
Arquitectura Apache Pig en Hadoop: características, aplicaciones, flujo de ejecución
Publicado: 2020-06-26Tabla de contenido
¿Por qué Apache Pig es tan popular?
Para analizar y procesar grandes datos, Hadoop utiliza Map Reduce. Map Reduce es un programa que está escrito en Java. Sin embargo, a los desarrolladores les resulta difícil escribir y mantener estos extensos códigos Java. Con Apache Pig, los desarrolladores pueden analizar y procesar rápidamente grandes conjuntos de datos sin usar códigos Java complejos. Apache Pig, desarrollado por investigadores de Yahoo, ejecuta trabajos de Map Reduce en extensos conjuntos de datos y proporciona una interfaz fácil para que los desarrolladores procesen los datos de manera eficiente.
Apache Pig surgió como una bendición para aquellos que no entienden la programación Java. Hoy, Apache Pig se ha vuelto muy popular entre los desarrolladores porque ofrece flexibilidad, reduce la complejidad del código y requiere menos esfuerzo. Si es un principiante y está interesado en obtener más información sobre la ciencia de datos, consulte nuestros cursos de ciencia de datos de las mejores universidades.
Map Reduce vs Apache Pig
La siguiente tabla resume la diferencia entre Map Reduce y Apache Pig:
| cerdo apache | Mapa reducido |
| Lenguaje de escritura | lenguaje compilado |
| Proporciona un mayor nivel de abstracción. | Proporciona un bajo nivel de abstracción. |
| Requiere unas pocas líneas de código (10 líneas de código pueden resumir 200 líneas de código Map Reduce) | Requiere un código más extenso (más líneas de código) |
| Requiere menos tiempo y esfuerzo de desarrollo | Requiere más tiempo y esfuerzo de desarrollo |
| Menor eficiencia de código | Mayor eficiencia de código en comparación con Apache Pig |
Características del cerdo apache
Apache Pig ofrece las siguientes características:
- Permite a los programadores escribir menos líneas de códigos. Los programadores pueden escribir 200 líneas de código Java en solo diez líneas usando el lenguaje Pig Latin.
- El enfoque de consultas múltiples de Apache Pig reduce el tiempo de desarrollo.
- Apache pig tiene un rico conjunto de conjuntos de datos para realizar operaciones como unir, filtrar, ordenar, cargar, agrupar, etc.
- El lenguaje Pig Latin es muy similar a SQL. Los programadores con buenos conocimientos de SQL encuentran fácil escribir secuencias de comandos de Pig.
- Permite a los programadores escribir menos líneas de códigos. Los programadores pueden escribir 200 líneas de código Java en solo diez líneas usando el lenguaje Pig Latin.
- Apache Pig maneja el análisis de datos estructurados y no estructurados.
Aplicaciones Apache Pig
Algunas de las aplicaciones de Apache Pig son:
- Procesa gran volumen de datos
- Admite la creación rápida de prototipos y consultas ad-hoc en grandes conjuntos de datos
- Realiza procesamiento de datos en plataformas de búsqueda.
- Procesa cargas de datos urgentes
- Utilizado por las empresas de telecomunicaciones para desidentificar la información de datos de llamadas del usuario.
¿Qué es el cerdo apache?
Map Reduce requiere que los programas se traduzcan en map y reduce etapas. Dado que no todos los analistas de datos estaban familiarizados con Map Reduce, los investigadores de Yahoo introdujeron Apache pig para cerrar la brecha. The Pig se construyó sobre Hadoop, que proporciona un alto nivel de abstracción y permite a los programadores dedicar menos tiempo a escribir programas complejos de Map Reduce. Pig no es un acrónimo; fue nombrado después de un animal doméstico. Como un cerdo animal come cualquier cosa, Pig puede trabajar con cualquier tipo de datos.

Fuente
Arquitectura Apache Pig en Hadoop
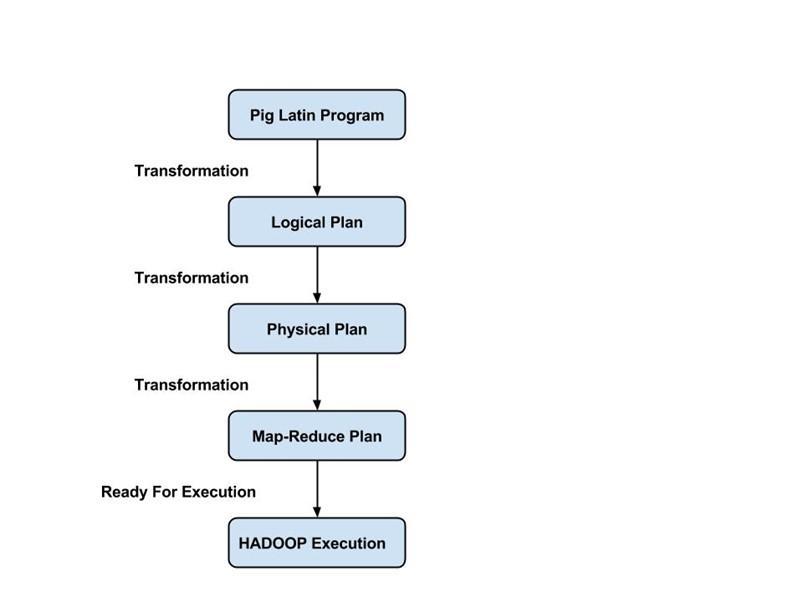
La arquitectura de Apache Pig consta de un intérprete de Pig Latin que utiliza scripts de Pig Latin para procesar y analizar conjuntos de datos masivos. Los programadores utilizan el lenguaje Pig Latin para analizar grandes conjuntos de datos en el entorno Hadoop. Apache pig tiene un amplio conjunto de conjuntos de datos para realizar diferentes operaciones de datos como unir, filtrar, clasificar, cargar, agrupar, etc.
Los programadores deben usar el lenguaje Pig Latin para escribir un script Pig para realizar una tarea específica. Pig convierte estos scripts de Pig en una serie de trabajos Map-Reduce para facilitar el trabajo de los programadores. Los programas de Pig Latin se ejecutan a través de varios mecanismos, como UDF, shells integrados y Grunt.
La arquitectura de Apache Pig consta de los siguientes componentes principales:
- analizador
- Optimizador
- Compilador
- Motor de ejecución
- Modo de ejecución
Estudiemos todos estos componentes del cerdo en detalle.
Escrituras latinas de cerdo
Los scripts de Pig se envían al entorno de ejecución de Pig para producir los resultados deseados.
Puede ejecutar los scripts de Pig utilizando uno de los métodos:
- Caparazón Gruñido
- Archivo de comandos
- Guión incrustado
analizador
Parser maneja todas las declaraciones o comandos de Pig Latin. Parser realiza varias comprobaciones en las declaraciones de Pig, como la comprobación de sintaxis, la comprobación de tipo y genera una salida DAG (Gráfico acíclico dirigido) . La salida DAG representa todos los operadores lógicos de los scripts como nodos y el flujo de datos como bordes.
Optimizador
Una vez que se completa la operación de análisis y se genera una salida DAG, la salida se pasa al optimizador. Luego, el optimizador realiza las actividades de optimización en la salida, como dividir, fusionar, proyectar, empujar hacia abajo, transformar y reordenar, etc. El optimizador procesa los datos extraídos y omite datos o columnas innecesarios mediante la realización de actividades de empuje y proyección y mejora el rendimiento de las consultas. .

Compilador
El compilador compila la salida que genera el optimizador en una serie de trabajos Map Reduce. El compilador convierte automáticamente los trabajos de Pig en trabajos de Map Reduce y optimiza el rendimiento reorganizando el orden de ejecución.
Motor de ejecución
Después de realizar todas las operaciones anteriores, estos trabajos de Map Reduce se envían al motor de ejecución, que luego se ejecuta en la plataforma Hadoop para producir los resultados deseados. Luego puede usar la declaración DUMP para mostrar los resultados en la pantalla o las declaraciones STORE para almacenar los resultados en HDFS (Sistema de archivos distribuidos de Hadoop).
Modo de ejecución
Apache Pig se ejecuta en dos modos de ejecución que son local y Map Reduce. La elección del modo de ejecución depende de dónde se almacenan los datos y dónde desea ejecutar el script de Pig. Puede almacenar sus datos localmente (en una sola máquina) o en un entorno de clúster de Hadoop distribuido.
- Modo local : puede usar el modo local si su conjunto de datos es pequeño. En modo local, Pig se ejecuta en una sola JVM utilizando el host local y el sistema de archivos. En este modo, la ejecución del mapeador paralelo es imposible ya que todos los archivos se instalan y ejecutan en el host local. Puede usar el comando pig -x local para especificar el modo local.
- Modo de reducción de mapa : Apache Pig utiliza el modo de reducción de mapa de forma predeterminada. En el modo Map Reduce, un programador ejecuta las declaraciones de Pig Latin en datos que ya están almacenados en el HDFS (Sistema de archivos distribuidos de Hadoop) . Puede usar el comando pig -x mapreduce para especificar el modo Map-Reduce.
Fuente
Modelo de datos latinos de cerdo
El modelo de datos de Pig Latin le permite a Pig manejar cualquier tipo de datos. El modelo de datos Pig Latin está completamente anidado y puede tratar tipos de datos complejos tanto atómicos como enteros, flotantes y no atómicos, como mapas y tuplas.
Entendamos el modelo de datos en profundidad:
- Átomo: un átomo es un valor único almacenado en forma de cadena y se puede usar como un número y una cadena. Los valores atómicos de Pig son enteros, dobles, flotantes, matriz de bytes y matriz de caracteres. Un solo valor atómico también se llama campo.
Por ejemplo, “Kiara” o 27
- Tupla: una tupla es un registro que contiene un conjunto ordenado de campos (cualquier tipo). Una tupla es muy similar a una fila en un RDBMS (Sistema de gestión de bases de datos relacionales) .
Por ejemplo, (Kiara, 27)
- Bolsa: un átomo es un valor único almacenado en forma de cadena y se puede usar como un número y una cadena. Los valores atómicos de Pig son enteros, dobles, flotantes, matriz de bytes y matriz de caracteres. Un solo valor atómico también se llama campo.
Por ejemplo, {(Kiara, 27), (Kehsav, 45)}
- Mapa: un conjunto de pares clave-valor se conoce como mapa. La clave debe ser única y debe ser del tipo de matriz de caracteres. Sin embargo, el valor puede ser de cualquier tipo.
Por ejemplo, [nombre#Kiara, edad#27]
- Relación: una bolsa de tuplas se denomina relación.
Flujo de ejecución de un trabajo de cerdo
Los siguientes pasos explican el flujo de ejecución de un trabajo Pig:
- El desarrollador escribe un script de Pig utilizando el idioma Pig Latin y lo almacena en el sistema de archivos local.
- Después de enviar los scripts de Pig, Apache Pig establece una conexión con el compilador y genera una serie de Map Reduce Jobs como salida.
- El compilador Pig recibe datos sin procesar de HDFS, realiza operaciones y almacena los resultados en HDFS una vez que finalizan los trabajos de Map Reduce.
Lea también: Tutorial de Apache Pig
Conclusión
En este blog, hemos aprendido sobre la arquitectura de Apache Pig , los componentes de Pig, la diferencia entre Map Reduce y Apache Pig, el modelo de datos de Pig Latin y el flujo de ejecución de un trabajo de Pig.
Apache Pig es una gran ayuda para los programadores, ya que proporciona una plataforma con una interfaz sencilla, reduce la complejidad del código y les ayuda a lograr resultados de manera eficiente. Yahoo, eBay, LinkedIn y Twitter son algunas de las empresas que utilizan Pig para procesar sus grandes volúmenes de datos.
Si tiene curiosidad por aprender sobre Apache Pig, ciencia de datos, consulte el programa Executive PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos prácticos, tutoría con la industria. expertos, 1 a 1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cuáles son las características de Apache Pig?
Apache Pig es una herramienta o plataforma de muy alto nivel que se utiliza para el procesamiento de grandes conjuntos de datos. Los códigos de análisis de datos se desarrollan con el uso de un lenguaje de scripting de alto nivel llamado Pig Latin. En primer lugar, los programadores escribirán scripts Pig Latin para procesar los datos en un mapa específico y reducir las tareas. Apache Pig tiene muchas características que lo convierten en una herramienta muy útil.
1. Proporciona un amplio conjunto de operadores para realizar diferentes operaciones, como ordenar, unir, filtrar, etc.
2. Apache Pig se considera una gran ayuda para los programadores de SQL, ya que es fácil de aprender, leer y escribir.
3. Hacer funciones y procesos definidos por el usuario es fácil
4. Se requieren menos líneas de código para cualquier proceso o función
5. Permite a los usuarios realizar análisis de datos estructurados y no estructurados
6. Las operaciones de unir y dividir son bastante fáciles de realizar
¿Cuáles son los modos de ejecución disponibles en Apache Pig?
Apache Pig se puede ejecutar en dos modos diferentes:
1. Modo local: todos los archivos se instalarán y ejecutarán desde su sistema de archivos local y host local en este modo. Por lo general, este modo se utiliza con fines de prueba. Aquí, no necesitará HDFS o Hadoop.
2. Modo MapReduce: en el modo MapReduce, Apache Pig se usa para cargar y procesar los datos que ya existen en el sistema de archivos Hadoop (HDFS). Se invocará un trabajo de MapReduce en el back-end cada vez que intentemos ejecutar una instrucción Pig Latin para procesar los datos. Realizará una operación particular sobre los datos ya existentes en el HDFS.
¿Cuáles son algunas de las aplicaciones clave de Apache Pig?
Apache Pig resultó ser una bendición para todos aquellos programadores que no podían entender la programación Java de manera competente. Lo mejor de Apache Pig es que ofrece flexibilidad, requiere menos esfuerzo que otras plataformas y reduce la complejidad del código.
Algunas de las aplicaciones clave de Apache Pig son:
1. Procesamiento de un gran volumen de datos de los conjuntos de datos
2. Útil en todos los lugares donde se requieren conocimientos analíticos con el uso de muestreo
3. Para la recopilación de una gran cantidad de conjuntos de datos en forma de rastreos web y registros de búsqueda
4. Requerido para crear prototipos de algoritmos de procesamiento de grandes conjuntos de datos