、各ワーカーのシステムログにダンプされました。 ある時点で、Celeryレイヤーのデバッグと保守が不便になり始めました。 最終的に、タスクログをタスク固有のファイルに分離することにしました。
ユースケースの説明:各タスクが標準出力とエラーをファイルに記録するようにCeleryを拡張します
Celeryは、Pythonアプリケーションに内部での動作を細かく制御できるようにします。 おなじみのシグナルフレームワークが付属しています。 Celeryを使用しているアプリケーションは、特定のアクションの動作を強化するために、それらのいくつかをサブスクライブできます。 タスクレベルのシグナルを活用して、個々のタスクのライフサイクルを詳細に追跡します。 セロリには常にロギングバックエンドが付属しており、目標を達成するためにいくつかの場所でわずかにオーバーライドするだけで、その恩恵を受けることができます。
実装の詳細
Celeryは、タスクごとのロギングをすでにサポートしています。 ファイルに保存するには、ログ出力を適切な場所にディスパッチする必要があります。 この場合、タスクの適切な場所は、タスクの名前と一致するファイルです。 Celeryインスタンスでは、組み込みのログ構成を動的に推測されるログハンドラーでオーバーライドします。 celeryd_after_setupシグナルをサブスクライブして、そこでシステムログを設定することができます。
ファイル: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Celeryアプリに登録されているタスクごとに、ハンドラーを使用して対応するロガーを構築していることに注意してください。 各ハンドラーのタイプはlogging.FileHandlerであるため、そのような各インスタンスは入力としてファイル名を受け取ります。 これを実行するために必要なのは、このモジュールをファイルの最後にあるcelery_uncovered/celery.pyにインポートすることだけです。
import celery_uncovered.tricks.celery_conf get_task_logger(task_name)を呼び出すことにより、特定のタスクロガーを受信できます。 タスクごとにこのような動作を一般化するには、いくつかのユーティリティメソッドを使用してcelery.current_app.Taskをわずかに拡張する必要があります。
ファイル: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) これで、 task.log_msg("Hello, my name is: %s", task.request.id)を呼び出す場合、ログ出力はタスク名で対応するファイルにルーティングされます。
試してみる
このタスクがどのように機能するかを起動してテストするには、最初にCeleryプロセスを開始します。
$ celery -A celery_uncovered worker -l info次に、シェルを介して機能をテストできるようになります。
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) 最後に、結果を確認するには、 celery_uncovered/logsディレクトリに移動し、 celery_uncovered.tricks.tasks.add.logという対応するログファイルを開きます。 このタスクを複数回実行すると、次のようなものが表示される場合があります。
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...シナリオ4-スコープ対応タスク
CeleryとDjangoに基づいて構築された海外ユーザー向けのPythonアプリケーションを想像してみましょう。 ユーザーは、アプリケーションを使用する言語(ロケール)を設定できます。
多言語のロケール対応の電子メール通知システムを設計する必要があります。 電子メール通知を送信するには、特定のキューによって処理される特別なCeleryタスクを登録しました。 このタスクは、入力としていくつかの重要な引数と現在のユーザーロケールを受け取り、ユーザーが選択した言語で電子メールが送信されるようにします。
ここで、そのようなタスクが多数あると想像してください。ただし、これらの各タスクはロケール引数を受け入れます。 この場合、より高いレベルの抽象化でそれを解決する方が良いのではないでしょうか? ここでは、その方法を説明します。
ユースケースの説明: 1つの実行コンテキストからスコープを自動的に継承し、パラメーターとして現在の実行コンテキストに挿入します。
実装の詳細
ここでも、タスクロギングで行ったように、基本タスククラスcelery.current_app.Taskを拡張し、タスクの呼び出しを担当するいくつかのメソッドをオーバーライドします。 このデモンストレーションの目的で、 celery.current_app.Task::apply_asyncメソッドをオーバーライドしています。 このモジュールには、完全に機能する代替品を作成するのに役立つ追加のタスクがあります。
ファイル: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)重要な手がかりは、デフォルトで現在のロケールをKey-Value引数として呼び出し元のタスクに渡すことです。 タスクが特定のロケールを引数として呼び出された場合、そのタスクは変更されません。
試してみる
この機能をテストするために、 ScopeBasedTaskタイプのダミータスクを定義しましょう。 ロケールIDでファイルを検索し、そのコンテンツをJSONとして読み取ります。
ファイル: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) 次に、Celeryを起動し、シェルを起動し、さまざまなシナリオでこのタスクの実行をテストする手順を繰り返す必要があります。 フィクスチャは、 celery_uncovered/tricks/fixtures/locales/ディレクトリの下にあります。
結論
この投稿は、さまざまな視点からセロリを探索することを目的としています。 私は、郵送やレポートの生成などの従来の例でCeleryを示したほか、いくつかの興味深いニッチなビジネスユースケースへのトリックを共有しました。 Celeryはデータ駆動型の哲学に基づいて構築されており、チームはシステムスタックの一部としてCeleryを導入することで、生活をはるかにシンプルにすることができます。 基本的なPythonの経験があれば、Celeryベースのサービスの開発はそれほど複雑ではなく、かなり迅速に習得できるはずです。 デフォルトの構成はほとんどの用途に十分ですが、必要に応じて、非常に柔軟にすることができます。
私たちのチームは、バックグラウンドジョブと長時間実行タスクのオーケストレーションバックエンドとしてCeleryを使用することを選択しました。 さまざまなユースケースで広く使用されていますが、この投稿ではそのほんの一部しか言及されていません。 私たちは毎日ギガバイトのデータを取り込んで分析していますが、これは水平スケーリング技術の始まりにすぎません。