
Hadoop 中的 Apache Pig 架构:特性、应用程序、执行流程
已发表: 2020-06-26目录
为什么 Apache Pig 如此受欢迎
为了分析和处理大数据,Hadoop 使用 Map Reduce。 Map Reduce 是一个用 Java 编写的程序。 但是,开发人员发现编写和维护这些冗长的 Java 代码具有挑战性。 使用 Apache Pig,开发人员可以快速分析和处理大型数据集,而无需使用复杂的 Java 代码。 雅虎研究人员开发的 Apache Pig 在大量数据集上执行 Map Reduce 作业,并为开发人员提供了一个简单的界面来有效地处理数据。
Apache Pig 的出现对于那些不懂 Java 编程的人来说是一个福音。 今天,Apache Pig 在开发人员中变得非常流行,因为它提供了灵活性、降低了代码复杂性并且需要的工作量更少。 如果您是初学者并且有兴趣了解有关数据科学的更多信息,请查看我们来自顶尖大学的数据科学课程。
Map Reduce 与 Apache Pig
下表总结了 Map Reduce 和 Apache Pig 的区别:
| 阿帕奇猪 | 地图缩减 |
| 脚本语言 | 编译语言 |
| 提供更高层次的抽象 | 提供低层次的抽象 |
| 需要几行代码(10行代码可以总结200行Map Reduce代码) | 需要更广泛的代码(更多代码行) |
| 需要更少的开发时间和精力 | 需要更多的开发时间和精力 |
| 代码效率较低 | 与 Apache Pig 相比,代码效率更高 |
Apache Pig 特性
Apache Pig 提供以下功能:
- 允许程序员编写更少的代码行。 程序员可以使用 Pig Latin 语言仅用 10 行代码编写 200 行 Java 代码。
- Apache Pig 多查询方法减少了开发时间。
- Apache pig 拥有丰富的数据集,用于执行连接、过滤、排序、加载、分组等操作。
- Pig Latin 语言与 SQL 非常相似。 具有良好 SQL 知识的程序员发现编写 Pig 脚本很容易。
- 允许程序员编写更少的代码行。 程序员可以使用 Pig Latin 语言仅用 10 行代码编写 200 行 Java 代码。
- Apache Pig 处理结构化和非结构化数据分析。
Apache Pig 应用程序
一些 Apache Pig 应用程序是:
- 处理大量数据
- 支持跨大型数据集的快速原型设计和临时查询
- 在搜索平台中执行数据处理
- 处理时间敏感的数据加载
- 电信公司用于对用户通话数据信息进行去标识化。
什么是阿帕奇猪?
Map Reduce 需要将程序转换为 map 和 reduce 阶段。 由于并非所有数据分析师都熟悉 Map Reduce,因此雅虎研究人员引入了 Apache pig 来弥补这一差距。 Pig 构建在 Hadoop 之上,提供了高级抽象,使程序员能够花费更少的时间编写复杂的 Map Reduce 程序。 猪不是首字母缩略词; 它以家畜命名。 作为动物猪吃任何东西,猪可以处理任何类型的数据。

资源
Hadoop 中的 Apache Pig 架构
Apache Pig 架构由一个 Pig Latin 解释器组成,它使用 Pig Latin 脚本来处理和分析海量数据集。 程序员使用 Pig Latin 语言分析 Hadoop 环境中的大型数据集。 Apache pig 拥有丰富的数据集,用于执行不同的数据操作,如连接、过滤、排序、加载、分组等。
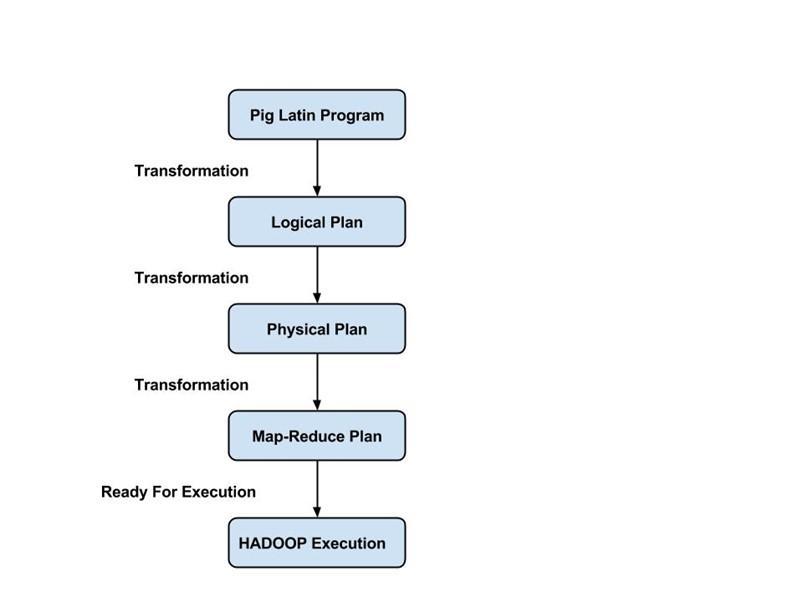
程序员必须使用 Pig Latin 语言编写 Pig 脚本来执行特定任务。 Pig 将这些 Pig 脚本转换为一系列 Map-Reduce 作业,以简化程序员的工作。 Pig Latin 程序通过各种机制执行,例如 UDF、嵌入式和 Grunt shell。
Apache Pig 架构由以下主要组件组成:
- 解析器
- 优化器
- 编译器
- 执行引擎
- 执行模式
让我们详细研究所有这些 Pig 组件。
猪拉丁文
Pig 脚本被提交到 Pig 执行环境以产生所需的结果。
您可以使用以下方法之一执行 Pig 脚本:
- 咕噜壳
- 脚本文件
- 嵌入式脚本
解析器
Parser 处理所有 Pig Latin 语句或命令。 Parser 对 Pig 语句执行多项检查,如语法检查、类型检查,并生成DAG(有向无环图)输出。 DAG 输出将脚本的所有逻辑运算符表示为节点,将数据流表示为边。

优化器
解析操作完成并生成 DAG 输出后,将输出传递给优化器。 优化器然后对输出执行优化活动,例如拆分、合并、投影、下推、转换和重新排序等。优化器处理提取的数据并通过执行下推和投影活动省略不必要的数据或列,提高查询性能.
编译器
编译器将优化器生成的输出编译成一系列 Map Reduce 作业。 编译器自动将 Pig 作业转换为 Map Reduce 作业,并通过重新排列执行顺序来优化性能。
执行引擎
在执行完上述所有操作后,这些 Map Reduce 作业被提交给执行引擎,然后在 Hadoop 平台上执行以产生所需的结果。 然后,您可以使用 DUMP 语句在屏幕上显示结果或使用 STORE 语句将结果存储在HDFS (Hadoop 分布式文件系统)中。
执行模式
Apache Pig 以本地和 Map Reduce 两种执行模式执行。 执行模式的选择取决于数据的存储位置以及您要运行 Pig 脚本的位置。 您可以将数据存储在本地(在单台机器中)或分布式 Hadoop 集群环境中。
- 本地模式——如果您的数据集很小,您可以使用本地模式。 在本地模式下,Pig 使用本地主机和文件系统在单个 JVM 中运行。 在这种模式下,并行映射器执行是不可能的,因为所有文件都安装并在本地主机上运行。 您可以使用pig -x local命令指定本地模式。
- Map Reduce 模式——Apache Pig 默认使用 Map Reduce 模式。 在 Map Reduce 模式下,程序员对已存储在HDFS(Hadoop 分布式文件系统)中的数据执行 Pig Latin 语句。 您可以使用pig -x mapreduce命令指定 Map-Reduce 模式。
资源
猪拉丁数据模型
Pig Latin 数据模型允许 Pig 处理任何类型的数据。 Pig Latin 数据模型是完全嵌套的,可以处理整数、浮点数等原子数据类型和 Map 和元组等非原子复杂数据类型。
让我们深入了解数据模型:
- 原子——原子是以字符串形式存储的单个值,可以用作数字和字符串。 Pig 的原子值是整数、双精度、浮点数、字节数组和字符数组。 单个原子值也称为字段。
例如,“Kiara”或 27
- 元组 –元组是包含一组有序字段(任何类型)的记录。 元组与RDBMS(关系数据库管理系统)中的行非常相似。
例如,(Kiara,27 岁)
- Bag –原子是以字符串形式存储的单个值,可以用作数字和字符串。 Pig 的原子值是整数、双精度、浮点数、字节数组和字符数组。 单个原子值也称为字段。
例如,{(Kiara, 27), (Kehsav, 45)}
- Map –键值对集合称为映射。 键必须是唯一的,并且应该是 char 数组类型。 但是,该值可以是任何类型。
例如,[姓名#Kiara,年龄#27]
- 关系——一袋元组称为关系。
Pig Job的执行流程
以下步骤解释了 Pig 作业的执行流程:
- 开发人员使用 Pig Latin 语言编写 Pig 脚本并将其存储在本地文件系统中。
- 提交 Pig 脚本后,Apache Pig 与编译器建立连接并生成一系列 Map Reduce Jobs 作为输出。
- Pig 编译器从 HDFS 接收原始数据执行操作,并在 Map Reduce 作业完成后将结果存储到 HDFS。
另请阅读: Apache Pig 教程
结论
在这篇博客中,我们了解了Apache Pig 架构、Pig 组件、Map Reduce 和 Apache Pig 的区别、Pig Latin 数据模型以及 Pig 作业的执行流程。
Apache Pig 对程序员来说是一个福音,因为它提供了一个具有简单界面的平台,降低了代码复杂性,并帮助他们有效地实现了结果。 雅虎、eBay、LinkedIn 和 Twitter 是使用 Pig 处理大量数据的一些公司。
如果您想了解 Apache Pig、数据科学,请查看 IIIT-B 和 upGrad 的数据科学执行 PG 计划,该计划是为在职专业人士创建的,并提供 10 多个案例研究和项目、实用的实践研讨会、行业指导专家,与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
Apache Pig 的特点是什么?
Apache Pig 是一个非常高级的工具或平台,用于处理大型数据集。 数据分析代码是使用称为 Pig Latin 的高级脚本语言开发的。 首先,程序员将编写 Pig Latin 脚本,将数据处理成特定的地图并减少任务。 Apache Pig 有很多特性,这使它成为一个非常有用的工具。
1. 提供丰富的运算符集来执行不同的操作,如排序、连接、过滤等。
2. Apache Pig 被认为是 SQL 程序员的福音,因为它易于学习、阅读和编写。
3. 制作用户定义的功能和流程很容易
4. 任何流程或功能都需要更少的代码行
5. 允许用户对非结构化和结构化数据进行分析
6. Join 和 Split 操作非常容易执行
Apache Pig 中有哪些可用的执行模式?
Apache Pig 可以以两种不同的模式执行:
1. 本地模式 - 在此模式下,所有文件都将从您的本地文件系统和本地主机安装和运行。 通常,此模式用于测试目的。 在这里,您不需要 HDFS 或 Hadoop。
2. MapReduce 模式——在 MapReduce 模式中,Apache Pig 用于加载和处理已经存在于 Hadoop 文件系统 (HDFS) 中的数据。 每当我们尝试执行 Pig Latin 语句来处理数据时,都会在后端调用 MapReduce 作业。 它将对 HDFS 中已经存在的数据执行特定操作。
Apache Pig 的一些关键应用是什么?
事实证明,Apache Pig 对那些无法熟练理解 Java 编程的程序员来说是一个福音。 Apache Pig 最好的地方在于它提供了灵活性,比其他平台需要更少的努力,并降低了代码的复杂性。
Apache Pig 的一些关键应用包括:
1.从数据集中处理大量数据
2. 在需要使用采样进行分析洞察力的每个地方都很有用
3.用于网络爬取和搜索日志形式的大量数据集的收集
4. 对大型数据集的处理算法进行原型设计所需