
Architektura Apache Pig w Hadoop: funkcje, aplikacje, przepływ wykonania
Opublikowany: 2020-06-26Spis treści
Dlaczego Apache Pig jest tak popularny
Aby analizować i przetwarzać duże zbiory danych, Hadoop używa funkcji Map Reduce. Map Reduce to program napisany w Javie. Jednak deweloperom trudno jest pisać i utrzymywać te długie kody Java. Dzięki Apache Pig programiści mogą szybko analizować i przetwarzać duże zestawy danych bez używania złożonych kodów Java. Apache Pig, opracowany przez badaczy Yahoo, wykonuje zadania Map Reduce na obszernych zestawach danych i zapewnia programistom łatwy interfejs do wydajnego przetwarzania danych.
Apache Pig pojawił się jako dobrodziejstwo dla tych, którzy nie rozumieją programowania w Javie. Dzisiaj Apache Pig stał się bardzo popularny wśród programistów, ponieważ oferuje elastyczność, zmniejsza złożoność kodu i wymaga mniej wysiłku. Jeśli jesteś początkującym i chcesz dowiedzieć się więcej na temat nauki o danych, sprawdź nasze kursy nauki o danych prowadzone przez najlepsze uniwersytety.
Redukcja mapy kontra Apache Pig
Poniższa tabela podsumowuje różnicę między mapą Reduce i Apache Pig:
| Świnia Apaczów | Zmniejszenie mapy |
| Język skryptowy | Skompilowany język |
| Zapewnia wyższy poziom abstrakcji | Zapewnia niski poziom abstrakcji |
| Wymaga kilku linijek kodu (10 linijek kodu może podsumować 200 linijek kodu Map Reduce) | Wymaga bardziej rozbudowanego kodu (więcej linii kodu) |
| Wymaga mniej czasu i wysiłku na rozwój | Wymaga więcej czasu i wysiłku na rozwój |
| Mniejsza wydajność kodu | Większa wydajność kodu w porównaniu do Apache Pig |
Funkcje Apache Pig
Apache Pig oferuje następujące funkcje:
- Pozwala programistom pisać mniej linii kodu. Programiści mogą napisać 200 wierszy kodu Java w zaledwie 10 wierszach przy użyciu języka Pig Latin.
- Podejście oparte na wielu zapytaniach Apache Pig skraca czas programowania.
- Apache Pig ma bogaty zestaw zestawów danych do wykonywania operacji, takich jak łączenie, filtrowanie, sortowanie, ładowanie, grupowanie itp.
- Język Pig Latin jest bardzo podobny do SQL. Programiści z dobrą znajomością SQL mogą z łatwością napisać skrypt Pig.
- Pozwala programistom pisać mniej linii kodu. Programiści mogą napisać 200 wierszy kodu Java w zaledwie 10 wierszach przy użyciu języka Pig Latin.
- Apache Pig obsługuje zarówno ustrukturyzowaną, jak i nieustrukturyzowaną analizę danych.
Aplikacje Apache Pig
Oto kilka aplikacji Apache Pig:
- Przetwarza duże ilości danych
- Obsługuje szybkie prototypowanie i zapytania ad-hoc w dużych zbiorach danych
- Wykonuje przetwarzanie danych w platformach wyszukiwania
- Przetwarza ładowanie danych wrażliwe na czas
- Wykorzystywane przez firmy telekomunikacyjne do deidentyfikacji informacji o danych połączeń użytkownika.
Co to jest świnia Apache?
Map Reduce wymaga, aby programy były tłumaczone na mapę i zmniejszały etapy. Ponieważ nie wszyscy analitycy danych byli zaznajomieni z Map Reduce, dlatego badacze Yahoo wprowadzili Apache Pig, aby wypełnić lukę. Świnia została zbudowana na platformie Hadoop, która zapewnia wysoki poziom abstrakcji i pozwala programistom spędzać mniej czasu na pisaniu złożonych programów Map Reduce. Świnia nie jest akronimem; został nazwany na cześć zwierzęcia domowego. Ponieważ świnia zwierzęca zjada wszystko, Świnia może pracować na dowolnym rodzaju danych.

Źródło
Architektura Apache Pig w Hadoop
Architektura Apache Pig składa się z interpretera Pig Latin, który wykorzystuje skrypty Pig Latin do przetwarzania i analizowania ogromnych zbiorów danych. Programiści używają języka Pig Latin do analizowania dużych zbiorów danych w środowisku Hadoop. Apache Pig ma bogaty zestaw zestawów danych do wykonywania różnych operacji na danych, takich jak łączenie, filtrowanie, sortowanie, ładowanie, grupowanie itp.
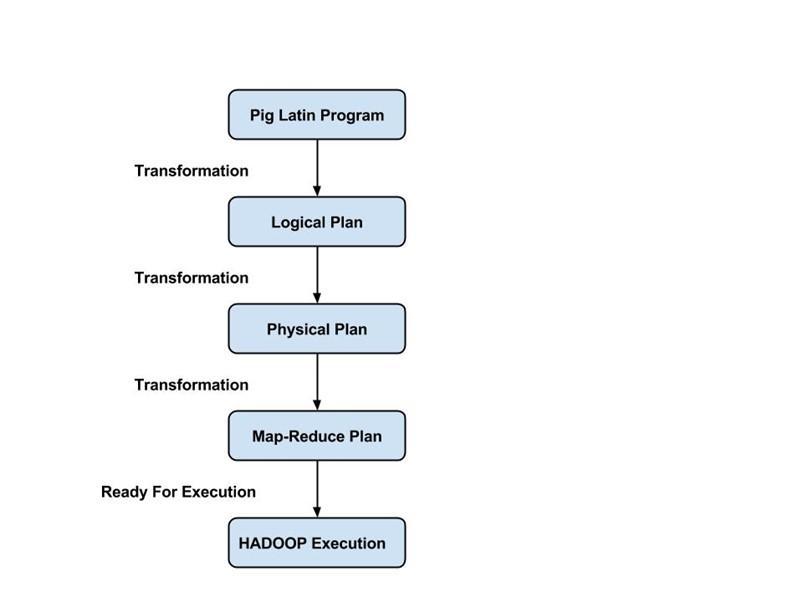
Programiści muszą używać języka Pig Latin, aby napisać skrypt Pig wykonujący określone zadanie. Pig konwertuje te skrypty Pig w serię zadań Map-Reduce, aby ułatwić pracę programistów. Programy Pig Latin są wykonywane za pomocą różnych mechanizmów, takich jak UDF, powłoki wbudowane i Grunt.
Architektura Apache Pig składa się z następujących głównych komponentów:
- Parser
- Optymalizator
- Kompilator
- Silnik wykonawczy
- Tryb wykonania
Przeanalizujmy szczegółowo wszystkie te składniki Pig.
Świńskie skrypty łacińskie
Skrypty Pig są przesyłane do środowiska wykonawczego Pig w celu uzyskania pożądanych rezultatów.
Skrypty Pig można uruchomić za pomocą jednej z metod:
- Grunt Shell
- Plik skryptu
- Skrypt osadzony
Parser
Parser obsługuje wszystkie instrukcje i polecenia Pig Latin. Parser wykonuje kilka kontroli instrukcji Pig, takich jak sprawdzanie składni, sprawdzanie typu i generuje dane wyjściowe DAG (Directed Acyclic Graph) . Dane wyjściowe DAG reprezentują wszystkie operatory logiczne skryptów jako węzły, a przepływ danych jako krawędzie.
Optymalizator
Po zakończeniu operacji analizowania i wygenerowaniu danych wyjściowych DAG dane wyjściowe są przekazywane do optymalizatora. Optymalizator następnie wykonuje czynności optymalizacyjne na wyjściu, takie jak dzielenie, scalanie, projekcja, przesuwanie w dół, przekształcanie, zmiana kolejności itp. Optymalizator przetwarza wyodrębnione dane i pomija niepotrzebne dane lub kolumny, wykonując czynności przesuwania i projekcji oraz poprawia wydajność zapytań .

Kompilator
Kompilator kompiluje dane wyjściowe generowane przez optymalizator w serię zadań Map Reduce. Kompilator automatycznie konwertuje zadania Pig na zadania Map Reduce i optymalizuje wydajność poprzez zmianę kolejności wykonywania.
Silnik wykonawczy
Po wykonaniu wszystkich powyższych operacji zadania Map Reduce są przesyłane do silnika wykonawczego, który jest następnie wykonywany na platformie Hadoop w celu uzyskania pożądanych wyników. Następnie można użyć instrukcji DUMP do wyświetlenia wyników na ekranie lub instrukcji STORE do przechowywania wyników w systemie plików HDFS (Hadoop Distributed File System).
Tryb wykonania
Apache Pig jest wykonywany w dwóch trybach wykonania: lokalnym i Map Reduce. Wybór trybu wykonania zależy od tego, gdzie przechowywane są dane i gdzie chcesz uruchomić skrypt Pig. Dane można przechowywać lokalnie (na jednej maszynie) lub w rozproszonym środowisku klastra Hadoop.
- Tryb lokalny — możesz użyć trybu lokalnego, jeśli zestaw danych jest mały. W trybie lokalnym Pig działa w pojedynczej JVM, korzystając z lokalnego hosta i systemu plików. W tym trybie równoległe wykonanie mapowania jest niemożliwe, ponieważ wszystkie pliki są instalowane i uruchamiane na hoście lokalnym. Możesz użyć polecenia pig -x local , aby określić tryb lokalny.
- Tryb redukcji mapy – Apache Pig domyślnie używa trybu redukcji mapy. W trybie Map Reduce programista wykonuje instrukcje Pig Latin na danych, które są już zapisane w HDFS (Hadoop Distributed File System) . Możesz użyć polecenia pig -x mapreduce , aby określić tryb Map-Reduce.
Źródło
Świński łaciński model danych
Model danych Pig Latin pozwala Pig na obsługę każdego rodzaju danych. Model danych Pig Latin jest w pełni zagnieżdżony i może traktować zarówno atomowe, takie jak liczby całkowite, zmiennoprzecinkowe, jak i nieatomowe złożone typy danych, takie jak Map i krotka.
Pozwól nam dogłębnie zrozumieć model danych:
- Atom – Atom to pojedyncza wartość przechowywana w postaci ciągu i może być używana jako liczba i ciąg. Atomowe wartości Pig to integer, double, float, tablica bajtów i tablica znaków. Pojedyncza wartość atomowa jest również nazywana polem.
Na przykład „Kiara” lub 27
- Krotka — krotka to rekord, który zawiera uporządkowany zestaw pól (dowolnego typu). Krotka jest bardzo podobna do wiersza w RDBMS (Relational Database Management System) .
Na przykład (Kiara, 27 lat)
- Torba – atom to pojedyncza wartość przechowywana w postaci ciągu i może być używana jako liczba i ciąg. Atomowe wartości Pig to integer, double, float, tablica bajtów i tablica znaków. Pojedyncza wartość atomowa jest również nazywana polem.
Na przykład {(Kiara, 27), (Kehsav, 45)}
- Mapa — zestaw par klucz-wartość jest znany jako mapa. Klucz musi być unikalny i powinien być typu tablica znaków. Jednak wartość może być dowolna.
Na przykład [imię#Kiara, wiek#27]
- Relacja — worek krotek nazywa się relacją.
Przepływ wykonania zadania świnia
Poniższe kroki wyjaśniają przepływ wykonania zadania Pig:
- Deweloper pisze skrypt Pig w języku Pig Latin i przechowuje go w lokalnym systemie plików.
- Po przesłaniu skryptów Pig, Apache Pig nawiązuje połączenie z kompilatorem i generuje serię zadań Map Reduce Jobs jako dane wyjściowe.
- Kompilator Pig otrzymuje surowe dane z operacji HDFS i przechowuje wyniki w HDFS po zakończeniu zadań Map Reduce.
Przeczytaj także: Samouczek Apache Pig
Wniosek
W tym blogu dowiedzieliśmy się o architekturze Apache Pig Architecture , komponentach Pig, różnicy między Map Reduce i Apache Pig, modelu danych Pig Latin oraz przepływie wykonywania zadania Pig.
Apache Pig jest dobrodziejstwem dla programistów, ponieważ zapewnia platformę z łatwym interfejsem, zmniejsza złożoność kodu i pomaga im skutecznie osiągać wyniki. Yahoo, eBay, LinkedIn i Twitter to niektóre z firm, które wykorzystują Pig do przetwarzania dużych ilości danych.
Jeśli chcesz dowiedzieć się więcej o Apache Pig, nauce o danych, sprawdź program Executive PG w dziedzinie Data Science IIIT-B i upGrad, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z przemysłem eksperci, indywidualni z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Jakie są cechy Apache Pig?
Apache Pig to bardzo wysokopoziomowe narzędzie lub platforma używana do przetwarzania dużych zbiorów danych. Kody analizy danych są opracowywane przy użyciu języka skryptowego wysokiego poziomu o nazwie Pig Latin. Po pierwsze, programiści napiszą skrypty Pig Latin, aby przetworzyć dane na określoną mapę i zredukować zadania. Apache Pig ma wiele funkcji, co czyni go bardzo przydatnym narzędziem.
1. Zapewnia bogaty zestaw operatorów do wykonywania różnych operacji, takich jak sortowanie, sprzężenia, filtrowanie itp.
2. Apache Pig jest uważany za dobrodziejstwo dla programistów SQL, ponieważ jest łatwy do nauczenia, czytania i pisania.
3. Tworzenie funkcji i procesów zdefiniowanych przez użytkownika jest łatwe
4. Mniej linii kodu jest wymaganych dla dowolnego procesu lub funkcji
5. Umożliwia użytkownikom przeprowadzanie analizy zarówno danych nieustrukturyzowanych, jak i ustrukturyzowanych
6. Operacje łączenia i dzielenia są dość łatwe do wykonania
Jakie są dostępne tryby wykonywania w Apache Pig?
Apache Pig można uruchomić w dwóch różnych trybach:
1. Tryb lokalny — wszystkie pliki zostaną zainstalowane i uruchomione z lokalnego systemu plików i lokalnego hosta w tym trybie. Zazwyczaj ten tryb jest wykorzystywany do celów testowych. Tutaj nie potrzebujesz HDFS ani Hadoop.
2. Tryb MapReduce - W trybie MapReduce, Apache Pig służy do ładowania i przetwarzania danych, które już istnieją w systemie plików Hadoop (HDFS). Zadanie MapReduce zostanie wywołane na zapleczu za każdym razem, gdy spróbujemy wykonać instrukcję Pig Latin w celu przetworzenia danych. Wykona określoną operację na już istniejących danych w HDFS.
Jakie są niektóre z kluczowych zastosowań Apache Pig?
Apache Pig okazał się być dobrodziejstwem dla wszystkich tych programistów, którzy nie byli w stanie biegle zrozumieć programowania w Javie. Najlepszą rzeczą w Apache Pig jest to, że oferuje elastyczność, wymaga mniej wysiłku niż inne platformy i zmniejsza złożoność kodu.
Niektóre z kluczowych zastosowań Apache Pig to:
1. Przetwarzanie dużej ilości danych ze zbiorów danych
2. Przydatne wszędzie tam, gdzie wymagane są wglądy analityczne z wykorzystaniem próbkowania
3. Do gromadzenia dużej ilości zbiorów danych w postaci indeksowania sieci i dzienników wyszukiwania
4. Wymagane do prototypowania algorytmów przetwarzania dużych zbiorów danych