
Организация рабочего процесса фонового задания в Celery для Python
Опубликовано: 2022-03-11Современные веб-приложения и их базовые системы работают быстрее и быстрее, чем когда-либо прежде. Тем не менее, все еще есть много случаев, когда вы хотите переложить выполнение тяжелой задачи на другие части всей вашей системной архитектуры вместо того, чтобы решать их в своем основном потоке. Определить такие задачи так же просто, как проверить, относятся ли они к одной из следующих категорий:
- Периодические задачи — задания, которые вы запланируете запускать в определенное время или через определенный интервал, например, создание ежемесячного отчета или веб-парсер, который запускается два раза в день.
- Сторонние задачи — веб-приложение должно быстро обслуживать пользователей, не дожидаясь завершения других действий во время загрузки страницы, например, отправки электронного письма или уведомления или распространения обновлений во внутренние инструменты (такие как сбор данных для A/B-тестирования или ведение журнала системы). ).
- Длительные задания — задания, требующие значительных ресурсов, когда пользователям приходится ждать, пока они вычислят свои результаты, например, выполнение сложного рабочего процесса (рабочие процессы DAG), генерация графа, задачи, подобные Map-Reduce, и обслуживание медиаконтента (видео, аудио).
Простым решением для выполнения фоновой задачи было бы запустить ее в отдельном потоке или процессе. Python — это высокоуровневый полный язык программирования по Тьюрингу, который, к сожалению, не обеспечивает встроенного параллелизма в масштабе, сравнимом с Erlang, Go, Java, Scala или Akka. Они основаны на коммуникативных последовательных процессах Тони Хоара (CSP). Потоки Python, с другой стороны, координируются и планируются глобальной блокировкой интерпретатора (GIL), которая предотвращает одновременное выполнение байт-кодов Python несколькими собственными потоками. Избавление от GIL является предметом многочисленных дискуссий среди разработчиков Python, но не в центре внимания данной статьи. Параллельное программирование на Python — это старомодно, хотя вы можете прочитать об этом в учебнике Python Multithreading Tutorial , написанном коллегой по Toptaler Маркусом Маккарди. Таким образом, согласованное проектирование связи между процессами является процессом, подверженным ошибкам, и приводит к связыванию кода и плохой ремонтопригодности системы, не говоря уже о том, что это негативно влияет на масштабируемость. Кроме того, процесс Python является обычным процессом в операционной системе (ОС) и со всей стандартной библиотекой Python становится тяжеловесным. По мере увеличения количества процессов в приложении переключение с одного такого процесса на другой становится трудоемкой операцией.
Чтобы лучше понять параллелизм с Python, посмотрите это невероятное выступление Дэвида Бизли на PyCon'15.
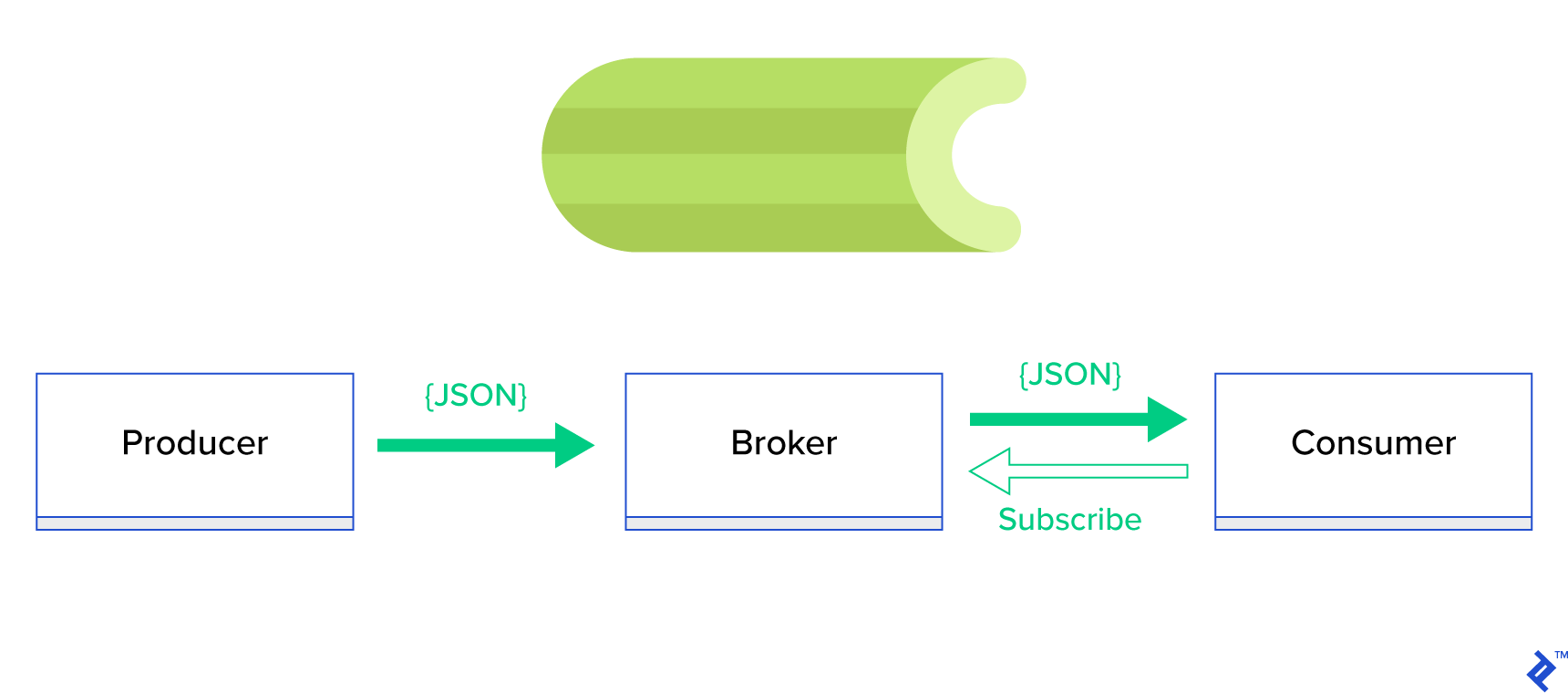
Гораздо лучшим решением будет обслуживать распределенную очередь или ее хорошо известную родственную парадигму, называемую публикация-подписка . Как показано на рисунке 1, существует два типа приложений, в которых одно, называемое издателем , отправляет сообщения, а другое, называемое подписчиком , получает сообщения. Эти два агента не взаимодействуют друг с другом напрямую и даже не знают друг о друге. Издатели отправляют сообщения в центральную очередь или брокера , а подписчики получают интересующие их сообщения от этого брокера. В этом методе есть два основных преимущества:
- Масштабируемость — агентам не нужно знать друг о друге в сети. Они ориентированы по темам. Таким образом, это означает, что каждый из них может продолжать нормально работать независимо от другого в асинхронном режиме.
- Слабая связанность — каждый агент представляет свою часть системы (сервис, модуль). Поскольку они слабо связаны, каждый из них может масштабироваться отдельно за пределы центра обработки данных.
Существует множество систем обмена сообщениями, которые поддерживают такие парадигмы и предоставляют удобный API, управляемый протоколами TCP или HTTP, например, JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ и т. д.
Что такое сельдерей?
Celery — один из самых популярных менеджеров фоновых заданий в мире Python. Celery совместим с несколькими брокерами сообщений, такими как RabbitMQ или Redis, и может действовать как как производитель, так и как потребитель.
Celery — это асинхронная очередь задач/очередь заданий, основанная на распределенной передаче сообщений. Он ориентирован на операции в реальном времени, но также поддерживает планирование. Единицы выполнения, называемые задачами, выполняются одновременно на одном или нескольких рабочих серверах с использованием многопроцессорности, Eventlet или gevent. Задачи могут выполняться асинхронно (в фоновом режиме) или синхронно (ожидание готовности). - Сельдерей Проект
Чтобы начать работу с Celery, просто следуйте пошаговому руководству в официальной документации.
Цель этой статьи — дать вам хорошее представление о том, какие варианты использования может охватывать Celery. В этой статье мы не только покажем интересные примеры, но и попробуем научиться применять Celery к реальным задачам, таким как фоновая рассылка, создание отчетов, ведение журналов и отчеты об ошибках. Я поделюсь своим способом тестирования задач, выходящих за рамки эмуляции, и, наконец, я предоставлю несколько приемов, которые (хорошо) не задокументированы в официальной документации, на поиск которых у меня ушли часы исследований.
Если у вас нет опыта работы с Celery, я рекомендую вам сначала попробовать его, следуя официальному руководству.
Разжигание аппетита
Если эта статья заинтриговала вас и вызвала желание немедленно погрузиться в код, перейдите в этот репозиторий GitHub для получения кода, используемого в этой статье. README даст вам быстрый и грязный подход к запуску и игре с примерами приложений.
Первые шаги с сельдереем
Для начала пройдемся по серии практических примеров, которые покажут читателю, как просто и изящно Celery решает, казалось бы, нетривиальные задачи. Все примеры будут представлены в рамках фреймворка Django; однако большинство из них можно легко портировать на другие фреймворки Python (Flask, Pyramid).
Макет проекта был создан Cookiecutter Django; однако я оставил только несколько зависимостей, которые, на мой взгляд, облегчают разработку и подготовку этих вариантов использования. Я также удалил ненужные для этого поста модули и приложения, чтобы уменьшить шум и сделать код более понятным.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}содержит различные приложения, которые мы рассмотрим в этом посте. Каждое приложение содержит набор примеров, упорядоченных по требуемому уровню понимания Celery. -
celery_uncovered/celery.pyопределяет экземпляр Celery.
Файл: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Затем нам нужно убедиться, что Celery запустится вместе с Django. По этой причине мы импортируем приложение в celery_uncovered/__init__.py .
Файл: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings — это источник конфигурации для нашего приложения и Celery. В зависимости от среды выполнения Django запустит соответствующие настройки: local.py для разработки или test.py для тестирования. Вы также можете определить свою собственную среду, если хотите, создав новый модуль Python (например, prod.py ). Конфигурации Celery имеют префикс CELERY_ . Для этого поста я настроил RabbitMQ в качестве брокера и SQLite в качестве конечного результата.
Файл: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Сценарий 1. Генерация и экспорт отчетов
Первый случай, который мы рассмотрим, — это создание и экспорт отчетов. В этом примере вы узнаете, как определить задачу, которая создает отчет в формате CSV, и запланировать ее через равные промежутки времени с помощью celerybeat.
Описание варианта использования: выберите пятьсот самых популярных репозиториев с GitHub за выбранный период (день, неделя, месяц), сгруппируйте их по темам и экспортируйте результат в CSV-файл.
Если мы предоставим службу HTTP, которая будет выполнять эту функцию, запускаемую нажатием кнопки с надписью «Создать отчет», приложение остановится и дождется завершения задачи, прежде чем отправить ответ HTTP. Это плохо. Мы хотим, чтобы наше веб-приложение было быстрым, и мы не хотим, чтобы наши пользователи ждали, пока наш сервер вычислит результаты. Вместо того, чтобы ждать получения результатов, мы предпочли бы поставить задачу в очередь рабочих процессов через зарегистрированную очередь в Celery и ответить интерфейсу с помощью task_id . Затем внешний интерфейс будет использовать task_id для асинхронного запроса результата задачи (например, AJAX) и будет держать пользователя в курсе хода выполнения задачи. Наконец, когда процесс завершается, результаты могут быть представлены в виде файла для загрузки через HTTP.
Детали реализации
Прежде всего, разобьем процесс на наименьшие возможные единицы и создадим пайплайн:
- Сборщики — это работники, отвечающие за получение репозиториев из службы GitHub.
- Агрегатор — это работник, который отвечает за объединение результатов в один список.
- Импортер — это работник, который создает CSV-отчеты о самых популярных репозиториях в GitHub.
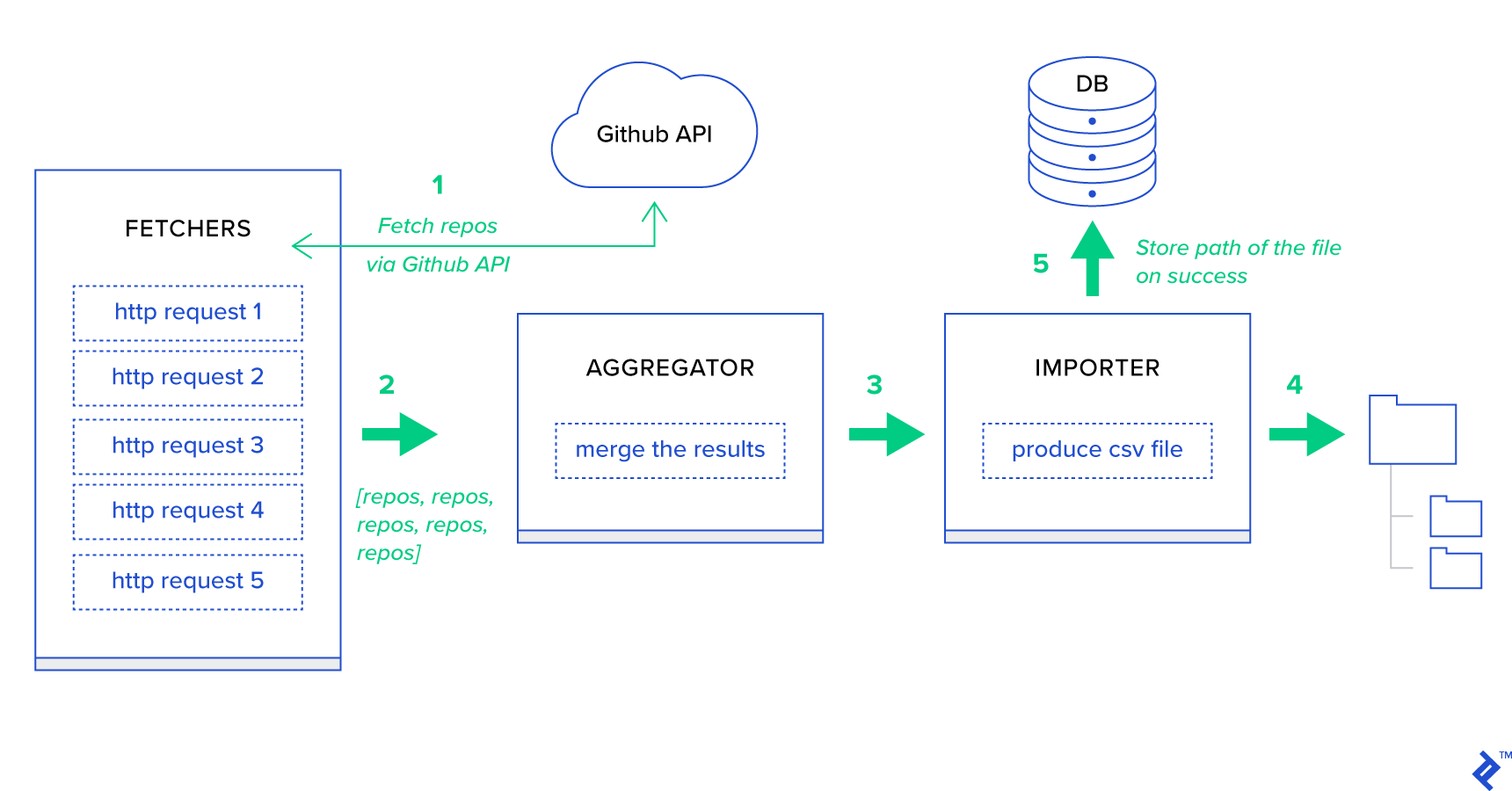
Получение репозиториев — это HTTP-запрос с использованием GitHub Search API GET /search/repositories . Однако существует ограничение службы API GitHub, которое необходимо обрабатывать: API возвращает до 100 репозиториев на запрос вместо 500. Мы могли бы отправить пять запросов по одному, но мы не хотим заставлять пользователя ждать. для пяти отдельных запросов, поскольку HTTP-запросы являются операцией, связанной с вводом-выводом. Вместо этого мы можем выполнить пять одновременных HTTP-запросов с соответствующим параметром страницы. Таким образом, страница будет находиться в диапазоне [1..5]. Давайте определим задачу с именем fetch_hot_repos/3 -> list в toyex/tasks.py :
Файл: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Итак fetch_hot_repos создает запрос к GitHub API и отвечает пользователю списком репозиториев. Он получает три параметра, которые будут определять полезную нагрузку нашего запроса:
-
since— фильтрует репозитории по дате создания. -
per_page— количество результатов, возвращаемых на запрос (ограничено 100). -
page— номер запрашиваемой страницы (в диапазоне [1..5]).
Примечание. Чтобы использовать GitHub Search API, вам потребуется токен OAuth для прохождения проверки подлинности. В нашем случае он сохраняется в настройках GITHUB_OAUTH .
Затем нам нужно определить основную задачу, которая будет отвечать за агрегирование результатов и их экспорт в файл CSV produce_hot_repo_report_task/2->filepath:
Файл: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Эта задача использует celery.canvas.group для выполнения пяти одновременных вызовов fetch_hot_repos/3 . Эти результаты ожидаются, а затем сводятся к списку объектов репозитория. Затем наш набор результатов группируется по темам и, наконец, экспортируется в сгенерированный файл CSV в MEDIA_ROOT/ .
Чтобы периодически планировать задачу, вы можете добавить запись в список расписаний в файле конфигурации:
Файл: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Пробуем
Для того, чтобы запустить и проверить работу задачи, для начала нам нужно запустить процесс Celery:
$ celery -A celery_uncovered worker -l info Далее нам нужно создать celery_uncovered/media/ . Затем вы сможете протестировать его функциональность через Shell или Celerybeat:
Оболочка :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Сельдерейбит :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Вы можете посмотреть результаты в MEDIA_ROOT/ .
Сценарий 2. Отчет об ошибках сервера 500 по электронной почте
Одним из наиболее распространенных вариантов использования Celery является отправка уведомлений по электронной почте. Уведомление по электронной почте — это связанная операция ввода-вывода в автономном режиме, которая использует либо локальный SMTP-сервер, либо сторонний SES. Существует множество вариантов использования, связанных с отправкой электронной почты, и в большинстве из них пользователю не нужно ждать завершения этого процесса, прежде чем получить ответ HTTP. Вот почему такие задачи предпочтительнее выполнять в фоновом режиме и немедленно отвечать пользователю.
Описание варианта использования: Сообщите об ошибках 50X по электронной почте администратору через Celery.
Python и Django имеют необходимый опыт для ведения системного журнала. Я не буду вдаваться в подробности того, как на самом деле работает ведение журнала Python. Однако, если вы никогда не пробовали его раньше или вам нужно освежить знания, прочтите документацию по встроенному модулю ведения журнала. Вы определенно хотите это в своей производственной среде. В Django есть специальный обработчик логов, называемый AdminEmailHandler, который отправляет администраторам электронные письма для каждого полученного сообщения журнала.
Детали реализации
Основная идея — расширить метод send_mail класса AdminEmailHandler таким образом, чтобы он мог отправлять почту через Celery. Это можно сделать, как показано на рисунке ниже:
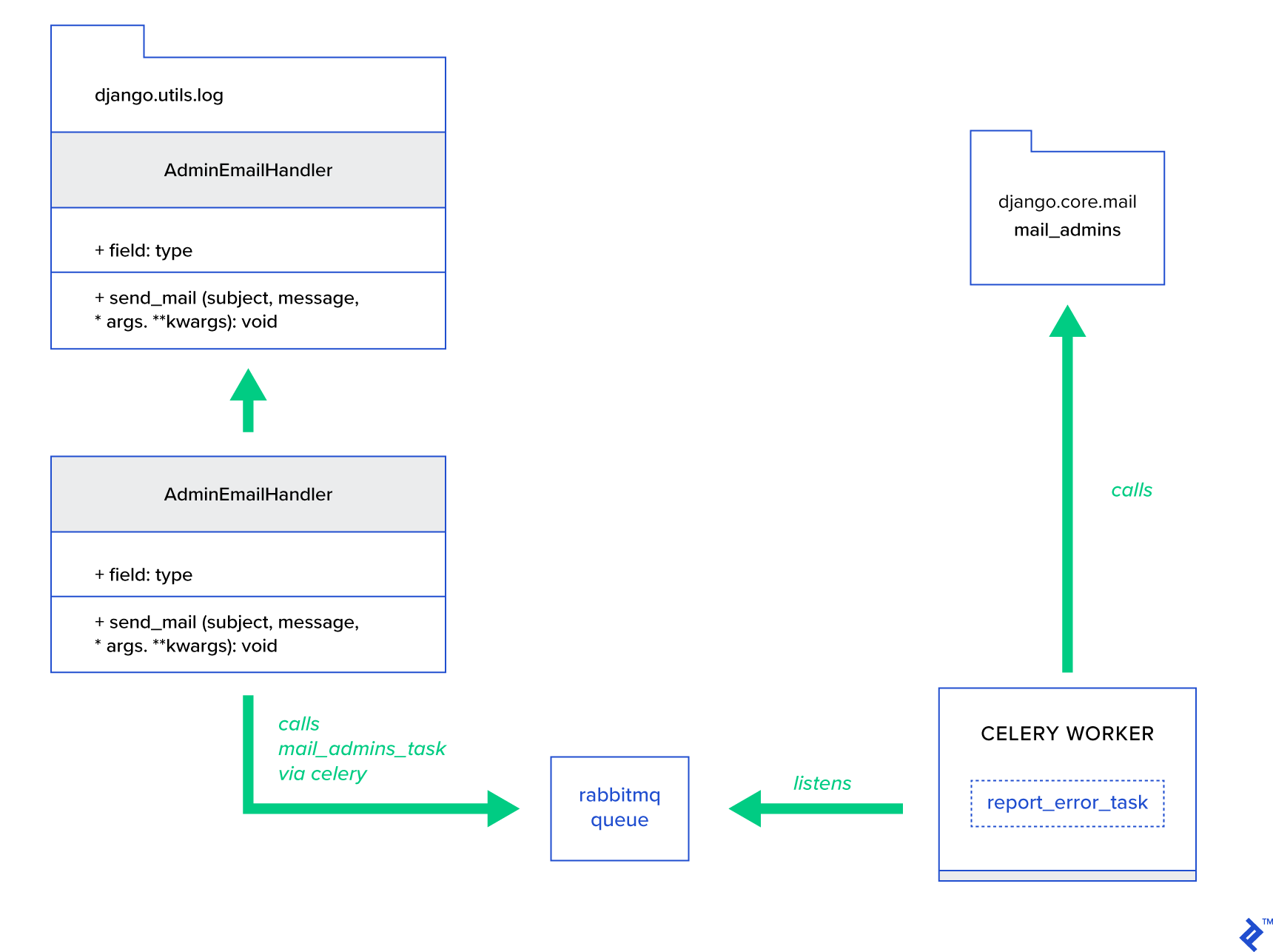
Во-первых, нам нужно настроить задачу с именем report_error_task , которая вызывает mail_admins с предоставленной темой и сообщением:
Файл: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Затем мы фактически расширяем AdminEmailHandler, чтобы он внутренне вызывал только определенную задачу Celery:
Файл: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Наконец, нам нужно настроить ведение журнала. Настройка ведения журнала в Django довольно проста. Что вам нужно, так это переопределить LOGGING , чтобы механизм ведения журнала начал использовать только что определенный обработчик:
Файл config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Обратите внимание, что я намеренно настроил фильтры обработчиков require_debug_true , чтобы протестировать эту функциональность во время работы приложения в режиме отладки.
Пробуем
Чтобы проверить это, я подготовил представление Django, которое обслуживает операцию «деления на ноль» по адресу localhost:8000/report-error . Вам также необходимо запустить контейнер MailHog Docker, чтобы проверить, что электронная почта действительно отправлена.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Дополнительные детали
В качестве инструмента тестирования почты я установил MailHog и настроил рассылку Django, чтобы использовать ее для доставки по SMTP. Есть много способов развернуть и запустить MailHog. Я решил использовать контейнер Docker. Вы можете найти подробности в соответствующем файле README:
Файл: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Чтобы настроить ваше приложение для использования MailHog, вам нужно добавить следующие строки в вашу конфигурацию:
Файл: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Помимо стандартных задач Celery
Задачи Celery могут быть созданы из любой вызываемой функции. По умолчанию любая определяемая пользователем задача внедряется с помощью celery.app.task.Task в качестве родительского (абстрактного) класса. Этот класс содержит функционал запуска задач асинхронно (передача его по сети воркеру Celery) или синхронно (для целей тестирования), создание подписей и многие другие утилиты. В следующих примерах мы попытаемся расширить Celery.app.task.Task а затем использовать его в качестве базового класса, чтобы добавить несколько полезных функций для наших задач.
Сценарий 3 — ведение журнала файлов для каждой задачи
В одном из своих проектов я разрабатывал приложение, которое предоставляет конечному пользователю инструмент, подобный извлечению, преобразованию, загрузке (ETL), который может принимать, а затем фильтровать огромное количество иерархических данных. Бэкэнд был разделен на два модуля:
- Оркестрация конвейера обработки данных с помощью Celery
- Обработка данных с помощью Go
Celery был развернут с одним экземпляром Celerybeat и более чем 40 рабочими процессами. Было более двадцати различных задач, которые составляли действия по конвейеру и оркестровке. Каждая такая задача может не сработать в какой-то момент. Все эти сбои сбрасывались в системный журнал каждого воркера. В какой-то момент стало неудобно отлаживать и поддерживать слой Celery. В конце концов, мы решили изолировать журнал задач в файле, специфичном для задачи.
Описание варианта использования: Расширьте возможности Celery, чтобы каждая задача регистрировала свой стандартный вывод и ошибки в файлах.
Celery предоставляет приложениям Python большой контроль над тем, что они делают внутри. Он поставляется со знакомой структурой сигналов. Приложения, использующие Celery, могут подписаться на некоторые из них, чтобы улучшить поведение определенных действий. Мы собираемся использовать сигналы на уровне задач, чтобы обеспечить подробное отслеживание жизненных циклов отдельных задач. Celery всегда поставляется с серверной частью ведения журнала, и мы собираемся извлечь из этого выгоду, лишь немного переопределяя в нескольких местах для достижения наших целей.
Детали реализации
Celery уже поддерживает ведение журнала для каждой задачи. Чтобы сохранить в файл, необходимо отправить вывод журнала в нужное место. В нашем случае правильным расположением задачи является файл, соответствующий названию задачи. В экземпляре Celery мы переопределим встроенную конфигурацию ведения журнала с помощью динамически выводимых обработчиков ведения журнала. Есть возможность подписаться на сигнал celeryd_after_setup и потом там настроить системное логирование:
Файл: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Обратите внимание, что для каждой задачи, зарегистрированной в приложении Celery, мы создаем соответствующий регистратор с его обработчиком. Каждый обработчик имеет тип logging.FileHandler , поэтому каждый такой экземпляр получает в качестве входных данных имя файла. Все, что вам нужно для запуска, — это импортировать этот модуль в celery_uncovered/celery.py в конце файла:
import celery_uncovered.tricks.celery_conf Конкретный регистратор задач можно получить, вызвав get_task_logger(task_name) . Чтобы обобщить такое поведение для каждой задачи, необходимо немного расширить celery.current_app.Task несколькими служебными методами:
Файл: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Теперь в случае вызова task.log_msg("Hello, my name is: %s", task.request.id) вывод лога будет перенаправлен в соответствующий файл под именем задачи.
Пробуем
Для того, чтобы запустить и проверить работу этой задачи, сначала запустите процесс Celery:
$ celery -A celery_uncovered worker -l infoЗатем вы сможете протестировать функциональность через Shell:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Наконец, чтобы увидеть результат, перейдите в celery_uncovered/logs и откройте соответствующий файл журнала с именем celery_uncovered.tricks.tasks.add.log . Вы можете увидеть что-то подобное, как показано ниже, после многократного запуска этой задачи:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Сценарий 4 — Задачи с учетом области
Давайте представим приложение Python для международных пользователей, построенное на Celery и Django. Пользователи могут указать, на каком языке (локали) они используют ваше приложение.
Вы должны разработать многоязычную систему уведомлений по электронной почте с учетом локали. Для отправки уведомлений по электронной почте вы зарегистрировали специальную задачу Celery, которая обрабатывается определенной очередью. Эта задача получает в качестве входных данных некоторые ключевые аргументы и текущую локаль пользователя, поэтому электронная почта будет отправляться на выбранном пользователем языке.
Теперь представьте, что у нас много таких задач, но каждая из них принимает аргумент локали. В таком случае не лучше ли было бы решить ее на более высоком уровне абстракции? Здесь мы видим, как это сделать.
Описание варианта использования: автоматическое наследование области действия из одного контекста выполнения и внедрение ее в текущий контекст выполнения в качестве параметра.
Детали реализации
Опять же, как и в случае с ведением журнала задач, мы хотим расширить базовый класс задач celery.current_app.Task и переопределить несколько методов, отвечающих за вызов задач. Для этой демонстрации я переопределяю метод celery.current_app.Task::apply_async . Для этого модуля есть дополнительные задачи, которые помогут вам произвести полнофункциональную замену.
Файл: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)Ключевым моментом является передача текущей локали в качестве аргумента ключ-значение в вызывающую задачу по умолчанию. Если задача была вызвана с определенной локалью в качестве аргумента, то она остается неизменной.
Пробуем
Чтобы проверить эту функциональность, давайте определим фиктивную задачу типа ScopeBasedTask . Он находит файл по идентификатору локали и считывает его содержимое в формате JSON:
Файл: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Теперь вам нужно повторить шаги по запуску Celery, запуску оболочки и тестированию выполнения этой задачи в разных сценариях. Фикстуры находятся в celery_uncovered/tricks/fixtures/locales/ .
Заключение
Этот пост был посвящен изучению сельдерея с разных точек зрения. Я продемонстрировал Celery на обычных примерах, таких как рассылка по почте и создание отчетов, а также поделился хитростями с некоторыми интересными нишевыми случаями использования в бизнесе. Celery основан на философии, основанной на данных, и ваша команда может значительно упростить свою жизнь, представив его как часть своего системного стека. Разработка сервисов на основе Celery не очень сложна, если у вас есть базовый опыт работы с Python, и вы сможете довольно быстро освоить его. Конфигурации по умолчанию достаточно для большинства применений, но при необходимости они могут быть очень гибкими.
Наша команда решила использовать Celery в качестве серверной части оркестрации для фоновых и длительных задач. Мы широко используем его для различных вариантов использования, лишь некоторые из которых были упомянуты в этом посте. Каждый день мы получаем и анализируем гигабайты данных, но это только начало методов горизонтального масштабирования.