
HadoopのApachePigアーキテクチャ:機能、アプリケーション、実行フロー
公開: 2020-06-26目次
ApachePigがとても人気がある理由
ビッグデータを分析および処理するために、HadoopはMapReduceを使用します。 MapReduceはJavaで書かれたプログラムです。 しかし、開発者は、これらの長いJavaコードを記述して維持するのが難しいと感じています。 Apache Pigを使用すると、開発者は複雑なJavaコードを使用せずに、大規模なデータセットをすばやく分析して処理できます。 Yahooの研究者によって開発されたApachePigは、広範なデータセットに対してMap Reduceジョブを実行し、開発者がデータを効率的に処理するための簡単なインターフェイスを提供します。
Apache Pigは、Javaプログラミングを理解していない人にとっては恩恵として浮上しました。 今日、Apache Pigは柔軟性を提供し、コードの複雑さを軽減し、労力が少なくて済むため、開発者の間で非常に人気があります。 初心者でデータサイエンスについて詳しく知りたい場合は、一流大学のデータサイエンスコースをご覧ください。
MapReduceとApachePig
次の表は、MapReduceとApachePigの違いをまとめたものです。
| アパッチピッグ | MapReduce |
| スクリプト言語 | コンパイル言語 |
| より高いレベルの抽象化を提供します | 低レベルの抽象化を提供します |
| 数行のコードが必要です(10行のコードで200行のMapReduceコードを要約できます) | より広範なコードが必要です(より多くのコード行) |
| より少ない開発時間と労力で済みます | より多くの開発時間と労力が必要 |
| コード効率の低下 | ApachePigと比較してコードの効率が高い |
ApachePigの機能
Apache Pigは、次の機能を提供します。
- プログラマーがより少ない行のコードを記述できるようにします。 プログラマーは、Pig Latin言語を使用して、わずか10行で200行のJavaコードを記述できます。
- Apache Pigマルチクエリアプローチは、開発時間を短縮します。
- Apache pigには、結合、フィルター、並べ替え、読み込み、グループ化などの操作を実行するための豊富なデータセットのセットがあります。
- Pigラテン語はSQLと非常によく似ています。 SQLの知識が豊富なプログラマーは、Pigスクリプトを簡単に作成できます。
- プログラマーがより少ない行のコードを記述できるようにします。 プログラマーは、Pig Latin言語を使用して、わずか10行で200行のJavaコードを記述できます。
- Apache Pigは、構造化データ分析と非構造化データ分析の両方を処理します。
ApachePigアプリケーション
ApachePigアプリケーションのいくつかは次のとおりです。
- 大量のデータを処理します
- 大規模なデータセット全体でのラピッドプロトタイピングとアドホッククエリをサポートします
- 検索プラットフォームでデータ処理を実行します
- 時間に敏感なデータロードを処理します
- 通信会社がユーザーの通話データ情報を匿名化するために使用します。
Apache Pigとは何ですか?
Map Reduceでは、プログラムをmapおよびreduceステージに変換する必要があります。 すべてのデータアナリストがMapReduceに精通しているわけではないため、ギャップを埋めるためにYahooの研究者によってApachepigが導入されました。 Pigは、高レベルの抽象化を提供し、プログラマーが複雑なMapReduceプログラムの作成に費やす時間を短縮できるHadoop上に構築されました。 Pigは頭字語ではありません。 家畜にちなんで名付けられました。 動物のブタは何でも食べるので、ブタはあらゆる種類のデータを処理できます。

ソース
HadoopのApachePigアーキテクチャ
Apache Pigアーキテクチャは、PigLatinスクリプトを使用して大量のデータセットを処理および分析するPigLatinインタープリターで構成されています。 プログラマーは、Pig Latin言語を使用して、Hadoop環境の大規模なデータセットを分析します。 Apache pigには、結合、フィルター、並べ替え、読み込み、グループ化などのさまざまなデータ操作を実行するための豊富なデータセットのセットがあります。
プログラマーは、特定のタスクを実行するためのPigスクリプトを作成するために、Pigラテン語を使用する必要があります。 Pigは、これらのPigスクリプトを一連のMap-Reduceジョブに変換して、プログラマーの作業を容易にします。 Pig Latinプログラムは、UDF、組み込み、Gruntシェルなどのさまざまなメカニズムを介して実行されます。
Apache Pigアーキテクチャは、次の主要コンポーネントで構成されています。
- パーサー
- オプティマイザ
- コンパイラ
- 実行エンジン
- 実行モード
これらすべてのPigコンポーネントを詳細に調べてみましょう。
ピッグラテンスクリプト
Pigスクリプトは、Pig実行環境に送信され、目的の結果が生成されます。
次のいずれかの方法を使用して、Pigスクリプトを実行できます。
- グラントシェル
- スクリプトファイル
- 埋め込みスクリプト
パーサー
パーサーは、すべてのPigLatinステートメントまたはコマンドを処理します。 パーサーは、構文チェック、型チェックなどのPigステートメントに対していくつかのチェックを実行し、 DAG(有向非巡回グラフ)出力を生成します。 DAG出力は、スクリプトのすべての論理演算子をノードとして表し、データフローをエッジとして表します。
オプティマイザ
解析操作が完了し、DAG出力が生成されると、出力はオプティマイザーに渡されます。 次に、オプティマイザーは、分割、マージ、プロジェクション、プッシュダウン、変換、並べ替えなどの最適化アクティビティを出力に対して実行します。オプティマイザーは、プッシュダウンおよびプロジェクションアクティビティを実行することにより、抽出されたデータを処理し、不要なデータまたは列を省略して、クエリのパフォーマンスを向上させます。 。

コンパイラ
コンパイラーは、オプティマイザーによって生成された出力を一連のMapReduceジョブにコンパイルします。 コンパイラーは、PigジョブをMap Reduceジョブに自動的に変換し、実行順序を再配置することでパフォーマンスを最適化します。
実行エンジン
上記のすべての操作を実行した後、これらのMap Reduceジョブは実行エンジンに送信され、Hadoopプラットフォームで実行されて、目的の結果が生成されます。 次に、DUMPステートメントを使用して結果を画面に表示したり、STOREステートメントを使用して結果をHDFS (Hadoop分散ファイルシステム)に保存したりできます。
実行モード
Apache Pigは、ローカルとMapReduceの2つの実行モードで実行されます。 実行モードの選択は、データが保存されている場所と、Pigスクリプトを実行する場所によって異なります。 データをローカル(単一のマシン)または分散Hadoopクラスター環境に保存できます。
- ローカルモード–データセットが小さい場合は、ローカルモードを使用できます。 ローカルモードでは、Pigはローカルホストとファイルシステムを使用して単一のJVMで実行されます。 このモードでは、すべてのファイルがローカルホストにインストールされて実行されるため、並列マッパーの実行は不可能です。 pig -x localコマンドを使用して、ローカルモードを指定できます。
- MapReduceモード–ApachePigはデフォルトでMapReduceモードを使用します。 Map Reduceモードでは、プログラマーは、 HDFS(Hadoop分散ファイルシステム)に既に保存されているデータに対してPigLatinステートメントを実行します。 pig -x mapreduceコマンドを使用して、Map-Reduceモードを指定できます。
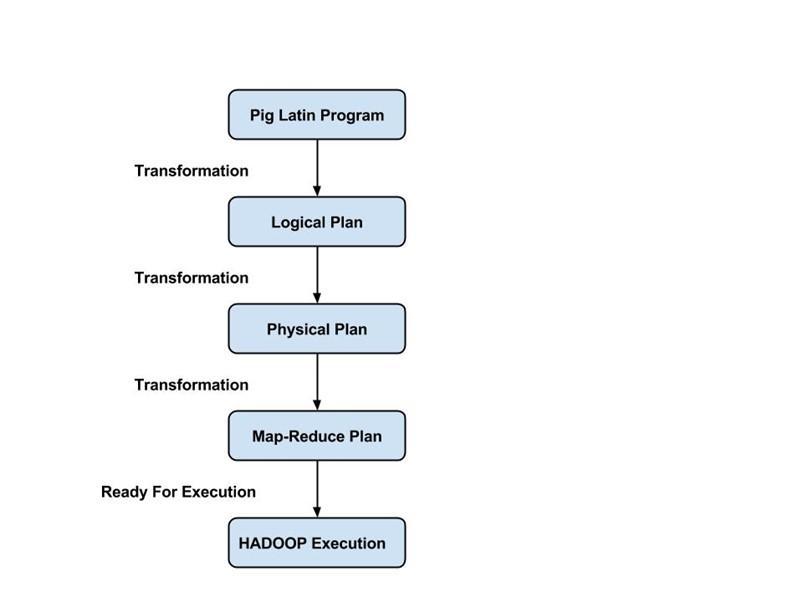
ソース
ピッグラテンデータモデル
Pig Latinデータモデルを使用すると、Pigはあらゆる種類のデータを処理できます。 Pig Latinデータモデルは完全にネストされており、整数、浮動小数点数などのアトミックデータ型と、マップやタプルなどの非アトミック複合データ型の両方を処理できます。
データモデルを深く理解しましょう。
- アトム–アトムは、文字列形式で格納された単一の値であり、数値および文字列として使用できます。 Pigのアトミック値は、integer、double、float、byte array、およびchararrayです。 単一のアトミック値はフィールドとも呼ばれます。
たとえば、「キアラ」または27
- タプル–タプルは、順序付けられたフィールドのセット(任意のタイプ)を含むレコードです。 タプルは、 RDBMS(リレーショナルデータベース管理システム)の行と非常によく似ています。
たとえば、(キアラ、27)
- バッグ–アトムは文字列形式で格納された単一の値であり、数値および文字列として使用できます。 Pigのアトミック値は、integer、double、float、byte array、およびchararrayです。 単一のアトミック値はフィールドとも呼ばれます。
たとえば、{(Kiara、27)、(Kehsav、45)}
- マップ–キーと値のペアセットはマップと呼ばれます。 キーは一意である必要があり、char配列型である必要があります。 ただし、値はどのようなものでもかまいません。
例:[name#Kiara、age#27]
- 関係–タプルのバッグは関係と呼ばれます。
Pigジョブの実行フロー
次の手順では、Pigジョブの実行フローについて説明します。
- 開発者は、Pig Latin言語を使用してPigスクリプトを作成し、ローカルファイルシステムに保存します。
- Pigスクリプトを送信した後、Apache Pigはコンパイラーとの接続を確立し、一連のMapReduceジョブを出力として生成します。
- Pigコンパイラは、HDFS実行操作から生データを受け取り、MapReduceジョブが終了した後に結果をHDFSに保存します。
また読む: ApachePigチュートリアル
結論
このブログでは、 Apache Pigアーキテクチャ、Pigコンポーネント、MapReduceとApachePigの違い、Pig Latinデータモデル、およびPigジョブの実行フローについて学習しました。
Apache Pigは、簡単なインターフェイスを備えたプラットフォームを提供し、コードの複雑さを軽減し、効率的に結果を達成するのに役立つため、プログラマーにとってメリットがあります。 Yahoo、eBay、LinkedIn、Twitterは、Pigを使用して大量のデータを処理している企業の一部です。
Apache Pig、データサイエンスについて知りたい場合は、IIIT-BとupGradのデータサイエンスのエグゼクティブPGプログラムをご覧ください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界とのメンターシップを提供します。専門家、業界のメンターと1対1で、400時間以上の学習とトップ企業との仕事の支援。
Apache Pigの機能は何ですか?
Apache Pigは、大規模なデータセットの処理に使用される非常に高レベルのツールまたはプラットフォームです。 データ分析コードは、PigLatinと呼ばれる高レベルのスクリプト言語を使用して開発されています。 まず、プログラマーは、データを特定のマップに処理してタスクを減らすためのPigLatinスクリプトを作成します。 Apache Pigには多くの機能があり、非常に便利なツールになっています。
1.並べ替え、結合、フィルターなどのさまざまな操作を実行するための豊富な演算子のセットを提供します。
2. Apache Pigは、学習、読み取り、および書き込みが簡単であるため、SQLプログラマーにとって恩恵であると考えられています。
3.ユーザー定義の関数とプロセスの作成は簡単です
4.プロセスまたは機能に必要なコード行が少なくて済みます
5.ユーザーが非構造化データと構造化データの両方の分析を実行できるようにします
6.結合および分割操作は非常に簡単に実行できます
Apache Pigで使用可能な実行モードは何ですか?
Apache Pigは、次の2つの異なるモードで実行できます。
1.ローカルモード-すべてのファイルは、このモードでローカルファイルシステムとローカルホストからインストールおよび実行されます。 通常、このモードはテストの目的で使用されます。 ここでは、HDFSやHadoopは必要ありません。
2. MapReduceモード-MapReduceモードでは、Apache Pigを使用して、Hadoopファイルシステム(HDFS)にすでに存在するデータをロードおよび処理します。 データを処理するためにPigLatinステートメントを実行しようとすると、バックエンドでMapReduceジョブが呼び出されます。 HDFS内の既存のデータに対して特定の操作を実行します。
Apache Pigの主要なアプリケーションにはどのようなものがありますか?
Apache Pigは、Javaプログラミングを十分に理解できなかったすべてのプログラマーにとって恩恵であることが判明しました。 Apache Pigの最も優れている点は、柔軟性があり、他のプラットフォームよりも労力が少なくて済み、コードの複雑さが軽減されることです。
ApachePigの主要なアプリケーションのいくつかは次のとおりです。
1.データセットからの大量のデータの処理
2.サンプリングを使用して分析的洞察が必要なすべての場所で役立ちます
3.Webクロールおよび検索ログの形式で大量のデータセットを収集する場合
4.大規模なデータセットの処理アルゴリズムのプロトタイピングに必要