
การจัดเตรียมเวิร์กโฟลว์งานพื้นหลังใน Celery สำหรับ Python
เผยแพร่แล้ว: 2022-03-11เว็บแอปพลิเคชันสมัยใหม่และระบบพื้นฐานนั้นเร็วและตอบสนองได้ดีกว่าที่เคยเป็นมา อย่างไรก็ตาม ยังมีอีกหลายกรณีที่คุณต้องการลดภาระงานหนักไปยังส่วนอื่น ๆ ของสถาปัตยกรรมระบบทั้งหมดของคุณ แทนที่จะจัดการกับงานเหล่านั้นบนเธรดหลักของคุณ การระบุงานดังกล่าวทำได้ง่ายเพียงแค่ตรวจสอบเพื่อดูว่างานดังกล่าวอยู่ในประเภทใดประเภทหนึ่งต่อไปนี้:
- งานประจำ — งานที่คุณจะกำหนดเวลาให้ทำงานในเวลาที่กำหนดหรือหลังจากช่วงเวลาหนึ่งๆ เช่น การสร้างรายงานรายเดือนหรือเว็บสแครปเปอร์ที่ทำงานวันละสองครั้ง
- งานของบุคคลที่สาม — เว็บแอปต้องให้บริการผู้ใช้อย่างรวดเร็วโดยไม่ต้องรอให้ดำเนินการอื่นให้เสร็จในขณะที่หน้าเว็บโหลด เช่น ส่งอีเมลหรือการแจ้งเตือน หรือเผยแพร่การอัปเดตไปยังเครื่องมือภายใน (เช่น การรวบรวมข้อมูลสำหรับการทดสอบ A/B หรือการบันทึกระบบ ).
- งานระยะยาว — งานที่มีราคาแพงในทรัพยากร ซึ่งผู้ใช้ต้องรอขณะคำนวณผลลัพธ์ เช่น การดำเนินการเวิร์กโฟลว์ที่ซับซ้อน (เวิร์กโฟลว์ DAG) การสร้างกราฟ การลดแผนที่ เช่น งาน และการให้บริการเนื้อหาสื่อ (วิดีโอ เสียง)
วิธีแก้ปัญหาที่ตรงไปตรงมาในการดำเนินการงานพื้นหลังคือการเรียกใช้งานภายในเธรดหรือกระบวนการที่แยกจากกัน Python เป็นภาษาการเขียนโปรแกรมที่สมบูรณ์ของทัวริงในระดับสูง ซึ่งไม่มีการทำงานพร้อมกันในตัวในระดับที่ตรงกับ Erlang, Go, Java, Scala หรือ Akka สิ่งเหล่านี้ขึ้นอยู่กับกระบวนการสื่อสารตามลำดับ (CSP) ของ Tony Hoare ในทางกลับกัน เธรด Python มีการประสานงานและกำหนดเวลาโดยการล็อกตัวแปลทั่วโลก (GIL) ซึ่งป้องกันไม่ให้เธรดดั้งเดิมหลายรายการเรียกใช้ Python bytecodes พร้อมกัน การกำจัด GIL เป็นหัวข้อที่มีการอภิปรายกันมากในหมู่นักพัฒนา Python แต่ไม่ใช่ประเด็นสำคัญของบทความนี้ การเขียนโปรแกรมพร้อมกันใน Python นั้นล้าสมัย แม้ว่าคุณสามารถอ่านเกี่ยวกับมันใน Python Multithreading Tutorial โดย Toptaler Marcus McCurdy ดังนั้น การออกแบบการสื่อสารระหว่างกระบวนการอย่างสม่ำเสมอจึงเป็นกระบวนการที่มักเกิดข้อผิดพลาด และนำไปสู่การจับคู่โค้ดและการบำรุงรักษาระบบที่ไม่ดี และยังส่งผลกระทบในทางลบต่อความสามารถในการปรับขนาด นอกจากนี้ กระบวนการ Python ยังเป็นกระบวนการปกติภายใต้ระบบปฏิบัติการ (OS) และด้วยไลบรารีมาตรฐาน Python ทั้งหมด กระบวนการจะกลายเป็นรุ่นหนา เมื่อจำนวนกระบวนการในแอพเพิ่มขึ้น การเปลี่ยนจากกระบวนการดังกล่าวเป็นกระบวนการอื่นจะกลายเป็นการดำเนินการที่ใช้เวลานาน
เพื่อให้เข้าใจการทำงานพร้อมกันกับ Python ได้ดีขึ้น ให้ชมสุนทรพจน์อันน่าทึ่งของ David Beazley ที่ PyCon'15
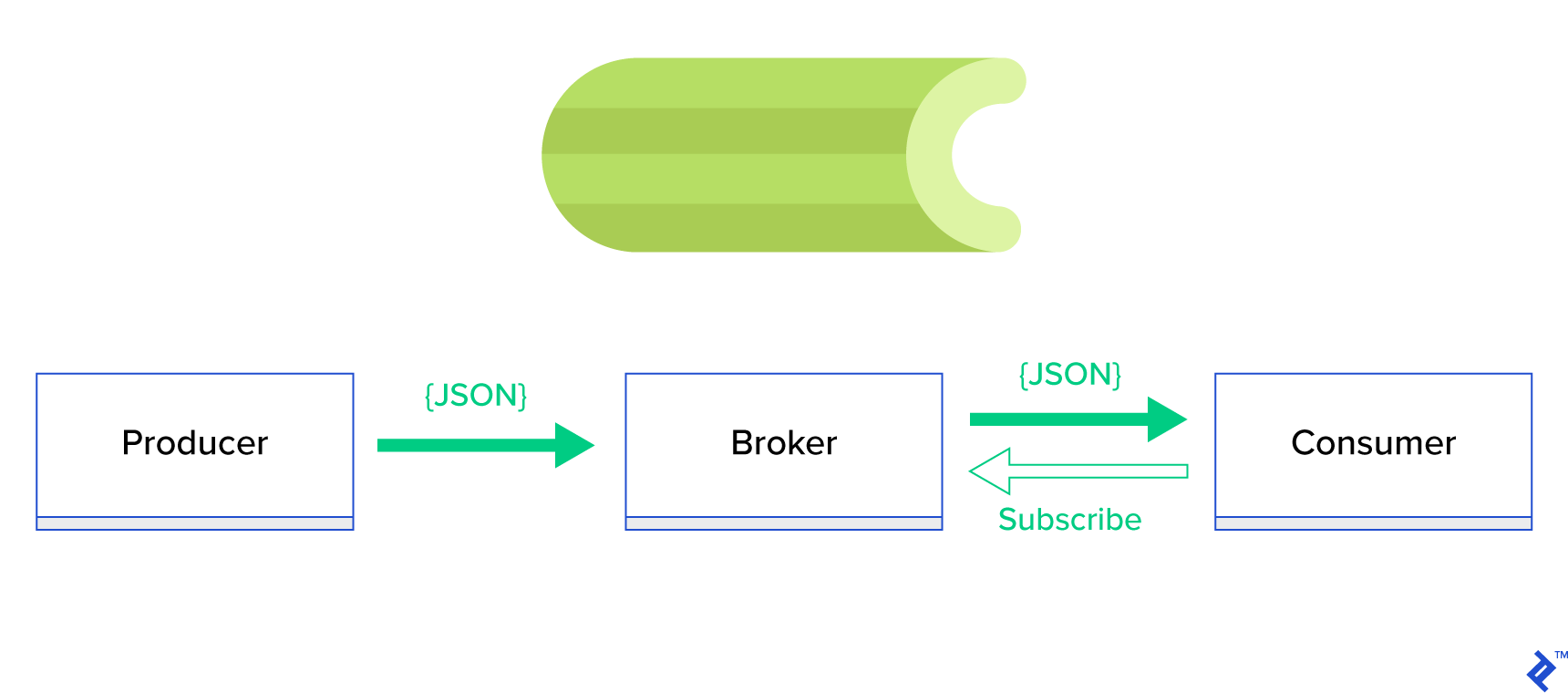
ทางออกที่ดีกว่ามากคือการให้บริการ คิวแบบกระจาย หรือกระบวนทัศน์พี่น้องที่รู้จักกันดีซึ่งเรียกว่า publish-subscribe ดังที่แสดงในรูปที่ 1 มีแอปพลิเคชันสองประเภทซึ่งประเภทหนึ่งเรียกว่าผู้ เผยแพร่ ส่งข้อความ และอีกประเภทหนึ่งเรียกว่า Subscriber รับ ข้อความ เจ้าหน้าที่ทั้งสองไม่ได้โต้ตอบกันโดยตรงและไม่ได้รับรู้ซึ่งกันและกัน ผู้จัดพิมพ์ส่งข้อความไปยังคิวกลาง หรือ นายหน้า และสมาชิกจะได้รับข้อความที่น่าสนใจจากนายหน้ารายนี้ มีข้อดีหลักสองประการในวิธีนี้:
- ความสามารถในการปรับขนาด — ตัวแทนไม่จำเป็นต้องรู้เกี่ยวกับกันและกันในเครือข่าย พวกเขาจะเน้นตามหัวข้อ ดังนั้นจึงหมายความว่าแต่ละเครื่องสามารถทำงานต่อไปได้ตามปกติโดยไม่คำนึงถึงรูปแบบอื่นแบบอะซิงโครนัส
- ข้อต่อหลวม — แต่ละเอเจนต์แสดงถึงส่วนหนึ่งของระบบ (บริการ โมดูล) เนื่องจากพวกมันเชื่อมต่อกันอย่างหลวม ๆ แต่ละอันสามารถปรับขนาดได้นอกเหนือจากดาต้าเซ็นเตอร์
มีระบบการส่งข้อความจำนวนมากที่สนับสนุนกระบวนทัศน์ดังกล่าวและจัดเตรียม API ที่เรียบร้อย ซึ่งขับเคลื่อนโดยโปรโตคอล TCP หรือ HTTP เช่น JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ เป็นต้น
คื่นฉ่ายคืออะไร?
คื่นฉ่ายเป็นหนึ่งในผู้จัดการงานเบื้องหลังที่ได้รับความนิยมมากที่สุดในโลกของ Python คื่นฉ่ายเข้ากันได้กับตัวรับส่งข้อความหลายตัวเช่น RabbitMQ หรือ Redis และสามารถทำหน้าที่เป็นทั้งผู้ผลิตและผู้บริโภค
คื่นฉ่ายเป็นคิวงานแบบอะซิงโครนัส/คิวงานตามการส่งข้อความแบบกระจาย มุ่งเน้นไปที่การดำเนินการตามเวลาจริง แต่รองรับการตั้งเวลาเช่นกัน หน่วยการดำเนินการ เรียกว่างาน ถูกดำเนินการพร้อมกันบนเซิร์ฟเวอร์ของผู้ปฏิบัติงานตั้งแต่หนึ่งเซิร์ฟเวอร์ขึ้นไปโดยใช้การประมวลผลหลายตัว, Eventlet หรือ gevent งานสามารถดำเนินการแบบอะซิงโครนัส (ในพื้นหลัง) หรือแบบซิงโครนัส (รอจนกว่าจะพร้อม) – โครงการขึ้นฉ่ายฝรั่ง
ในการเริ่มต้นใช้งาน Celery เพียงทำตามคำแนะนำทีละขั้นตอนที่เอกสารอย่างเป็นทางการ
จุดเน้นของบทความนี้คือการช่วยให้คุณเข้าใจถึงกรณีการใช้งานที่คื่นฉ่ายสามารถครอบคลุมได้ ในบทความนี้ เราจะไม่เพียงแค่แสดงตัวอย่างที่น่าสนใจเท่านั้น แต่ยังพยายามเรียนรู้วิธีใช้ Celery กับงานจริง เช่น การส่งจดหมายในเบื้องหลัง การสร้างรายงาน การบันทึก และการรายงานข้อผิดพลาด ฉันจะแบ่งปันวิธีการทดสอบงานของฉันนอกเหนือจากการจำลอง และสุดท้าย ฉันจะให้เทคนิคบางอย่างที่ไม่ได้บันทึกไว้ในเอกสารอย่างเป็นทางการ ซึ่งใช้เวลาหลายชั่วโมงในการค้นคว้าเพื่อค้นหาตัวเอง
หากคุณไม่เคยมีประสบการณ์กับ Celery มาก่อน เราขอแนะนำให้คุณลองทำตามบทแนะนำอย่างเป็นทางการก่อน
กระตุ้นความอยากอาหารของคุณ
หากบทความนี้ทำให้คุณสนใจและทำให้คุณอยากดำดิ่งลงไปในโค้ดทันที ให้ทำตามที่เก็บ GitHub นี้สำหรับโค้ดที่ใช้ในบทความนี้ README จะมีวิธีการที่รวดเร็วและสกปรกในการรันและเล่นกับแอปพลิเคชันตัวอย่าง
ก้าวแรกกับคื่นฉ่าย
สำหรับผู้เริ่มต้น เราจะพูดถึงชุดตัวอย่างที่ใช้งานได้จริง ซึ่งจะแสดงให้ผู้อ่านเห็นว่า Celery แก้ปัญหาที่ดูเรียบง่ายและสง่างามได้อย่างไร ตัวอย่างทั้งหมดจะถูกนำเสนอภายในกรอบงานของ Django อย่างไรก็ตาม ส่วนใหญ่สามารถย้ายไปยังเฟรมเวิร์ก Python อื่นได้อย่างง่ายดาย (Flask, Pyramid)
เค้าโครงโครงการสร้างโดย Cookiecutter Django; อย่างไรก็ตาม ฉันเก็บการขึ้นต่อกันเพียงไม่กี่อย่าง ซึ่งในความคิดของฉัน อำนวยความสะดวกในการพัฒนาและเตรียมกรณีการใช้งานเหล่านี้ ฉันยังลบโมดูลที่ไม่จำเป็นสำหรับโพสต์และแอปพลิเคชันนี้เพื่อลดเสียงรบกวนและทำให้โค้ดเข้าใจได้ง่ายขึ้น
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}มีแอปพลิเคชันต่างๆ ที่เราจะกล่าวถึงในโพสต์นี้ แต่ละแอปพลิเคชันประกอบด้วยชุดตัวอย่างที่จัดเรียงตามระดับความเข้าใจของคื่นฉ่ายที่ต้องการ -
celery_uncovered/celery.pyกำหนดอินสแตนซ์ของ Celery
ไฟล์: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() จากนั้นเราต้องมั่นใจว่า Celery จะเริ่มต้นพร้อมกับ Django ด้วยเหตุผลดังกล่าว เราจึงนำเข้าแอปใน celery_uncovered/__init__.py
ไฟล์: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings เป็นแหล่งที่มาของการกำหนดค่าสำหรับแอพและ Celery ของเรา ขึ้นอยู่กับสภาพแวดล้อมการทำงาน Django จะเปิดการตั้งค่าที่เกี่ยวข้อง: local.py สำหรับการพัฒนา หรือ test.py สำหรับการทดสอบ คุณยังสามารถกำหนดสภาพแวดล้อมของคุณเองได้หากต้องการโดยการสร้างโมดูลหลามใหม่ (เช่น prod.py ) การกำหนดค่าคื่นฉ่ายนำหน้าด้วย CELERY_ สำหรับโพสต์นี้ ฉันกำหนดค่า RabbitMQ เป็นนายหน้าและ SQLite เป็นผลลัพธ์ bac-end
ไฟล์: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'สถานการณ์ที่ 1 - การสร้างและส่งออกรายงาน
กรณีแรกที่เราจะกล่าวถึงคือการสร้างและส่งออกรายงาน ในตัวอย่างนี้ คุณจะได้เรียนรู้วิธีกำหนดงานที่สร้างรายงาน CSV และจัดกำหนดการตามช่วงเวลาปกติด้วย celerybeat
ใช้คำอธิบายกรณี: ดึงที่เก็บที่ร้อนแรงที่สุดห้าร้อยแห่งจาก GitHub ต่อช่วงเวลาที่เลือก (วัน สัปดาห์ เดือน) จัดกลุ่มตามหัวข้อ และส่งออกผลลัพธ์ไปยังไฟล์ CSV
หากเราให้บริการ HTTP ที่จะเรียกใช้คุณลักษณะนี้โดยคลิกที่ปุ่ม "สร้างรายงาน" แอปพลิเคชันจะหยุดและรอให้งานเสร็จสิ้นก่อนที่จะส่งการตอบกลับ HTTP กลับ นี้ไม่ดี. เราต้องการให้เว็บแอปพลิเคชันของเราทำงานได้อย่างรวดเร็ว และไม่ต้องการให้ผู้ใช้รอในขณะที่ส่วนหลังของเรากำลังคำนวณผลลัพธ์ แทนที่จะรอให้สร้างผลลัพธ์ เราค่อนข้างจะจัดคิวงานให้กับกระบวนการของผู้ปฏิบัติงานผ่านคิวที่ลงทะเบียนใน Celery และตอบกลับด้วย task_id ที่ส่วนหน้า จากนั้น front-end จะใช้ task_id เพื่อสอบถามผลลัพธ์ของงานในรูปแบบอะซิงโครนัส (เช่น AJAX) และจะแจ้งให้ผู้ใช้อัปเดตด้วยความคืบหน้าของงาน สุดท้าย เมื่อกระบวนการเสร็จสิ้น ผลลัพธ์สามารถทำหน้าที่เป็นไฟล์เพื่อดาวน์โหลดผ่าน HTTP
รายละเอียดการใช้งาน
ก่อนอื่น ให้เราแยกกระบวนการออกเป็นหน่วยที่เล็กที่สุดและสร้างไปป์ไลน์:
- Fetchers คือพนักงานที่รับผิดชอบในการรับที่เก็บจากบริการ GitHub
- ผู้ รวบรวม คือผู้ปฏิบัติงานที่รับผิดชอบในการรวมผลลัพธ์ไว้ในรายการเดียว
- ผู้นำเข้า คือพนักงานที่สร้างรายงาน CSV ของที่เก็บที่ร้อนแรงที่สุดใน GitHub
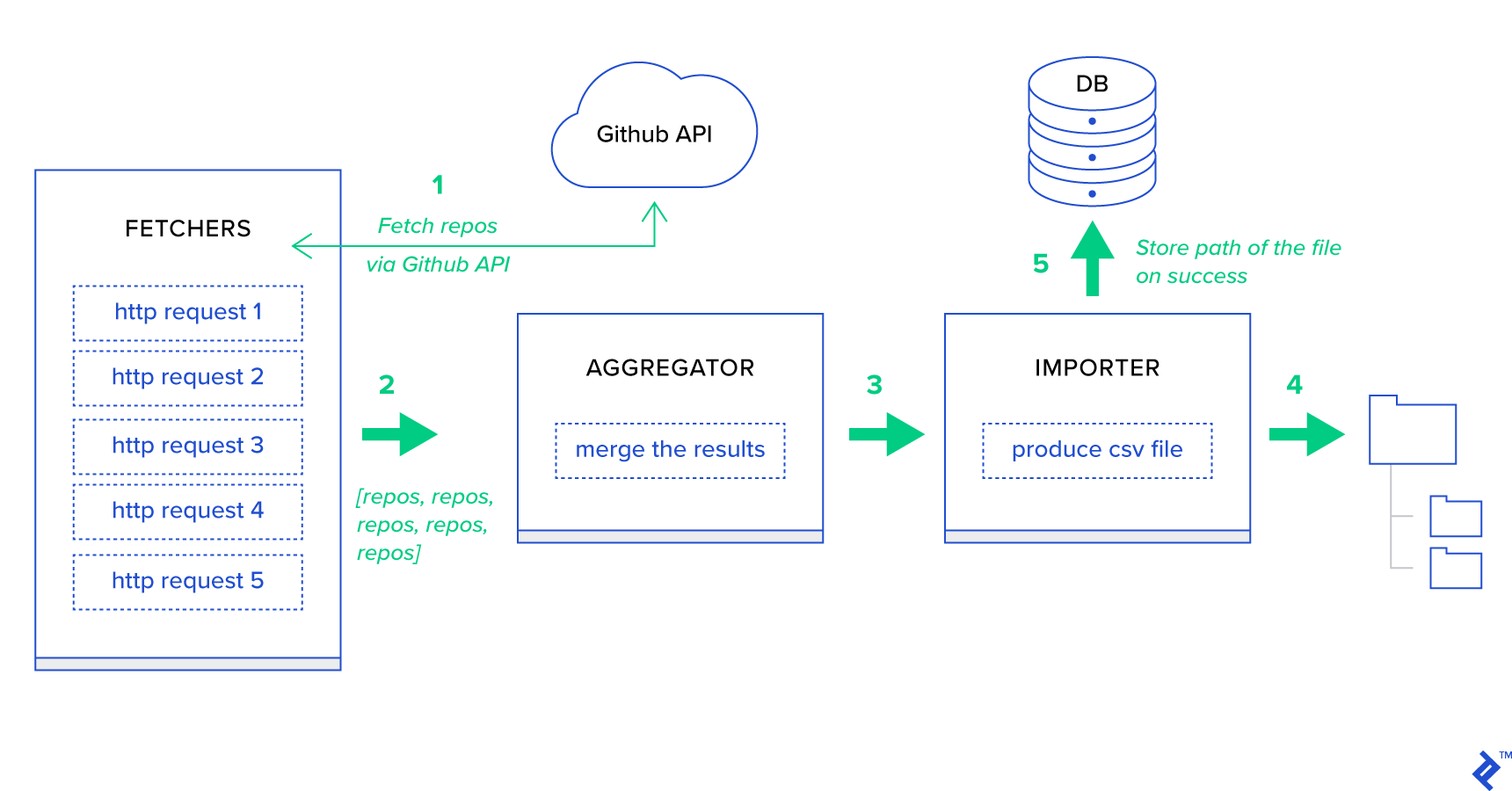
การดึงที่เก็บเป็นคำขอ HTTP โดยใช้ GitHub Search API GET /search/repositories อย่างไรก็ตาม มีข้อจำกัดของบริการ GitHub API ที่ควรได้รับการจัดการ: API จะส่งคืนที่เก็บ 100 รายการต่อคำขอแทนที่จะเป็น 500 รายการ เราสามารถส่งคำขอได้ครั้งละห้าคำขอ แต่เราไม่ต้องการให้ผู้ใช้รอ สำหรับห้าคำขอแต่ละรายการ เนื่องจากคำขอ HTTP เป็นการดำเนินการที่ผูกไว้กับ I/O แต่เราสามารถดำเนินการร้องขอ HTTP พร้อมกันห้ารายการด้วยพารามิเตอร์เพจที่เหมาะสม ดังนั้นหน้าจะอยู่ในช่วง [1..5] มากำหนดงานที่เรียกว่า fetch_hot_repos/3 -> list ในโมดูล toyex/tasks.py :
ไฟล์: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items ดังนั้น fetch_hot_repos จะสร้างคำขอไปยัง GitHub API และตอบสนองต่อผู้ใช้ด้วยรายการที่เก็บ ได้รับพารามิเตอร์สามตัวที่จะกำหนด payload คำขอของเรา:
-
since— กรองที่เก็บในวันที่สร้าง -
per_page— จำนวนผลลัพธ์ที่ส่งคืนต่อคำขอ (จำกัด 100) -
page—- หมายเลขหน้าที่ร้องขอ (อยู่ในช่วง [1..5])
หมายเหตุ: ในการใช้ GitHub Search API คุณจะต้องใช้โทเค็น OAuth เพื่อผ่านการตรวจสอบสิทธิ์ ในกรณีของเรา มันถูกบันทึกไว้ในการตั้งค่าภายใต้ GITHUB_OAUTH
ต่อไป เราต้องกำหนดงานหลักที่จะรับผิดชอบในการรวมผลลัพธ์และส่งออกเป็นไฟล์ CSV: produce_hot_repo_report_task/2->filepath:
ไฟล์: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) งานนี้ใช้ celery.canvas.group เพื่อดำเนินการเรียก fetch_hot_repos/3 พร้อมกันห้าครั้ง ผลลัพธ์เหล่านั้นจะรอและลดลงเป็นรายการของอ็อบเจ็กต์ที่เก็บ จากนั้น ชุดผลลัพธ์ของเราจะถูกจัดกลุ่มตามหัวข้อ และสุดท้ายส่งออกไปยังไฟล์ CSV ที่สร้างขึ้นภายใต้ MEDIA_ROOT/
ในการกำหนดเวลางานเป็นระยะ คุณอาจต้องการเพิ่มรายการลงในรายการกำหนดการในไฟล์การกำหนดค่า:
ไฟล์: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }ลองเลย
ในการเริ่มและทดสอบว่างานทำงานอย่างไร อันดับแรก เราต้องเริ่มกระบวนการคื่นฉ่าย:
$ celery -A celery_uncovered worker -l info ต่อไป เราต้องสร้าง celery_uncovered/media/ จากนั้น คุณจะสามารถทดสอบการทำงานของมันผ่าน Shell หรือ Celerybeat:
เชลล์ :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)คื่นฉ่าย :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info คุณสามารถดูผลลัพธ์ภายใต้ MEDIA_ROOT/
สถานการณ์ที่ 2 - รายงานข้อผิดพลาด 500 เซิร์ฟเวอร์ ผ่านอีเมล
กรณีการใช้งานทั่วไปสำหรับ Celery คือการส่งการแจ้งเตือนทางอีเมล การแจ้งเตือนทางอีเมลเป็นการดำเนินการที่ผูกไว้กับ I/O แบบออฟไลน์ซึ่งใช้ประโยชน์จากเซิร์ฟเวอร์ SMTP ในเครื่องหรือ SES ของบุคคลที่สาม มีหลายกรณีการใช้งานที่เกี่ยวข้องกับการส่งอีเมล และสำหรับกรณีส่วนใหญ่ ผู้ใช้ไม่จำเป็นต้องรอจนกว่ากระบวนการนี้จะเสร็จสิ้นก่อนที่จะได้รับการตอบกลับ HTTP นั่นเป็นเหตุผลว่าทำไมจึงต้องการดำเนินการดังกล่าวในพื้นหลังและตอบกลับผู้ใช้ทันที
ใช้คำอธิบายกรณี: รายงานข้อผิดพลาด 50X ไปยังอีเมลผู้ดูแลระบบผ่าน Celery
Python และ Django มีพื้นหลังที่จำเป็นในการบันทึกระบบ ฉันจะไม่ลงรายละเอียดว่าการบันทึกของ Python ทำงานอย่างไร อย่างไรก็ตาม หากคุณไม่เคยลองใช้มาก่อนหรือต้องการทบทวน ให้อ่านเอกสารประกอบของโมดูลการบันทึกในตัว คุณต้องการสิ่งนี้ในสภาพแวดล้อมการผลิตของคุณอย่างแน่นอน Django มีตัวจัดการบันทึกพิเศษที่เรียกว่า AdminEmailHandler ซึ่งจะส่งอีเมลถึงผู้ดูแลระบบสำหรับแต่ละข้อความบันทึกที่ได้รับ
รายละเอียดการใช้งาน
แนวคิดหลักคือการขยายเมธอด send_mail ของคลาส AdminEmailHandler เพื่อให้สามารถส่งเมลผ่าน Celery ได้ สามารถทำได้ตามภาพประกอบด้านล่าง:
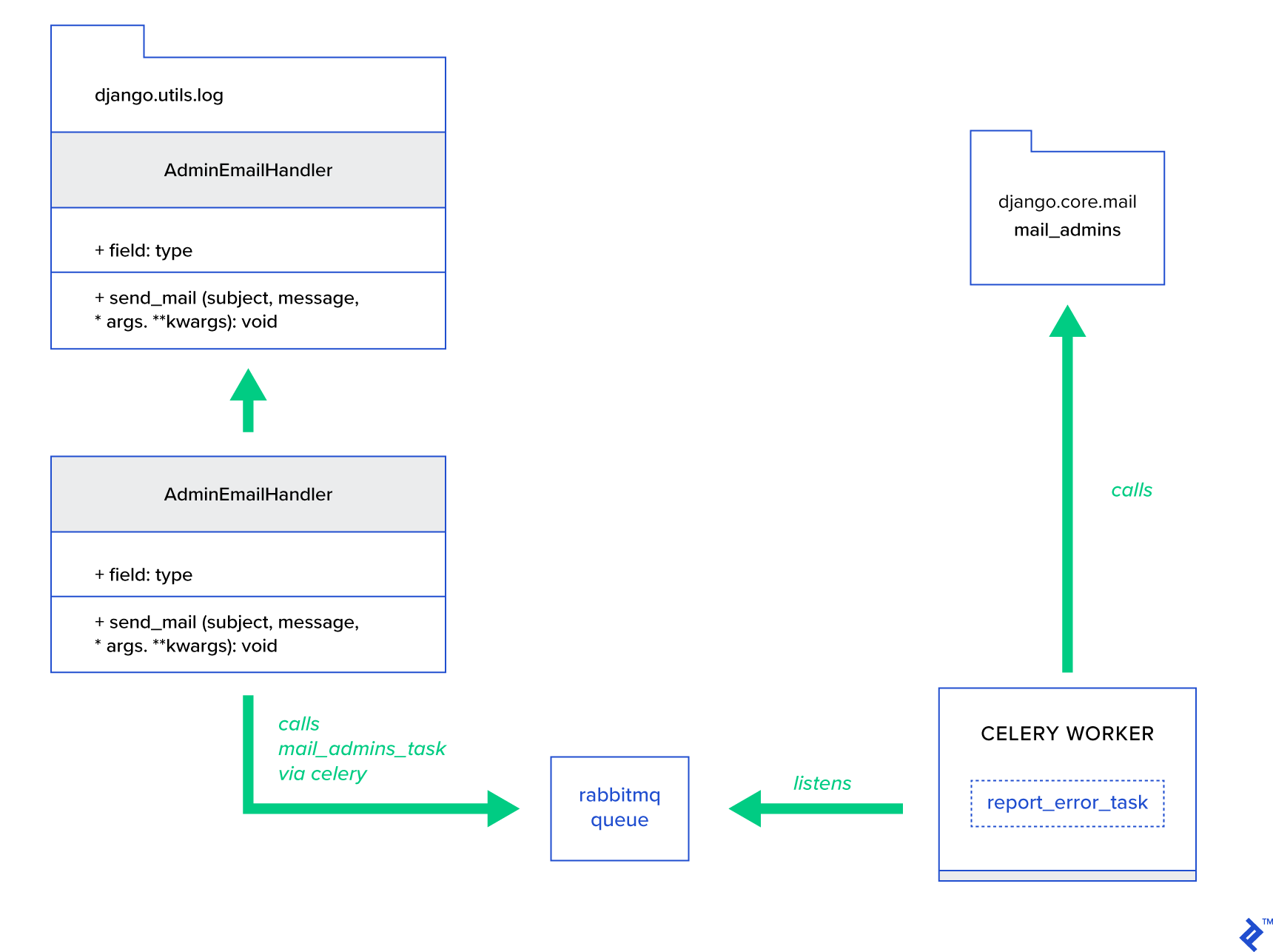
อันดับแรก เราต้องตั้งค่างานที่เรียกว่า report_error_task ซึ่งเรียก mail_admins ด้วยหัวเรื่องและข้อความที่ให้มา:
ไฟล์: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)ต่อไป เราขยาย AdminEmailHandler เพื่อให้เรียกเฉพาะงาน Celery ที่กำหนดไว้ภายใน:
ไฟล์: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) สุดท้าย เราต้องตั้งค่าการบันทึก การกำหนดค่าการบันทึกใน Django ค่อนข้างตรงไปตรงมา สิ่งที่คุณต้องการคือการแทนที่ LOGGING เพื่อให้เอ็นจิ้นการบันทึกเริ่มทำงานโดยใช้ตัวจัดการที่กำหนดไว้ใหม่:
ไฟล์ config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } ขอให้สังเกตว่าฉันตั้งใจตั้งค่าตัวกรองตัวจัดการ require_debug_true เพื่อทดสอบการทำงานนี้ในขณะที่แอปพลิเคชันกำลังทำงานในโหมดแก้ไขข้อบกพร่อง
ลองเลย
เพื่อทดสอบ ฉันได้เตรียมมุมมอง Django ที่ให้บริการการดำเนินการ "หารด้วยศูนย์" ที่ localhost:8000/report-error คุณต้องเริ่มคอนเทนเนอร์ MailHog Docker เพื่อทดสอบว่าอีเมลนั้นถูกส่งจริงหรือไม่
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)รายละเอียดเพิ่มเติม
ในฐานะเครื่องมือทดสอบเมล ฉันตั้งค่า MailHog และกำหนดค่า Django mailing เพื่อใช้สำหรับการจัดส่ง SMTP มีหลายวิธีในการปรับใช้และเรียกใช้ MailHog ฉันตัดสินใจที่จะไปกับคอนเทนเนอร์ Docker คุณสามารถค้นหารายละเอียดในไฟล์ README ที่เกี่ยวข้อง:
ไฟล์: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025ในการกำหนดค่าแอปพลิเคชันของคุณให้ใช้ MailHog คุณต้องเพิ่มบรรทัดต่อไปนี้ในการกำหนดค่าของคุณ:
ไฟล์: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')นอกเหนือจากงานคื่นฉ่ายเริ่มต้น
งานคื่นฉ่ายสามารถสร้างขึ้นจากฟังก์ชันที่เรียกได้ โดยค่าเริ่มต้น งานที่ผู้ใช้กำหนดจะถูกฉีดด้วย celery.app.task.Task เป็นคลาสพาเรนต์ (นามธรรม) คลาสนี้มีฟังก์ชันการทำงานแบบอะซิงโครนัส (ส่งผ่านเครือข่ายไปยังพนักงานของ Celery) หรือแบบซิงโครนัส (เพื่อวัตถุประสงค์ในการทดสอบ) การสร้างลายเซ็นและยูทิลิตี้อื่น ๆ อีกมากมาย ในตัวอย่างต่อไป เราจะพยายามขยาย Celery.app.task.Task แล้วใช้เป็นคลาสพื้นฐานเพื่อเพิ่มพฤติกรรมที่เป็นประโยชน์บางอย่างให้กับงานของเรา
สถานการณ์ที่ 3 - การบันทึกไฟล์ต่องาน
ในโครงการหนึ่งของฉัน ฉันกำลังพัฒนาแอพที่ให้ผู้ใช้ปลายทางด้วยเครื่องมือ Extract, Transform, Load (ETL) ที่สามารถนำเข้าแล้วกรองข้อมูลแบบลำดับชั้นจำนวนมาก ส่วนหลังถูกแบ่งออกเป็นสองโมดูล:
- การประสานของไปป์ไลน์การประมวลผลข้อมูลด้วย Celery
- การประมวลผลข้อมูลด้วย Go
คื่นฉ่ายถูกนำไปใช้กับ Celerybeat หนึ่งอินสแตนซ์และพนักงานมากกว่า 40 คน มีงานมากกว่า 20 งานที่แตกต่างกันซึ่งประกอบไปด้วยกิจกรรมไปป์ไลน์และการประสาน แต่ละงานดังกล่าวอาจล้มเหลวในบางจุด ความล้มเหลวทั้งหมดเหล่านี้ถูกทิ้งลงในบันทึกของระบบของผู้ปฏิบัติงานแต่ละคน เมื่อถึงจุดหนึ่ง มันเริ่มไม่สะดวกที่จะดีบักและรักษาเลเยอร์คื่นฉ่าย ในที่สุด เราตัดสินใจแยกบันทึกของงานไปยังไฟล์เฉพาะของงาน
ใช้คำอธิบายเคส: ขยาย Celery เพื่อให้แต่ละงานบันทึกเอาต์พุตมาตรฐานและข้อผิดพลาดไปยังไฟล์
Celery ให้แอปพลิเคชั่น Python ควบคุมสิ่งที่มันทำภายในได้ดีเยี่ยม มันมาพร้อมกับกรอบสัญญาณที่คุ้นเคย แอปพลิเคชันที่ใช้ Celery สามารถสมัครรับข้อมูลบางส่วนเพื่อเพิ่มพฤติกรรมของการกระทำบางอย่าง เรากำลังจะใช้สัญญาณระดับงานเพื่อให้การติดตามวงจรชีวิตของงานแต่ละรายการอย่างละเอียด คื่นฉ่ายมาพร้อมกับแบ็คเอนด์การบันทึกเสมอ และเราจะใช้ประโยชน์จากมันในขณะที่เอาชนะเพียงเล็กน้อยในที่ไม่กี่แห่งเพื่อให้บรรลุเป้าหมายของเรา
รายละเอียดการใช้งาน
คื่นฉ่ายรองรับการบันทึกต่องานแล้ว ในการบันทึกลงในไฟล์ จำเป็นต้องส่งเอาต์พุตบันทึกไปยังตำแหน่งที่เหมาะสม ในกรณีของเรา ตำแหน่งที่เหมาะสมของงานคือไฟล์ที่ตรงกับชื่องาน ในอินสแตนซ์ Celery เราจะแทนที่การกำหนดค่าการบันทึกในตัวด้วยตัวจัดการการบันทึกที่สรุปแบบไดนามิก เป็นไปได้ที่จะสมัครสัญญาณ celeryd_after_setup จากนั้นกำหนดค่าการบันทึกระบบที่นั่น:
ไฟล์: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) ขอให้สังเกตว่าสำหรับแต่ละงานที่ลงทะเบียนในแอป Celery เรากำลังสร้างตัวบันทึกที่สอดคล้องกันพร้อมตัวจัดการ ตัวจัดการแต่ละตัวเป็นประเภท logging.FileHandler ดังนั้นแต่ละอินสแตนซ์ดังกล่าวจึงได้รับชื่อไฟล์เป็นอินพุต สิ่งที่คุณต้องทำคือนำเข้าโมดูลนี้ไปที่ celery_uncovered/celery.py ที่ส่วนท้ายของไฟล์:
import celery_uncovered.tricks.celery_conf สามารถรับตัวบันทึกงานเฉพาะได้โดยการเรียก get_task_logger(task_name) เพื่อที่จะสรุปพฤติกรรมดังกล่าวสำหรับแต่ละงาน จำเป็นต้องขยาย celery.current_app.Task เล็กน้อยด้วยวิธีการยูทิลิตี้สองสามวิธี:
ไฟล์: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) ตอนนี้ ในกรณีของการเรียกไปยัง task.log_msg("Hello, my name is: %s", task.request.id) เอาต์พุตบันทึกจะถูกส่งไปยังไฟล์ที่เกี่ยวข้องภายใต้ชื่องาน
ลองเลย
ในการเริ่มและทดสอบว่างานนี้ทำงานอย่างไร ให้เริ่มกระบวนการคื่นฉ่ายก่อน:
$ celery -A celery_uncovered worker -l infoจากนั้นคุณจะสามารถทดสอบการทำงานผ่านเชลล์:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) สุดท้าย หากต้องการดูผลลัพธ์ ให้ไปที่ celery_uncovered/logs และเปิดไฟล์บันทึกที่เกี่ยวข้องที่เรียกว่า celery_uncovered.tricks.tasks.add.log คุณอาจเห็นสิ่งที่คล้ายกันด้านล่างหลังจากเรียกใช้งานนี้หลายครั้ง:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...สถานการณ์ที่ 4 - งานที่ต้องคำนึงถึงขอบเขต
ให้เราจินตนาการถึงแอปพลิเคชั่น Python สำหรับผู้ใช้ต่างประเทศที่สร้างขึ้นบน Celery และ Django ผู้ใช้สามารถตั้งค่าภาษา (ท้องถิ่น) ที่พวกเขาใช้แอปพลิเคชันของคุณได้
คุณต้องออกแบบระบบการแจ้งเตือนทางอีเมลที่ทราบถึงสถานที่หลายภาษา ในการส่งการแจ้งเตือนทางอีเมล คุณได้ลงทะเบียนงาน Celery พิเศษที่ได้รับการจัดการโดยคิวเฉพาะ งานนี้ได้รับอาร์กิวเมนต์หลักเป็นอินพุตและตำแหน่งที่ตั้งของผู้ใช้ปัจจุบัน เพื่อที่อีเมลจะถูกส่งไปในภาษาที่ผู้ใช้เลือก
ลองนึกภาพว่าเรามีงานดังกล่าวมากมาย แต่งานแต่ละงานนั้นยอมรับอาร์กิวเมนต์ของสถานที่ ในกรณีนี้ จะดีกว่าไหมที่จะแก้ปัญหาในระดับนามธรรมที่สูงกว่า ที่นี่เราเห็นวิธีการทำเช่นนั้น
ใช้คำอธิบายเคส: สืบทอดขอบเขตโดยอัตโนมัติจากบริบทการดำเนินการหนึ่งรายการ และแทรกลงในบริบทการดำเนินการปัจจุบันเป็นพารามิเตอร์
รายละเอียดการใช้งาน
อีกครั้ง เช่นเดียวกับที่เราทำกับการบันทึกงาน เราต้องการขยายคลาสงานพื้นฐาน celery.current_app.Task และแทนที่วิธีการสองสามอย่างที่รับผิดชอบในการเรียกงาน เพื่อการสาธิตนี้ ฉันกำลังแทนที่ celery.current_app.Task::apply_async มีงานเพิ่มเติมสำหรับโมดูลนี้ที่จะช่วยให้คุณผลิตชิ้นส่วนทดแทนที่ทำงานได้อย่างสมบูรณ์
ไฟล์: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)เงื่อนงำสำคัญคือการส่งผ่านโลแคลปัจจุบันเป็นอาร์กิวเมนต์ของคีย์-ค่าในงานที่เรียกโดยค่าเริ่มต้น หากมีการเรียกงานด้วยสถานที่ที่แน่นอนเป็นอาร์กิวเมนต์ งานนั้นจะไม่เปลี่ยนแปลง
ลองเลย
เพื่อทดสอบการทำงานนี้ ให้เรากำหนดงานจำลองประเภท ScopeBasedTask มันค้นหาไฟล์ตามรหัสสถานที่และอ่านเนื้อหาเป็น JSON:
ไฟล์: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) ตอนนี้สิ่งที่คุณต้องทำคือทำซ้ำขั้นตอนในการเปิดใช้ Celery เริ่มการทำงานของเชลล์ และทดสอบการดำเนินการของงานนี้ในสถานการณ์ต่างๆ ฟิกซ์เจอร์จะอยู่ใต้ celery_uncovered/tricks/fixtures/locales/
บทสรุป
โพสต์นี้มีวัตถุประสงค์เพื่อสำรวจคื่นฉ่ายจากมุมมองที่ต่างกัน ฉันสาธิตคื่นฉ่ายในตัวอย่างทั่วไป เช่น การส่งจดหมายและการสร้างรายงาน ตลอดจนเคล็ดลับที่แบ่งปันให้กับกรณีการใช้งานเฉพาะกลุ่มธุรกิจที่น่าสนใจ คื่นฉ่ายสร้างขึ้นจากปรัชญาที่ขับเคลื่อนด้วยข้อมูล และทีมของคุณอาจทำให้ชีวิตของพวกเขาง่ายขึ้นมากด้วยการแนะนำมันให้เป็นส่วนหนึ่งของสแต็กระบบของพวกเขา การพัฒนาบริการที่ใช้ Celery นั้นไม่ซับซ้อนมากนักหากคุณมีประสบการณ์เกี่ยวกับ Python ขั้นพื้นฐาน และคุณจะสามารถรับมันได้อย่างรวดเร็ว การกำหนดค่าเริ่มต้นนั้นดีเพียงพอสำหรับการใช้งานส่วนใหญ่ แต่ถ้าจำเป็น การกำหนดค่าเหล่านี้อาจยืดหยุ่นได้มาก
ทีมงานของเราได้เลือกใช้ Celery เป็นแบ็คเอนด์การประสานสำหรับงานพื้นหลังและงานที่ดำเนินมายาวนาน เราใช้อย่างกว้างขวางสำหรับกรณีการใช้งานที่หลากหลาย ซึ่งมีการกล่าวถึงเพียงไม่กี่รายการในโพสต์นี้ เรานำเข้าและวิเคราะห์ข้อมูลกิกะไบต์ทุกวัน แต่นี่เป็นเพียงจุดเริ่มต้นของเทคนิคการปรับขนาดแนวนอนเท่านั้น