
Apache Pig-Architektur in Hadoop: Funktionen, Anwendungen, Ausführungsablauf
Veröffentlicht: 2020-06-26Inhaltsverzeichnis
Warum Apache Pig so beliebt ist
Zur Analyse und Verarbeitung von Big Data verwendet Hadoop Map Reduce. Map Reduce ist ein in Java geschriebenes Programm. Entwickler finden es jedoch schwierig, diese langen Java-Codes zu schreiben und zu pflegen. Mit Apache Pig können Entwickler große Datenmengen schnell analysieren und verarbeiten, ohne komplexe Java-Codes zu verwenden. Apache Pig, das von Yahoo-Forschern entwickelt wurde, führt Map Reduce-Jobs auf umfangreichen Datensätzen aus und bietet eine einfache Schnittstelle für Entwickler, um die Daten effizient zu verarbeiten.
Apache Pig hat sich als Segen für diejenigen herausgestellt, die die Java-Programmierung nicht verstehen. Heute ist Apache Pig bei Entwicklern sehr beliebt, da es Flexibilität bietet, die Codekomplexität reduziert und weniger Aufwand erfordert. Wenn Sie Anfänger sind und mehr über Data Science erfahren möchten, sehen Sie sich unsere Data Science-Kurse von Top-Universitäten an.
Map Reduce vs. Apache Pig
Die folgende Tabelle fasst den Unterschied zwischen Map Reduce und Apache Pig zusammen:
| Apache-Schwein | Karte verkleinern |
| Skriptsprache | Kompilierte Sprache |
| Bietet eine höhere Abstraktionsebene | Bietet eine niedrige Abstraktionsebene |
| Erfordert ein paar Codezeilen (10 Codezeilen können 200 Zeilen Map Reduce-Code zusammenfassen) | Erfordert einen umfangreicheren Code (mehr Codezeilen) |
| Erfordert weniger Entwicklungszeit und -aufwand | Erfordert mehr Entwicklungszeit und Aufwand |
| Geringere Codeeffizienz | Höhere Effizienz des Codes im Vergleich zu Apache Pig |
Apache Pig-Funktionen
Apache Pig bietet die folgenden Funktionen:
- Ermöglicht Programmierern, weniger Codezeilen zu schreiben. Programmierer können mit der Sprache Pig Latin 200 Zeilen Java-Code in nur zehn Zeilen schreiben.
- Der Multi-Query-Ansatz von Apache Pig reduziert die Entwicklungszeit.
- Apache Pig verfügt über eine Vielzahl von Datensätzen zum Ausführen von Operationen wie Verbinden, Filtern, Sortieren, Laden, Gruppieren usw.
- Pig Latin ist sehr ähnlich zu SQL. Programmierern mit guten SQL-Kenntnissen fällt es leicht, Pig-Skripte zu schreiben.
- Ermöglicht Programmierern, weniger Codezeilen zu schreiben. Programmierer können mit der Sprache Pig Latin 200 Zeilen Java-Code in nur zehn Zeilen schreiben.
- Apache Pig verarbeitet sowohl strukturierte als auch unstrukturierte Datenanalysen.
Apache Pig-Anwendungen
Einige der Apache Pig-Anwendungen sind:
- Verarbeitet große Datenmengen
- Unterstützt schnelles Prototyping und Ad-hoc-Abfragen über große Datensätze hinweg
- Führt Datenverarbeitung in Suchplattformen durch
- Verarbeitet zeitkritische Datenlasten
- Wird von Telekommunikationsunternehmen verwendet, um die Anrufdateninformationen des Benutzers zu de-identifizieren.
Was ist Apache Pig?
Map Reduce erfordert, dass Programme in Map- und Reduce-Stufen übersetzt werden. Da nicht alle Datenanalysten mit Map Reduce vertraut waren, wurde Apache Pig von Yahoo-Forschern eingeführt, um die Lücke zu schließen. The Pig wurde auf Hadoop aufgebaut, das ein hohes Maß an Abstraktion bietet und es Programmierern ermöglicht, weniger Zeit mit dem Schreiben komplexer Map Reduce-Programme zu verbringen. Schwein ist kein Akronym; es wurde nach einem Haustier benannt. Da ein Schwein alles frisst, kann Pig mit jeder Art von Daten arbeiten.

Quelle
Apache Pig-Architektur in Hadoop
Die Apache Pig-Architektur besteht aus einem Pig Latin-Interpreter, der Pig Latin-Skripte verwendet, um riesige Datenmengen zu verarbeiten und zu analysieren. Programmierer verwenden die Sprache Pig Latin, um große Datensätze in der Hadoop-Umgebung zu analysieren. Apache Pig verfügt über eine Vielzahl von Datensätzen zum Ausführen verschiedener Datenoperationen wie Verbinden, Filtern, Sortieren, Laden, Gruppieren usw.
Programmierer müssen die Pig Latin-Sprache verwenden, um ein Pig-Skript zu schreiben, um eine bestimmte Aufgabe auszuführen. Pig wandelt diese Pig-Skripte in eine Reihe von Map-Reduce-Jobs um, um Programmierern die Arbeit zu erleichtern. Pig Latin-Programme werden über verschiedene Mechanismen wie UDFs, eingebettete und Grunt-Shells ausgeführt.
Die Apache Pig-Architektur besteht aus den folgenden Hauptkomponenten:
- Parser
- Optimierer
- Compiler
- Ausführungs-Engine
- Ausführungsmodus
Lassen Sie uns alle diese Pig-Komponenten im Detail untersuchen.
Lateinische Schweineschriften
Pig-Skripte werden an die Pig-Ausführungsumgebung übermittelt, um die gewünschten Ergebnisse zu erzielen.
Sie können die Pig-Skripte mit einer der folgenden Methoden ausführen:
- Grunz Shell
- Skriptdatei
- Eingebettetes Skript
Parser
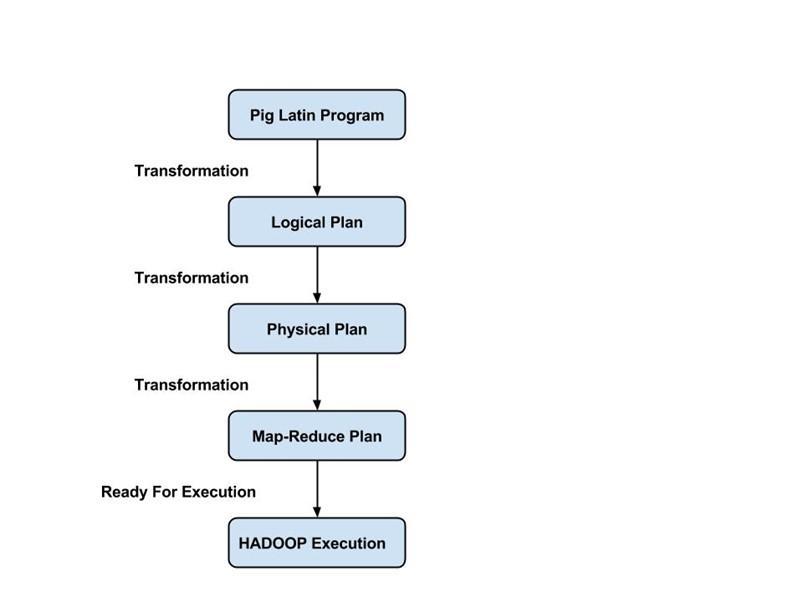
Parser verarbeitet alle Pig Latin-Anweisungen oder -Befehle. Der Parser führt mehrere Überprüfungen der Pig-Anweisungen durch, z. B. Syntaxprüfung, Typprüfung, und generiert eine DAG-Ausgabe (Directed Acyclic Graph) . Die DAG-Ausgabe stellt alle logischen Operatoren der Skripte als Knoten und den Datenfluss als Kanten dar.
Optimierer
Sobald der Parsing-Vorgang abgeschlossen ist und eine DAG-Ausgabe generiert wird, wird die Ausgabe an den Optimierer übergeben. Der Optimierer führt dann die Optimierungsaktivitäten für die Ausgabe durch, wie z. B. Aufteilen, Zusammenführen, Projektion, Pushdown, Transformation und Neuordnung usw. Der Optimierer verarbeitet die extrahierten Daten und lässt unnötige Daten oder Spalten aus, indem er Pushdown- und Projektionsaktivitäten durchführt und die Abfrageleistung verbessert .
Compiler
Der Compiler kompiliert die vom Optimierer generierte Ausgabe in eine Reihe von Map-Reduce-Jobs. Der Compiler wandelt Pig-Jobs automatisch in Map-Reduce-Jobs um und optimiert die Leistung, indem er die Ausführungsreihenfolge neu anordnet.

Ausführungs-Engine
Nach Durchführung aller oben genannten Operationen werden diese Map-Reduce-Jobs an die Ausführungs-Engine übermittelt, die dann auf der Hadoop-Plattform ausgeführt wird, um die gewünschten Ergebnisse zu erzielen. Sie können dann die DUMP-Anweisung verwenden, um die Ergebnisse auf dem Bildschirm anzuzeigen, oder STORE-Anweisungen verwenden, um die Ergebnisse in HDFS (Hadoop Distributed File System) zu speichern.
Ausführungsmodus
Apache Pig wird in zwei Ausführungsmodi ausgeführt, nämlich lokal und Map Reduce. Die Wahl des Ausführungsmodus hängt davon ab, wo die Daten gespeichert sind und wo Sie das Pig-Skript ausführen möchten. Sie können Ihre Daten entweder lokal (auf einem einzelnen Computer) oder in einer verteilten Hadoop-Clusterumgebung speichern.
- Lokaler Modus – Sie können den lokalen Modus verwenden, wenn Ihr Datensatz klein ist. Im lokalen Modus wird Pig in einer einzigen JVM ausgeführt, die den lokalen Host und das Dateisystem verwendet. In diesem Modus ist eine parallele Mapper-Ausführung nicht möglich, da alle Dateien auf dem lokalen Host installiert und ausgeführt werden. Sie können den lokalen Befehl pig -x verwenden , um den lokalen Modus anzugeben.
- Kartenreduktionsmodus – Apache Pig verwendet standardmäßig den Kartenreduktionsmodus. Im Map Reduce-Modus führt ein Programmierer die Pig Latin-Anweisungen auf Daten aus, die bereits im HDFS (Hadoop Distributed File System) gespeichert sind. Sie können den Befehl pig -x mapreduce verwenden , um den Map-Reduce-Modus anzugeben.
Quelle
Lateinisches Datenmodell für Schweine
Pig Latin-Datenmodell ermöglicht es Pig, jede Art von Daten zu verarbeiten. Das Pig Latin-Datenmodell ist vollständig verschachtelt und kann sowohl atomare wie Integer-, Float- als auch nicht-atomare komplexe Datentypen wie Map und Tuple behandeln.
Lassen Sie uns das Datenmodell im Detail verstehen:
- Atom – Ein Atom ist ein einzelner Wert, der in Form einer Zeichenfolge gespeichert ist und als Zahl und Zeichenfolge verwendet werden kann. Atomare Werte von Pig sind Integer, Double, Float, Byte-Array und Char-Array. Ein einzelner atomarer Wert wird auch als Feld bezeichnet.
Zum Beispiel „Kiara“ oder 27
- Tupel – Ein Tupel ist ein Datensatz, der einen geordneten Satz von Feldern (beliebigen Typs) enthält. Ein Tupel ist einer Zeile in einem RDBMS (Relational Database Management System) sehr ähnlich.
Zum Beispiel (Kiara, 27)
- Bag – Ein Atom ist ein einzelner Wert, der in Form einer Zeichenfolge gespeichert ist und als Zahl und Zeichenfolge verwendet werden kann. Atomare Werte von Pig sind Integer, Double, Float, Byte-Array und Char-Array. Ein einzelner atomarer Wert wird auch als Feld bezeichnet.
Zum Beispiel {(Kiara, 27), (Kehsav, 45)}
- Karte – Ein Satz von Schlüssel-Wert-Paaren wird als Karte bezeichnet. Der Schlüssel muss eindeutig sein und sollte vom Typ Char-Array sein. Der Wert kann jedoch beliebig sein.
Beispiel: [Name#Kiara, Alter#27]
- Relation – Eine Menge Tupel wird als Relation bezeichnet.
Ausführungsablauf eines Pig-Jobs
Die folgenden Schritte erläutern den Ausführungsablauf eines Pig-Jobs:
- Der Entwickler schreibt ein Pig-Skript in der Sprache Pig Latin und speichert es im lokalen Dateisystem.
- Nach dem Senden der Pig-Skripte stellt Apache Pig eine Verbindung mit dem Compiler her und generiert als Ausgabe eine Reihe von Map-Reduce-Jobs.
- Der Pig-Compiler empfängt Rohdaten von HDFS-Durchführungsoperationen und speichert die Ergebnisse in HDFS, nachdem Map Reduce-Jobs abgeschlossen sind.
Lesen Sie auch: Apache Pig Tutorial
Fazit
In diesem Blog haben wir die Apache Pig-Architektur , Pig-Komponenten, den Unterschied zwischen Map Reduce und Apache Pig, das Pig Latin-Datenmodell und den Ausführungsablauf eines Pig-Jobs kennengelernt.
Apache Pig ist ein Segen für Programmierer, da es eine Plattform mit einer einfachen Schnittstelle bietet, die Codekomplexität reduziert und ihnen hilft, effizient Ergebnisse zu erzielen. Yahoo, eBay, LinkedIn und Twitter sind einige der Unternehmen, die Pig verwenden, um ihre großen Datenmengen zu verarbeiten.
Wenn Sie mehr über Apache Pig und Data Science erfahren möchten, besuchen Sie das Executive PG Program in Data Science von IIIT-B & upGrad, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops und Mentoring in der Industrie bietet Experten, 1-on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was sind die Funktionen von Apache Pig?
Apache Pig ist ein sehr hochwertiges Tool oder eine Plattform, die für die Verarbeitung großer Datensätze verwendet wird. Die Datenanalysecodes werden unter Verwendung einer höheren Skriptsprache namens Pig Latin entwickelt. Zunächst werden die Programmierer Pig Latin-Skripte schreiben, um die Daten in einer bestimmten Karte zu verarbeiten und die Aufgaben zu reduzieren. Apache Pig hat viele Funktionen, die es zu einem sehr nützlichen Werkzeug machen.
1. Es bietet eine Vielzahl von Operatoren, um verschiedene Operationen durchzuführen, wie z. B. Sortieren, Verbinden, Filtern usw.
2. Apache Pig gilt als Segen für SQL-Programmierer, da es leicht zu erlernen, zu lesen und zu schreiben ist.
3. Das Erstellen benutzerdefinierter Funktionen und Prozesse ist einfach
4. Für jeden Prozess oder jede Funktion sind weniger Codezeilen erforderlich
5. Ermöglicht den Benutzern die Analyse sowohl unstrukturierter als auch strukturierter Daten
6. Join- und Split-Operationen sind ziemlich einfach durchzuführen
Was sind die verfügbaren Ausführungsmodi in Apache Pig?
Apache Pig kann in zwei verschiedenen Modi ausgeführt werden:
1. Lokaler Modus – In diesem Modus werden alle Dateien von Ihrem lokalen Dateisystem und lokalen Host installiert und ausgeführt. Normalerweise wird dieser Modus zu Testzwecken verwendet. Hier benötigen Sie weder HDFS noch Hadoop.
2. MapReduce-Modus – Im MapReduce-Modus wird Apache Pig zum Laden und Verarbeiten der bereits im Hadoop-Dateisystem (HDFS) vorhandenen Daten verwendet. Ein MapReduce-Job wird im Backend immer dann aufgerufen, wenn wir versuchen, eine Pig Latin-Anweisung zur Verarbeitung der Daten auszuführen. Es führt eine bestimmte Operation mit den bereits vorhandenen Daten im HDFS durch.
Was sind einige der wichtigsten Anwendungen von Apache Pig?
Apache Pig erwies sich als Segen für all jene Programmierer, die nicht in der Lage waren, die Java-Programmierung professionell zu verstehen. Das Beste an Apache Pig ist, dass es Flexibilität bietet, weniger Aufwand erfordert als andere Plattformen und die Komplexität des Codes reduziert.
Einige der wichtigsten Anwendungen von Apache Pig sind:
1. Verarbeitung einer großen Datenmenge aus den Datensätzen
2. Nützlich überall dort, wo analytische Erkenntnisse mittels Probenahme benötigt werden
3. Für die Sammlung einer großen Menge an Datensätzen in Form von Web-Crawls und Suchprotokollen
4. Erforderlich für das Prototyping der Verarbeitungsalgorithmen großer Datensätze