
Orchestrarea unui flux de lucru de fundal în Celery pentru Python
Publicat: 2022-03-11Aplicațiile web moderne și sistemele lor subiacente sunt mai rapide și mai receptive decât oricând. Cu toate acestea, există încă multe cazuri în care doriți să descărcați execuția unei sarcini grele în alte părți ale întregii arhitecturi de sistem, în loc să le abordați pe firul principal. Identificarea unor astfel de sarcini este la fel de simplă ca și verificarea pentru a vedea dacă aparțin uneia dintre următoarele categorii:
- Sarcini periodice — Lucrări pe care le veți programa să ruleze la o anumită oră sau după un interval, de exemplu, generarea de rapoarte lunare sau un web scraper care rulează de două ori pe zi.
- Sarcini de la terți — Aplicația web trebuie să servească rapid utilizatorilor, fără a aștepta finalizarea altor acțiuni în timp ce pagina se încarcă, de exemplu, trimiterea unui e-mail sau notificare sau propagarea actualizărilor la instrumentele interne (cum ar fi colectarea de date pentru testarea A/B sau înregistrarea sistemului ).
- Lucrări de lungă durată — Lucrări care sunt costisitoare în resurse, în care utilizatorii trebuie să aștepte în timp ce își calculează rezultatele, de exemplu, execuția unui flux de lucru complex (fluxuri de lucru DAG), generarea de grafice, sarcini similare cu Map-Reduce și difuzarea conținutului media (video, audio).
O soluție simplă pentru a executa o sarcină de fundal ar fi rularea acesteia într-un fir sau proces separat. Python este un limbaj de programare complet Turing de nivel înalt, care, din păcate, nu oferă concurență încorporată la o scară care să se potrivească cu cea a Erlang, Go, Java, Scala sau Akka. Acestea se bazează pe Procesele secvențiale de comunicare (CSP) ale lui Tony Hoare. Firele Python, pe de altă parte, sunt coordonate și programate de blocarea globală a interpretului (GIL), care împiedică mai multe fire de execuție native să execute coduri de octeți Python simultan. A scăpa de GIL este un subiect de multe discuții în rândul dezvoltatorilor Python, dar nu este punctul central al acestui articol. Programarea concomitentă în Python este de modă veche, deși sunteți binevenit să citiți despre aceasta în Tutorialul Python Multithreading de la colegul Toptaler Marcus McCurdy. Deci, proiectarea comunicării între procese în mod consecvent este un proces predispus la erori și duce la cuplarea codului și la mentenabilitatea proastă a sistemului, ca să nu mai vorbim că afectează negativ scalabilitatea. În plus, procesul Python este un proces normal sub un sistem de operare (OS) și, cu întreaga bibliotecă standard Python, devine o greutate grea. Pe măsură ce numărul de procese din aplicație crește, trecerea de la un astfel de proces la altul devine o operațiune care necesită timp.
Pentru a înțelege mai bine concurența cu Python, urmăriți acest discurs incredibil al lui David Beazley la PyCon'15.
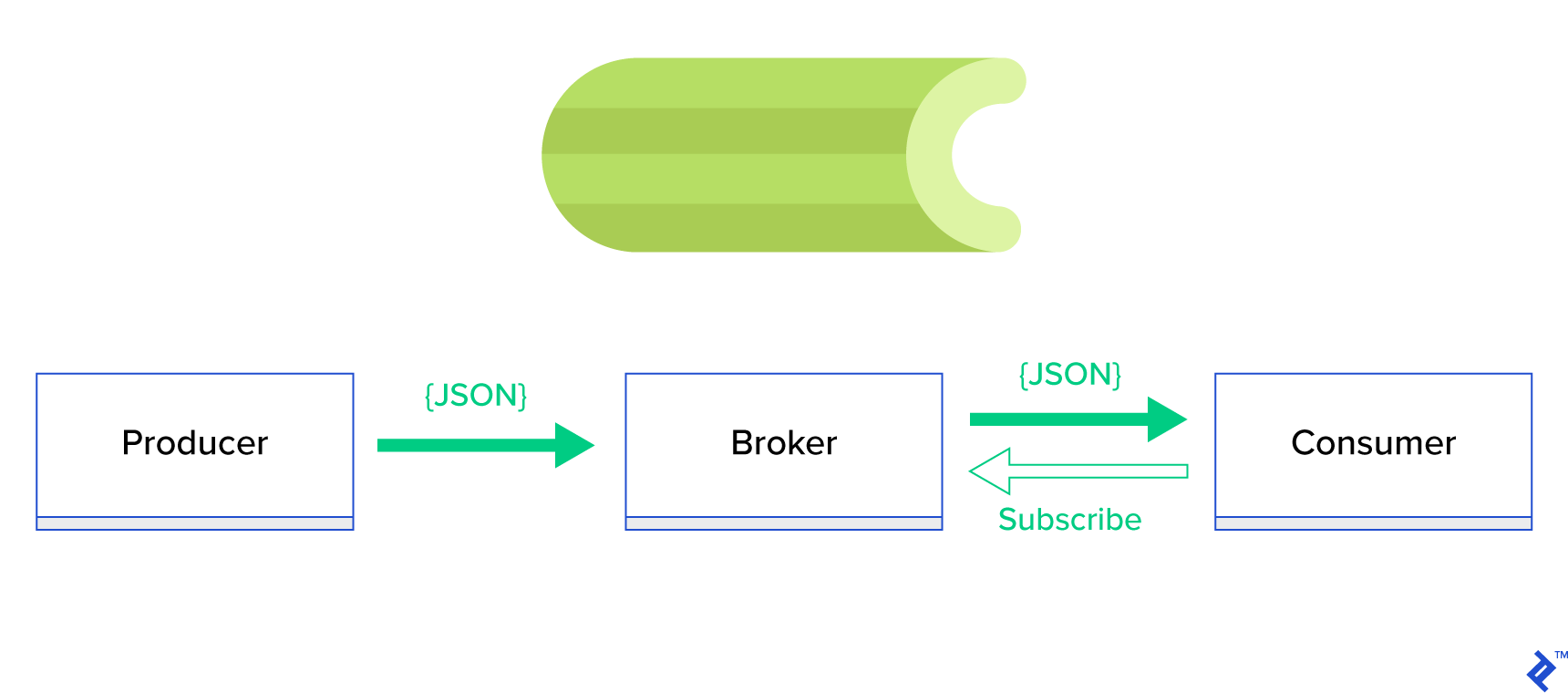
O soluție mult mai bună este de a servi o coadă distribuită sau binecunoscuta paradigmă de frați numită publish-subscribe . După cum este prezentat în Figura 1, există două tipuri de aplicații în care una, numită editor , trimite mesaje, iar cealaltă, numită abonat , primește mesaje. Acei doi agenți nu interacționează direct unul cu celălalt și nici măcar nu sunt conștienți unul de celălalt. Editorii trimit mesaje către o coadă centrală, sau broker , iar abonații primesc mesaje de interes de la acest broker. Există două avantaje principale în această metodă:
- Scalabilitate — agenții nu trebuie să cunoască unul despre celălalt în rețea. Ele sunt concentrate pe subiect. Deci înseamnă că fiecare poate continua să funcționeze normal, indiferent de celălalt, în mod asincron.
- Cuplaj liber - fiecare agent reprezintă partea sa din sistem (serviciu, modul). Deoarece sunt cuplate slab, fiecare se poate scala individual dincolo de centrul de date.
Există o mulțime de sisteme de mesagerie care acceptă astfel de paradigme și oferă un API ordonat, condus fie de protocoale TCP, fie HTTP, de exemplu, JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ etc.
Ce este țelina?
Țelina este unul dintre cei mai populari manageri de locuri de muncă din lumea Python. Țelina este compatibilă cu mai mulți brokeri de mesaje precum RabbitMQ sau Redis și poate acționa atât ca producător, cât și ca consumator.
Țelina este o coadă de sarcini asincronă/coadă de locuri de muncă bazată pe transmiterea distribuită a mesajelor. Este axat pe operațiuni în timp real, dar acceptă și programarea. Unitățile de execuție, numite sarcini, sunt executate simultan pe unul sau mai multe servere de lucru folosind multiprocesare, Eventlet sau gevent. Sarcinile se pot executa asincron (în fundal) sau sincron (așteptați până când sunt gata). – Proiect Telina
Pentru a începe cu țelina, trebuie doar să urmați un ghid pas cu pas din documentele oficiale.
Accentul acestui articol este să vă ofere o bună înțelegere a cazurilor de utilizare care ar putea fi acoperite de țelină. În acest articol, nu vom arăta doar exemple interesante, ci și vom încerca să învățăm cum să aplicăm Țelina la sarcini din lumea reală, cum ar fi trimiterea în fundal, generarea de rapoarte, înregistrarea în jurnal și raportarea erorilor. Voi împărtăși modul meu de a testa sarcinile dincolo de emulare și, în final, voi oferi câteva trucuri care nu sunt (bine) documentate în documentația oficială, ceea ce mi-a luat ore întregi de cercetare pentru a le descoperi singur.
Dacă nu aveți experiență anterioară cu țelina, vă încurajez mai întâi să o încercați urmând tutorialul oficial.
Îți trezește pofta de mâncare
Dacă acest articol vă intrigă și vă face să doriți să vă scufundați imediat în cod, atunci accesați acest depozit GitHub pentru codul folosit în acest articol. Fișierul README de acolo vă va oferi abordarea rapidă și murdară pentru rularea și jucarea cu aplicațiile exemplu.
Primii pași cu țelină
Pentru început, vom parcurge o serie de exemple practice care vor arăta cititorului cât de simplu și elegant rezolvă țelina sarcini aparent nebanale. Toate exemplele vor fi prezentate în cadrul Django; cu toate acestea, majoritatea dintre ele ar putea fi portate cu ușurință în alte cadre Python (Flask, Pyramid).
Aspectul proiectului a fost generat de Cookiecutter Django; totuși, am păstrat doar câteva dependențe care, în opinia mea, facilitează dezvoltarea și pregătirea acestor cazuri de utilizare. De asemenea, am eliminat modulele inutile pentru această postare și aplicații pentru a reduce zgomotul și a face codul mai ușor de înțeles.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}conține diferite aplicații pe care le vom acoperi în această postare. Fiecare aplicație conține un set de exemple organizate în funcție de nivelul de înțelegere cerut de țelină. -
celery_uncovered/celery.pydefinește o instanță de țelină.
Fișier: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Atunci trebuie să ne asigurăm că țelina va începe împreună cu Django. Din acest motiv, importăm aplicația în celery_uncovered/__init__.py .
Fișier: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings este sursa de configurare pentru aplicația noastră și Țelina. În funcție de mediul de execuție, Django va lansa setările corespunzătoare: local.py pentru dezvoltare sau test.py pentru testare. Puteți, de asemenea, să vă definiți propriul mediu dacă doriți, creând un nou modul Python (de exemplu, prod.py ). Configurațiile de țelină sunt prefixate cu CELERY_ . Pentru această postare, am configurat RabbitMQ ca broker și SQLite ca rezultat final.
Fișier: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Scenariul 1 - Generarea și exportul rapoartelor
Primul caz pe care îl vom acoperi este generarea și exportul rapoartelor. În acest exemplu, veți învăța cum să definiți o sarcină care produce un raport CSV și să o programați la intervale regulate cu țelină.
Descrierea cazului de utilizare: preluați cele mai bune cinci sute de depozite din GitHub pe perioadă aleasă (zi, săptămână, lună), grupați-le după subiecte și exportați rezultatul în fișierul CSV.
Dacă oferim un serviciu HTTP care va executa această caracteristică declanșată făcând clic pe un buton etichetat „Generează raport”, aplicația se va opri și va aștepta finalizarea sarcinii înainte de a trimite un răspuns HTTP înapoi. Asta e rău. Dorim ca aplicația noastră web să fie rapidă și nu vrem ca utilizatorii noștri să aștepte până când back-end-ul nostru calculează rezultatele. În loc să așteptăm ca rezultatele să fie produse, preferăm să punem în coadă sarcina la procesele de lucru printr-o coadă înregistrată în Celery și să răspundem cu task_id la front-end. Apoi, front-end-ul va folosi task_id pentru a interoga rezultatul sarcinii într-un mod asincron (de exemplu, AJAX) și va ține utilizatorul la curent cu progresul sarcinii. În cele din urmă, când procesul se termină, rezultatele pot fi servite ca fișier de descărcat prin HTTP.
Detalii de implementare
Mai întâi de toate, să descompunăm procesul în cele mai mici unități posibile și să creăm o conductă:
- Fetchers sunt lucrătorii care sunt responsabili pentru obținerea depozitelor de la serviciul GitHub.
- Agregatorul este lucrătorul care este responsabil pentru consolidarea rezultatelor într-o singură listă.
- Importatorul este lucrătorul care produce rapoarte CSV ale celor mai bune depozite din GitHub.
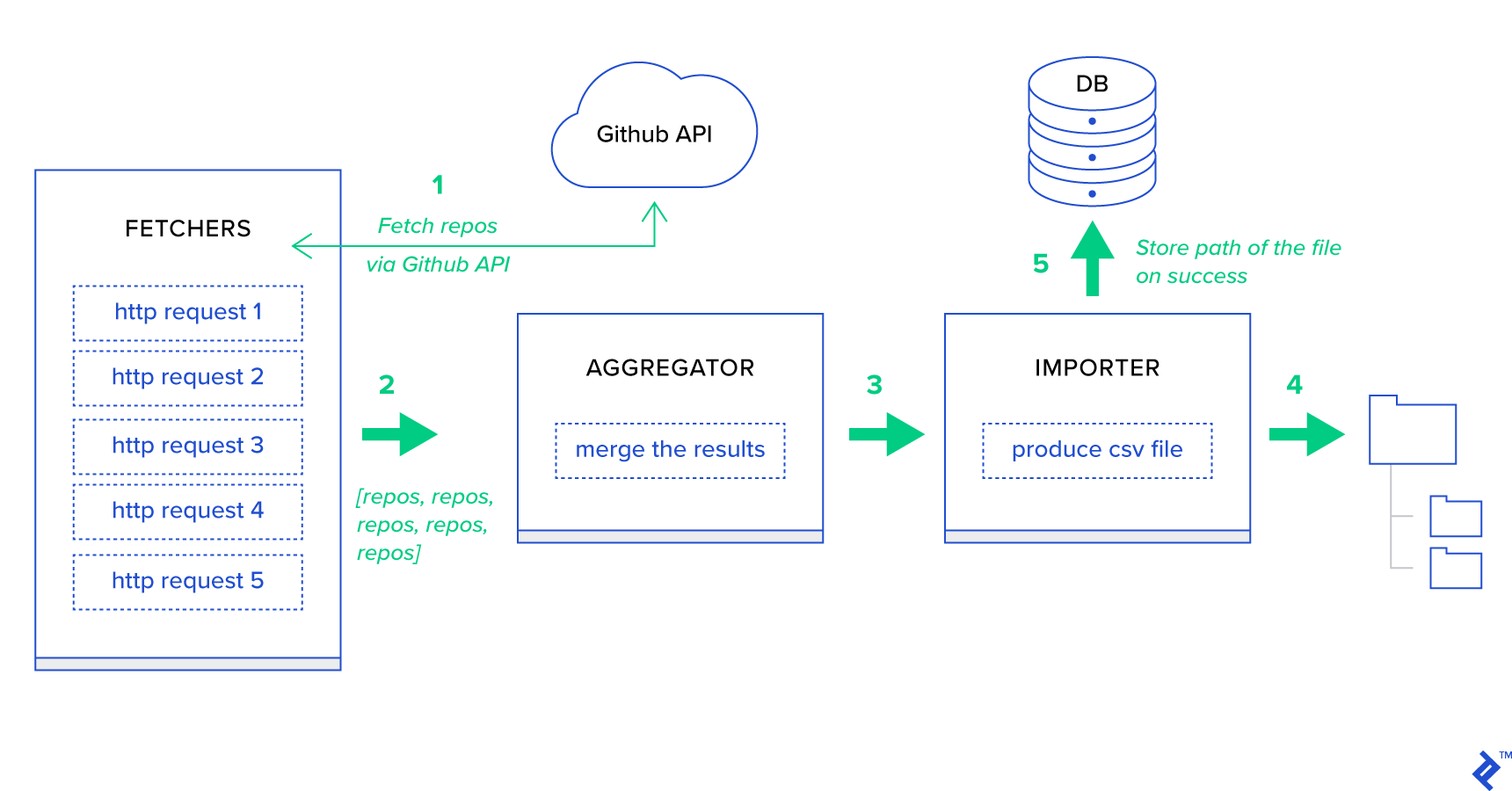
Preluarea depozitelor este o solicitare HTTP folosind API-ul de căutare GitHub GET /search/repositories . Cu toate acestea, există o limitare a serviciului API GitHub care ar trebui gestionat: API-ul returnează până la 100 de depozite per cerere în loc de 500. Am putea trimite cinci solicitări pe rând, dar nu vrem să-l facem pe utilizator să aștepte. pentru cinci cereri individuale, deoarece cererile HTTP sunt o operație legată de I/O. În schimb, putem executa cinci solicitări HTTP concurente cu un parametru de pagină corespunzător. Deci pagina va fi în intervalul [1..5]. Să definim o sarcină numită fetch_hot_repos/3 -> list în modulul toyex/tasks.py :
Fișier: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Deci fetch_hot_repos creează o solicitare către API-ul GitHub și răspunde utilizatorului cu o listă de depozite. Primește trei parametri care vor defini sarcina utilă a cererii noastre:
-
since— Filtrează depozitele la data creării. -
per_page— Numărul de rezultate de returnat per cerere (limitat de 100). -
page—- Numărul paginii solicitat (în intervalul [1..5]).
Notă: pentru a utiliza API-ul de căutare GitHub, veți avea nevoie de un token OAuth pentru a trece verificările de autentificare. În cazul nostru, este salvat în setările din GITHUB_OAUTH .
În continuare, trebuie să definim o sarcină principală care va fi responsabilă pentru agregarea rezultatelor și exportarea lor într-un fișier CSV: produce_hot_repo_report_task/2->filepath:
Fișier: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Această sarcină folosește celery.canvas.group pentru a executa cinci apeluri concurente ale fetch_hot_repos/3 . Aceste rezultate sunt așteptate și apoi reduse la o listă de obiecte de depozit. Apoi setul nostru de rezultate este grupat pe subiect și, în final, exportat într-un fișier CSV generat în directorul MEDIA_ROOT/ .
Pentru a programa periodic sarcina, poate doriți să adăugați o intrare la lista de programare în fișierul de configurare:
Fișier: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Încercând
Pentru a lansa și a testa modul în care funcționează sarcina, mai întâi trebuie să începem procesul de țelină:
$ celery -A celery_uncovered worker -l info Apoi, trebuie să creăm directorul celery_uncovered/media/ . Apoi, veți putea să-i testați funcționalitatea fie prin Shell sau Celerybeat:
Shell :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)bataie de telina :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Puteți urmări rezultatele în directorul MEDIA_ROOT/ .
Scenariul 2 - Raportați erorile Server 500 prin e-mail
Unul dintre cele mai frecvente cazuri de utilizare pentru țelină este trimiterea de notificări prin e-mail. Notificarea prin e-mail este o operațiune de I/O offline care folosește fie un server SMTP local, fie un SES terță parte. Există multe cazuri de utilizare care implică trimiterea unui e-mail și, pentru majoritatea dintre ele, utilizatorul nu trebuie să aștepte până la finalizarea acestui proces înainte de a primi un răspuns HTTP. De aceea, este de preferat să executați astfel de sarcini în fundal și să răspundeți imediat utilizatorului.
Descrierea cazului de utilizare: Raportați erori de 50X către e-mailul administratorului prin Țelina.
Python și Django au fundalul necesar pentru a efectua înregistrarea în sistem. Nu voi intra în detalii despre cum funcționează de fapt înregistrarea Python. Cu toate acestea, dacă nu ați încercat niciodată până acum sau aveți nevoie de o actualizare, citiți documentația modulului de înregistrare încorporat. Cu siguranță îți dorești asta în mediul tău de producție. Django are un handler special de înregistrare numit AdminEmailHandler care trimite e-mail administratorilor pentru fiecare mesaj de jurnal pe care îl primește.
Detalii de implementare
Ideea principală este de a extinde metoda send_mail a clasei AdminEmailHandler în așa fel încât să poată trimite e-mail prin țelină. Acest lucru se poate face așa cum este ilustrat în figura de mai jos:
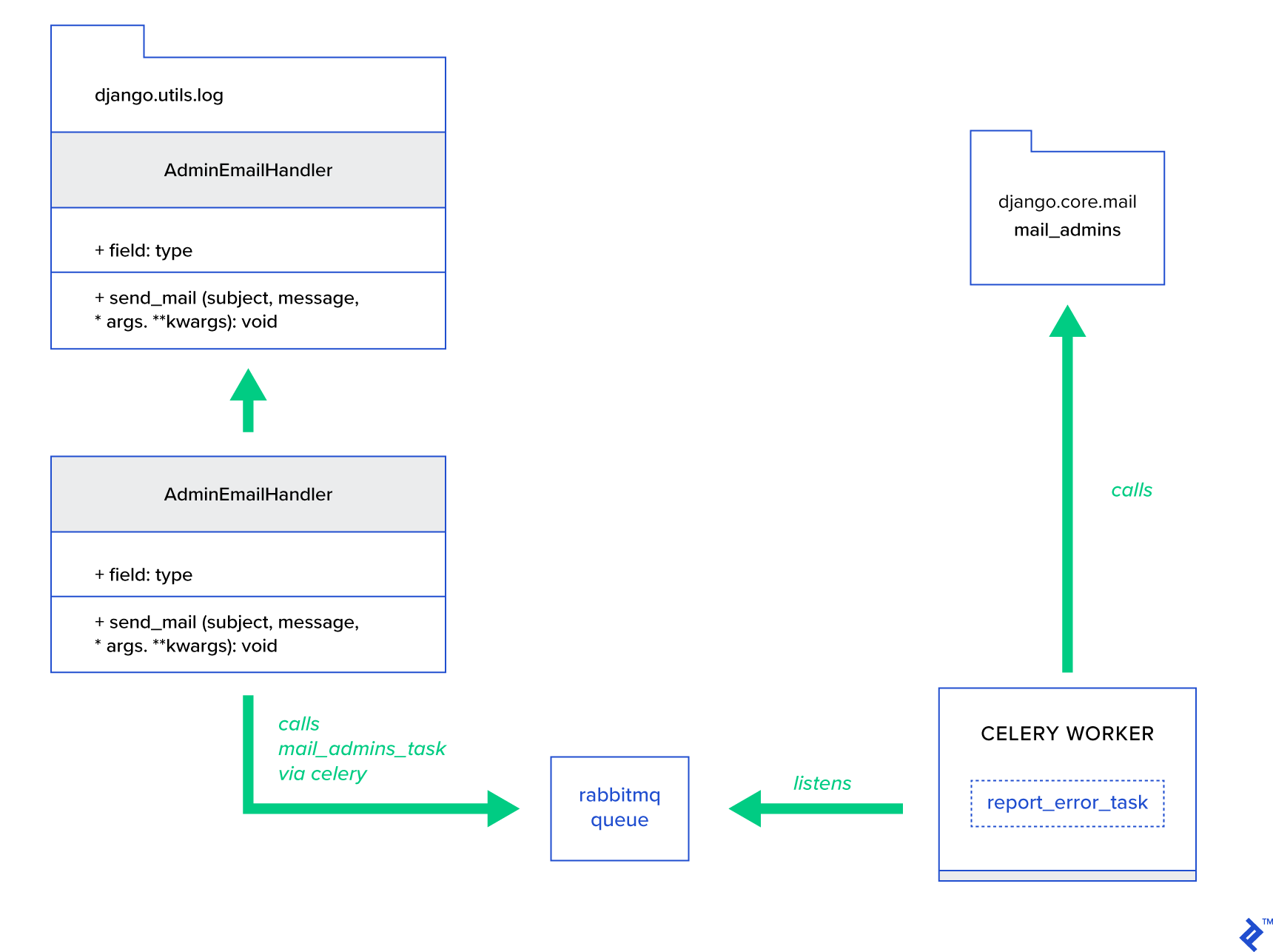
Mai întâi, trebuie să setăm o sarcină numită report_error_task care apelează mail_admins cu subiectul și mesajul furnizat:
Fișier: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Apoi, extindem de fapt AdminEmailHandler, astfel încât să apeleze intern doar sarcina de țelină definită:
Fișier: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) În cele din urmă, trebuie să setăm înregistrarea în jurnal. Configurarea logării în Django este destul de simplă. Ceea ce aveți nevoie este să suprascrieți LOGGING , astfel încât motorul de logare să pornească să utilizeze un handler nou definit:
Fișier config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Observați că am configurat intenționat filtrele de gestionare require_debug_true pentru a testa această funcționalitate în timp ce aplicația rulează în modul de depanare.
Încercând
Pentru a-l testa, am pregătit o vizualizare Django care servește o operațiune „diviziune după zero” la localhost:8000/report-error . De asemenea, trebuie să porniți un container MailHog Docker pentru a testa dacă e-mailul este efectiv trimis.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Detalii suplimentare
Ca instrument de testare a corespondenței, am configurat MailHog și am configurat mailingul Django pentru a-l folosi pentru livrarea SMTP. Există multe moduri de a implementa și de a rula MailHog. Am decis să merg cu un container Docker. Puteți găsi detalii în fișierul README corespunzător:
Fișier: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Pentru a configura aplicația să utilizeze MailHog, trebuie să adăugați următoarele linii în configurația dvs.:
Fișier: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Dincolo de sarcinile implicite de țelină
Sarcinile de țelină ar putea fi create din orice funcție apelabilă. În mod implicit, orice sarcină definită de utilizator este injectată cu celery.app.task.Task ca clasă părinte (abstractă). Această clasă conține funcționalitatea de a rula sarcini asincron (trecându-le prin rețea unui lucrător Celery) sau sincron (în scopuri de testare), creând semnături și multe alte utilități. În exemplele următoare, vom încerca să extindem Celery.app.task.Task și apoi să o folosim ca clasă de bază pentru a adăuga câteva comportamente utile sarcinilor noastre.
Scenariul 3 - Înregistrare fișiere per sarcină
Într-unul dintre proiectele mele, dezvoltam o aplicație care oferă utilizatorului final un instrument asemănător ETL (Extract, Transform, Load) care era capabil să ingereze și apoi să filtreze o cantitate imensă de date ierarhice. Back-end-ul a fost împărțit în două module:
- Orchestrarea unei conducte de procesare a datelor cu țelină
- Prelucrarea datelor cu Go
Celery a fost implementat cu o instanță Celerybeat și peste 40 de lucrători. Au fost peste douăzeci de sarcini diferite care au compus activitățile de conductă și orchestrație. Fiecare astfel de sarcină poate eșua la un moment dat. Toate aceste erori au fost aruncate în jurnalul de sistem al fiecărui lucrător. La un moment dat, a început să devină incomod să depanați și să mențineți stratul de țelină. În cele din urmă, am decis să izolăm jurnalul de activități într-un fișier specific pentru sarcini.
Descrierea cazului de utilizare: Extindeți țelina astfel încât fiecare sarcină să își înregistreze rezultatul standard și erorile în fișiere
Celery oferă aplicațiilor Python un control excelent asupra a ceea ce face în interior. Se livrează cu un cadru de semnale familiar. Aplicațiile care folosesc Celery se pot abona la câteva dintre acestea pentru a spori comportamentul anumitor acțiuni. Vom valorifica semnalele la nivel de sarcină pentru a oferi urmărire detaliate a ciclurilor de viață ale sarcinilor individuale. Țelina vine întotdeauna cu un back-end de logare și vom beneficia de el, în timp ce o depășim ușor în câteva locuri pentru a ne atinge obiectivele.
Detalii de implementare
Țelina acceptă deja înregistrarea pentru fiecare sarcină. Pentru a salva într-un fișier, este necesar să trimiteți rezultatul jurnalului în locația potrivită. În cazul nostru, locația corectă a sarcinii este un fișier care se potrivește cu numele sarcinii. În instanța de țelină, vom suprascrie configurația de înregistrare încorporată cu handlere de înregistrare deduse dinamic. Este posibil să vă abonați la semnalul celeryd_after_setup și apoi să configurați înregistrarea sistemului acolo:
Fișier: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Observați că pentru fiecare sarcină înregistrată în aplicația Celery, construim un logger corespunzător cu gestionarea acestuia. Fiecare handler este de tipul logging.FileHandler și, prin urmare, fiecare astfel de instanță primește un nume de fișier ca intrare. Tot ce aveți nevoie pentru a rula acest lucru este să importați acest modul în celery_uncovered/celery.py la sfârșitul fișierului:
import celery_uncovered.tricks.celery_conf Un anumit task logger poate fi primit apelând get_task_logger(task_name) . Pentru a generaliza un astfel de comportament pentru fiecare sarcină, este necesar să extindeți ușor celery.current_app.Task cu câteva metode utilitare:
Fișier: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Acum, în cazul unui apel la task.log_msg("Hello, my name is: %s", task.request.id) , ieșirea jurnalului va fi direcționată către fișierul corespunzător sub numele sarcinii.
Încercând
Pentru a lansa și a testa modul în care funcționează această sarcină, începeți mai întâi procesul de țelină:
$ celery -A celery_uncovered worker -l infoApoi veți putea testa funcționalitatea prin Shell:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) În cele din urmă, pentru a vedea rezultatul, navigați la directorul celery_uncovered/logs și deschideți fișierul jurnal corespunzător numit celery_uncovered.tricks.tasks.add.log . Este posibil să vedeți ceva similar ca mai jos după ce ați executat această sarcină de mai multe ori:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Scenariul 4 - Sarcini care țin cont de domeniul de aplicare
Să ne imaginăm o aplicație Python pentru utilizatori internaționali care este construită pe țelină și Django. Utilizatorii pot seta în ce limbă (locală) folosesc aplicația dvs.
Trebuie să proiectați un sistem de notificare prin e-mail multilingv, care știe localitatea. Pentru a trimite notificări prin e-mail, ați înregistrat o sarcină specială de țelină care este gestionată de o anumită coadă. Această sarcină primește câteva argumente cheie ca intrare și o localitate curentă a utilizatorului, astfel încât e-mailul va fi trimis în limba aleasă de utilizator.
Acum imaginați-vă că avem multe astfel de sarcini, dar fiecare dintre aceste sarcini acceptă un argument local. În acest caz, nu ar fi mai bine să o rezolvăm la un nivel superior de abstractizare? Aici vedem cum să facem asta.
Descrierea cazului de utilizare: Moșteniți automat domeniul de aplicare dintr-un context de execuție și injectați-l în contextul de execuție curent ca parametru.
Detalii de implementare
Din nou, așa cum am făcut cu înregistrarea sarcinilor, dorim să extindem o clasă de activități de bază celery.current_app.Task și să suprascriem câteva metode responsabile pentru apelarea sarcinilor. În scopul acestei demonstrații, anulez metoda celery.current_app.Task::apply_async . Există sarcini suplimentare pentru acest modul care vă vor ajuta să produceți un înlocuitor complet funcțional.
Fișier: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)Indiciul cheie este de a trece localitatea curentă ca argument cheie-valoare într-o sarcină de apelare în mod implicit. Dacă o sarcină a fost apelată cu o anumită localitate ca argument, atunci aceasta este neschimbată.
Încercând
Pentru a testa această funcționalitate, să definim o sarcină inactivă de tip ScopeBasedTask . Localizează un fișier după ID-ul local și citește conținutul acestuia ca JSON:
Fișier: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Acum, ceea ce trebuie să faceți este să repetați pașii de lansare a lui Celery, pornirea shell-ului și testarea execuției acestei sarcini pe diferite scenarii. Fixturile sunt situate în directorul celery_uncovered/tricks/fixtures/locales/ .
Concluzie
Această postare și-a propus să exploreze țelina din diferite perspective. Am demonstrat țelină în exemple convenționale, cum ar fi generarea de corespondență și rapoarte, precum și trucuri partajate pentru unele cazuri de utilizare de afaceri de nișă interesante. Țelina este construită pe o filozofie bazată pe date, iar echipa dvs. își poate face viața mult mai simplă prin introducerea acesteia ca parte a stivei lor de sistem. Dezvoltarea serviciilor bazate pe țelină nu este foarte complicată dacă aveți experiență de bază în Python și ar trebui să puteți să o preluați destul de repede. Configurația implicită este suficient de bună pentru majoritatea utilizărilor, dar dacă este necesar, pot fi foarte flexibile.
Echipa noastră a ales să folosească țelina ca back-end de orchestrare pentru joburi de fundal și sarcini de lungă durată. Îl folosim pe scară largă pentru o varietate de cazuri de utilizare, dintre care doar câteva au fost menționate în această postare. Ingerăm și analizăm gigaocteți de date în fiecare zi, dar acesta este doar începutul tehnicilor de scalare orizontală.