
Orkiestrowanie przepływu pracy w tle w Seler dla Pythona
Opublikowany: 2022-03-11Nowoczesne aplikacje internetowe i ich systemy bazowe są szybsze i bardziej responsywne niż kiedykolwiek wcześniej. Jednak nadal istnieje wiele przypadków, w których chcesz odciążyć wykonywanie ciężkiego zadania na inne części całej architektury systemu, zamiast zajmować się nimi w głównym wątku. Identyfikacja takich zadań jest tak prosta, jak sprawdzenie, czy należą one do jednej z następujących kategorii:
- Zadania okresowe — zadania, które zaplanujesz, aby były uruchamiane w określonym czasie lub po przerwie, np. comiesięczne generowanie raportów lub web scraper uruchamiany dwa razy dziennie.
- Zadania innych firm — aplikacja internetowa musi szybko służyć użytkownikom, nie czekając na zakończenie innych działań podczas ładowania strony, np. wysyłanie wiadomości e-mail lub powiadomienia lub rozpowszechnianie aktualizacji narzędzi wewnętrznych (takich jak zbieranie danych do testów A/B lub rejestrowanie systemu). ).
- Długotrwałe zadania — zadania, które są kosztowne pod względem zasobów, w których użytkownicy muszą czekać podczas obliczania wyników, np. wykonanie złożonego przepływu pracy (przepływy pracy DAG), generowanie wykresów, zadania typu Map-Reduce i udostępnianie treści multimedialnych (wideo, audio).
Prostym rozwiązaniem do wykonania zadania w tle byłoby uruchomienie go w osobnym wątku lub procesie. Python to kompletny język programowania wysokiego poziomu Turing, który niestety nie zapewnia wbudowanej współbieżności w skali odpowiadającej Erlangowi, Go, Javie, Scali lub Akka. Są one oparte na Communicating Sequential Processes (CSP) Tony'ego Hoare'a. Z drugiej strony wątki Pythona są koordynowane i planowane przez globalną blokadę interpretera (GIL), która uniemożliwia wielu rodzimym wątkom wykonywanie kodów bajtowych Pythona jednocześnie. Pozbycie się GIL jest tematem wielu dyskusji wśród programistów Pythona, ale nie jest przedmiotem tego artykułu. Programowanie współbieżne w Pythonie jest staromodne, chociaż możesz przeczytać o tym w samouczku wielowątkowości Pythona autorstwa innego Toptalera, Marcusa McCurdy. Tak więc konsekwentne projektowanie komunikacji między procesami jest procesem podatnym na błędy i prowadzi do łączenia kodu i złej konserwacji systemu, nie wspominając o tym, że negatywnie wpływa na skalowalność. Ponadto proces Pythona jest normalnym procesem w systemie operacyjnym (OS) i wraz z całą standardową biblioteką Pythona staje się ciężki. Wraz ze wzrostem liczby procesów w aplikacji przełączanie się z jednego takiego procesu na inny staje się operacją czasochłonną.
Aby lepiej zrozumieć współbieżność z Pythonem, obejrzyj to niesamowite przemówienie Davida Beazleya na PyCon'15.
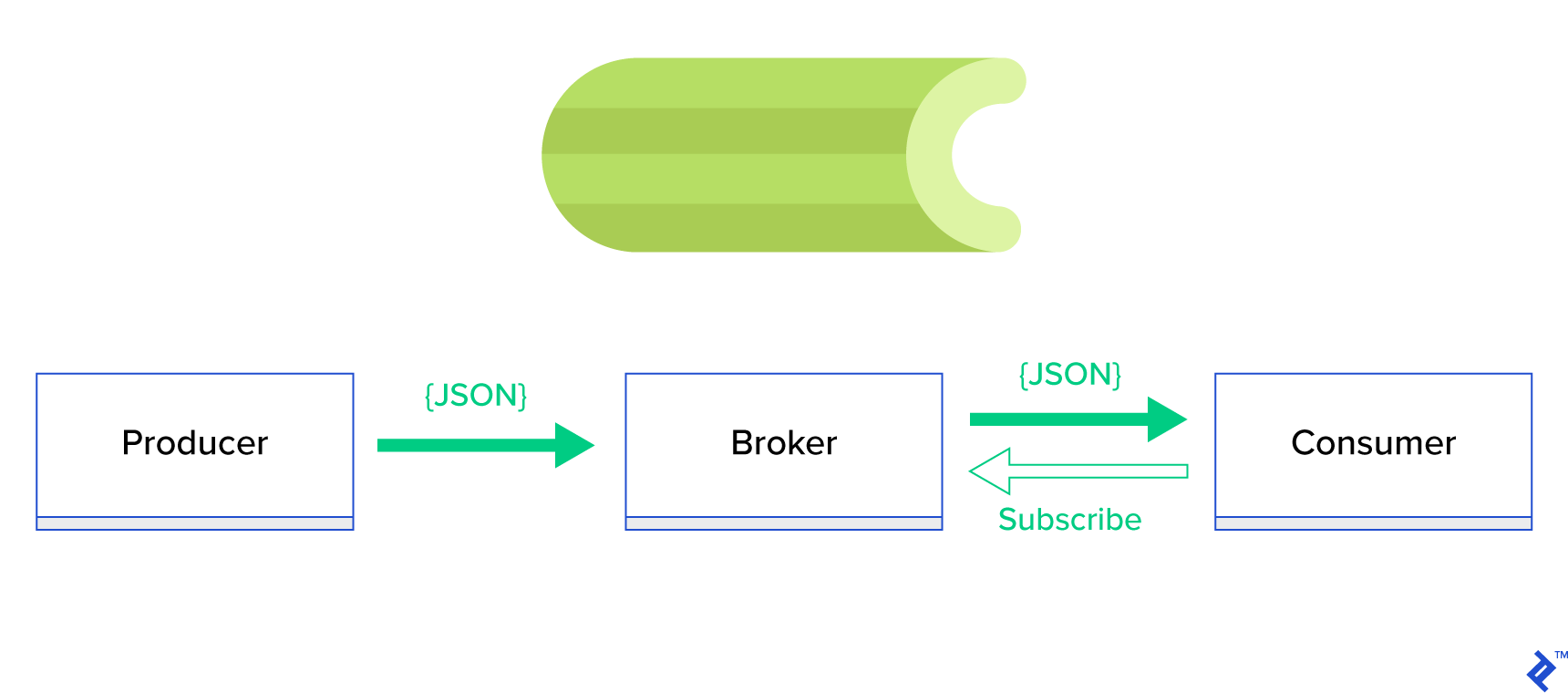
O wiele lepszym rozwiązaniem jest obsługa kolejki rozproszonej lub jej dobrze znanego paradygmatu siostrzanego zwanego publikacją-subskrypcją . Jak pokazano na rysunku 1, istnieją dwa typy aplikacji, w których jedna, zwana wydawcą , wysyła wiadomości, a druga, zwana subskrybentem , odbiera wiadomości. Ci dwaj agenci nie oddziałują ze sobą bezpośrednio, a nawet nie są sobie nawzajem świadomi. Wydawcy wysyłają komunikaty do kolejki centralnej lub brokera , a subskrybenci otrzymują od tego brokera interesujące komunikaty. Ta metoda ma dwie główne zalety:
- Skalowalność — agenci nie muszą wiedzieć o sobie nawzajem w sieci. Koncentrują się na temacie. Oznacza to, że każdy może nadal działać normalnie, niezależnie od drugiego, w sposób asynchroniczny.
- Luźne połączenie — każdy agent reprezentuje swoją część systemu (usługę, moduł). Ponieważ są one luźno powiązane, każdy z nich można indywidualnie skalować poza centrum danych.
Istnieje wiele systemów przesyłania wiadomości, które obsługują takie paradygmaty i zapewniają zgrabny interfejs API, oparty na protokołach TCP lub HTTP, np. JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ itp.
Co to jest seler?
Celery jest jednym z najpopularniejszych menedżerów pracy w tle w świecie Pythona. Celery jest kompatybilny z kilkoma brokerami komunikatów, takimi jak RabbitMQ czy Redis i może działać zarówno jako producent, jak i konsument.
Celery to asynchroniczna kolejka zadań/kolejka zadań oparta na przekazywaniu wiadomości rozproszonych. Koncentruje się na operacjach w czasie rzeczywistym, ale obsługuje również planowanie. Jednostki wykonawcze, zwane zadaniami, są wykonywane jednocześnie na co najmniej jednym serwerze roboczym przy użyciu przetwarzania wieloprocesowego, Eventlet lub gevent. Zadania mogą być wykonywane asynchronicznie (w tle) lub synchronicznie (poczekaj, aż będą gotowe). – Projekt Seler
Aby rozpocząć korzystanie z selera, po prostu postępuj zgodnie z przewodnikiem krok po kroku w oficjalnych dokumentach.
Celem tego artykułu jest dobre zrozumienie, które przypadki użycia mogą być objęte programem Celery. W tym artykule nie tylko pokażemy ciekawe przykłady, ale także spróbujemy nauczyć się, jak zastosować Celery do rzeczywistych zadań, takich jak wysyłanie wiadomości w tle, generowanie raportów, rejestrowanie i raportowanie błędów. Podzielę się moim sposobem testowania zadań poza emulacją i na koniec przedstawię kilka sztuczek, które nie są (dobrze) udokumentowane w oficjalnej dokumentacji, których odkrycie zajęło mi wiele godzin badań.
Jeśli nie masz wcześniejszego doświadczenia z Selerem, zachęcam Cię najpierw do wypróbowania go zgodnie z oficjalnym samouczkiem.
Zaostrzenie apetytu
Jeśli ten artykuł Cię intryguje i sprawia, że chcesz natychmiast zagłębić się w kod, przejdź do tego repozytorium GitHub, aby znaleźć kod użyty w tym artykule. Znajdujący się tam plik README zapewni szybkie i brudne podejście do uruchamiania i zabawy przykładowymi aplikacjami.
Pierwsze kroki z selerem
Na początek przejdziemy przez szereg praktycznych przykładów, które pokażą czytelnikowi, jak prosto i elegancko Celery rozwiązuje pozornie nietrywialne zadania. Wszystkie przykłady zostaną przedstawione w ramach Django; jednak większość z nich można łatwo przenieść do innych frameworków Pythona (Flask, Pyramid).
Układ projektu został wygenerowany przez Cookiecutter Django; jednak zachowałem tylko kilka zależności, które moim zdaniem ułatwiają rozwój i przygotowanie tych przypadków użycia. Usunąłem też niepotrzebne moduły do tego postu i aplikacji, aby zredukować szum i ułatwić zrozumienie kodu.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}zawiera różne aplikacje, które omówimy w tym poście. Każda aplikacja zawiera zestaw przykładów uporządkowanych według wymaganego poziomu znajomości selera. -
celery_uncovered/celery.pydefiniuje instancję Celery.
Plik: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Wtedy musimy mieć pewność, że Celery wystartuje razem z Django. Z tego powodu importujemy aplikację w celery_uncovered/__init__.py .
Plik: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings to źródło konfiguracji naszej aplikacji i Celery. W zależności od środowiska wykonawczego, Django uruchomi odpowiednie ustawienia: local.py dla rozwoju lub test.py dla testów. Możesz również zdefiniować własne środowisko, jeśli chcesz, tworząc nowy moduł Pythona (np. prod.py ). Konfiguracje selera są poprzedzone prefiksem CELERY_ . W tym poście skonfigurowałem RabbitMQ jako brokera i SQLite jako wynikowy bac-end.
Plik: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Scenariusz 1 — generowanie i eksportowanie raportów
Pierwszym przypadkiem, który omówimy, jest generowanie i eksportowanie raportów. W tym przykładzie dowiesz się, jak zdefiniować zadanie, które generuje raport CSV i zaplanować je w regularnych odstępach czasu za pomocą celerybeat.
Opis przypadku użycia: pobierz pięćset najgorętszych repozytoriów z GitHub w wybranym okresie (dzień, tydzień, miesiąc), pogrupuj je tematycznie i wyeksportuj wynik do pliku CSV.
Jeśli udostępnimy usługę HTTP, która uruchomi tę funkcję wywołaną przez kliknięcie przycisku „Generuj raport”, aplikacja zatrzyma się i czeka na zakończenie zadania przed wysłaniem odpowiedzi HTTP. To jest złe. Chcemy, aby nasza aplikacja internetowa była szybka i nie chcemy, aby nasi użytkownicy czekali, aż nasz back-end oblicza wyniki. Zamiast czekać na wyniki, wolelibyśmy kolejkować zadanie do procesów roboczych za pośrednictwem zarejestrowanej kolejki w Celery i odpowiedzieć z task_id na front-end. Następnie fronton użyje identyfikatora task_id do zapytania o wynik zadania w sposób asynchroniczny (np. AJAX) i będzie na bieżąco informował użytkownika o postępie zadania. Wreszcie, gdy proces się zakończy, wyniki mogą zostać podane jako plik do pobrania przez HTTP.
Szczegóły dotyczące wdrożenia
Przede wszystkim rozłóżmy proces na najmniejsze możliwe jednostki i stwórzmy potok:
- Moduły pobierania to pracownicy odpowiedzialni za pobieranie repozytoriów z usługi GitHub.
- Agregator to pracownik odpowiedzialny za konsolidację wyników na jednej liście.
- Importer to pracownik, który tworzy raporty CSV dotyczące najgorętszych repozytoriów w GitHub.
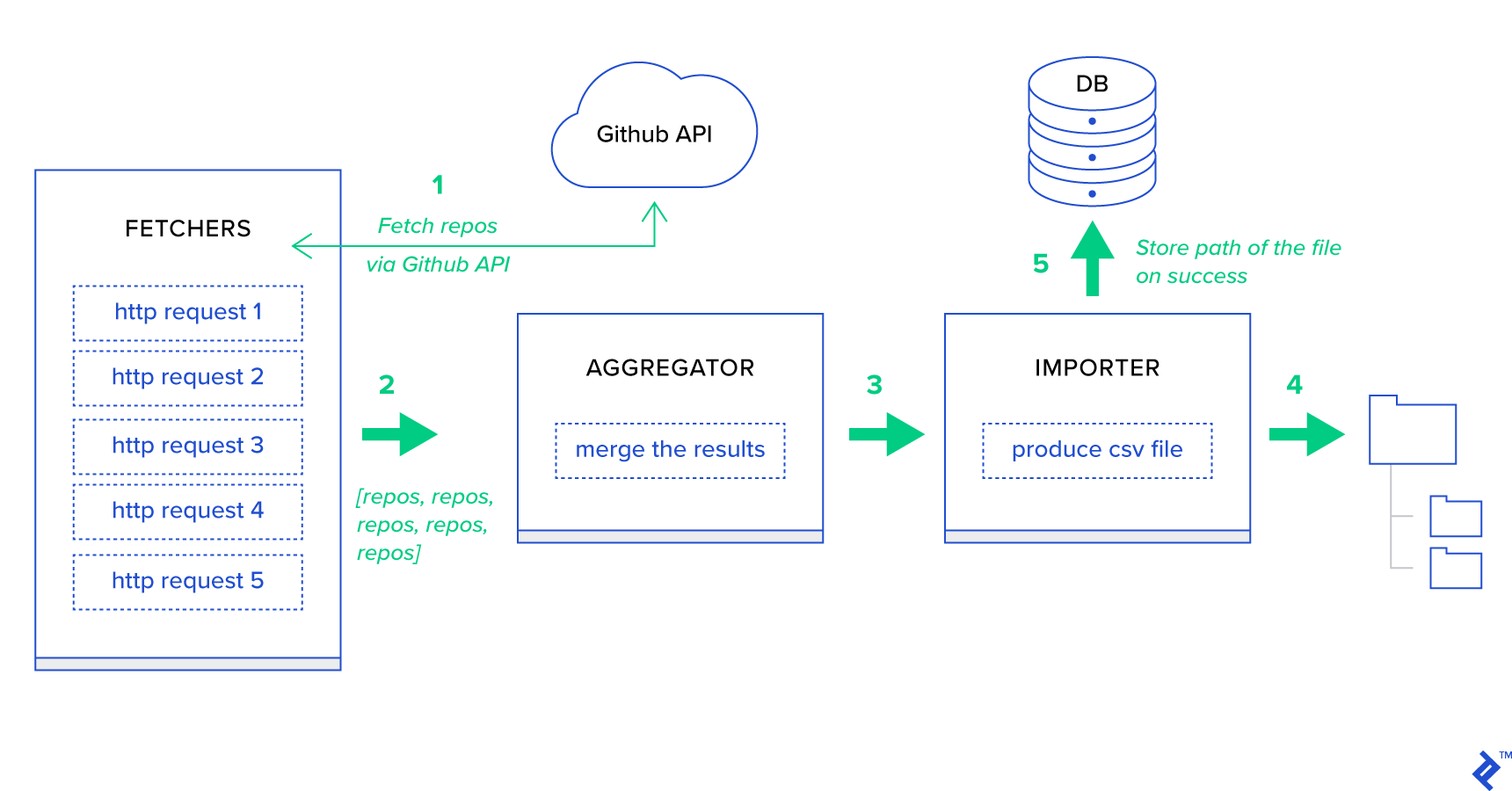
Pobieranie repozytoriów to żądanie HTTP za pomocą interfejsu API wyszukiwania GitHub GET /search/repositories . Istnieje jednak ograniczenie usługi GitHub API, które należy obsłużyć: API zwraca do 100 repozytoriów na żądanie zamiast 500. Moglibyśmy wysłać pięć żądań pojedynczo, ale nie chcemy, aby nasz użytkownik czekał dla pięciu indywidualnych żądań, ponieważ żądania HTTP są operacją powiązaną we/wy. Zamiast tego możemy wykonać pięć jednoczesnych żądań HTTP z odpowiednim parametrem strony. Czyli strona będzie w zakresie [1..5]. Zdefiniujmy zadanie o nazwie fetch_hot_repos/3 -> list w module toyex/tasks.py :
Plik: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Tak więc fetch_hot_repos tworzy żądanie do interfejsu API GitHub i odpowiada użytkownikowi listą repozytoriów. Otrzymuje trzy parametry, które zdefiniują nasz ładunek żądania:
-
since— Filtruje repozytoria w dniu utworzenia. -
per_page— Liczba wyników do zwrócenia na żądanie (ograniczona do 100). -
page—- Żądany numer strony (w zakresie [1..5]).
Uwaga: aby korzystać z interfejsu API wyszukiwania GitHub, potrzebujesz tokena OAuth, aby przejść testy uwierzytelniania. W naszym przypadku jest to zapisane w ustawieniach pod GITHUB_OAUTH .
Następnie musimy zdefiniować zadanie główne, które będzie odpowiedzialne za agregację wyników i wyeksportowanie ich do pliku CSV: produce_hot_repo_report_task/2->filepath:
Plik: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) To zadanie wykorzystuje celery.canvas.group do wykonania pięciu równoczesnych wywołań fetch_hot_repos/3 . Wyniki te są oczekiwane, a następnie sprowadzane do listy obiektów repozytorium. Następnie nasz zestaw wyników jest pogrupowany tematycznie i ostatecznie eksportowany do wygenerowanego pliku CSV w katalogu MEDIA_ROOT/ .
Aby zaplanować zadanie okresowo, możesz dodać wpis do listy harmonogramów w pliku konfiguracyjnym:
Plik: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Wypróbowanie
Aby uruchomić i przetestować działanie zadania, najpierw musimy uruchomić proces Seler:
$ celery -A celery_uncovered worker -l info Następnie musimy utworzyć celery_uncovered/media/ . Następnie będziesz mógł przetestować jego funkcjonalność za pomocą Shell lub Celerybeat:
Powłoka :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)selera :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Wyniki możesz obejrzeć w katalogu MEDIA_ROOT/ .
Scenariusz 2 — zgłaszanie błędów serwera 500 za pośrednictwem poczty e-mail
Jednym z najczęstszych przypadków użycia Selera jest wysyłanie powiadomień e-mail. Powiadomienie e-mail to operacja we/wy w trybie offline, która wykorzystuje lokalny serwer SMTP lub SES innej firmy. Istnieje wiele przypadków użycia, które wiążą się z wysłaniem wiadomości e-mail i w większości z nich użytkownik nie musi czekać na zakończenie tego procesu przed otrzymaniem odpowiedzi HTTP. Dlatego preferowane jest wykonywanie takich zadań w tle i natychmiastowe reagowanie na użytkownika.
Opis przypadku użycia: Zgłoś błędy 50X na adres e-mail administratora za pośrednictwem programu Celery.
Python i Django mają niezbędne zaplecze do rejestrowania systemu. Nie będę wchodził w szczegóły, jak faktycznie działa logowanie w Pythonie. Jeśli jednak nigdy wcześniej tego nie próbowałeś lub potrzebujesz odświeżenia, zapoznaj się z dokumentacją wbudowanego modułu logowania. Na pewno chcesz tego w swoim środowisku produkcyjnym. Django ma specjalny program do obsługi rejestratora o nazwie AdminEmailHandler, który wysyła e-maile do administratorów z każdym otrzymanym logiem.
Szczegóły dotyczące wdrożenia
Główną ideą jest rozszerzenie metody send_mail klasy AdminEmailHandler w taki sposób, aby mogła wysyłać pocztę przez Celery. Można to zrobić, jak pokazano na poniższym rysunku:
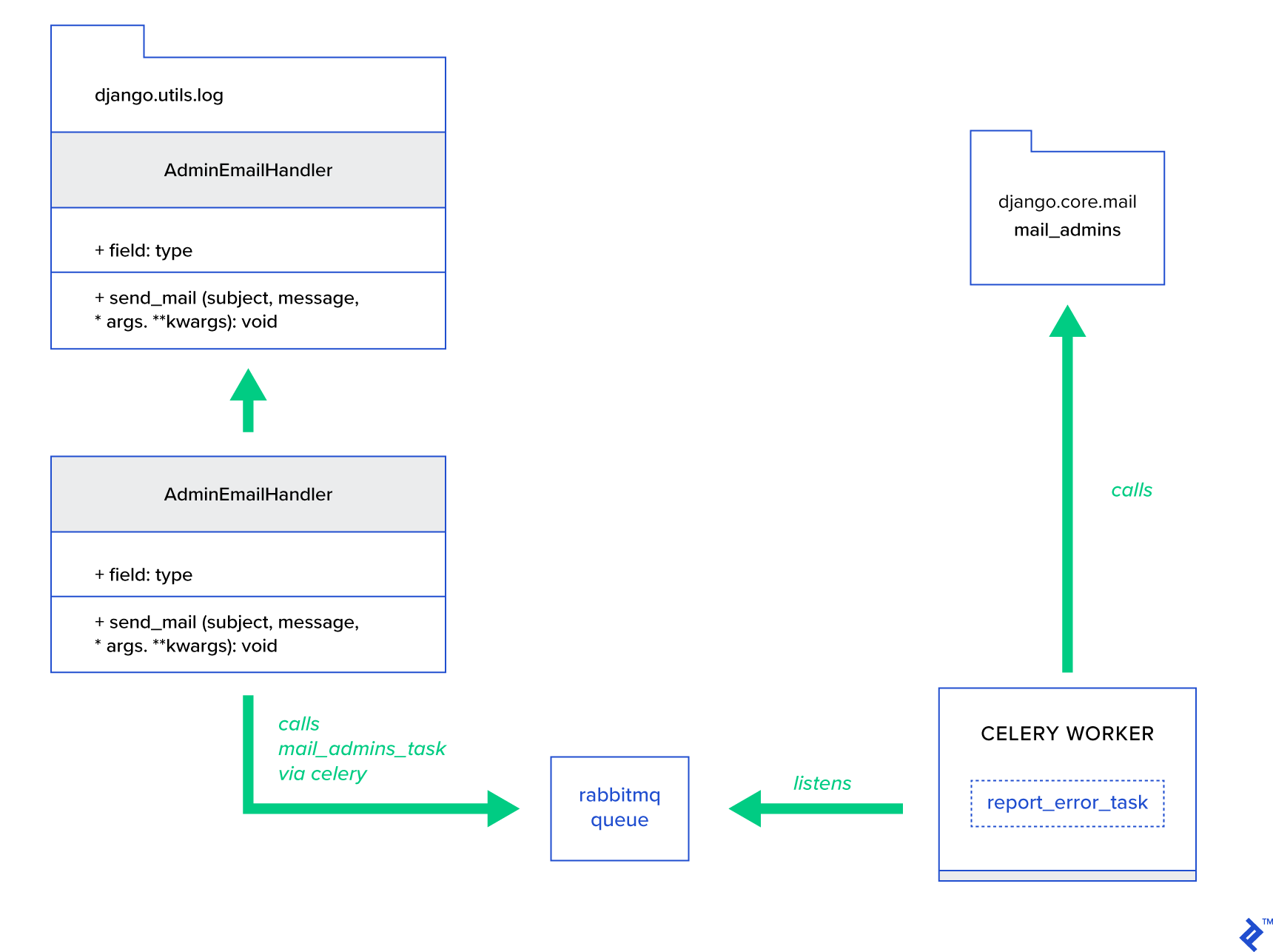
Najpierw musimy skonfigurować zadanie o nazwie report_error_task , które wywołuje mail_admins z podanym tematem i wiadomością:
Plik: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Następnie rozszerzamy AdminEmailHandler, aby wewnętrznie wywoływał tylko zdefiniowane zadanie Celery:
Plik: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Na koniec musimy skonfigurować logowanie. Konfiguracja logowania w Django jest dość prosta. To, czego potrzebujesz, to nadpisać LOGGING , aby silnik rejestrowania zaczął używać nowo zdefiniowanego modułu obsługi:
Konfiguracja pliku config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Zauważ, że celowo ustawiłem filtry obsługi require_debug_true , aby przetestować tę funkcjonalność, gdy aplikacja jest uruchomiona w trybie debugowania.
Wypróbowanie
Aby to przetestować, przygotowałem widok Django, który obsługuje operację „dzielenie przez zero” na localhost:8000/report-error . Musisz również uruchomić kontener MailHog Docker, aby sprawdzić, czy wiadomość e-mail jest rzeczywiście wysłana.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Dodatkowe szczegóły
Jako narzędzie do testowania poczty skonfigurowałem MailHog i skonfigurowałem wysyłkę Django, aby używać go do dostarczania SMTP. Istnieje wiele sposobów na wdrożenie i uruchomienie MailHog. Zdecydowałem się na kontener Docker. Szczegóły znajdziesz w odpowiednim pliku README:
Plik: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Aby skonfigurować aplikację do korzystania z MailHog, musisz dodać następujące wiersze w swojej konfiguracji:
Plik: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Poza domyślnymi zadaniami dotyczącymi selera
Zadania selerowe mogą być tworzone z dowolnej funkcji wywoływanej. Domyślnie każde zadanie zdefiniowane przez użytkownika jest wstrzykiwane z celery.app.task.Task jako klasą nadrzędną (abstrakcyjną). Ta klasa zawiera funkcjonalność uruchamiania zadań asynchronicznie (przekazywanie przez sieć do pracownika Celery) lub synchronicznie (w celach testowych), tworzenie sygnatur i wiele innych narzędzi. W kolejnych przykładach postaramy się rozszerzyć Celery.app.task.Task , a następnie użyć go jako klasy bazowej, aby dodać kilka przydatnych zachowań do naszych zadań.
Scenariusz 3 — Rejestrowanie plików według zadania
W jednym z moich projektów rozwijałem aplikację, która zapewnia użytkownikowi końcowemu narzędzie podobne do Extract, Transform, Load (ETL), które było w stanie pozyskiwać, a następnie filtrować ogromną ilość danych hierarchicznych. Back-end został podzielony na dwa moduły:
- Orkiestracja potoku przetwarzania danych z Celery
- Przetwarzanie danych z Go
Celery został wdrożony z jedną instancją Celerybeat i ponad 40 pracownikami. Na działania potoku i orkiestracji składało się ponad dwadzieścia różnych zadań. Każde takie zadanie może w pewnym momencie zakończyć się niepowodzeniem. Wszystkie te awarie zostały zrzucone do dziennika systemowego każdego pracownika. W pewnym momencie debugowanie i utrzymywanie warstwy Celery stało się niewygodne. Ostatecznie zdecydowaliśmy się wyizolować dziennik zadań do pliku specyficznego dla zadania.
Opis przypadku użycia: Rozszerz program Celery, aby każde zadanie rejestrowało swoje standardowe wyjście i błędy w plikach
Celery zapewnia aplikacjom Pythona doskonałą kontrolę nad tym, co robi wewnętrznie. Jest dostarczany ze znaną strukturą sygnałów. Aplikacje korzystające z programu Celery mogą subskrybować kilka z nich w celu usprawnienia zachowania niektórych działań. Zamierzamy wykorzystać sygnały na poziomie zadania, aby zapewnić pełne śledzenie cykli życia poszczególnych zadań. Seler zawsze jest wyposażony w zaplecze do rejestrowania i zamierzamy czerpać z niego korzyści, tylko nieznacznie nadpisując w kilku miejscach, aby osiągnąć nasze cele.
Szczegóły dotyczące wdrożenia
Seler obsługuje już logowanie według zadania. Aby zapisać do pliku, konieczne jest wysłanie wyjścia logu do właściwej lokalizacji. W naszym przypadku właściwą lokalizacją zadania jest plik pasujący do nazwy zadania. W instancji Celery zastąpimy wbudowaną konfigurację rejestrowania dynamicznie wywnioskowanymi funkcjami obsługi rejestrowania. Istnieje możliwość zasubskrybowania sygnału celeryd_after_setup , a następnie skonfigurowania tam logowania systemowego:
Plik: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Zauważ, że dla każdego zadania zarejestrowanego w aplikacji Celery budujemy odpowiedni logger z jego obsługą. Każda procedura obsługi jest typu logging.FileHandler , a zatem każde takie wystąpienie otrzymuje nazwę pliku jako dane wejściowe. Wszystko, czego potrzebujesz, aby to uruchomić, to zaimportować ten moduł do celery_uncovered/celery.py na końcu pliku:
import celery_uncovered.tricks.celery_conf Konkretny rejestrator zadań można odebrać, wywołując get_task_logger(task_name) . Aby uogólnić takie zachowanie dla każdego zadania, należy nieco rozszerzyć celery.current_app.Task o kilka metod użytkowych:
Plik: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Teraz w przypadku wywołania task.log_msg("Hello, my name is: %s", task.request.id) , dane wyjściowe dziennika zostaną przekierowane do odpowiedniego pliku pod nazwą zadania.
Wypróbowanie
Aby uruchomić i przetestować działanie tego zadania, najpierw uruchom proces Seler:
$ celery -A celery_uncovered worker -l infoWtedy będziesz mógł przetestować funkcjonalność za pomocą powłoki:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Aby zobaczyć wynik, przejdź do katalogu celery_uncovered/logs i otwórz odpowiedni plik dziennika o nazwie celery_uncovered.tricks.tasks.add.log . Po wielokrotnym uruchomieniu tego zadania możesz zobaczyć coś podobnego do poniższego:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Scenariusz 4 — Zadania uwzględniające zakres
Wyobraźmy sobie aplikację Pythona dla międzynarodowych użytkowników, zbudowaną na Celery i Django. Użytkownicy mogą ustawić język (lokal), w którym używają Twojej aplikacji.
Musisz zaprojektować wielojęzyczny system powiadomień e-mail z uwzględnieniem lokalizacji. Aby wysyłać powiadomienia e-mail, zarejestrowałeś specjalne zadanie Celery, które jest obsługiwane przez określoną kolejkę. To zadanie otrzymuje kilka kluczowych argumentów jako dane wejściowe i bieżące ustawienia regionalne użytkownika, dzięki czemu wiadomość e-mail zostanie wysłana w wybranym przez użytkownika języku.
Teraz wyobraź sobie, że mamy wiele takich zadań, ale każde z nich akceptuje argument locale. Czy w takim razie nie byłoby lepiej rozwiązać go na wyższym poziomie abstrakcji? Tutaj widzimy, jak to zrobić.
Opis przypadku użycia: Automatycznie dziedzicz zakres z jednego kontekstu wykonania i wstrzyknij go do bieżącego kontekstu wykonania jako parametr.
Szczegóły dotyczące wdrożenia
Podobnie jak w przypadku rejestrowania zadań, chcemy rozszerzyć podstawową klasę zadań celery.current_app.Task i przesłonić kilka metod odpowiedzialnych za wywoływanie zadań. Na potrzeby tej demonstracji zastępuję metodę celery.current_app.Task::apply_async . Dla tego modułu są dodatkowe zadania, które pomogą Ci wyprodukować w pełni działający zamiennik.
Plik: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)Kluczową wskazówką jest, aby domyślnie przekazać bieżące ustawienia regionalne jako argument klucz-wartość do zadania wywołującego. Jeśli zadanie zostało wywołane z pewnymi ustawieniami narodowymi jako argumentem, to jest to niezmienione.
Wypróbowanie
Aby przetestować tę funkcjonalność, zdefiniujmy fikcyjne zadanie typu ScopeBasedTask . Lokalizuje plik według identyfikatora lokalizacji i odczytuje jego zawartość jako JSON:
Plik: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Teraz musisz powtórzyć kroki uruchamiania programu Celery, uruchamiania powłoki i testowania wykonania tego zadania w różnych scenariuszach. Urządzenia znajdują się w katalogu celery_uncovered/tricks/fixtures/locales/ .
Wniosek
Ten post miał na celu poznanie selera z różnych perspektyw. Zademonstrowałem Celery'ego na konwencjonalnych przykładach, takich jak wysyłanie wiadomości i generowanie raportów, a także udostępniałem sztuczki w ciekawych niszowych zastosowaniach biznesowych. Celery opiera się na filozofii opartej na danych, a Twój zespół może znacznie uprościć swoje życie, wprowadzając go jako część swojego stosu systemowego. Tworzenie usług opartych na Celery nie jest zbyt skomplikowane, jeśli masz podstawowe doświadczenie w Pythonie, i powinieneś być w stanie szybko je opanować. Domyślna konfiguracja jest wystarczająco dobra dla większości zastosowań, ale w razie potrzeby mogą być bardzo elastyczne.
Nasz zespół podjął decyzję o użyciu Celery jako zaplecza orkiestracyjnego do zadań wykonywanych w tle i długotrwałych zadań. Używamy go szeroko w różnych przypadkach użycia, z których tylko kilka zostało wspomnianych w tym poście. Codziennie pobieramy i analizujemy gigabajty danych, ale to dopiero początek technik skalowania poziomego.