
สถาปัตยกรรม Apache Pig ใน Hadoop: คุณลักษณะ แอปพลิเคชัน ขั้นตอนการดำเนินการ
เผยแพร่แล้ว: 2020-06-26สารบัญ
ทำไม Apache Pig ถึงได้รับความนิยม
ในการวิเคราะห์และประมวลผลข้อมูลขนาดใหญ่ Hadoop ใช้ Map Reduce Map Reduce เป็นโปรแกรมที่เขียนด้วยภาษาจาวา แต่นักพัฒนาพบว่าการเขียนและรักษาโค้ด Java ที่มีความยาวเหล่านี้เป็นเรื่องที่ท้าทาย ด้วย Apache Pig นักพัฒนาสามารถวิเคราะห์และประมวลผลชุดข้อมูลขนาดใหญ่ได้อย่างรวดเร็วโดยไม่ต้องใช้โค้ด Java ที่ซับซ้อน Apache Pig ที่พัฒนาโดยนักวิจัยของ Yahoo ดำเนินงาน Map Reduce บนชุดข้อมูลที่กว้างขวาง และให้อินเทอร์เฟซที่ง่ายสำหรับนักพัฒนาในการประมวลผลข้อมูลอย่างมีประสิทธิภาพ
Apache Pig เป็นประโยชน์สำหรับผู้ที่ไม่เข้าใจการเขียนโปรแกรม Java วันนี้ Apache Pig ได้รับความนิยมอย่างมากในหมู่นักพัฒนา เนื่องจากมีความยืดหยุ่น ลดความซับซ้อนของโค้ด และใช้ความพยายามน้อยลง หากคุณเป็นมือใหม่และสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับวิทยาศาสตร์ข้อมูล ลองดูหลักสูตรวิทยาศาสตร์ข้อมูลของเราจากมหาวิทยาลัยชั้นนำ
แผนที่ลดเทียบกับ Apache Pig
ตารางต่อไปนี้สรุปความแตกต่างระหว่าง Map Reduce และ Apache Pig:
| Apache Pig | แผนที่ลด |
| ภาษาสคริปต์ | ภาษาที่เรียบเรียง |
| ให้ระดับนามธรรมที่สูงขึ้น | ให้ระดับนามธรรมต่ำ |
| ต้องใช้รหัสสองสามบรรทัด (รหัส 10 บรรทัดสามารถสรุปรหัสลดแผนที่ได้ 200 บรรทัด) | ต้องใช้โค้ดที่ครอบคลุมมากขึ้น (โค้ดหลายบรรทัด) |
| ใช้เวลาและความพยายามในการพัฒนาน้อยลง | ต้องใช้เวลาและความพยายามในการพัฒนามากขึ้น |
| ประสิทธิภาพของโค้ดน้อยลง | โค้ดประสิทธิภาพสูงกว่าเมื่อเปรียบเทียบกับ Apache Pig |
คุณสมบัติ Apache Pig
Apache Pig มีคุณสมบัติดังต่อไปนี้:
- อนุญาตให้โปรแกรมเมอร์เขียนโค้ดน้อยลง โปรแกรมเมอร์สามารถเขียนโค้ด Java 200 บรรทัดในสิบบรรทัดโดยใช้ภาษา Pig Latin
- วิธีการหลายแบบสอบถามของ Apache Pig ช่วยลดเวลาในการพัฒนา
- Apache pig มีชุดข้อมูลจำนวนมากสำหรับดำเนินการต่างๆ เช่น เข้าร่วม กรอง จัดเรียง โหลด กลุ่ม ฯลฯ
- ภาษา Pig Latin นั้นคล้ายกับ SQL มาก โปรแกรมเมอร์ที่มีความรู้เกี่ยวกับ SQL เป็นอย่างดีจะเขียน Pig script ได้ง่าย
- อนุญาตให้โปรแกรมเมอร์เขียนโค้ดน้อยลง โปรแกรมเมอร์สามารถเขียนโค้ด Java 200 บรรทัดในสิบบรรทัดโดยใช้ภาษา Pig Latin
- Apache Pig จัดการทั้งการวิเคราะห์ข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
Apache Pig Applications
แอปพลิเคชั่น Apache Pig บางส่วน ได้แก่ :
- ประมวลผลข้อมูลปริมาณมาก
- รองรับการสร้างต้นแบบอย่างรวดเร็วและการสืบค้นข้อมูลแบบเฉพาะกิจในชุดข้อมูลขนาดใหญ่
- ดำเนินการประมวลผลข้อมูลในแพลตฟอร์มการค้นหา
- ประมวลผลการโหลดข้อมูลที่ไวต่อเวลา
- ใช้โดยบริษัทโทรคมนาคมเพื่อยกเลิกการระบุข้อมูลการโทรของผู้ใช้
Apache Pig คืออะไร?
Map Reduce ต้องการโปรแกรมที่จะแปลเป็นแผนที่และลดขั้นตอน เนื่องจากนักวิเคราะห์ข้อมูลบางคนไม่คุ้นเคยกับ Map Reduce ดังนั้น นักวิจัย Yahoo จึงแนะนำหมู Apache เพื่อลดช่องว่าง The Pig สร้างขึ้นบน Hadoop ที่ให้ความเป็นนามธรรมในระดับสูง และช่วยให้โปรแกรมเมอร์ใช้เวลาน้อยลงในการเขียนโปรแกรม Map Reduce ที่ซับซ้อน หมูไม่ใช่คำย่อ มันถูกตั้งชื่อตามสัตว์เลี้ยง ในขณะที่หมูสัตว์กินอะไรก็ได้ Pig สามารถทำงานกับข้อมูลประเภทใดก็ได้

แหล่งที่มา
สถาปัตยกรรม Apache Pig ใน Hadoop
สถาปัตยกรรม Apache Pig ประกอบด้วยล่าม Pig Latin ที่ใช้สคริปต์ Pig Latin เพื่อประมวลผลและวิเคราะห์ชุดข้อมูลขนาดใหญ่ โปรแกรมเมอร์ใช้ภาษา Pig Latin เพื่อวิเคราะห์ชุดข้อมูลขนาดใหญ่ในสภาพแวดล้อม Hadoop Apache pig มีชุดข้อมูลจำนวนมากสำหรับดำเนินการกับข้อมูลต่างๆ เช่น เข้าร่วม กรอง จัดเรียง โหลด จัดกลุ่ม ฯลฯ
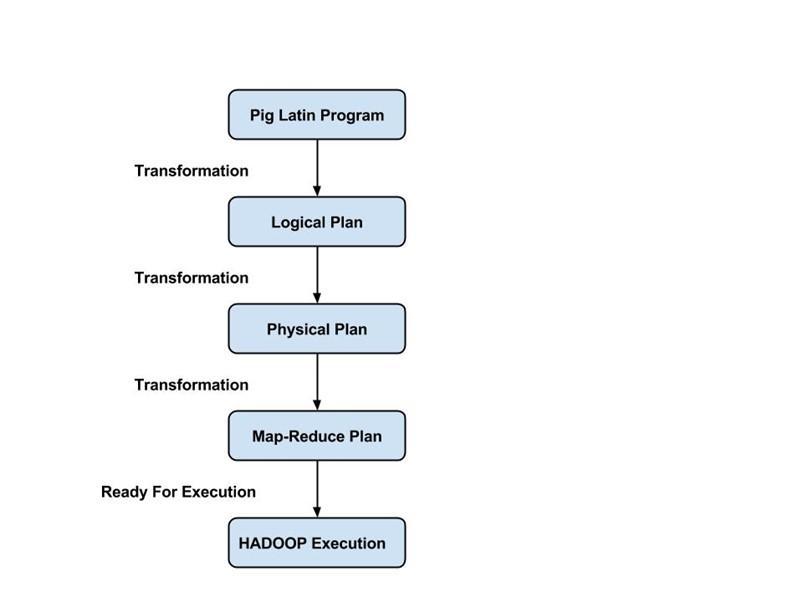
โปรแกรมเมอร์ต้องใช้ภาษา Pig Latin เพื่อเขียนสคริปต์ Pig เพื่อทำงานเฉพาะ Pig แปลงสคริปต์ Pig เหล่านี้เป็นชุดงาน Map-Reduce เพื่อช่วยให้การทำงานของโปรแกรมเมอร์ง่ายขึ้น โปรแกรม Pig Latin ทำงานโดยใช้กลไกต่างๆ เช่น UDF, Embedded และ Grunt shells
สถาปัตยกรรม Apache Pig ประกอบด้วยองค์ประกอบหลักดังต่อไปนี้:
- พาร์เซอร์
- เครื่องมือเพิ่มประสิทธิภาพ
- คอมไพเลอร์
- เครื่องมือดำเนินการ
- โหมดการดำเนินการ
ให้เราศึกษาส่วนประกอบ Pig เหล่านี้อย่างละเอียด
อักษรละตินหมู
สคริปต์ Pig จะถูกส่งไปยังสภาพแวดล้อมการดำเนินการ Pig เพื่อให้ได้ผลลัพธ์ที่ต้องการ
คุณสามารถรันสคริปต์ Pig ได้โดยใช้หนึ่งในวิธี:
- Grunt Shell
- ไฟล์สคริปต์
- สคริปต์ฝังตัว
พาร์เซอร์
Parser จัดการคำสั่งหรือคำสั่ง Pig Latin ทั้งหมด Parser ดำเนินการตรวจสอบหลายอย่างในคำสั่ง Pig เช่น การตรวจสอบไวยากรณ์ การตรวจสอบประเภท และสร้างเอาต์พุต DAG (Directed Acyclic Graph) เอาต์พุต DAG แสดงถึงตัวดำเนินการเชิงตรรกะทั้งหมดของสคริปต์เป็นโหนดและการไหลของข้อมูลเป็นขอบ
เครื่องมือเพิ่มประสิทธิภาพ
เมื่อการแยกวิเคราะห์เสร็จสิ้นและสร้างเอาต์พุต DAG เอาต์พุตจะถูกส่งไปยังเครื่องมือเพิ่มประสิทธิภาพ จากนั้นตัวเพิ่มประสิทธิภาพจะดำเนินกิจกรรมการปรับให้เหมาะสมในผลลัพธ์ เช่น การแยก การผสาน การฉายภาพ การกดลง การแปลง และการจัดลำดับใหม่ เป็นต้น เครื่องมือเพิ่มประสิทธิภาพจะประมวลผลข้อมูลที่แยกออกมาและละเว้นข้อมูลหรือคอลัมน์ที่ไม่จำเป็นโดยดำเนินการกดลงและกิจกรรมการฉายภาพและปรับปรุงประสิทธิภาพการสืบค้น .

คอมไพเลอร์
คอมไพเลอร์รวบรวมเอาท์พุตที่สร้างโดยตัวเพิ่มประสิทธิภาพเป็นชุดของงาน Map Reduce คอมไพเลอร์จะแปลงงาน Pig เป็นงาน Map Reduce โดยอัตโนมัติและเพิ่มประสิทธิภาพการทำงานโดยจัดเรียงลำดับการดำเนินการใหม่
เครื่องมือดำเนินการ
หลังจากดำเนินการทั้งหมดข้างต้นแล้ว งาน Map Reduce เหล่านี้จะถูกส่งไปยังเอ็นจิ้นการดำเนินการ ซึ่งจะถูกดำเนินการบนแพลตฟอร์ม Hadoop เพื่อให้ได้ผลลัพธ์ที่ต้องการ จากนั้นคุณสามารถใช้คำสั่ง DUMP เพื่อแสดงผลลัพธ์บนหน้าจอหรือคำสั่ง STORE เพื่อจัดเก็บผลลัพธ์ใน HDFS (Hadoop Distributed File System)
โหมดการดำเนินการ
Apache Pig ดำเนินการในสองโหมดการทำงานที่อยู่ในเครื่องและการลดแผนที่ การเลือกโหมดการดำเนินการขึ้นอยู่กับตำแหน่งที่จัดเก็บข้อมูลและตำแหน่งที่คุณต้องการเรียกใช้สคริปต์ Pig คุณสามารถจัดเก็บข้อมูลของคุณในเครื่อง (ในเครื่องเดียว) หรือในสภาพแวดล้อมคลัสเตอร์ Hadoop แบบกระจาย
- โหมดท้องถิ่น – คุณสามารถใช้โหมดท้องถิ่นได้หากชุดข้อมูลของคุณมีขนาดเล็ก ในโหมดโลคัล Pig ทำงานใน JVM เดียวโดยใช้โฮสต์โลคัลและระบบไฟล์ ในโหมดนี้ การดำเนินการ mapper แบบขนานเป็นไปไม่ได้ เนื่องจากไฟล์ทั้งหมดได้รับการติดตั้งและรันบน localhost คุณสามารถใช้ คำสั่ง ท้องถิ่น pig -x เพื่อระบุโหมดโลคัล
- โหมดลดแผนที่ – Apache Pig ใช้โหมดลดแผนที่เป็นค่าเริ่มต้น ในโหมด Map Reduce โปรแกรมเมอร์รันคำสั่ง Pig Latin กับข้อมูลที่จัดเก็บไว้ใน HDFS (Hadoop Distributed File System) คุณสามารถใช้ คำสั่ง pig -x mapreduce เพื่อระบุโหมด Map-Reduce
แหล่งที่มา
โมเดลข้อมูล Pig Latin
โมเดลข้อมูล Pig Latin ช่วยให้ Pig จัดการกับข้อมูลประเภทใดก็ได้ โมเดลข้อมูล Pig Latin ถูกซ้อนกันอย่างสมบูรณ์และสามารถจัดการกับทั้งประเภทข้อมูลอะตอม เช่น จำนวนเต็ม ทุ่น และประเภทข้อมูลที่ไม่ซับซ้อนของอะตอม เช่น แผนที่และทูเปิล
ให้เราเข้าใจโมเดลข้อมูลในเชิงลึก:
- อะตอม – อะตอมเป็นค่าเดียวที่เก็บไว้ในรูปแบบสตริงและสามารถใช้เป็นตัวเลขและสตริงได้ ค่าอะตอมของ Pig คือจำนวนเต็ม, สองเท่า, ทุ่น, ไบต์อาร์เรย์ และ ถ่านอาร์เรย์ ค่าอะตอมเดียวเรียกอีกอย่างว่าฟิลด์
ตัวอย่างเช่น “Kiara” หรือ 27
- ทูเพิล – ทูเพิลคือเร็กคอร์ดที่มีชุดฟิลด์ที่เรียงลำดับ (ประเภทใดก็ได้) ทูเพิลคล้ายกับแถวใน RDBMS (ระบบจัดการฐานข้อมูลเชิงสัมพันธ์) มาก
ตัวอย่างเช่น (Kiara, 27)
- กระเป๋า – อะตอมเป็นค่าเดียวที่จัดเก็บในรูปแบบสตริงและสามารถใช้เป็นตัวเลขและสตริงได้ ค่าอะตอมของ Pig คือจำนวนเต็ม, สองเท่า, ทุ่น, ไบต์อาร์เรย์ และ ถ่านอาร์เรย์ ค่าอะตอมเดียวเรียกอีกอย่างว่าฟิลด์
ตัวอย่างเช่น {(Kiara, 27), (Kehsav, 45)}
- แผนที่ – ชุดคู่คีย์-ค่าเรียกว่าแผนที่ คีย์ต้องไม่ซ้ำกันและควรเป็นประเภทอาร์เรย์ถ่าน อย่างไรก็ตาม มูลค่าสามารถเป็นอะไรก็ได้
ตัวอย่างเช่น [name#Kiara อายุ#27]
- ความสัมพันธ์ – ถุงทูเพิลเรียกว่าความสัมพันธ์
ขั้นตอนการดำเนินการของงานหมู
ขั้นตอนต่อไปนี้อธิบายขั้นตอนการดำเนินการของงาน Pig:
- ผู้พัฒนาเขียนสคริปต์ Pig โดยใช้ภาษา Pig Latin และจัดเก็บไว้ในระบบไฟล์ในเครื่อง
- หลังจากส่งสคริปต์ Pig แล้ว Apache Pig จะสร้างการเชื่อมต่อกับคอมไพเลอร์และสร้างชุดของ Map Reduce Jobs เป็นเอาต์พุต
- คอมไพเลอร์ Pig รับข้อมูลดิบจาก HDFS ดำเนินการและจัดเก็บผลลัพธ์ลงใน HDFS หลังจากงาน Map Reduce เสร็จสิ้น
อ่านเพิ่มเติม: Apache Pig Tutorial
บทสรุป
ในบล็อกนี้ เราได้เรียนรู้เกี่ยวกับ Apache Pig Architecture ส่วนประกอบ Pig ความแตกต่างระหว่าง Map Reduce และ Apache Pig โมเดลข้อมูล Pig Latin และโฟลว์การดำเนินการของงาน Pig
Apache Pig เป็นประโยชน์สำหรับโปรแกรมเมอร์เนื่องจากมีแพลตฟอร์มที่มีอินเทอร์เฟซที่ใช้งานง่าย ลดความซับซ้อนของโค้ด และช่วยให้พวกเขาบรรลุผลลัพธ์อย่างมีประสิทธิภาพ Yahoo, eBay, LinkedIn และ Twitter คือบริษัทบางแห่งที่ใช้ Pig ในการประมวลผลข้อมูลจำนวนมาก
หากคุณอยากเรียนรู้เกี่ยวกับ Apache Pig วิทยาศาสตร์ข้อมูล ลองดู โปรแกรม Executive PG ของ IIIT-B และ upGrad ใน Data Science ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 รายการ เวิร์กช็อปภาคปฏิบัติจริง การให้คำปรึกษากับอุตสาหกรรม ผู้เชี่ยวชาญ ตัวต่อตัวกับที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
คุณสมบัติของ Apache Pig คืออะไร?
Apache Pig เป็นเครื่องมือหรือแพลตฟอร์มระดับสูงที่ใช้สำหรับการประมวลผลชุดข้อมูลขนาดใหญ่ รหัสการวิเคราะห์ข้อมูลได้รับการพัฒนาโดยใช้ภาษาสคริปต์ระดับสูงที่เรียกว่า Pig Latin ประการแรก โปรแกรมเมอร์จะเขียนสคริปต์ Pig Latin เพื่อประมวลผลข้อมูลลงในแผนที่เฉพาะและลดงานลง Apache Pig มีคุณสมบัติมากมายซึ่งทำให้เป็นเครื่องมือที่มีประโยชน์มาก
1. มีชุดตัวดำเนินการจำนวนมากเพื่อดำเนินการต่างๆ เช่น การเรียงลำดับ การรวม ตัวกรอง ฯลฯ
2. Apache Pig ถือได้ว่าเป็นประโยชน์สำหรับโปรแกรมเมอร์ SQL เนื่องจากเรียนรู้ อ่าน และเขียนได้ง่าย
3. ทำให้ฟังก์ชันและกระบวนการที่ผู้ใช้กำหนดเป็นเรื่องง่าย
4. ต้องใช้โค้ดน้อยลงสำหรับกระบวนการหรือฟังก์ชันใดๆ
5. อนุญาตให้ผู้ใช้ทำการวิเคราะห์ทั้งข้อมูลที่ไม่มีโครงสร้างและโครงสร้าง
6. เข้าร่วมและแยกการดำเนินการค่อนข้างง่าย
โหมดการดำเนินการที่มีอยู่ใน Apache Pig คืออะไร
Apache Pig สามารถทำได้ในสองโหมดที่แตกต่างกัน:
1. Local Mode - ไฟล์ทั้งหมดจะถูกติดตั้งและเรียกใช้จากระบบไฟล์ในเครื่องและโฮสต์ภายในเครื่องในโหมดนี้ โดยปกติ โหมดนี้ใช้เพื่อวัตถุประสงค์ในการทดสอบ ที่นี่คุณไม่จำเป็นต้องใช้ HDFS หรือ Hadoop
2. โหมด MapReduce - ในโหมด MapReduce Apache Pig ใช้สำหรับโหลดและประมวลผลข้อมูลที่มีอยู่แล้วในระบบไฟล์ Hadoop (HDFS) งาน MapReduce จะถูกเรียกใช้ในส่วนหลังเมื่อใดก็ตามที่เราพยายามดำเนินการคำสั่ง Pig Latin เพื่อประมวลผลข้อมูล จะดำเนินการเฉพาะกับข้อมูลที่มีอยู่แล้วใน HDFS
แอปพลิเคชันหลักของ Apache Pig มีอะไรบ้าง
Apache Pig กลายเป็นพรสำหรับโปรแกรมเมอร์ทุกคนที่ไม่เข้าใจการเขียนโปรแกรม Java อย่างเชี่ยวชาญ สิ่งที่ดีที่สุดเกี่ยวกับ Apache Pig คือให้ความยืดหยุ่น ใช้ความพยายามน้อยกว่าแพลตฟอร์มอื่น และลดความซับซ้อนของโค้ด
แอปพลิเคชั่นหลักบางตัวของ Apache Pig คือ:
1. การประมวลผลข้อมูลจำนวนมากจากชุดข้อมูล
2. มีประโยชน์ในทุกที่ที่ต้องการข้อมูลเชิงลึกในการวิเคราะห์ด้วยการใช้การสุ่มตัวอย่าง
3. สำหรับการรวบรวมชุดข้อมูลจำนวนมากในรูปแบบของการรวบรวมข้อมูลเว็บและบันทึกการค้นหา
4. จำเป็นสำหรับการสร้างต้นแบบอัลกอริธึมการประมวลผลของชุดข้อมูลขนาดใหญ่