
Python용 Celery에서 백그라운드 작업 워크플로 조정
게시 됨: 2022-03-11최신 웹 애플리케이션과 기본 시스템은 그 어느 때보다 빠르고 반응성이 뛰어납니다. 그러나 무거운 작업의 실행을 메인 스레드에서 처리하는 대신 전체 시스템 아키텍처의 다른 부분으로 오프로드하려는 경우가 여전히 많습니다. 이러한 작업을 식별하는 것은 다음 범주 중 하나에 속하는지 확인하는 것만큼 간단합니다.
- 정기 작업 - 특정 시간 또는 간격 후에 실행하도록 예약하는 작업(예: 월별 보고서 생성 또는 하루에 두 번 실행되는 웹 스크레이퍼).
- 타사 작업 - 웹 앱은 페이지가 로드되는 동안 다른 작업이 완료될 때까지 기다리지 않고 사용자에게 신속하게 서비스를 제공해야 합니다. ).
- 장기 실행 작업 — 복잡한 워크플로 실행(DAG 워크플로), 그래프 생성, Map-Reduce와 같은 작업 및 미디어 콘텐츠 제공(비디오, 오디오).
백그라운드 작업을 실행하는 간단한 솔루션은 별도의 스레드 또는 프로세스 내에서 실행하는 것입니다. Python은 높은 수준의 Turing 완전한 프로그래밍 언어로 불행히도 Erlang, Go, Java, Scala 또는 Akka와 일치하는 규모의 내장 동시성을 제공하지 않습니다. 이는 Tony Hoare의 Communicating Sequential Processes(CSP)를 기반으로 합니다. 반면에 Python 스레드는 전역 인터프리터 잠금(GIL)에 의해 조정되고 일정이 잡혀 여러 기본 스레드가 Python 바이트코드를 한 번에 실행하는 것을 방지합니다. GIL을 제거하는 것은 파이썬 개발자들 사이에서 많은 토론의 주제이지만 이 기사의 초점은 아닙니다. Python의 동시 프로그래밍은 구식이지만 동료 Toptaler Marcus McCurdy의 Python Multithreading Tutorial 에서 이에 대해 읽을 수 있습니다. 따라서 프로세스 간의 통신을 일관되게 설계하는 것은 오류가 발생하기 쉬운 프로세스이며 확장성에 부정적인 영향을 미치는 것은 물론이고 코드 결합 및 시스템 유지 관리 불량으로 이어집니다. 또한 Python 프로세스는 운영 체제(OS)에서 일반적인 프로세스이며 전체 Python 표준 라이브러리와 함께 중량급이 됩니다. 앱의 프로세스 수가 증가함에 따라 이러한 프로세스에서 다른 프로세스로 전환하는 것은 시간 소모적인 작업이 됩니다.
Python과의 동시성을 더 잘 이해하려면 PyCon'15에서 David Beazley의 놀라운 연설을 시청하십시오.
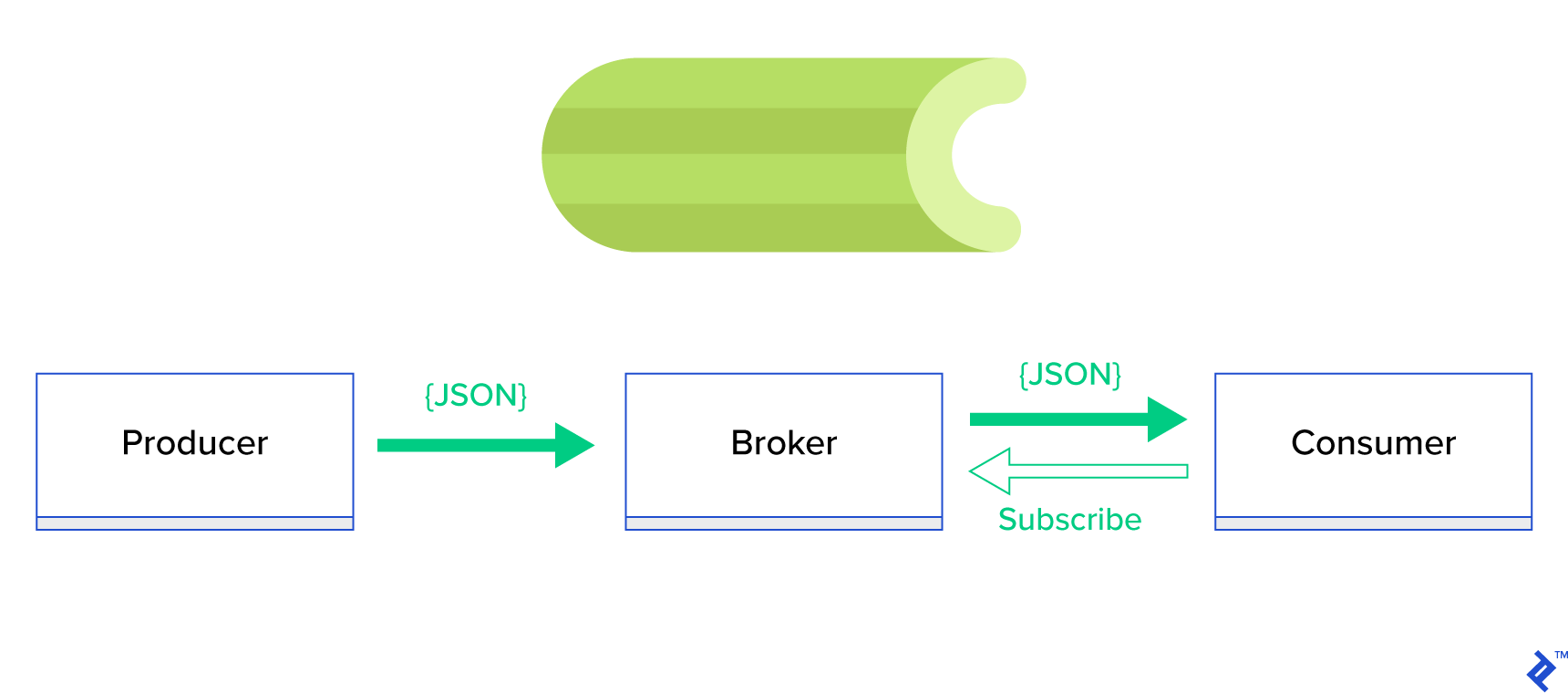
훨씬 더 나은 솔루션은 분산 큐 또는 publish-subscribe 라는 잘 알려진 형제 패러다임을 제공하는 것입니다. 그림 1에서 볼 수 있듯이 게시자 라고 하는 하나는 메시지를 보내고 구독자 라고 하는 다른 하나는 메시지를 받는 두 가지 유형의 응용 프로그램이 있습니다. 이 두 에이전트는 서로 직접 상호 작용하지 않으며 서로를 인식하지도 않습니다. 게시자는 중앙 대기열 또는 브로커 에 메시지를 보내고 구독자는 이 브로커로부터 관심 있는 메시지를 받습니다. 이 방법에는 두 가지 주요 이점이 있습니다.
- 확장성 — 에이전트는 네트워크에서 서로에 대해 알 필요가 없습니다. 그들은 주제별로 집중되어 있습니다. 따라서 각각은 비동기 방식으로 서로에 관계없이 계속해서 정상적으로 작동할 수 있습니다.
- 느슨한 결합 - 각 에이전트는 시스템(서비스, 모듈)의 해당 부분을 나타냅니다. 느슨하게 결합되어 있기 때문에 각각은 데이터 센터를 넘어 개별적으로 확장할 수 있습니다.
이러한 패러다임을 지원하고 TCP 또는 HTTP 프로토콜(예: JMS, RabbitMQ, Redis Pub/Sub, Apache ActiveMQ 등)로 구동되는 깔끔한 API를 제공하는 메시징 시스템이 많이 있습니다.
셀러리 란 무엇입니까?
Celery는 Python 세계에서 가장 인기 있는 백그라운드 작업 관리자 중 하나입니다. Celery는 RabbitMQ 또는 Redis와 같은 여러 메시지 브로커와 호환되며 생산자이자 소비자 역할을 할 수 있습니다.
Celery는 분산 메시지 전달을 기반으로 하는 비동기 작업 대기열/작업 대기열입니다. 실시간 작업에 중점을 두지만 스케줄링도 지원합니다. 작업이라고 하는 실행 단위는 다중 처리, Eventlet 또는 gevent를 사용하여 하나 이상의 작업자 서버에서 동시에 실행됩니다. 작업은 비동기적으로(백그라운드에서) 또는 동기적으로(준비될 때까지 대기) 실행할 수 있습니다. – 셀러리 프로젝트
Celery를 시작하려면 공식 문서에서 단계별 가이드를 따르세요.
이 기사의 초점은 Celery가 적용할 수 있는 사용 사례를 잘 이해하는 것입니다. 이 기사에서는 흥미로운 예를 보여줄 뿐만 아니라 백그라운드 메일링, 보고서 생성, 로깅 및 오류 보고와 같은 실제 작업에 Celery를 적용하는 방법을 배우려고 합니다. 에뮬레이션 이외의 작업을 테스트하는 방법을 공유하고 마지막으로 공식 문서에 문서화되지 않은 몇 가지 트릭을 제공할 것입니다.
Celery에 대한 이전 경험이 없는 경우 먼저 공식 자습서를 따라 사용해 보는 것이 좋습니다.
식욕을 돋우기
이 기사에 흥미가 생겨 즉시 코드에 빠져들고 싶다면 이 기사에 사용된 코드에 대해 이 GitHub 리포지토리를 따르십시오. 거기에 있는 README 파일은 예제 응용 프로그램을 실행하고 재생하기 위한 빠르고 더러운 접근 방식을 제공합니다.
셀러리의 첫걸음
우선 Celery가 사소해 보이는 작업을 얼마나 간단하고 우아하게 해결하는지 독자에게 보여주는 일련의 실제 사례를 살펴보겠습니다. 모든 예제는 Django 프레임워크 내에서 제공됩니다. 그러나 대부분은 다른 Python 프레임워크(Flask, Pyramid)로 쉽게 이식될 수 있습니다.
프로젝트 레이아웃은 Cookiecutter Django에 의해 생성되었습니다. 그러나 제 생각에는 이러한 사용 사례의 개발 및 준비를 용이하게 하는 몇 가지 종속성만 유지했습니다. 또한 노이즈를 줄이고 코드를 더 쉽게 이해할 수 있도록 이 게시물과 애플리케이션에 불필요한 모듈을 제거했습니다.
- celery_uncovered/ - celery_uncovered/__init__.py - celery_uncovered/{toyex,tricks,advex} - celery_uncovered/celery.py - config/settings/{base,local,test}.py - config/urls.py - manage.py-
celery_uncovered/{toyex,tricks,advex}에는 이 게시물에서 다룰 다양한 애플리케이션이 포함되어 있습니다. 각 응용 프로그램에는 필요한 Celery 이해 수준에 따라 구성된 일련의 예제가 포함되어 있습니다. -
celery_uncovered/celery.py는 Celery 인스턴스를 정의합니다.
파일: celery_uncovered/celery.py :
from __future__ import absolute_import import os from celery import Celery, signals # set the default Django settings module for the 'celery' program. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local') app = Celery('celery_uncovered') # Using a string here means the worker will not have to # pickle the object when using Windows. app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() 그런 다음 Celery가 Django와 함께 시작되도록 해야 합니다. 이러한 이유로 celery_uncovered/__init__.py 에서 앱을 가져옵니다.
파일: celery_uncovered/__init__.py :
from __future__ import absolute_import # This will make sure the app is always imported when # Django starts so that shared_task will use this app. from .celery import app as celery_app # noqa __all__ = ['celery_app'] __version__ = '0.0.1' __version_info__ = tuple([int(num) if num.isdigit() else num for num in __version__.replace('-', '.', 1).split('.')]) config/settings 는 앱과 Celery의 구성 소스입니다. 실행 환경에 따라 Django는 해당 설정을 시작합니다: 개발용 local.py 또는 테스트용 test.py 원하는 경우 새 파이썬 모듈(예: prod.py )을 만들어 자신만의 환경을 정의할 수도 있습니다. 셀러리 구성에는 CELERY_ 접두사가 붙습니다. 이 게시물에서는 RabbitMQ를 브로커로, SQLite를 결과 bac-end로 구성했습니다.
파일: config/local.py :
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='amqp://guest:guest@localhost:5672//') CELERY_RESULT_BACKEND = 'django-db+sqlite:///results.sqlite'시나리오 1 - 보고서 생성 및 내보내기
우리가 다룰 첫 번째 사례는 보고서 생성 및 내보내기입니다. 이 예에서는 CSV 보고서를 생성하는 작업을 정의하고 celerybeat를 사용하여 정기적으로 일정을 잡는 방법을 배웁니다.
사용 사례 설명: 선택한 기간(일, 주, 월)별로 GitHub에서 가장 인기 있는 저장소 500개를 가져와서 주제별로 그룹화하고 결과를 CSV 파일로 내보냅니다.
"보고서 생성"이라는 버튼을 클릭하여 트리거된 이 기능을 실행할 HTTP 서비스를 제공하면 애플리케이션이 중지되고 HTTP 응답을 다시 보내기 전에 작업이 완료될 때까지 기다립니다. 이것은 나쁘다. 우리는 웹 애플리케이션이 빠르기를 원하고 백엔드가 결과를 계산하는 동안 사용자가 기다리기를 원하지 않습니다. 결과가 생성되기를 기다리는 대신 Celery에 등록된 대기열을 통해 작업자 프로세스에 작업을 대기열에 넣고 프론트 엔드에 task_id 로 응답합니다. 그런 다음 프런트 엔드는 task_id 를 사용하여 비동기 방식(예: AJAX)으로 작업 결과를 쿼리하고 사용자에게 작업 진행 상황을 계속 업데이트합니다. 마지막으로 프로세스가 완료되면 결과를 HTTP를 통해 다운로드할 파일로 제공할 수 있습니다.
구현 세부 정보
우선, 프로세스를 가능한 가장 작은 단위로 분해하고 파이프라인을 생성하겠습니다.
- 가져오기는 GitHub 서비스에서 리포지토리를 가져오는 일을 담당하는 작업자입니다.
- Aggregator 는 결과를 하나의 목록으로 통합하는 일을 담당하는 작업자입니다.
- Importer 는 GitHub에서 가장 인기 있는 리포지토리의 CSV 보고서를 생성하는 작업자입니다.
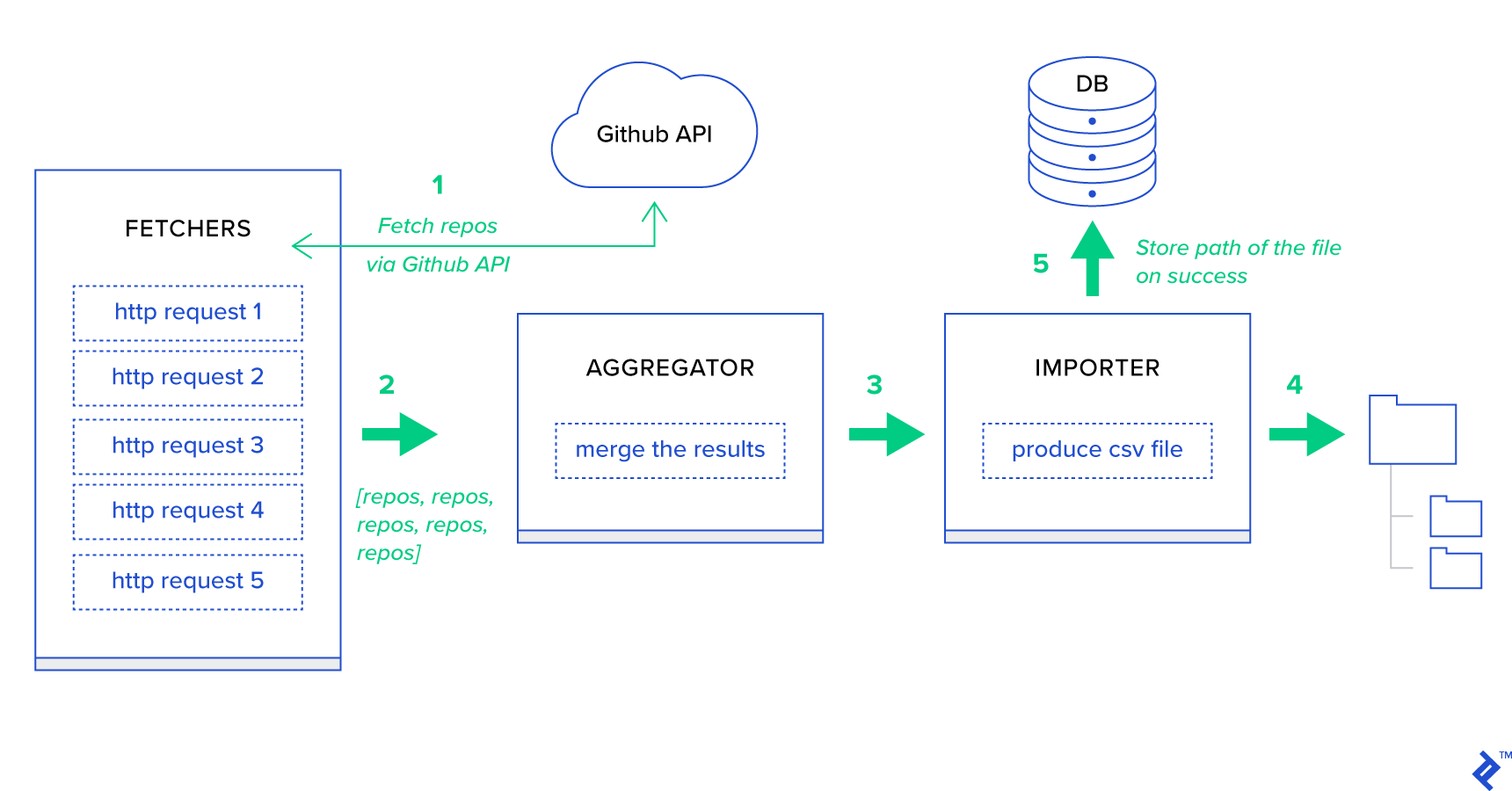
리포지토리 가져오기는 GitHub Search API GET /search/repositories 를 사용하는 HTTP 요청입니다. 그러나 처리해야 하는 GitHub API 서비스의 제한이 있습니다. API는 요청당 500개 대신 최대 100개의 리포지토리를 반환합니다. 한 번에 하나씩 5개의 요청을 보낼 수 있지만 사용자를 기다리게 하고 싶지 않습니다. HTTP 요청은 I/O 바운드 작업이므로 5개의 개별 요청에 대해 대신 적절한 페이지 매개변수를 사용하여 5개의 동시 HTTP 요청을 실행할 수 있습니다. 따라서 페이지는 [1..5] 범위에 있습니다. toyex/tasks.py 모듈에 fetch_hot_repos/3 -> list 라는 작업을 정의해 보겠습니다.
파일: celery_uncovered/toyex/local.py
@shared_task def fetch_hot_repos(since, per_page, page): payload = { 'sort': 'stars', 'order': 'desc', 'q': 'created:>={date}'.format(date=since), 'per_page': per_page, 'page': page, 'access_token': settings.GITHUB_OAUTH} headers = {'Accept': 'application/vnd.github.v3+json'} connect_timeout, read_timeout = 5.0, 30.0 r = requests.get( 'https://api.github.com/search/repositories', params=payload, headers=headers, timeout=(connect_timeout, read_timeout)) items = r.json()[u'items'] return items 따라서 fetch_hot_repos 는 GitHub API에 대한 요청을 생성하고 저장소 목록으로 사용자에게 응답합니다. 요청 페이로드를 정의하는 세 가지 매개변수를 수신합니다.
-
since— 생성 날짜를 기준으로 리포지토리를 필터링합니다. -
per_page— 요청당 반환할 결과 수(100개로 제한됨). -
page— 요청된 페이지 번호(범위 [1..5]).
참고: GitHub Search API를 사용하려면 인증 확인을 통과하기 위한 OAuth 토큰이 필요합니다. 우리의 경우 GITHUB_OAUTH 아래의 설정에 저장됩니다.
다음으로 결과를 집계하고 이를 CSV 파일로 내보내는 역할을 하는 마스터 작업을 정의해야 합니다 produce_hot_repo_report_task/2->filepath:
파일: celery_uncovered/toyex/local.py
@shared_task def produce_hot_repo_report(period, ref_date=None): # 1. parse date ref_date_str = strf_date(period, ref_date=ref_date) # 2. fetch and join fetch_jobs = group([ fetch_hot_repos.s(ref_date_str, 100, 1), fetch_hot_repos.s(ref_date_str, 100, 2), fetch_hot_repos.s(ref_date_str, 100, 3), fetch_hot_repos.s(ref_date_str, 100, 4), fetch_hot_repos.s(ref_date_str, 100, 5) ]) # 3. group by language and # 4. create csv return chord(fetch_jobs)(build_report_task.s(ref_date_str)).get() @shared_task def build_report_task(results, ref_date): all_repos = [] for repos in results: all_repos += [Repository(repo) for repo in repos] # 3. group by language grouped_repos = {} for repo in all_repos: if repo.language in grouped_repos: grouped_repos[repo.language].append(repo.name) else: grouped_repos[repo.language] = [repo.name] # 4. create csv lines = [] for lang in sorted(grouped_repos.keys()): lines.append([lang] + grouped_repos[lang]) filename = '{media}/github-hot-repos-{date}.csv'.format(media=settings.MEDIA_ROOT, date=ref_date) return make_csv(filename, lines) 이 작업은 celery.canvas.group 을 사용하여 5개의 fetch_hot_repos/3 동시 호출을 실행합니다. 이러한 결과는 기다린 다음 리포지토리 개체 목록으로 축소됩니다. 그런 다음 결과 세트가 주제별로 그룹화되고 최종적으로 MEDIA_ROOT/ 디렉토리 아래에 생성된 CSV 파일로 내보내집니다.
작업을 주기적으로 예약하기 위해 구성 파일의 일정 목록에 항목을 추가할 수 있습니다.
파일: config/local.py
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'produce-csv-reports': { 'task': 'celery_uncovered.toyex.tasks.produce_hot_repo_report_task', 'schedule': crontab(minute=0, hour=0) # midnight, 'args': ('today',) }, }그것을 밖으로 시도
작업이 어떻게 작동하는지 시작하고 테스트하려면 먼저 Celery 프로세스를 시작해야 합니다.
$ celery -A celery_uncovered worker -l info 다음으로 celery_uncovered/media/ 디렉토리를 생성해야 합니다. 그런 다음 Shell 또는 Celerybeat를 통해 기능을 테스트할 수 있습니다.
쉘 :
from datetime import date from celery_uncovered.toyex.tasks import produce_hot_repo_report_task produce_hot_repo_report_task.delay('today').get(timeout=5)셀러리비트 :
# Start celerybeat with the following command $ celery -A celery_uncovered beat -l info MEDIA_ROOT/ 디렉토리에서 결과를 볼 수 있습니다.
시나리오 2 - 이메일을 통해 Server 500 오류 보고
Celery의 가장 일반적인 사용 사례 중 하나는 이메일 알림을 보내는 것입니다. 이메일 알림은 로컬 SMTP 서버 또는 타사 SES를 활용하는 오프라인 I/O 바인딩 작업입니다. 이메일 전송과 관련된 많은 사용 사례가 있으며 대부분의 경우 사용자는 HTTP 응답을 받기 전에 이 프로세스가 완료될 때까지 기다릴 필요가 없습니다. 그렇기 때문에 백그라운드에서 이러한 작업을 실행하고 사용자에게 즉시 응답하는 것이 좋습니다.

사용 사례 설명: Celery를 통해 관리자 이메일에 50X 오류를 보고합니다.
Python과 Django는 시스템 로깅을 수행하는 데 필요한 배경 지식을 갖추고 있습니다. Python의 로깅이 실제로 어떻게 작동하는지 자세히 설명하지 않겠습니다. 그러나 이전에 시도한 적이 없거나 새로고침이 필요한 경우 내장된 로깅 모듈의 설명서를 읽으십시오. 프로덕션 환경에서 이것을 원할 것입니다. Django에는 수신하는 각 로그 메시지에 대해 관리자에게 이메일을 보내는 AdminEmailHandler라는 특수 로거 처리기가 있습니다.
구현 세부 정보
주요 아이디어는 Celery를 통해 메일을 보낼 수 있는 방식으로 AdminEmailHandler 클래스의 send_mail 메소드를 확장하는 것입니다. 이는 아래 그림과 같이 수행할 수 있습니다.
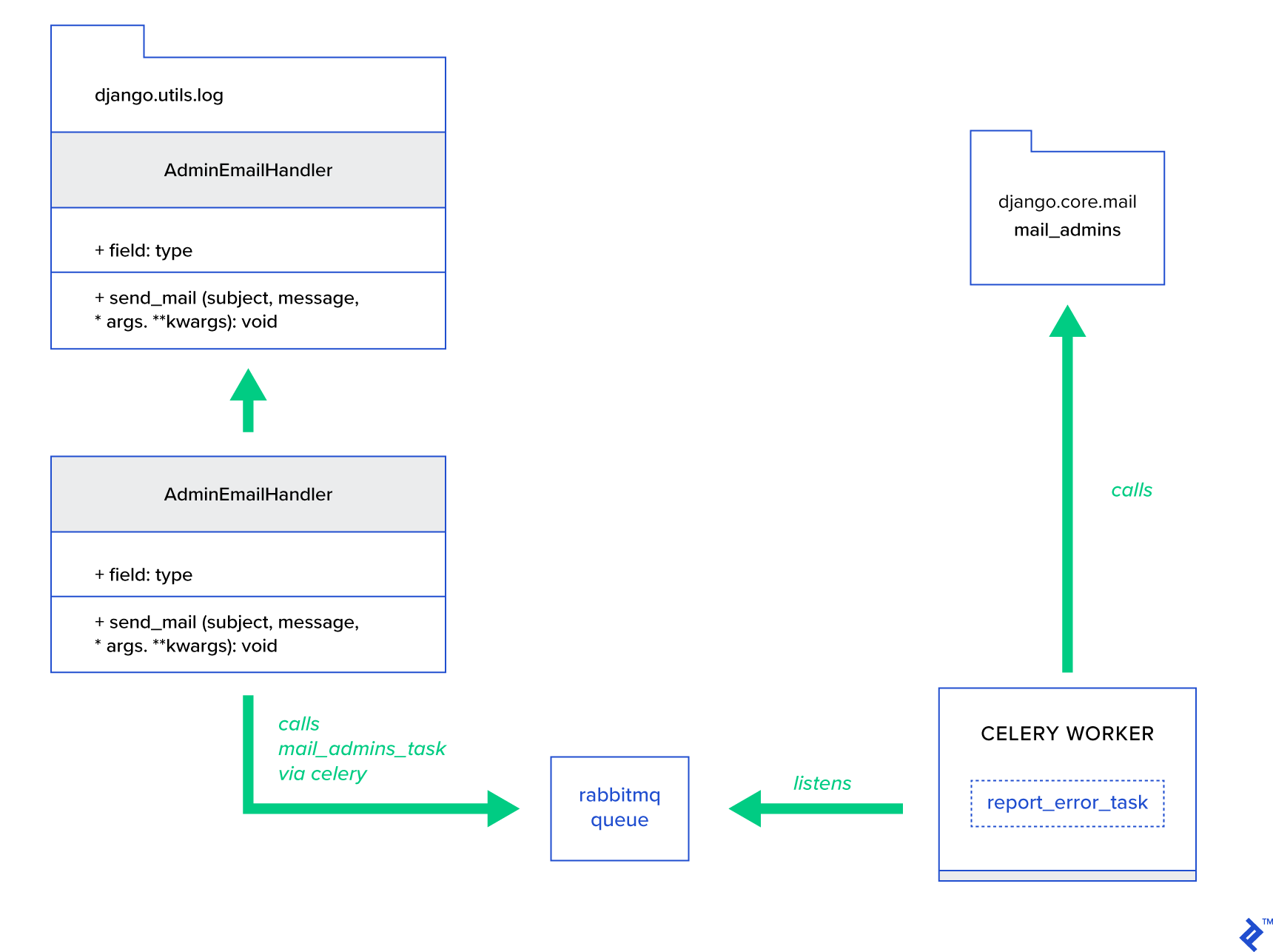
먼저 제공된 제목과 메시지로 mail_admins 를 호출하는 report_error_task 라는 작업을 설정해야 합니다.
파일: celery_uncovered/toyex/tasks.py
@shared_task def report_error_task(subject, message, *args, **kwargs): mail_admins(subject, message, *args, **kwargs)다음으로, 내부적으로 정의된 Celery 작업만 호출하도록 AdminEmailHandler를 실제로 확장합니다.
파일: celery_uncovered/toyex/admin_email.py
from django.utils.log import AdminEmailHandler from celery_uncovered.handlers.tasks import report_error_task class CeleryHandler(AdminEmailHandler): def send_mail(self, subject, message, *args, **kwargs): report_error_task.delay(subject, message, *args, **kwargs) 마지막으로 로깅을 설정해야 합니다. Django의 로그인 구성은 매우 간단합니다. 필요한 것은 로깅 엔진이 새로 정의된 핸들러를 사용하여 시작하도록 LOGGING 을 재정의하는 것입니다.
파일 config/settings/local.py
LOGGING = { 'version': 1, 'disable_existing_loggers': False, ..., 'handlers': { ... 'mail_admins': { 'level': 'ERROR', 'filters': ['require_debug_true'], 'class': 'celery_uncovered.toyex.log_handlers.admin_email.CeleryHandler' } }, 'loggers': { 'django': { 'handlers': ['console', 'mail_admins'], 'level': 'INFO', }, ... } } 응용 프로그램이 디버그 모드에서 실행되는 동안 이 기능을 테스트하기 위해 의도적으로 핸들러 필터 require_debug_true 를 설정했습니다.
그것을 밖으로 시도
이를 테스트하기 위해 localhost:8000/report-error 에서 "0으로 나누기" 작업을 제공하는 Django 보기를 준비했습니다. 또한 이메일이 실제로 전송되었는지 테스트하려면 MailHog Docker 컨테이너를 시작해야 합니다.
$ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ CELERY_TASKSK_ALWAYS_EAGER=False python manage.py runserver $ # with your browser navigate to [http://localhost:8000](http://localhost:8000) $ # now check your outgoing emails by vising web UI [http://localhost:8025](http://localhost:8025)추가 세부 사항
메일 테스트 도구로 MailHog를 설정하고 SMTP 배달에 사용하도록 Django 메일링을 구성했습니다. MailHog를 배포하고 실행하는 방법에는 여러 가지가 있습니다. Docker 컨테이너를 사용하기로 결정했습니다. 해당 README 파일에서 세부 정보를 찾을 수 있습니다.
파일: docker/mailhog/README.md
$ docker build . -f docker/mailhog/Dockerfile -t mailhog/mailhog:latest $ docker run -d -p 1025:1025 -p 8025:8025 mailhog/mailhog $ # navigate with your browser to localhost:8025MailHog를 사용하도록 애플리케이션을 구성하려면 구성에 다음 줄을 추가해야 합니다.
파일: config/settings/local.py
EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.smtp.EmailBackend') EMAIL_PORT = 1025 EMAIL_HOST = env('EMAIL_HOST', default='mailhog')기본 셀러리 작업 너머
셀러리 작업은 호출 가능한 모든 함수에서 만들 수 있습니다. 기본적으로 모든 사용자 정의 작업에는 celery.app.task.Task 가 상위(추상) 클래스로 삽입됩니다. 이 클래스에는 작업을 비동기적으로(네트워크를 통해 Celery 작업자에게 전달) 또는 동기적으로(테스트 목적으로) 실행하고 서명 및 기타 여러 유틸리티를 생성하는 기능이 포함되어 있습니다. 다음 예제에서는 Celery.app.task.Task 를 확장한 다음 작업에 몇 가지 유용한 동작을 추가하기 위해 기본 클래스로 사용합니다.
시나리오 3 - 작업당 파일 로깅
내 프로젝트 중 하나에서 최종 사용자에게 엄청난 양의 계층적 데이터를 수집하고 필터링할 수 있는 ETL(추출, 변환, 로드)과 유사한 도구를 제공하는 앱을 개발 중이었습니다. 백엔드는 두 개의 모듈로 분할되었습니다.
- Celery를 사용한 데이터 처리 파이프라인의 오케스트레이션
- Go를 사용한 데이터 처리
Celery는 하나의 Celerybeat 인스턴스와 40명 이상의 작업자와 함께 배포되었습니다. 파이프라인과 오케스트레이션 활동을 구성하는 20개 이상의 다른 작업이 있었습니다. 이러한 각 작업은 어느 시점에서 실패할 수 있습니다. 이러한 모든 실패는 각 작업자의 시스템 로그에 덤프되었습니다. 어느 시점에서 Celery 계층을 디버그하고 유지 관리하는 것이 불편해지기 시작했습니다. 결국 우리는 작업 로그를 작업 특정 파일로 분리하기로 결정했습니다.
사용 사례 설명: 각 작업이 표준 출력과 오류를 파일에 기록하도록 Celery를 확장합니다.
Celery는 Python 응용 프로그램이 내부적으로 수행하는 작업을 완벽하게 제어할 수 있도록 합니다. 친숙한 신호 프레임워크와 함께 제공됩니다. Celery를 사용하는 응용 프로그램은 특정 작업의 동작을 강화하기 위해 그 중 몇 가지를 구독할 수 있습니다. 개별 작업 수명 주기에 대한 자세한 추적을 제공하기 위해 작업 수준 신호를 활용할 것입니다. Celery는 항상 로깅 백엔드와 함께 제공되며 목표를 달성하기 위해 일부 위치에서 약간만 재정의하면서 이점을 활용할 것입니다.
구현 세부 정보
Celery는 이미 작업당 로깅을 지원합니다. 파일에 저장하려면 로그 출력을 적절한 위치로 보내야 합니다. 우리의 경우 작업의 적절한 위치는 작업 이름과 일치하는 파일입니다. Celery 인스턴스에서 우리는 내장된 로깅 구성을 동적으로 추론된 로깅 핸들러로 재정의할 것입니다. celeryd_after_setup 신호를 구독하고 거기에서 시스템 로깅을 구성할 수 있습니다.
파일: celery_uncovered/toyex/celery_conf.py
@signals.celeryd_after_setup.connect def configure_task_logging(instance=None, **kwargs): tasks = instance.app.tasks.keys() LOGS_DIR = settings.ROOT_DIR.path('logs') if not os.path.exists(str(LOGS_DIR)): os.makedirs(str(LOGS_DIR)) print 'dir created' default_handler = { 'level': 'DEBUG', 'filters': None, 'class': 'logging.FileHandler', 'filename': '' } default_logger = { 'handlers': [], 'level': 'DEBUG', 'propogate': True } LOG_CONFIG = { 'version': 1, # 'incremental': True, 'disable_existing_loggers': False, 'handlers': {}, 'loggers': {} } for task in tasks: task = str(task) if not task.startswith('celery_uncovered.'): continue task_handler = copy_dict(default_handler) task_handler['filename'] = str(LOGS_DIR.path(task + ".log")) task_logger = copy_dict(default_logger) task_logger['handlers'] = [task] LOG_CONFIG['handlers'][task] = task_handler LOG_CONFIG['loggers'][task] = task_logger logging.config.dictConfig(LOG_CONFIG) Celery 앱에 등록된 각 작업에 대해 핸들러를 사용하여 해당 로거를 빌드하고 있습니다. 각 처리기는 logging.FileHandler 유형이므로 이러한 각 인스턴스는 파일 이름을 입력으로 받습니다. 이 모듈을 실행하는 데 필요한 것은 파일 끝에서 이 모듈을 celery_uncovered/celery.py 로 가져오는 것입니다.
import celery_uncovered.tricks.celery_conf get_task_logger(task_name) 를 호출하여 특정 작업 로거를 수신할 수 있습니다. 각 작업에 대해 이러한 동작을 일반화하려면 몇 가지 유틸리티 메서드를 사용하여 celery.current_app.Task 를 약간 확장해야 합니다.
파일: celery_uncovered/tricks/celery_ext.py
class LoggingTask(current_app.Task): abstract = True ignore_result = False @property def logger(self): logger = get_task_logger(self.name) return logger def log_msg(self, msg, *msg_args): self.logger.debug(msg, *msg_args) 이제 task.log_msg("Hello, my name is: %s", task.request.id) 에 대한 호출의 경우 로그 출력이 작업 이름 아래의 해당 파일로 라우팅됩니다.
그것을 밖으로 시도
이 작업이 어떻게 작동하는지 시작하고 테스트하려면 먼저 Celery 프로세스를 시작하십시오.
$ celery -A celery_uncovered worker -l info그런 다음 Shell을 통해 기능을 테스트할 수 있습니다.
from datetime import date from celery_uncovered.tricks.tasks import add add.delay(1, 3) 마지막으로 결과를 보려면 celery_uncovered/logs 디렉터리로 이동하여 celery_uncovered.tricks.tasks.add.log 라는 해당 로그 파일을 엽니다. 이 작업을 여러 번 실행하면 아래와 비슷한 내용이 표시될 수 있습니다.
Result of 1 + 2 = 3 Result of 1 + 2 = 3 ...시나리오 4 - 범위 인식 작업
Celery와 Django를 기반으로 구축된 해외 사용자를 위한 Python 애플리케이션을 상상해 보겠습니다. 사용자는 애플리케이션을 사용하는 언어(로케일)를 설정할 수 있습니다.
다국어, 로케일 인식 이메일 알림 시스템을 설계해야 합니다. 이메일 알림을 보내려면 특정 대기열에서 처리하는 특별한 Celery 작업을 등록해야 합니다. 이 작업은 이메일이 사용자가 선택한 언어로 전송될 수 있도록 입력 및 현재 사용자 로캘로 몇 가지 주요 인수를 받습니다.
이제 이러한 작업이 많이 있지만 각 작업은 로케일 인수를 허용한다고 상상해 보십시오. 이 경우 더 높은 수준의 추상화에서 해결하는 것이 좋지 않을까요? 여기에서 우리는 그것을 하는 방법을 봅니다.
사용 사례 설명: 하나의 실행 컨텍스트에서 자동으로 범위를 상속하고 현재 실행 컨텍스트에 매개변수로 삽입합니다.
구현 세부 정보
다시 말하지만, 작업 로깅과 마찬가지로 기본 작업 클래스 celery.current_app.Task 를 확장하고 작업 호출을 담당하는 몇 가지 메서드를 재정의하려고 합니다. 이 데모에서는 celery.current_app.Task::apply_async 메서드를 재정의합니다. 이 모듈에는 완전히 작동하는 교체품을 생성하는 데 도움이 되는 추가 작업이 있습니다.
파일: celery_uncovered/tricks/celery_ext.py
class ScopeBasedTask(current_app.Task): abstract = True ignore_result = False default_locale_id = DEFAULT_LOCALE_ID scope_args = ('locale_id',) def __init__(self, *args, **kwargs): super(ScopeBasedTask, self).__init__(*args, **kwargs) self.set_locale(locale=kwargs.get('locale_id', None)) def set_locale(self, scenario_id=None): self.locale_id = self.default_locale_id if locale_id: self.locale_id = locale_id else: self.locale_id = get_current_locale().id def apply_async(self, args=None, kwargs=None, **other_kwargs): self.inject_scope_args(kwargs) return super(ScopeBasedTask, self).apply_async(args=args, kwargs=kwargs, **other_kwargs) def __call__(self, *args, **kwargs): task_rv = super(ScopeBasedTask, self).__call__(*args, **kwargs) return task_rv def inject_scope_args(self, kwargs): for arg in self.scope_args: if arg not in kwargs: kwargs[arg] = getattr(self, arg)핵심 단서는 기본적으로 현재 로케일을 키-값 인수로 호출 작업에 전달하는 것입니다. 특정 로케일을 인수로 사용하여 태스크가 호출된 경우 변경되지 않습니다.
그것을 밖으로 시도
이 기능을 테스트하기 위해 ScopeBasedTask 유형의 더미 작업을 정의하겠습니다. 로케일 ID로 파일을 찾고 내용을 JSON으로 읽습니다.
파일: celery_uncovered/tricks/tasks.py
@shared_task(bind=True, base=ScopeBasedTask) def read_scenario_file_task(self, **kwargs): fixture_parts = ["locales", "sc_%i.json" % kwargs['scenario_id']] return read_fixture(*fixture_parts) 이제 Celery를 시작하고, 셸을 시작하고, 다양한 시나리오에서 이 작업의 실행을 테스트하는 단계를 반복해야 합니다. 설비는 celery_uncovered/tricks/fixtures/locales/ 디렉토리 아래에 있습니다.
결론
이 게시물은 다양한 관점에서 셀러리를 탐색하는 것을 목표로 했습니다. 나는 메일링 및 보고서 생성과 같은 기존 예제에서 Celery를 시연했으며 흥미로운 틈새 비즈니스 사용 사례에 대한 공유 트릭을 보여주었습니다. Celery는 데이터 중심 철학을 기반으로 구축되었으며 팀은 이를 시스템 스택의 일부로 도입하여 삶을 훨씬 더 단순하게 만들 수 있습니다. 기본적인 Python 경험이 있다면 Celery 기반 서비스를 개발하는 것이 그리 복잡하지 않으며 상당히 빨리 익힐 수 있습니다. 기본 구성은 대부분의 용도에 충분하지만 필요한 경우 매우 유연할 수 있습니다.
우리 팀은 백그라운드 작업과 장기 실행 작업을 위한 오케스트레이션 백엔드로 Celery를 사용하기로 결정했습니다. 우리는 이 포스트에서 몇 가지만 언급한 다양한 사용 사례에 대해 광범위하게 사용합니다. 우리는 매일 기가바이트의 데이터를 수집하고 분석하지만 이것은 수평적 확장 기술의 시작에 불과합니다.