
Mengatur Alur Kerja Pekerjaan Latar Belakang di Seledri untuk Python
Diterbitkan: 2022-03-11Aplikasi web modern dan sistem dasarnya lebih cepat dan lebih responsif daripada sebelumnya. Namun, masih banyak kasus di mana Anda ingin memindahkan eksekusi tugas berat ke bagian lain dari seluruh arsitektur sistem Anda alih-alih menanganinya di utas utama Anda. Mengidentifikasi tugas-tugas tersebut semudah memeriksa untuk melihat apakah mereka termasuk dalam salah satu kategori berikut:
- Tugas berkala — Pekerjaan yang akan Anda jadwalkan untuk dijalankan pada waktu tertentu atau setelah interval, misalnya, pembuatan laporan bulanan atau pengikis web yang berjalan dua kali sehari.
- Tugas pihak ketiga — Aplikasi web harus melayani pengguna dengan cepat tanpa menunggu tindakan lain selesai saat halaman dimuat, misalnya, mengirim email atau pemberitahuan atau menyebarkan pembaruan ke alat internal (seperti mengumpulkan data untuk pengujian A/B atau log sistem ).
- Pekerjaan yang berjalan lama — Pekerjaan yang mahal dalam sumber daya, di mana pengguna harus menunggu sementara mereka menghitung hasilnya, misalnya, eksekusi alur kerja yang kompleks (alur kerja DAG), pembuatan grafik, tugas seperti Pengurangan Peta, dan penyajian konten media (video, audio).
Solusi langsung untuk menjalankan tugas latar belakang adalah menjalankannya dalam utas atau proses terpisah. Python adalah bahasa pemrograman lengkap Turing tingkat tinggi, yang sayangnya tidak menyediakan konkurensi bawaan pada skala yang cocok dengan Erlang, Go, Java, Scala, atau Akka. Itu didasarkan pada Communicating Sequential Processes (CSP) Tony Hoare. Utas Python, di sisi lain, dikoordinasikan dan dijadwalkan oleh kunci penerjemah global (GIL), yang mencegah beberapa utas asli mengeksekusi bytecode Python sekaligus. Menyingkirkan GIL adalah topik dari banyak diskusi di antara pengembang Python, tetapi itu bukan fokus dari artikel ini. Pemrograman serentak dengan Python sudah kuno, meskipun Anda dipersilakan untuk membacanya di Tutorial Multithreading Python oleh sesama Toptaler Marcus McCurdy. Jadi, merancang komunikasi antar proses secara konsisten adalah proses yang rawan kesalahan dan mengarah pada penggabungan kode dan pemeliharaan sistem yang buruk, belum lagi hal itu berdampak negatif pada skalabilitas. Selain itu, proses Python adalah proses normal di bawah Sistem Operasi (OS) dan, dengan seluruh pustaka standar Python, itu menjadi kelas berat. Karena jumlah proses dalam aplikasi meningkat, beralih dari satu proses ke proses lainnya menjadi operasi yang memakan waktu.
Untuk memahami konkurensi dengan Python lebih baik, tonton pidato luar biasa dari David Beazley ini di PyCon'15.
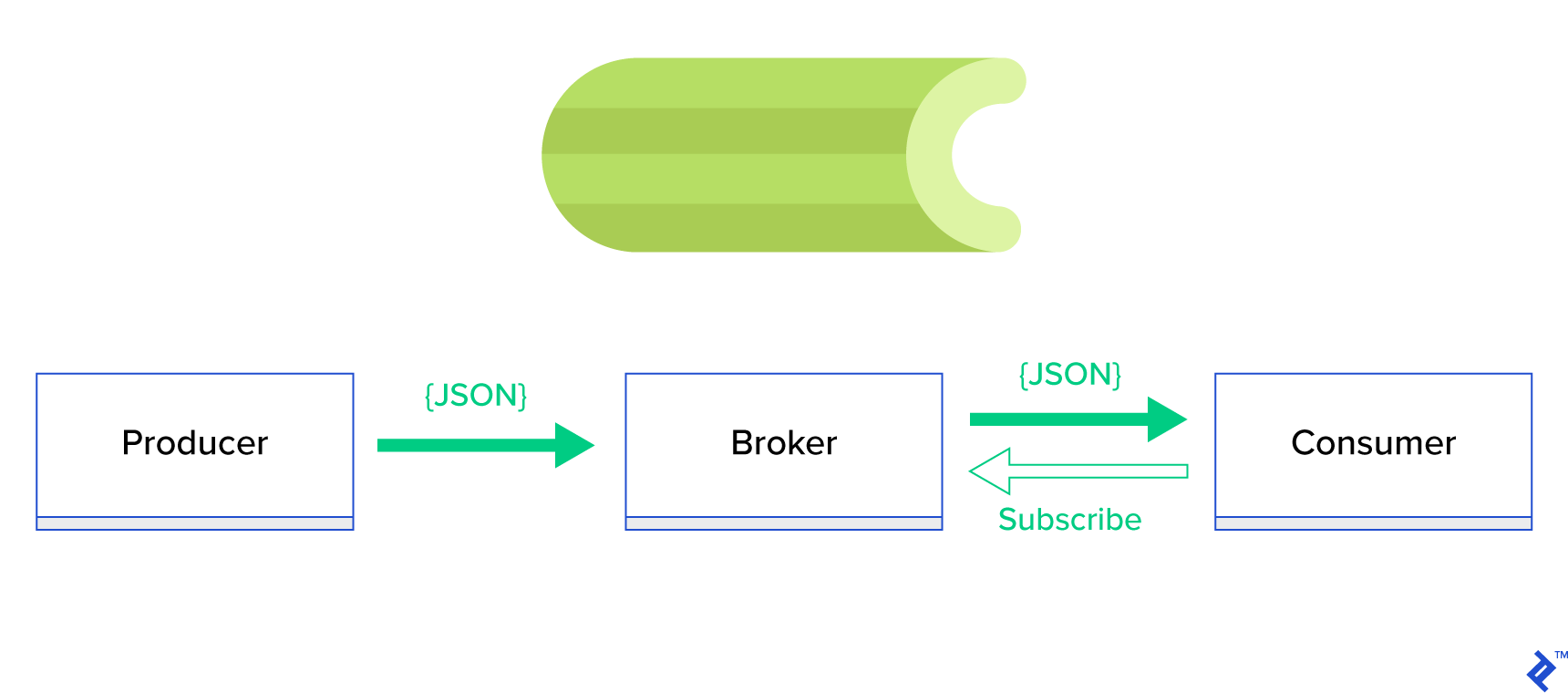
Solusi yang jauh lebih baik adalah dengan melayani antrian terdistribusi atau paradigma saudaranya yang terkenal disebut publish-subscribe . Seperti yang digambarkan pada Gambar 1, ada dua jenis aplikasi di mana satu, yang disebut penerbit , mengirim pesan dan yang lainnya, yang disebut pelanggan , menerima pesan. Kedua agen tersebut tidak berinteraksi satu sama lain secara langsung dan bahkan tidak menyadari satu sama lain. Penerbit mengirim pesan ke antrian pusat, atau broker , dan pelanggan menerima pesan yang menarik dari broker ini. Ada dua keuntungan utama dalam metode ini:
- Skalabilitas — agen tidak perlu mengetahui satu sama lain dalam jaringan. Mereka fokus berdasarkan topik. Jadi itu berarti bahwa masing-masing dapat terus beroperasi secara normal terlepas dari yang lain secara asinkron.
- Kopling longgar — setiap agen mewakili bagiannya dari sistem (layanan, modul). Karena mereka digabungkan secara longgar, masing-masing dapat menskalakan secara individual di luar pusat data.
Ada banyak sistem pesan yang mendukung paradigma tersebut dan menyediakan API yang rapi, didorong baik oleh protokol TCP atau HTTP, misalnya, JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ, dll.
Apa itu Seledri?
Seledri adalah salah satu manajer pekerjaan latar belakang paling populer di dunia Python. Seledri kompatibel dengan beberapa perantara pesan seperti RabbitMQ atau Redis dan dapat bertindak sebagai produsen dan konsumen.
Seledri adalah antrian tugas/antrian pekerjaan asinkron berdasarkan pengiriman pesan terdistribusi. Ini berfokus pada operasi waktu nyata tetapi juga mendukung penjadwalan. Unit eksekusi, yang disebut tugas, dieksekusi secara bersamaan pada satu atau lebih server pekerja menggunakan multiprosesor, Eventlet, atau gevent. Tugas dapat dijalankan secara asinkron (di latar belakang) atau secara sinkron (tunggu hingga siap). – Proyek Seledri
Untuk memulai dengan Seledri, cukup ikuti panduan langkah demi langkah di dokumen resmi.
Fokus artikel ini adalah memberi Anda pemahaman yang baik tentang kasus penggunaan mana yang dapat dicakup oleh Seledri. Dalam artikel ini, kami tidak hanya akan menunjukkan contoh menarik tetapi juga mencoba mempelajari cara menerapkan Seledri ke tugas dunia nyata seperti pengiriman surat latar belakang, pembuatan laporan, pencatatan log, dan pelaporan kesalahan. Saya akan membagikan cara saya menguji tugas-tugas di luar emulasi dan, akhirnya, saya akan memberikan beberapa trik yang tidak (baik) didokumentasikan dalam dokumentasi resmi yang membutuhkan waktu berjam-jam penelitian untuk saya temukan sendiri.
Jika Anda tidak memiliki pengalaman sebelumnya dengan Seledri, saya sarankan Anda mencobanya terlebih dahulu dengan mengikuti tutorial resmi.
Memuaskan Nafsu Makan Anda
Jika artikel ini membuat Anda penasaran dan ingin segera mendalami kode, ikuti repositori GitHub ini untuk kode yang digunakan dalam artikel ini. File README di sana akan memberi Anda pendekatan cepat dan kotor untuk menjalankan dan bermain dengan contoh aplikasi.
Langkah Pertama dengan Seledri
Sebagai permulaan, kita akan membahas serangkaian contoh praktis yang akan menunjukkan kepada pembaca betapa sederhana dan elegannya Seledri menyelesaikan tugas-tugas yang tampaknya tidak sepele. Semua contoh akan disajikan dalam kerangka Django; namun, kebanyakan dari mereka dapat dengan mudah di-porting ke kerangka kerja Python lainnya (Flask, Pyramid).
Tata letak proyek dihasilkan oleh Cookiecutter Django; namun, saya hanya menyimpan beberapa dependensi yang, menurut pendapat saya, memfasilitasi pengembangan dan persiapan kasus penggunaan ini. Saya juga menghapus modul yang tidak perlu untuk posting ini dan aplikasi untuk mengurangi kebisingan dan membuat kode lebih mudah dipahami.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}berisi berbagai aplikasi yang akan kami bahas dalam posting ini. Setiap aplikasi berisi kumpulan contoh yang disusun berdasarkan tingkat pemahaman Seledri yang dibutuhkan. -
celery_uncovered/celery.pymendefinisikan instance Seledri.
File: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() Kemudian kita perlu memastikan bahwa Seledri akan memulai bersama dengan Django. Oleh karena itu, kami mengimpor aplikasi di celery_uncovered/__init__.py .
File: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings adalah sumber konfigurasi untuk aplikasi kami dan Seledri. Bergantung pada lingkungan eksekusi, Django akan meluncurkan pengaturan yang sesuai: local.py untuk pengembangan atau test.py untuk pengujian. Anda juga dapat menentukan lingkungan Anda sendiri jika ingin dengan membuat modul python baru (mis., prod.py ). Konfigurasi seledri diawali dengan CELERY_ . Untuk posting ini, saya mengkonfigurasi RabbitMQ sebagai broker dan SQLite sebagai hasilnya bac-end.
File: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'Skenario 1 - Pembuatan laporan dan ekspor
Kasus pertama yang akan kita bahas adalah pembuatan laporan dan ekspor. Dalam contoh ini, Anda akan mempelajari cara menentukan tugas yang menghasilkan laporan CSV dan menjadwalkannya secara berkala dengan celerybeat.
Gunakan deskripsi kasus: ambil lima ratus repositori terpanas dari GitHub per periode yang dipilih (hari, minggu, bulan), kelompokkan berdasarkan topik, dan ekspor hasilnya ke file CSV.
Jika kami menyediakan layanan HTTP yang akan menjalankan fitur ini dipicu dengan mengklik tombol berlabel "Hasilkan Laporan", aplikasi akan berhenti dan menunggu tugas selesai sebelum mengirim kembali respons HTTP. Ini buruk. Kami ingin aplikasi web kami menjadi cepat dan kami tidak ingin pengguna kami menunggu sementara back-end kami menghitung hasilnya. Daripada menunggu hasil dihasilkan, kami lebih suka mengantri tugas ke proses pekerja melalui antrian terdaftar di Celery dan merespons dengan task_id ke front-end. Kemudian front-end akan menggunakan task_id untuk menanyakan hasil tugas secara asinkron (misalnya, AJAX) dan akan terus memperbarui pengguna dengan kemajuan tugas. Terakhir, ketika proses selesai, hasilnya dapat disajikan sebagai file untuk diunduh melalui HTTP.
Detail Implementasi
Pertama-tama, mari kita dekomposisi proses menjadi unit terkecil yang mungkin dan membuat jalur pipa:
- Fetcher adalah pekerja yang bertanggung jawab untuk mendapatkan repositori dari layanan GitHub.
- Agregator adalah pekerja yang bertanggung jawab untuk menggabungkan hasil ke dalam satu daftar.
- Importir adalah pekerja yang menghasilkan laporan CSV dari repositori terpanas di GitHub.
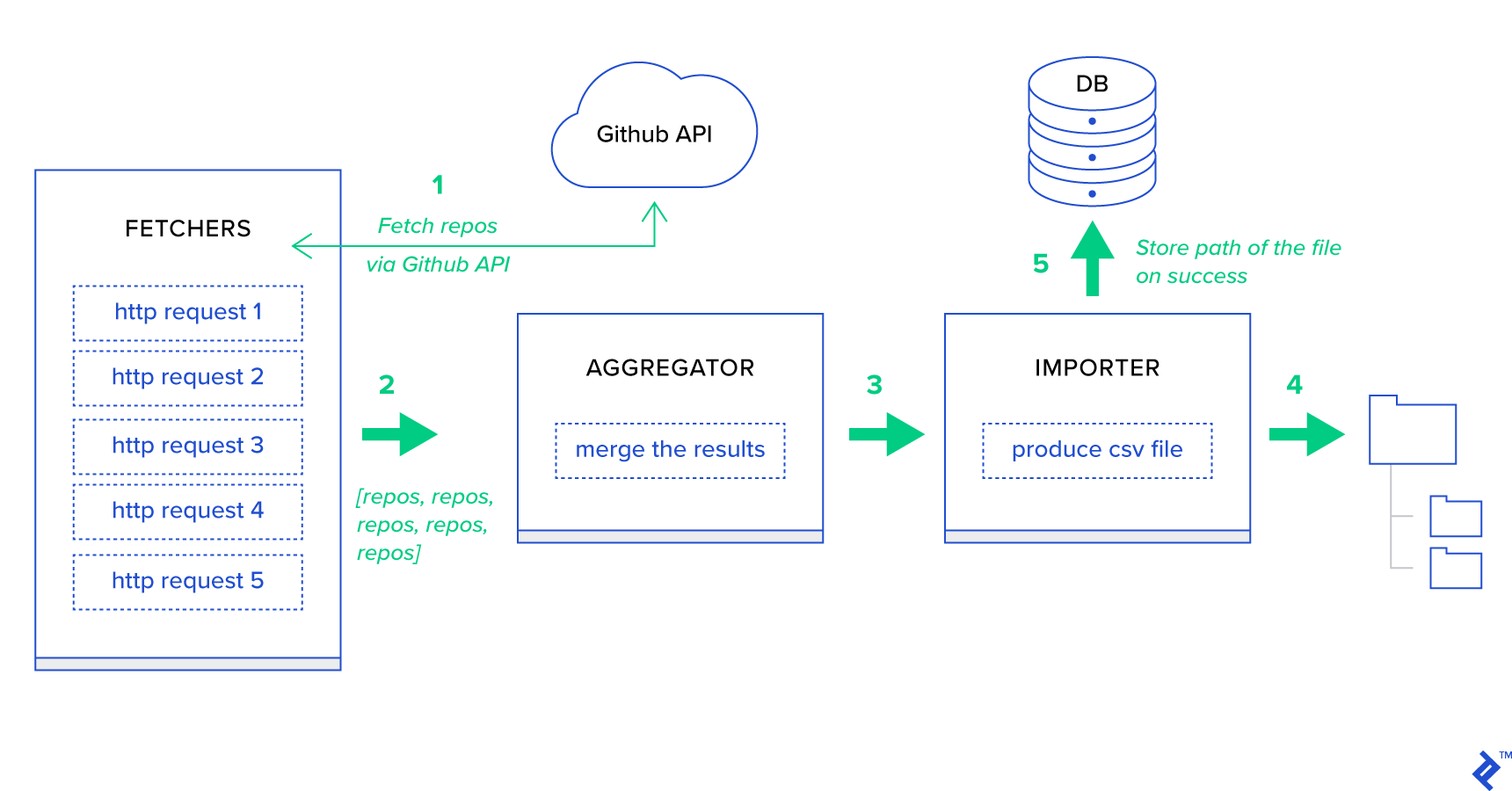
Mengambil repositori adalah permintaan HTTP menggunakan API Pencarian GitHub GET /search/repositories . Namun, ada batasan layanan API GitHub yang harus ditangani: API mengembalikan hingga 100 repositori per permintaan, bukan 500. Kami dapat mengirim lima permintaan satu per satu, tetapi kami tidak ingin membuat pengguna kami menunggu untuk lima permintaan individu karena permintaan HTTP adalah operasi terikat I/O. Sebagai gantinya, kami dapat menjalankan lima permintaan HTTP bersamaan dengan parameter halaman yang sesuai. Jadi halaman akan berada di kisaran [1,.5]. Mari kita definisikan tugas yang disebut fetch_hot_repos/3 -> list di modul toyex/tasks.py :
File: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items Jadi fetch_hot_repos membuat permintaan ke GitHub API dan merespons pengguna dengan daftar repositori. Ia menerima tiga parameter yang akan menentukan muatan permintaan kami:
-
since— Memfilter repositori pada tanggal pembuatan. -
per_page— Jumlah hasil yang akan ditampilkan per permintaan (dibatasi oleh 100). -
page—- Nomor halaman yang diminta (dalam kisaran [1.5]).
Catatan: Untuk menggunakan GitHub Search API, Anda memerlukan Token OAuth untuk lulus pemeriksaan autentikasi. Dalam kasus kami, itu disimpan dalam pengaturan di bawah GITHUB_OAUTH .
Selanjutnya, kita perlu mendefinisikan tugas utama yang akan bertanggung jawab untuk menggabungkan hasil dan mengekspornya ke dalam file CSV: produce_hot_repo_report_task/2->filepath:
File: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) Tugas ini menggunakan celery.canvas.group untuk mengeksekusi lima panggilan fetch_hot_repos/3 secara bersamaan. Hasil tersebut ditunggu dan kemudian direduksi menjadi daftar objek repositori. Kemudian kumpulan hasil kami dikelompokkan berdasarkan topik dan akhirnya diekspor ke file CSV yang dihasilkan di bawah direktori MEDIA_ROOT/ .
Untuk menjadwalkan tugas secara berkala, Anda mungkin ingin menambahkan entri ke daftar jadwal di file konfigurasi:
File: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }Mencobanya
Untuk meluncurkan dan menguji cara kerja tugas, pertama-tama kita harus memulai proses Seledri:
$ celery -A celery_uncovered worker -l info Selanjutnya, kita perlu membuat celery_uncovered/media/ . Kemudian, Anda akan dapat menguji fungsinya baik melalui Shell atau Celerybeat:
kulit :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)Seledri :

# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info Anda dapat melihat hasilnya di bawah direktori MEDIA_ROOT/ .
Skenario 2 - Laporkan Kesalahan Server 500 melalui Email
Salah satu kasus penggunaan paling umum untuk Celery adalah mengirim pemberitahuan email. Pemberitahuan email adalah operasi terikat I/O offline yang memanfaatkan server SMTP lokal atau SES pihak ketiga. Ada banyak kasus penggunaan yang melibatkan pengiriman email dan, sebagian besar dari kasus tersebut, pengguna tidak perlu menunggu hingga proses ini selesai sebelum menerima respons HTTP. Itulah mengapa lebih disukai untuk menjalankan tugas seperti itu di latar belakang dan segera merespons pengguna.
Deskripsi kasus penggunaan: Laporkan kesalahan 50X ke email administrator melalui Seledri.
Python dan Django memiliki latar belakang yang diperlukan untuk melakukan pencatatan sistem. Saya tidak akan membahas detail tentang bagaimana sebenarnya logging Python bekerja. Namun, jika Anda belum pernah mencobanya atau membutuhkan penyegaran, baca dokumentasi modul logging bawaan. Anda pasti menginginkan ini di lingkungan produksi Anda. Django memiliki pengendali pencatat khusus yang disebut AdminEmailHandler yang mengirim email kepada administrator untuk setiap pesan log yang diterimanya.
Detail Implementasi
Ide utamanya adalah untuk memperluas metode send_mail dari kelas AdminEmailHandler sedemikian rupa sehingga dapat mengirim email melalui Celery. Hal ini dapat dilakukan seperti yang diilustrasikan pada gambar di bawah ini:
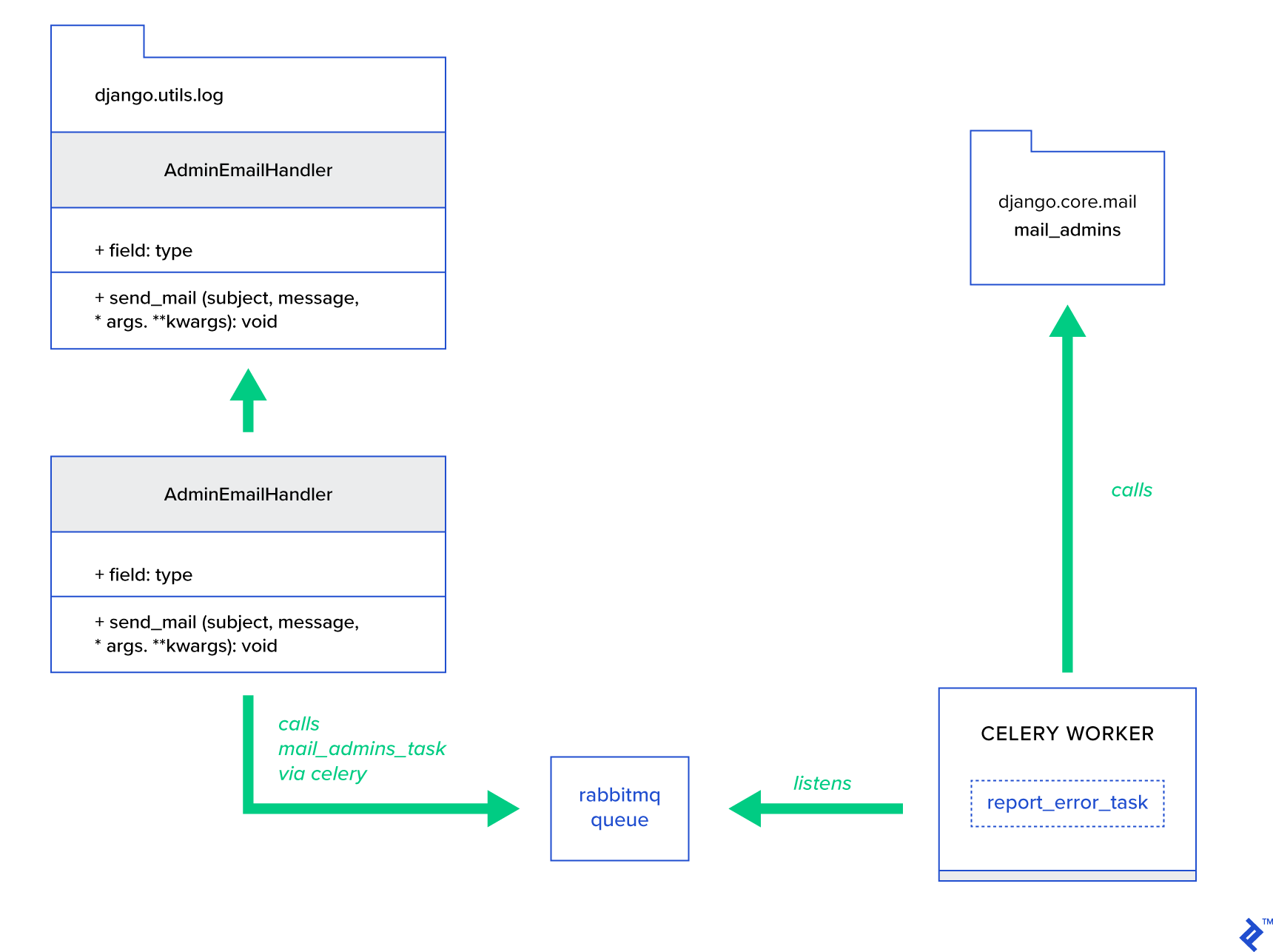
Pertama, kita perlu menyiapkan tugas yang disebut report_error_task yang memanggil mail_admins dengan subjek dan pesan yang disediakan:
File: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)Selanjutnya, kami benar-benar memperluas AdminEmailHandler sehingga secara internal hanya akan memanggil tugas Seledri yang ditentukan:
File: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) Terakhir, kita perlu mengatur logging. Konfigurasi login di Django cukup mudah. Yang Anda butuhkan adalah mengganti LOGGING sehingga mesin logging mulai menggunakan handler yang baru ditentukan:
File config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } Perhatikan bahwa saya sengaja mengatur filter penangan require_debug_true untuk menguji fungsionalitas ini saat aplikasi berjalan dalam mode debug.
Mencobanya
Untuk mengujinya, saya menyiapkan tampilan Django yang melayani operasi "division-by-zero" di localhost:8000/report-error . Anda juga perlu memulai wadah MailHog Docker untuk menguji apakah email benar-benar terkirim.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)Detail Ekstra
Sebagai alat pengujian surat, saya mengatur MailHog dan mengkonfigurasi surat Django untuk menggunakannya untuk pengiriman SMTP. Ada banyak cara untuk menyebarkan dan menjalankan MailHog. Saya memutuskan untuk menggunakan wadah Docker. Anda dapat menemukan detailnya di file README yang sesuai:
File: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025Untuk mengonfigurasi aplikasi Anda agar menggunakan MailHog, Anda perlu menambahkan baris berikut di konfigurasi Anda:
File: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')Melampaui Tugas Seledri Default
Tugas seledri dapat dibuat dari fungsi apa pun yang dapat dipanggil. Secara default, setiap tugas yang ditentukan pengguna disuntikkan dengan celery.app.task.Task sebagai kelas induk (abstrak). Kelas ini berisi fungsionalitas menjalankan tugas secara asinkron (meneruskannya melalui jaringan ke pekerja Seledri) atau secara sinkron (untuk tujuan pengujian), membuat tanda tangan, dan banyak utilitas lainnya. Dalam contoh berikutnya, kita akan mencoba memperluas Celery.app.task.Task dan kemudian menggunakannya sebagai kelas dasar untuk menambahkan beberapa perilaku yang berguna ke tugas kita.
Skenario 3 - Pencatatan File per Tugas
Di salah satu proyek saya, saya sedang mengembangkan aplikasi yang menyediakan alat seperti Ekstrak, Transformasi, Muat (ETL) kepada pengguna akhir yang mampu menyerap dan kemudian memfilter sejumlah besar data hierarkis. Bagian belakang dibagi menjadi dua modul:
- Orkestrasi saluran pemrosesan data dengan Celery
- Pemrosesan data dengan Go
Celery dikerahkan dengan satu instance Celerybeat dan lebih dari 40 pekerja. Ada lebih dari dua puluh tugas berbeda yang menyusun kegiatan pipa dan orkestrasi. Setiap tugas tersebut mungkin gagal di beberapa titik. Semua kegagalan ini dibuang ke log sistem setiap pekerja. Pada titik tertentu, mulai menjadi tidak nyaman untuk men-debug dan memelihara lapisan Seledri. Akhirnya, kami memutuskan untuk mengisolasi log tugas ke file tugas tertentu.
Gunakan deskripsi kasus: Perluas Seledri sehingga setiap tugas mencatat keluaran standar dan kesalahannya ke file
Celery menyediakan aplikasi Python dengan kontrol besar atas apa yang dilakukannya secara internal. Ini dikirimkan dengan kerangka sinyal yang sudah dikenal. Aplikasi yang menggunakan Seledri dapat berlangganan beberapa aplikasi tersebut untuk meningkatkan perilaku tindakan tertentu. Kami akan memanfaatkan sinyal tingkat tugas untuk menyediakan pelacakan verbose dari siklus hidup tugas individu. Seledri selalu hadir dengan back-end logging, dan kami akan mengambil manfaat darinya sementara hanya sedikit mengesampingkan di beberapa tempat untuk mencapai tujuan kami.
Detail Implementasi
Seledri sudah mendukung logging per tugas. Untuk menyimpan ke file, perlu mengirimkan output log ke lokasi yang tepat. Dalam kasus kami, lokasi tugas yang tepat adalah file yang cocok dengan nama tugas. Pada instance Celery, kami akan mengganti konfigurasi logging bawaan dengan handler logging yang disimpulkan secara dinamis. Dimungkinkan untuk berlangganan sinyal celeryd_after_setup dan kemudian mengonfigurasi logging sistem di sana:
File: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Perhatikan bahwa untuk setiap tugas yang terdaftar di aplikasi Celery, kami sedang membangun logger yang sesuai dengan handler-nya. Setiap handler bertipe logging.FileHandler , dan oleh karena itu setiap instance menerima nama file sebagai input. Yang Anda butuhkan untuk menjalankan ini adalah mengimpor modul ini ke celery_uncovered/celery.py di akhir file:
import celery_uncovered.tricks.celery_conf Pencatat tugas tertentu dapat diterima dengan memanggil get_task_logger(task_name) . Untuk menggeneralisasi perilaku seperti itu untuk setiap tugas, perlu sedikit memperluas celery.current_app.Task dengan beberapa metode utilitas:
File: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) Sekarang, dalam kasus panggilan ke task.log_msg("Hello, my name is: %s", task.request.id) , keluaran log akan dialihkan ke file yang sesuai dengan nama tugas.
Mencobanya
Untuk meluncurkan dan menguji cara kerja tugas ini, pertama-tama mulai proses Seledri:
$ celery -A celery_uncovered worker -l infoKemudian Anda akan dapat menguji fungsionalitas melalui Shell:
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) Terakhir, untuk melihat hasilnya, navigasikan ke direktori celery_uncovered/logs dan buka file log terkait yang disebut celery_uncovered.tricks.tasks.add.log . Anda mungkin melihat sesuatu yang mirip seperti di bawah ini setelah menjalankan tugas ini beberapa kali:
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...Skenario 4 - Tugas Sadar Lingkup
Mari kita bayangkan sebuah aplikasi Python untuk pengguna internasional yang dibangun di atas Celery dan Django. Pengguna dapat mengatur bahasa (lokal) mana mereka menggunakan aplikasi Anda.
Anda harus merancang sistem notifikasi email multibahasa yang sadar lokal. Untuk mengirim pemberitahuan email, Anda telah mendaftarkan tugas Seledri khusus yang ditangani oleh antrian tertentu. Tugas ini menerima beberapa argumen kunci sebagai masukan dan lokal pengguna saat ini sehingga email akan dikirim dalam bahasa yang dipilih pengguna.
Sekarang bayangkan bahwa kita memiliki banyak tugas seperti itu, tetapi masing-masing tugas tersebut menerima argumen lokal. Dalam hal ini, bukankah lebih baik untuk menyelesaikannya pada tingkat abstraksi yang lebih tinggi? Di sini, kita melihat bagaimana melakukannya.
Gunakan deskripsi kasus: Secara otomatis mewarisi cakupan dari satu konteks eksekusi dan memasukkannya ke dalam konteks eksekusi saat ini sebagai parameter.
Detail Implementasi
Sekali lagi, seperti yang kami lakukan dengan pencatatan tugas, kami ingin memperluas kelas tugas dasar celery.current_app.Task dan menimpa beberapa metode yang bertanggung jawab untuk memanggil tugas. Untuk tujuan demonstrasi ini, saya mengganti metode celery.current_app.Task::apply_async . Ada tugas tambahan untuk modul ini yang akan membantu Anda menghasilkan pengganti yang berfungsi penuh.
File: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)Petunjuk kuncinya adalah meneruskan lokal saat ini sebagai argumen nilai kunci ke dalam tugas pemanggilan secara default. Jika tugas dipanggil dengan lokal tertentu sebagai argumen, maka itu tidak berubah.
Mencobanya
Untuk menguji fungsionalitas ini, mari kita definisikan tugas dummy dengan tipe ScopeBasedTask . Ini menempatkan file dengan ID lokal dan membaca kontennya sebagai JSON:
File: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) Sekarang yang perlu Anda lakukan adalah mengulangi langkah-langkah meluncurkan Celery, memulai shell, dan menguji eksekusi tugas ini pada skenario yang berbeda. Fixtures terletak di bawah celery_uncovered/tricks/fixtures/locales/ .
Kesimpulan
Posting ini bertujuan untuk mengeksplorasi Seledri dari perspektif yang berbeda. Saya mendemonstrasikan Seledri dalam contoh konvensional seperti pembuatan surat dan laporan serta trik bersama untuk beberapa kasus penggunaan bisnis khusus yang menarik. Seledri dibangun di atas filosofi berbasis data dan tim Anda dapat membuat hidup mereka lebih sederhana dengan memperkenalkannya sebagai bagian dari tumpukan sistem mereka. Mengembangkan layanan berbasis Seledri tidak terlalu rumit jika Anda memiliki pengalaman dasar Python, dan Anda harus dapat mengambilnya dengan cukup cepat. Konfigurasi default cukup baik untuk sebagian besar penggunaan, tetapi jika diperlukan, mereka bisa sangat fleksibel.
Tim kami membuat pilihan untuk menggunakan Celery sebagai back-end orkestrasi untuk pekerjaan latar belakang dan tugas jangka panjang. Kami menggunakannya secara ekstensif untuk berbagai kasus penggunaan, yang hanya sedikit yang disebutkan dalam posting ini. Kami mencerna dan menganalisis gigabyte data setiap hari, tetapi ini hanyalah permulaan dari teknik penskalaan horizontal.