
Architettura Apache Pig in Hadoop: funzionalità, applicazioni, flusso di esecuzione
Pubblicato: 2020-06-26Sommario
Perché Apache Pig è così popolare
Per analizzare ed elaborare i big data, Hadoop utilizza Map Reduce. Map Reduce è un programma scritto in Java. Tuttavia, gli sviluppatori trovano difficile scrivere e mantenere questi lunghi codici Java. Con Apache Pig, gli sviluppatori possono analizzare ed elaborare rapidamente set di dati di grandi dimensioni senza utilizzare codici Java complessi. Apache Pig sviluppato dai ricercatori di Yahoo esegue i lavori Map Reduce su set di dati estesi e fornisce un'interfaccia semplice agli sviluppatori per elaborare i dati in modo efficiente.
Apache Pig è emerso come una manna per coloro che non capiscono la programmazione Java. Oggi, Apache Pig è diventato molto popolare tra gli sviluppatori in quanto offre flessibilità, riduce la complessità del codice e richiede meno sforzo. Se sei un principiante e sei interessato a saperne di più sulla scienza dei dati, dai un'occhiata ai nostri corsi di scienza dei dati delle migliori università.
Riduci mappa contro Apache Pig
La tabella seguente riassume la differenza tra Map Reduce e Apache Pig:
| Maiale Apache | Riduci mappa |
| Linguaggio di scripting | Linguaggio compilato |
| Fornisce un livello di astrazione più elevato | Fornisce un basso livello di astrazione |
| Richiede poche righe di codice (10 righe di codice possono riassumere 200 righe di codice Map Reduce) | Richiede un codice più esteso (più righe di codice) |
| Richiede meno tempo e fatica di sviluppo | Richiede più tempo e impegno per lo sviluppo |
| Minore efficienza del codice | Maggiore efficienza del codice rispetto ad Apache Pig |
Caratteristiche di Apache Pig
Apache Pig offre le seguenti funzionalità:
- Consente ai programmatori di scrivere meno righe di codice. I programmatori possono scrivere 200 righe di codice Java in sole dieci righe utilizzando il linguaggio Pig Latin.
- L'approccio multi-query di Apache Pig riduce i tempi di sviluppo.
- Apache pig ha un ricco set di set di dati per eseguire operazioni come unire, filtrare, ordinare, caricare, raggruppare, ecc.
- La lingua latina del maiale è molto simile a SQL. I programmatori con una buona conoscenza di SQL trovano facile scrivere lo script Pig.
- Consente ai programmatori di scrivere meno righe di codice. I programmatori possono scrivere 200 righe di codice Java in sole dieci righe utilizzando il linguaggio Pig Latin.
- Apache Pig gestisce sia l'analisi dei dati strutturati che non strutturati.
Applicazioni Apache Pig
Alcune delle applicazioni Apache Pig sono:
- Elabora grandi volumi di dati
- Supporta la prototipazione rapida e le query ad hoc su set di dati di grandi dimensioni
- Esegue l'elaborazione dei dati nelle piattaforme di ricerca
- Elabora i carichi di dati sensibili al tempo
- Utilizzato dalle società di telecomunicazioni per anonimizzare le informazioni sui dati delle chiamate dell'utente.
Cos'è Apache Pig?
Map Reduce richiede che i programmi vengano tradotti in mappe e riducano le fasi. Poiché non tutti gli analisti di dati avevano familiarità con Map Reduce, quindi, Apache pig è stato introdotto dai ricercatori di Yahoo per colmare il divario. The Pig è stato costruito su Hadoop che fornisce un alto livello di astrazione e consente ai programmatori di dedicare meno tempo alla scrittura di complessi programmi Map Reduce. Pig non è un acronimo; prende il nome da un animale domestico. Poiché un maiale animale mangia qualsiasi cosa, Pig può lavorare su qualsiasi tipo di dato.

Fonte
Architettura Apache Pig in Hadoop
L'architettura di Apache Pig è costituita da un interprete Pig Latin che utilizza gli script Pig Latin per elaborare e analizzare enormi set di dati. I programmatori utilizzano il linguaggio Pig Latin per analizzare grandi set di dati nell'ambiente Hadoop. Apache pig ha un ricco set di set di dati per eseguire diverse operazioni sui dati come unire, filtrare, ordinare, caricare, raggruppare, ecc.
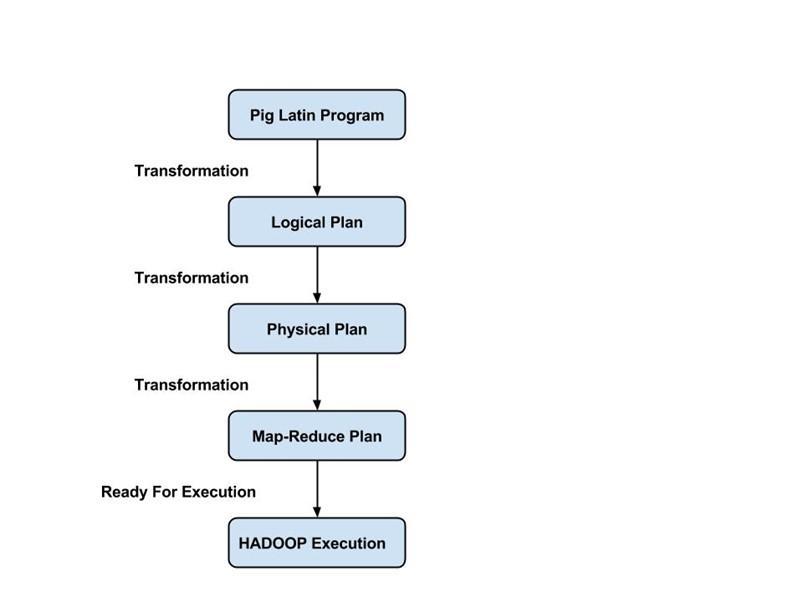
I programmatori devono utilizzare la lingua latina Pig per scrivere uno script Pig per eseguire un'attività specifica. Pig converte questi script Pig in una serie di lavori Map-Reduce per facilitare il lavoro dei programmatori. I programmi Pig Latin vengono eseguiti tramite vari meccanismi come UDF, shell incorporate e Grunt.
L' architettura di Apache Pig è composta dai seguenti componenti principali:
- analizzatore
- Ottimizzatore
- compilatore
- Motore di esecuzione
- Modalità di esecuzione
Studiamo in dettaglio tutti questi componenti Pig.
Script latini di maiale
Gli script Pig vengono inviati all'ambiente di esecuzione Pig per produrre i risultati desiderati.
Puoi eseguire gli script Pig utilizzando uno dei metodi:
- Grunt Shell
- File di script
- Script incorporato
analizzatore
Il parser gestisce tutte le istruzioni o i comandi di Pig Latin. Il parser esegue diversi controlli sulle istruzioni Pig come il controllo della sintassi, il controllo del tipo e genera un output DAG (Directed Acyclic Graph) . L'output del DAG rappresenta tutti gli operatori logici degli script come nodi e il flusso di dati come bordi.
Ottimizzatore
Una volta completata l'operazione di analisi e generato un output DAG, l'output viene passato all'ottimizzatore. L'ottimizzatore esegue quindi le attività di ottimizzazione sull'output, come suddivisione, unione, proiezione, pushdown, trasformazione e riordino, ecc. L'ottimizzatore elabora i dati estratti e omette i dati o le colonne non necessari eseguendo attività di pushdown e proiezione e migliora le prestazioni delle query .

compilatore
Il compilatore compila l'output generato dall'ottimizzatore in una serie di lavori Map Reduce. Il compilatore converte automaticamente i lavori Pig in lavori Map Reduce e ottimizza le prestazioni riorganizzando l'ordine di esecuzione.
Motore di esecuzione
Dopo aver eseguito tutte le operazioni di cui sopra, questi lavori Map Reduce vengono inviati al motore di esecuzione, che viene quindi eseguito sulla piattaforma Hadoop per produrre i risultati desiderati. È quindi possibile utilizzare l'istruzione DUMP per visualizzare i risultati sullo schermo o le istruzioni STORE per archiviare i risultati in HDFS (Hadoop Distributed File System).
Modalità di esecuzione
Apache Pig viene eseguito in due modalità di esecuzione che sono locali e Map Reduce. La scelta della modalità di esecuzione dipende da dove sono archiviati i dati e da dove si desidera eseguire lo script Pig. Puoi archiviare i tuoi dati localmente (in una singola macchina) o in un ambiente cluster Hadoop distribuito.
- Modalità locale : puoi utilizzare la modalità locale se il tuo set di dati è piccolo. In modalità locale, Pig viene eseguito in una singola JVM utilizzando l'host locale e il file system. In questa modalità, l'esecuzione del mapping parallelo è impossibile poiché tutti i file sono installati ed eseguiti su localhost. È possibile utilizzare il comando pig -x local per specificare la modalità locale.
- Modalità di riduzione della mappa : Apache Pig utilizza la modalità di riduzione della mappa per impostazione predefinita. In modalità Map Reduce, un programmatore esegue le istruzioni Pig Latin sui dati che sono già archiviati nell'HDFS (Hadoop Distributed File System) . È possibile utilizzare il comando pig -x mapreduce per specificare la modalità Map-Reduce.
Fonte
Modello di dati latino suino
Il modello di dati Pig Latin consente a Pig di gestire qualsiasi tipo di dati. Il modello di dati Pig Latin è completamente nidificato e può trattare sia tipi di dati atomici come interi, float che complessi non atomici come Map e tuple.
Cerchiamo di comprendere il modello di dati in modo approfondito:
- Atom – Un atomo è un singolo valore memorizzato in una forma di stringa e può essere utilizzato come numero e stringa. I valori atomici di Pig sono interi, double, float, array di byte e array di caratteri. Un singolo valore atomico è anche chiamato campo.
Ad esempio, "Kiara" o 27
- Tupla: una tupla è un record che contiene un insieme ordinato di campi (qualsiasi tipo). Una tupla è molto simile a una riga in un RDBMS (Relational Database Management System) .
Ad esempio, (Kiara, 27)
- Borsa: un atomo è un singolo valore memorizzato in una forma di stringa e può essere utilizzato come numero e stringa. I valori atomici di Pig sono interi, double, float, array di byte e array di caratteri. Un singolo valore atomico è anche chiamato campo.
Ad esempio, {(Kiara, 27), (Kehsav, 45)}
- Mappa: un insieme di coppie chiave-valore è noto come mappa. La chiave deve essere univoca e deve essere di tipo char array. Tuttavia, il valore può essere di qualsiasi tipo.
Ad esempio, [nome#Kiara, età#27]
- Relazione – Un sacco di tuple è chiamato relazione.
Flusso di esecuzione di un lavoro di maiale
I seguenti passaggi spiegano il flusso di esecuzione di un processo Pig:
- Lo sviluppatore scrive uno script Pig utilizzando la lingua latina Pig e lo memorizza nel file system locale.
- Dopo aver inviato gli script Pig, Apache Pig stabilisce una connessione con il compilatore e genera una serie di Map Reduce Jobs come output.
- Il compilatore Pig riceve dati grezzi da HDFS per eseguire operazioni e archivia i risultati in HDFS al termine dei lavori Map Reduce.
Leggi anche: Tutorial Apache Pig
Conclusione
In questo blog, abbiamo appreso dell'architettura Apache Pig , dei componenti Pig, della differenza tra Map Reduce e Apache Pig, del modello di dati Pig Latin e del flusso di esecuzione di un lavoro Pig.
Apache Pig è un vantaggio per i programmatori in quanto fornisce una piattaforma con un'interfaccia semplice, riduce la complessità del codice e li aiuta a ottenere risultati in modo efficiente. Yahoo, eBay, LinkedIn e Twitter sono alcune delle aziende che utilizzano Pig per elaborare i loro grandi volumi di dati.
Se sei curioso di conoscere Apache Pig, la scienza dei dati, dai un'occhiata all'Executive PG Program in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con l'industria esperti, 1 contro 1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Quali sono le caratteristiche di Apache Pig?
Apache Pig è uno strumento o una piattaforma di altissimo livello utilizzato per l'elaborazione di grandi set di dati. I codici di analisi dei dati sono sviluppati con l'uso di un linguaggio di scripting di alto livello chiamato Pig Latin. In primo luogo, i programmatori scriveranno script Pig Latin per elaborare i dati in una mappa specifica e ridurre le attività. Apache Pig ha molte funzionalità che lo rendono uno strumento molto utile.
1. Fornisce un ricco set di operatori per eseguire diverse operazioni, come ordinamento, join, filtro, ecc.
2. Apache Pig è considerato un vantaggio per i programmatori SQL poiché è facile da imparare, leggere e scrivere.
3. Creare funzioni e processi definiti dall'utente è facile
4. Sono necessarie meno righe di codice per qualsiasi processo o funzione
5. Consente agli utenti di eseguire analisi di dati sia non strutturati che strutturati
6. Le operazioni di unione e divisione sono piuttosto facili da eseguire
Quali sono le modalità di esecuzione disponibili in Apache Pig?
Apache Pig può essere eseguito in due diverse modalità:
1. Modalità locale: tutti i file verranno installati ed eseguiti dal file system locale e dall'host locale in questa modalità. Di solito, questa modalità viene utilizzata a scopo di test. Qui non avrai bisogno di HDFS o Hadoop.
2. Modalità MapReduce - Nella modalità MapReduce, Apache Pig viene utilizzato per caricare ed elaborare i dati già esistenti nell'Hadoop File System (HDFS). Un processo MapReduce verrà invocato nel back-end ogni volta che tentiamo di eseguire un'istruzione Pig Latin per l'elaborazione dei dati. Eseguirà una particolare operazione sui dati già esistenti nell'HDFS.
Quali sono alcune delle applicazioni chiave di Apache Pig?
Apache Pig si è rivelato essere un vantaggio per tutti quei programmatori che non erano in grado di comprendere a fondo la programmazione Java. La cosa migliore di Apache Pig è che offre flessibilità, richiede meno sforzo rispetto ad altre piattaforme e riduce la complessità del codice.
Alcune delle applicazioni chiave di Apache Pig sono:
1. Elaborazione di un grande volume di dati dai set di dati
2. Utile in ogni luogo in cui sono richiesti approfondimenti analitici con l'uso del campionamento
3. Per la raccolta di una grande quantità di set di dati sotto forma di web crawl e log di ricerca
4. Necessario per la prototipazione degli algoritmi di elaborazione di grandi insiemi di dati