
Архитектура Apache Pig в Hadoop: функции, приложения, поток выполнения
Опубликовано: 2020-06-26Оглавление
Почему Apache Pig так популярен
Для анализа и обработки больших данных Hadoop использует Map Reduce. Map Reduce — это программа, написанная на Java. Но разработчикам сложно писать и поддерживать эти длинные коды Java. С помощью Apache Pig разработчики могут быстро анализировать и обрабатывать большие наборы данных без использования сложных кодов Java. Apache Pig, разработанный исследователями Yahoo, выполняет задания Map Reduce для обширных наборов данных и предоставляет разработчикам простой интерфейс для эффективной обработки данных.
Apache Pig появился как благо для тех, кто не разбирается в программировании на Java. Сегодня Apache Pig стал очень популярным среди разработчиков, поскольку он предлагает гибкость, снижает сложность кода и требует меньше усилий. Если вы новичок и хотите узнать больше о науке о данных, ознакомьтесь с нашими курсами по науке о данных от лучших университетов.
Map Reduce против Apache Pig
В следующей таблице приведены различия между Map Reduce и Apache Pig:
| Апачская свинья | Уменьшение карты |
| Скриптовый язык | Скомпилированный язык |
| Обеспечивает более высокий уровень абстракции | Обеспечивает низкий уровень абстракции |
| Требуется несколько строк кода (10 строк кода могут суммировать 200 строк кода Map Reduce) | Требуется более обширный код (больше строк кода) |
| Требует меньше времени и усилий на разработку | Требует больше времени и усилий на разработку |
| Меньшая эффективность кода | Более высокая эффективность кода по сравнению с Apache Pig |
Особенности свиньи Apache
Apache Pig предлагает следующие функции:
- Позволяет программистам писать меньше строк кода. Программисты могут написать 200 строк кода Java всего за десять строк, используя язык Pig Latin.
- Многозапросный подход Apache Pig сокращает время разработки.
- Apache pig имеет богатый набор наборов данных для выполнения таких операций, как объединение, фильтрация, сортировка, загрузка, группировка и т. д.
- Язык свиной латыни очень похож на SQL. Программистам с хорошим знанием SQL будет легко написать сценарий Pig.
- Позволяет программистам писать меньше строк кода. Программисты могут написать 200 строк кода Java всего за десять строк, используя язык Pig Latin.
- Apache Pig обрабатывает как структурированные, так и неструктурированные данные.
Приложения Apache Pig
Вот несколько приложений Apache Pig:
- Обрабатывает большой объем данных
- Поддерживает быстрое прототипирование и специальные запросы для больших наборов данных.
- Выполняет обработку данных в поисковых платформах
- Обрабатывает срочные загрузки данных
- Используется телекоммуникационными компаниями для деидентификации информации о пользовательских вызовах.
Что такое Apache Pig?
Map Reduce требует, чтобы программы были переведены в этапы карты и сокращения. Поскольку не все аналитики данных были знакомы с Map Reduce, исследователи Yahoo представили Apache pig, чтобы заполнить пробел. Pig был создан на основе Hadoop, который обеспечивает высокий уровень абстракции и позволяет программистам тратить меньше времени на написание сложных программ Map Reduce. Свинья — это не аббревиатура; он был назван в честь домашнего животного. Как свинья-животное ест что угодно, так и Свинья может работать с любыми данными.

Источник
Архитектура Apache Pig в Hadoop
Архитектура Apache Pig состоит из интерпретатора Pig Latin, который использует скрипты Pig Latin для обработки и анализа массивных наборов данных. Программисты используют язык Pig Latin для анализа больших наборов данных в среде Hadoop. Apache pig имеет богатый набор наборов данных для выполнения различных операций с данными, таких как объединение, фильтрация, сортировка, загрузка, группировка и т. д.
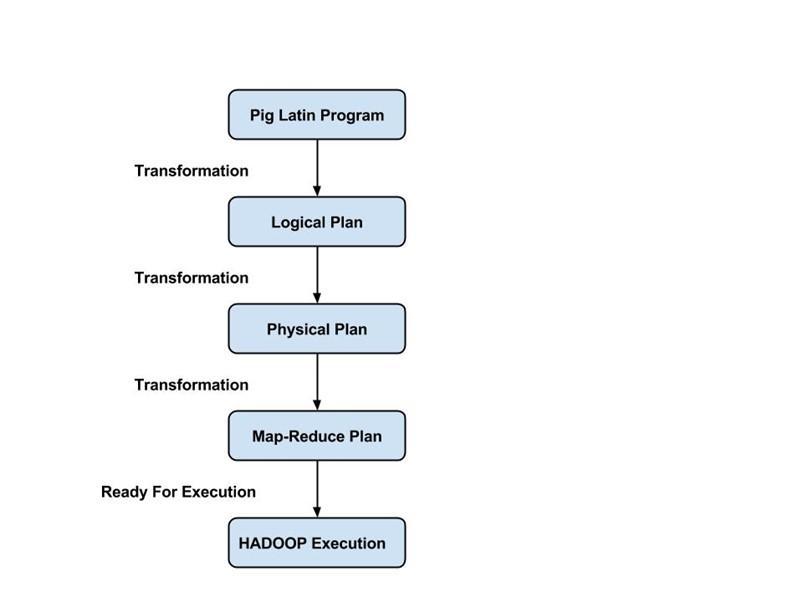
Программисты должны использовать язык Pig Latin для написания сценария Pig для выполнения конкретной задачи. Pig преобразует эти сценарии Pig в серию заданий Map-Reduce, чтобы облегчить работу программистов. Программы Pig Latin выполняются с помощью различных механизмов, таких как UDF, встроенные оболочки и оболочки Grunt.
Архитектура Apache Pig состоит из следующих основных компонентов:
- Парсер
- Оптимизатор
- Компилятор
- Исполнительный механизм
- Режим выполнения
Давайте подробно изучим все эти компоненты Pig.
Свинья на латыни
Скрипты Pig отправляются в среду выполнения Pig для получения желаемых результатов.
Вы можете выполнить сценарии Pig, используя один из методов:
- Грант Шелл
- Файл сценария
- Встроенный скрипт
Парсер
Парсер обрабатывает все операторы или команды Pig Latin. Парсер выполняет несколько проверок операторов Pig, таких как проверка синтаксиса, проверка типа, и генерирует выходные данные DAG (направленный ациклический граф) . Выходные данные DAG представляют все логические операторы сценариев в виде узлов, а поток данных — в виде ребер.
Оптимизатор
После завершения операции синтаксического анализа и создания выходных данных DAG эти выходные данные передаются оптимизатору. Затем оптимизатор выполняет действия по оптимизации выходных данных, такие как разделение, слияние, проекция, вставка вниз, преобразование, изменение порядка и т. д. Оптимизатор обрабатывает извлеченные данные и пропускает ненужные данные или столбцы, выполняя действия вставки и проекции и повышая производительность запросов. .

Компилятор
Компилятор компилирует выходные данные, созданные оптимизатором, в серию заданий Map Reduce. Компилятор автоматически преобразует задания Pig в задания Map Reduce и оптимизирует производительность, изменяя порядок выполнения.
Исполнительный механизм
После выполнения всех вышеперечисленных операций эти задания Map Reduce передаются механизму выполнения, который затем выполняется на платформе Hadoop для получения желаемых результатов. Затем вы можете использовать инструкцию DUMP для отображения результатов на экране или инструкцию STORE для сохранения результатов в HDFS (распределенная файловая система Hadoop).
Режим выполнения
Apache Pig выполняется в двух режимах выполнения: локальном и Map Reduce. Выбор режима выполнения зависит от того, где хранятся данные и где вы хотите запустить скрипт Pig. Вы можете хранить свои данные локально (на одном компьютере) или в распределенной кластерной среде Hadoop.
- Локальный режим — вы можете использовать локальный режим, если ваш набор данных небольшой. В локальном режиме Pig работает на одной JVM, используя локальный хост и файловую систему. В этом режиме параллельное выполнение картографа невозможно, так как все файлы устанавливаются и запускаются на локальном хосте. Вы можете использовать команду pig -x local , чтобы указать локальный режим.
- Режим уменьшения карты — Apache Pig по умолчанию использует режим уменьшения карты. В режиме Map Reduce программист выполняет операторы Pig Latin для данных, которые уже хранятся в HDFS (распределенная файловая система Hadoop) . Вы можете использовать команду pig -x mapreduce , чтобы указать режим Map-Reduce.
Источник
Модель данных Pig Latin
Модель данных Pig Latin позволяет Pig обрабатывать любые данные. Модель данных Pig Latin полностью вложена и может обрабатывать как атомарные, такие как целые числа, числа с плавающей запятой, так и неатомарные сложные типы данных, такие как карта и кортеж.
Давайте подробно разберем модель данных:
- Атом . Атом — это отдельное значение, хранящееся в виде строки, которое можно использовать как число и строку. Атомарными значениями Pig являются целые, двойные, числа с плавающей запятой, массив байтов и массив символов. Одно атомарное значение также называется полем.
Например, «Киара» или 27
- Кортеж — кортеж — это запись, содержащая упорядоченный набор полей (любого типа). Кортеж очень похож на строку в СУБД (реляционной системе управления базами данных) .
Например, (Киара, 27 лет)
- Сумка — атом — это отдельное значение, хранящееся в виде строки, которое можно использовать как число и строку. Атомарными значениями Pig являются целые, двойные, числа с плавающей запятой, массив байтов и массив символов. Одно атомарное значение также называется полем.
Например, {(Киара, 27), (Кехсав, 45)}
- Карта — набор пар ключ-значение называется картой. Ключ должен быть уникальным и относиться к типу массива символов. Однако значение может быть любым.
Например, [имя#Киара, возраст#27]
- Отношение . Набор кортежей называется отношением.
Поток выполнения работы свиньи
Следующие шаги объясняют поток выполнения задания Pig:
- Разработчик пишет скрипт Pig на языке Pig Latin и сохраняет его в локальной файловой системе.
- После отправки сценариев Pig Apache Pig устанавливает соединение с компилятором и генерирует серию заданий Map Reduce в качестве выходных данных.
- Компилятор Pig получает необработанные данные из HDFS, выполняет операции и сохраняет результаты в HDFS после завершения заданий Map Reduce.
Читайте также: Учебник по Apache Pig
Заключение
В этом блоге мы узнали об архитектуре Apache Pig , компонентах Pig, разнице между Map Reduce и Apache Pig, модели данных Pig Latin и потоке выполнения задания Pig.
Apache Pig является благом для программистов, поскольку предоставляет платформу с простым интерфейсом, снижает сложность кода и помогает им эффективно достигать результатов. Yahoo, eBay, LinkedIn и Twitter — некоторые из компаний, которые используют Pig для обработки своих больших объемов данных.
Если вам интересно узнать об Apache Pig, науке о данных, ознакомьтесь с программой Executive PG IIIT-B и upGrad по науке о данных , которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические практические семинары, наставничество в отрасли. экспертов, общение один на один с отраслевыми наставниками, более 400 часов обучения и помощь в трудоустройстве в ведущих фирмах.
Каковы особенности Apache Pig?
Apache Pig — это инструмент или платформа очень высокого уровня, используемая для обработки больших наборов данных. Коды анализа данных разрабатываются с использованием языка сценариев высокого уровня под названием Pig Latin. Во-первых, программисты будут писать скрипты Pig Latin для обработки данных в определенную карту и сокращения задач. Apache Pig имеет множество функций, что делает его очень полезным инструментом.
1. Он предоставляет богатый набор операторов для выполнения различных операций, таких как сортировка, объединение, фильтрация и т. д.
2. Apache Pig считается благом для программистов SQL, поскольку его легко изучать, читать и писать.
3. Легко создавать пользовательские функции и процессы
4. Для любого процесса или функции требуется меньше строк кода
5. Позволяет пользователям выполнять анализ как неструктурированных, так и структурированных данных.
6. Операции объединения и разделения довольно просты в выполнении.
Какие режимы выполнения доступны в Apache Pig?
Apache Pig может выполняться в двух разных режимах:
1. Локальный режим. В этом режиме все файлы будут установлены и запущены из вашей локальной файловой системы и локального хоста. Обычно этот режим используется для тестирования. Здесь вам не понадобятся HDFS или Hadoop.
2. Режим MapReduce. В режиме MapReduce Apache Pig используется для загрузки и обработки данных, которые уже существуют в файловой системе Hadoop (HDFS). Задание MapReduce будет вызываться в серверной части всякий раз, когда мы пытаемся выполнить оператор Pig Latin для обработки данных. Он выполнит определенную операцию с уже существующими данными в HDFS.
Каковы некоторые из ключевых приложений Apache Pig?
Apache Pig оказался благом для всех тех программистов, которые не могли хорошо разбираться в программировании на Java. Самое лучшее в Apache Pig заключается в том, что он предлагает гибкость, требует меньше усилий, чем другие платформы, и снижает сложность кода.
Вот некоторые из ключевых приложений Apache Pig:
1. Обработка большого объема данных из датасетов
2. Полезно везде, где требуется аналитическая информация с использованием выборки.
3. Для сбора большого количества наборов данных в виде веб-сканирования и журналов поиска.
4. Требуется для прототипирования алгоритмов обработки больших наборов данных