
Arhitectura Apache Pig în Hadoop: caracteristici, aplicații, flux de execuție
Publicat: 2020-06-26Cuprins
De ce Apache Pig este atât de popular
Pentru a analiza și procesa date mari, Hadoop folosește Map Reduce. Map Reduce este un program care este scris în Java. Dar dezvoltatorilor le este dificil să scrie și să mențină aceste coduri Java lungi. Cu Apache Pig, dezvoltatorii pot analiza și procesa rapid seturi mari de date fără a utiliza coduri Java complexe. Apache Pig dezvoltat de cercetătorii Yahoo execută lucrări Map Reduce pe seturi extinse de date și oferă dezvoltatorilor o interfață ușoară pentru a procesa datele în mod eficient.
Apache Pig a apărut ca un avantaj pentru cei care nu înțeleg programarea Java. Astăzi, Apache Pig a devenit foarte popular în rândul dezvoltatorilor, deoarece oferă flexibilitate, reduce complexitatea codului și necesită mai puțin efort. Dacă sunteți începător și doriți să aflați mai multe despre știința datelor, consultați cursurile noastre de știință a datelor de la universități de top.
Map Reduce vs. Apache Pig
Următorul tabel rezumă diferența dintre Map Reduce și Apache Pig:
| Apache Pig | Reducere hartă |
| Limbajul de scriptare | Limbajul compilat |
| Oferă un nivel mai ridicat de abstractizare | Oferă un nivel scăzut de abstractizare |
| Necesită câteva linii de cod (10 linii de cod pot rezuma 200 de linii de cod Map Reduce) | Necesită un cod mai extins (mai multe linii de cod) |
| Necesită mai puțin timp de dezvoltare și efort | Necesită mai mult timp de dezvoltare și efort |
| Eficiență mai mică a codului | Eficiență mai mare a codului în comparație cu Apache Pig |
Caracteristici Apache Pig
Apache Pig oferă următoarele caracteristici:
- Permite programatorilor să scrie mai puține linii de coduri. Programatorii pot scrie 200 de linii de cod Java în doar zece linii folosind limbajul Pig Latin.
- Abordarea multi-interogare Apache Pig reduce timpul de dezvoltare.
- Apache pig are un set bogat de seturi de date pentru efectuarea de operațiuni precum alăturarea, filtrarea, sortarea, încărcarea, gruparea etc.
- Limba latină porc este foarte asemănătoare cu SQL. Programatorilor cu cunoștințe bune SQL le este ușor să scrie script Pig.
- Permite programatorilor să scrie mai puține linii de coduri. Programatorii pot scrie 200 de linii de cod Java în doar zece linii folosind limbajul Pig Latin.
- Apache Pig se ocupă atât de analiza datelor structurate, cât și a celor nestructurate.
Aplicații Apache Pig
Câteva dintre aplicațiile Apache Pig sunt:
- Prelucrează un volum mare de date
- Suporta prototipuri rapide și interogări ad-hoc pe seturi mari de date
- Efectuează prelucrarea datelor în platformele de căutare
- Procesează încărcări de date sensibile la timp
- Folosit de companiile de telecomunicații pentru a de-identifica informațiile despre datele apelurilor utilizatorului.
Ce este Apache Pig?
Map Reduce necesită ca programele să fie traduse în hartă și să reducă etapele. Deoarece nu toți analiștii de date erau familiarizați cu Map Reduce, prin urmare, Apache pig a fost introdus de cercetătorii Yahoo pentru a reduce decalajul. Pig a fost construit pe Hadoop, care oferă un nivel ridicat de abstractizare și le permite programatorilor să petreacă mai puțin timp scriind programe complexe Map Reduce. Porcul nu este un acronim; a fost numit după un animal domestic. Deoarece un animal porc mănâncă orice, Pig poate lucra cu orice fel de date.

Sursă
Apache Pig Architecture în Hadoop
Arhitectura Apache Pig constă dintr-un interpret Pig Latin care utilizează scripturi Pig Latin pentru a procesa și analiza seturi masive de date. Programatorii folosesc limbajul Pig Latin pentru a analiza seturi mari de date în mediul Hadoop. Apache pig are un set bogat de seturi de date pentru a efectua diferite operațiuni de date, cum ar fi alăturarea, filtrarea, sortarea, încărcarea, gruparea etc.
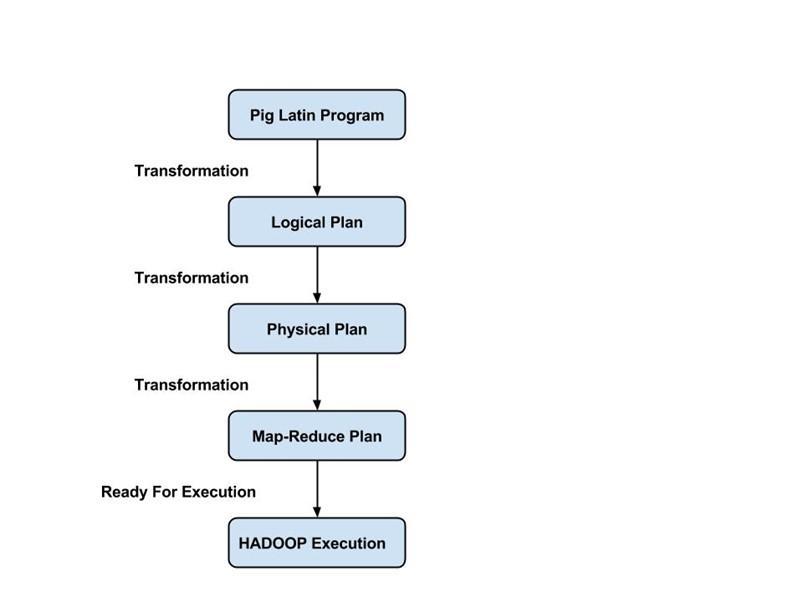
Programatorii trebuie să folosească limbajul Pig Latin pentru a scrie un script Pig pentru a îndeplini o anumită sarcină. Pig convertește aceste scripturi Pig într-o serie de joburi Map-Reduce pentru a ușura munca programatorilor. Programele Pig Latin sunt executate prin diferite mecanisme, cum ar fi UDF-uri, shell-uri încorporate și Grunt.
Arhitectura Apache Pig este formată din următoarele componente majore:
- Analizator
- Optimizer
- Compilator
- Motor de execuție
- Modul de execuție
Să studiem toate aceste componente Pig în detaliu.
Scriere latină de porc
Scripturile Pig sunt trimise mediului de execuție Pig pentru a produce rezultatele dorite.
Puteți executa scripturile Pig folosind una dintre metodele:
- Grunt Shell
- Fișier script
- Script încorporat
Analizator
Parser se ocupă de toate instrucțiunile sau comenzile Pig Latin. Parserul efectuează mai multe verificări asupra instrucțiunilor Pig, cum ar fi verificarea sintaxei, verificarea tipului și generează o ieșire DAG (Grafic aciclic direcționat) . Ieșirea DAG reprezintă toți operatorii logici ai scripturilor ca noduri și fluxul de date ca margini.
Optimizer
Odată ce operațiunea de analizare este finalizată și este generată o ieșire DAG, ieșirea este transmisă optimizatorului. Optimizatorul efectuează apoi activitățile de optimizare pe rezultat, cum ar fi împărțirea, îmbinare, proiecție, pushdown, transformare și reordonare etc. Optimizatorul procesează datele extrase și omite datele sau coloanele inutile prin efectuarea activității de pushdown și proiecție și îmbunătățește performanța interogărilor. .

Compilator
Compilatorul compilează rezultatul care este generat de optimizator într-o serie de joburi Map Reduce. Compilatorul convertește automat joburile Pig în joburi Map Reduce și optimizează performanța prin rearanjarea ordinii de execuție.
Motor de execuție
După efectuarea tuturor operațiunilor de mai sus, aceste joburi Map Reduce sunt transmise motorului de execuție, care este apoi executat pe platforma Hadoop pentru a produce rezultatele dorite. Puteți utiliza apoi instrucțiunea DUMP pentru a afișa rezultatele pe ecran sau instrucțiunile STORE pentru a stoca rezultatele în HDFS (Hadoop Distributed File System).
Modul de execuție
Apache Pig este executat în două moduri de execuție care sunt locale și Map Reduce. Alegerea modului de execuție depinde de locul în care sunt stocate datele și de unde doriți să rulați scriptul Pig. Puteți stoca datele fie local (într-o singură mașină), fie într-un mediu de cluster Hadoop distribuit.
- Modul local – Puteți utiliza modul local dacă setul de date este mic. În modul local, Pig rulează într-un singur JVM folosind gazda locală și sistemul de fișiere. În acest mod, execuția mapperului paralel este imposibilă, deoarece toate fișierele sunt instalate și rulate pe localhost. Puteți utiliza comanda locală pig -x pentru a specifica modul local.
- Modul Map Reduce – Apache Pig folosește modul Map Reduce în mod implicit. În modul Map Reduce, un programator execută instrucțiunile Pig Latin pe date care sunt deja stocate în HDFS (Hadoop Distributed File System) . Puteți utiliza comanda pig -x mapreduce pentru a specifica modul Map-Reduce.
Sursă
Pig Latin Data Model
Modelul de date Pig Latin îi permite lui Pig să gestioneze orice tip de date. Modelul de date Pig Latin este complet imbricat și poate trata atât tipuri de date atomice, cum ar fi întregi, float, cât și non-atomice complexe, cum ar fi Map și tuplu.
Să înțelegem în profunzime modelul de date:
- Atom – Un atom este o singură valoare stocată sub formă de șir și poate fi folosit ca număr și șir. Valorile atomice ale lui Pig sunt întregi, dublu, float, matrice de octeți și matrice de caractere. O singură valoare atomică se mai numește și câmp.
De exemplu, „Kiara” sau 27
- Tuplu – Un tuplu este o înregistrare care conține un set ordonat de câmpuri (orice tip). Un tuplu este foarte asemănător cu un rând dintr-un RDBMS (Relational Database Management System) .
De exemplu, (Kiara, 27 de ani)
- Bag – Un atom este o singură valoare stocată sub formă de șir și poate fi folosit ca număr și șir. Valorile atomice ale lui Pig sunt întregi, dublu, float, matrice de octeți și matrice de caractere. O singură valoare atomică se mai numește și câmp.
De exemplu, {(Kiara, 27), (Kehsav, 45)}
- Hartă – Un set de perechi cheie-valoare este cunoscut sub numele de hartă. Cheia trebuie să fie unică și trebuie să fie de tip matrice char. Cu toate acestea, valoarea poate fi de orice fel.
De exemplu, [nume#Kiara, vârsta#27]
- Relație – Un sac de tupluri se numește relație.
Fluxul de execuție al unei lucrări de porc
Următorii pași explică fluxul de execuție al unui job Pig:
- Dezvoltatorul scrie un script Pig folosind limba Pig Latin și îl stochează în sistemul de fișiere local.
- După trimiterea scripturilor Pig, Apache Pig stabilește o conexiune cu compilatorul și generează o serie de joburi Map Reduce ca rezultat.
- Compilatorul Pig primește date brute de la HDFS, efectuează operațiuni și stochează rezultatele în HDFS după ce lucrările Map Reduce sunt terminate.
Citește și: Tutorial Apache Pig
Concluzie
În acest blog, am aflat despre arhitectura Apache Pig , componentele Pig, diferența dintre Map Reduce și Apache Pig, modelul de date Pig Latin și fluxul de execuție al unui job Pig.
Apache Pig este un avantaj pentru programatori, deoarece oferă o platformă cu o interfață ușoară, reduce complexitatea codului și îi ajută să obțină eficient rezultate. Yahoo, eBay, LinkedIn și Twitter sunt unele dintre companiile care folosesc Pig pentru a-și procesa volumele mari de date.
Dacă sunteți curios să aflați despre Apache Pig, știința datelor, consultați Programul Executive PG în știința datelor de la IIIT-B și upGrad, care este creat pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu industrie experți, 1-la-1 cu mentori din industrie, peste 400 de ore de învățare și asistență la locul de muncă cu firme de top.
Care sunt caracteristicile Apache Pig?
Apache Pig este o unealtă sau o platformă de nivel foarte înalt folosită pentru procesarea seturilor mari de date. Codurile de analiză a datelor sunt dezvoltate cu ajutorul unui limbaj de scripting de nivel înalt numit Pig Latin. În primul rând, programatorii vor scrie scripturi Pig Latin pentru a procesa datele într-o anumită hartă și pentru a reduce sarcinile. Apache Pig are o mulțime de caracteristici care îl fac un instrument foarte util.
1. Oferă un set bogat de operatori pentru a efectua diferite operații, cum ar fi sortarea, îmbinările, filtrarea etc.
2. Apache Pig este considerat a fi un avantaj pentru programatorii SQL, deoarece este ușor de învățat, citit și scris.
3. Realizarea de funcții și procese definite de utilizator este ușoară
4. Sunt necesare mai puține linii de cod pentru orice proces sau funcție
5. Permite utilizatorilor să efectueze analize atât a datelor nestructurate, cât și a celor structurate
6. Operațiunile de alăturare și împărțire sunt destul de ușor de efectuat
Care sunt modurile de execuție disponibile în Apache Pig?
Apache Pig poate fi executat în două moduri diferite:
1. Modul local - Toate fișierele vor fi instalate și rulate din sistemul dvs. de fișiere local și gazda locală în acest mod. De obicei, acest mod este utilizat în scopul testării. Aici, nu veți avea nevoie de HDFS sau Hadoop.
2. Modul MapReduce - În modul MapReduce, Apache Pig este folosit pentru încărcarea și procesarea datelor care există deja în sistemul de fișiere Hadoop (HDFS). Un job MapReduce va fi invocat în back-end ori de câte ori încercăm să executăm o instrucțiune Pig Latin pentru procesarea datelor. Va efectua o anumită operație asupra datelor deja existente în HDFS.
Care sunt unele dintre aplicațiile cheie ale Apache Pig?
Apache Pig s-a dovedit a fi un avantaj pentru toți acei programatori care nu au fost capabili să înțeleagă cu competență programarea Java. Cel mai bun lucru despre Apache Pig este că oferă flexibilitate, necesită mai puțin efort decât alte platforme și reduce complexitatea codului.
Unele dintre aplicațiile cheie ale Apache Pig sunt:
1. Prelucrarea unui volum mare de date din seturile de date
2. Util în orice loc unde sunt necesare perspective analitice prin utilizarea eșantionării
3. Pentru colectarea unei cantități mari de seturi de date sub formă de accesări cu crawlere pe web și jurnale de căutare
4. Necesar pentru prototiparea algoritmilor de procesare a seturi de date mari