
Arsitektur Apache Pig di Hadoop: Fitur, Aplikasi, Alur Eksekusi
Diterbitkan: 2020-06-26Daftar isi
Mengapa Apache Pig begitu Populer
Untuk menganalisis dan memproses data besar, Hadoop menggunakan Map Reduce. Map Reduce adalah program yang ditulis dalam Java. Namun, pengembang merasa kesulitan untuk menulis dan memelihara kode Java yang panjang ini. Dengan Apache Pig, pengembang dapat dengan cepat menganalisis dan memproses kumpulan data besar tanpa menggunakan kode Java yang rumit. Apache Pig yang dikembangkan oleh peneliti Yahoo menjalankan pekerjaan Map Reduce pada kumpulan data yang ekstensif dan menyediakan antarmuka yang mudah bagi pengembang untuk memproses data secara efisien.
Apache Pig muncul sebagai anugerah bagi mereka yang tidak mengerti pemrograman Java. Saat ini, Apache Pig telah menjadi sangat populer di kalangan pengembang karena menawarkan fleksibilitas, mengurangi kerumitan kode, dan membutuhkan lebih sedikit usaha. Jika Anda seorang pemula dan tertarik untuk mempelajari lebih lanjut tentang ilmu data, lihat kursus ilmu data kami dari universitas terkemuka.
Pengurangan Peta vs. Babi Apache
Tabel berikut merangkum perbedaan antara Map Reduce dan Apache Pig:
| Babi Apache | Pengurangan Peta |
| Bahasa skrip | Bahasa yang dikompilasi |
| Memberikan tingkat abstraksi yang lebih tinggi | Memberikan tingkat abstraksi yang rendah |
| Memerlukan beberapa baris kode (10 baris kode dapat meringkas 200 baris kode Pengurangan Peta) | Memerlukan kode yang lebih ekstensif (lebih banyak baris kode) |
| Membutuhkan lebih sedikit waktu dan usaha pengembangan | Membutuhkan lebih banyak waktu dan usaha pengembangan |
| Efisiensi kode yang lebih rendah | Efisiensi kode yang lebih tinggi dibandingkan dengan Apache Pig |
Fitur Babi Apache
Apache Pig menawarkan fitur-fitur berikut:
- Memungkinkan pemrogram untuk menulis lebih sedikit baris kode. Programmer dapat menulis 200 baris kode Java hanya dalam sepuluh baris menggunakan bahasa Pig Latin.
- Pendekatan multi-kueri Apache Pig mengurangi waktu pengembangan.
- Apache pig memiliki kumpulan dataset yang kaya untuk melakukan operasi seperti bergabung, memfilter, mengurutkan, memuat, mengelompokkan, dll.
- Babi bahasa Latin sangat mirip dengan SQL. Pemrogram dengan pengetahuan SQL yang baik merasa mudah untuk menulis skrip Babi.
- Memungkinkan pemrogram untuk menulis lebih sedikit baris kode. Programmer dapat menulis 200 baris kode Java hanya dalam sepuluh baris menggunakan bahasa Pig Latin.
- Apache Pig menangani analisis data terstruktur dan tidak terstruktur.
Aplikasi Babi Apache
Beberapa aplikasi Apache Pig adalah:
- Memproses data dalam jumlah besar
- Mendukung pembuatan prototipe cepat dan kueri ad-hoc di seluruh kumpulan data besar
- Melakukan pemrosesan data di platform pencarian
- Memproses pemuatan data yang sensitif terhadap waktu
- Digunakan oleh perusahaan telekomunikasi untuk mengidentifikasi informasi data panggilan pengguna.
Apa itu Babi Apache?
Map Reduce membutuhkan program untuk diterjemahkan ke dalam peta dan tahap reduksi. Karena tidak semua analis data terbiasa dengan Map Reduce, maka, Apache pig diperkenalkan oleh peneliti Yahoo untuk menjembatani kesenjangan tersebut. Babi dibangun di atas Hadoop yang menyediakan abstraksi tingkat tinggi dan memungkinkan pemrogram menghabiskan lebih sedikit waktu untuk menulis program Pengurangan Peta yang kompleks. Babi bukanlah akronim; itu dinamai hewan domestik. Seperti hewan babi yang memakan apa saja, Babi dapat mengerjakan semua jenis data.

Sumber
Arsitektur Babi Apache di Hadoop
Arsitektur Apache Pig terdiri dari penerjemah Pig Latin yang menggunakan skrip Pig Latin untuk memproses dan menganalisis kumpulan data besar. Pemrogram menggunakan bahasa Pig Latin untuk menganalisis kumpulan data besar di lingkungan Hadoop. Apache pig memiliki kumpulan dataset yang kaya untuk melakukan operasi data yang berbeda seperti bergabung, memfilter, mengurutkan, memuat, mengelompokkan, dll.
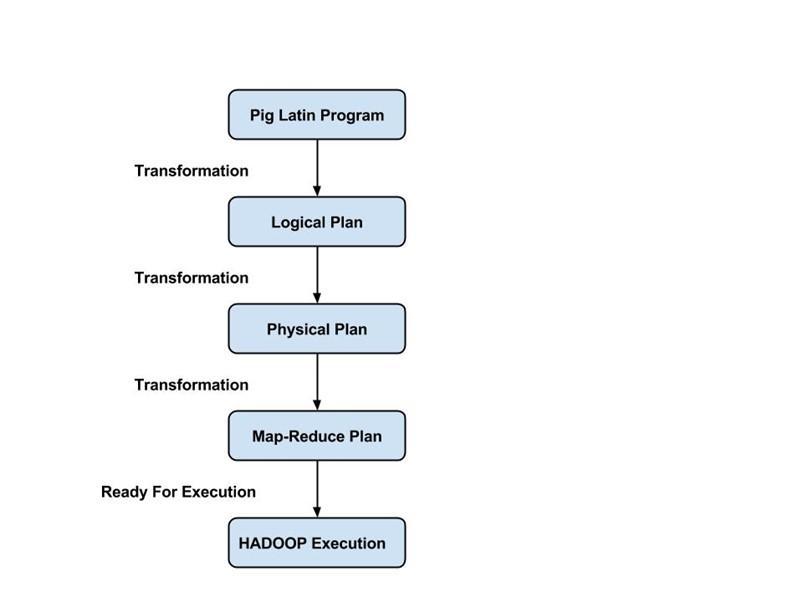
Programmer harus menggunakan bahasa Pig Latin untuk menulis skrip Pig untuk melakukan tugas tertentu. Pig mengubah skrip Babi ini menjadi serangkaian pekerjaan Pengurangan Peta untuk memudahkan pekerjaan programmer. Program Pig Latin dijalankan melalui berbagai mekanisme seperti UDF, embedded, dan shell Grunt.
Arsitektur Apache Pig terdiri dari komponen utama berikut:
- Pengurai
- Pengoptimal
- Penyusun
- Mesin Eksekusi
- Mode Eksekusi
Mari kita pelajari semua komponen Babi ini secara mendetail.
Aksara Latin Babi
Skrip babi dikirimkan ke lingkungan eksekusi Babi untuk menghasilkan hasil yang diinginkan.
Anda dapat menjalankan skrip Babi dengan menggunakan salah satu metode:
- Cangkang kasar
- File skrip
- Skrip yang disematkan
Pengurai
Parser menangani semua pernyataan atau perintah Pig Latin. Parser melakukan beberapa pemeriksaan pada pernyataan Pig seperti pemeriksaan sintaks, pemeriksaan jenis, dan menghasilkan output DAG (Directed Acyclic Graph) . Output DAG mewakili semua operator logis dari skrip sebagai node dan aliran data sebagai edge.
Pengoptimal
Setelah operasi parsing selesai dan output DAG dihasilkan, output diteruskan ke pengoptimal. Pengoptimal kemudian melakukan aktivitas pengoptimalan pada output, seperti pemisahan, penggabungan, proyeksi, pushdown, transformasi, dan penyusunan ulang, dll. Pengoptimal memproses data yang diekstraksi dan menghilangkan data atau kolom yang tidak perlu dengan melakukan aktivitas pushdown dan proyeksi serta meningkatkan kinerja kueri .

Penyusun
Kompilator mengkompilasi output yang dihasilkan oleh pengoptimal ke dalam serangkaian pekerjaan Pengurangan Peta. Kompilator secara otomatis mengubah pekerjaan Pig menjadi pekerjaan Pengurangan Peta dan mengoptimalkan kinerja dengan mengatur ulang urutan eksekusi.
Mesin Eksekusi
Setelah melakukan semua operasi di atas, pekerjaan Pengurangan Peta ini dikirimkan ke mesin eksekusi, yang kemudian dijalankan pada platform Hadoop untuk menghasilkan hasil yang diinginkan. Anda kemudian dapat menggunakan pernyataan DUMP untuk menampilkan hasil di layar atau pernyataan STORE untuk menyimpan hasil dalam HDFS (Hadoop Distributed File System).
Mode Eksekusi
Apache Pig dijalankan dalam dua mode eksekusi yaitu local dan Map Reduce. Pilihan mode eksekusi tergantung di mana data disimpan dan di mana Anda ingin menjalankan skrip Pig. Anda dapat menyimpan data Anda secara lokal (dalam satu mesin) atau di lingkungan cluster Hadoop terdistribusi.
- Mode Lokal – Anda dapat menggunakan mode lokal jika kumpulan data Anda kecil. Dalam mode lokal, Pig berjalan dalam satu JVM menggunakan host lokal dan sistem file. Dalam mode ini, eksekusi mapper paralel tidak mungkin dilakukan karena semua file diinstal dan dijalankan di localhost. Anda dapat menggunakan perintah lokal pig -x untuk menentukan mode lokal.
- Mode Pengurangan Peta – Apache Pig menggunakan mode Pengurangan Peta secara default. Dalam mode Pengurangan Peta, seorang programmer mengeksekusi pernyataan Pig Latin pada data yang sudah disimpan dalam HDFS (Hadoop Distributed File System) . Anda dapat menggunakan perintah pig -x mapreduce untuk menentukan mode Map-Reduce.
Sumber
Model Data Babi Latin
Model data Pig Latin memungkinkan Pig untuk menangani segala jenis data. Model data Pig Latin sepenuhnya bersarang dan dapat memperlakukan tipe data atom seperti integer, float, dan kompleks non-atomik seperti Peta dan Tuple.
Mari kita memahami model data secara mendalam:
- Atom – Atom adalah nilai tunggal yang disimpan dalam bentuk string dan dapat digunakan sebagai angka dan string. Nilai atom Pig adalah integer, double, float, byte array, dan char array. Nilai atom tunggal juga disebut bidang.
Misalnya, "Kiara" atau 27
- Tuple – Tuple adalah record yang berisi kumpulan field yang diurutkan (jenis apapun). Tuple sangat mirip dengan baris dalam RDBMS (Relational Database Management System) .
Misalnya, (Kiara, 27)
- Tas – Atom adalah nilai tunggal yang disimpan dalam bentuk string dan dapat digunakan sebagai angka dan string. Nilai atom Pig adalah integer, double, float, byte array, dan char array. Nilai atom tunggal juga disebut bidang.
Misalnya, {(Kiara, 27), (Kehsav, 45)}
- Peta – Kumpulan pasangan nilai kunci dikenal sebagai peta. Kuncinya harus unik dan harus bertipe array char. Namun, nilainya bisa berupa apa saja.
Misalnya, [nama#Kiara, umur#27]
- Relasi – Sekantong tupel disebut relasi.
Alur Eksekusi Pekerjaan Babi
Langkah-langkah berikut menjelaskan alur eksekusi pekerjaan Pig:
- Pengembang menulis skrip Pig menggunakan bahasa Pig Latin dan menyimpannya di sistem file lokal.
- Setelah mengirimkan skrip Pig, Apache Pig membuat koneksi dengan kompiler dan menghasilkan serangkaian Pekerjaan Pengurangan Peta sebagai output.
- Pig compiler menerima data mentah dari HDFS melakukan operasi dan menyimpan hasilnya ke dalam HDFS setelah pekerjaan Map Reduce selesai.
Baca Juga: Tutorial Babi Apache
Kesimpulan
Di blog ini, kita telah belajar tentang Arsitektur Apache Pig , komponen Pig, perbedaan antara Map Reduce dan Apache Pig, model data Pig Latin, dan alur eksekusi pekerjaan Pig.
Apache Pig adalah anugerah bagi programmer karena menyediakan platform dengan antarmuka yang mudah, mengurangi kerumitan kode, dan membantu mereka mencapai hasil secara efisien. Yahoo, eBay, LinkedIn, dan Twitter adalah beberapa perusahaan yang menggunakan Pig untuk memproses volume data mereka yang besar.
Jika Anda ingin tahu tentang Apache Pig, ilmu data, lihat Program PG Eksekutif IIIT-B & upGrad dalam Ilmu Data yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan industri pakar, tatap muka dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa saja fitur dari Apache Pig?
Apache Pig adalah alat atau platform tingkat tinggi yang digunakan untuk memproses kumpulan data besar. Kode analisis data dikembangkan dengan menggunakan bahasa scripting tingkat tinggi yang disebut Pig Latin. Pertama, programmer akan menulis skrip Pig Latin untuk memproses data menjadi peta tertentu dan mengurangi tugas. Apache Pig memiliki banyak fitur yang menjadikannya alat yang sangat berguna.
1. Ini menyediakan seperangkat operator yang kaya untuk melakukan operasi yang berbeda, seperti mengurutkan, menggabungkan, memfilter, dll.
2. Apache Pig dianggap sebagai keuntungan bagi programmer SQL karena mudah dipelajari, dibaca, dan ditulis.
3. Membuat fungsi dan proses yang ditentukan pengguna itu mudah
4. Lebih sedikit baris kode diperlukan untuk proses atau fungsi apa pun
5. Memungkinkan pengguna untuk melakukan analisis data tidak terstruktur dan terstruktur
6. Operasi Gabung dan Pisahkan cukup mudah dilakukan
Apa saja mode eksekusi yang tersedia di Apache Pig?
Apache Pig dapat dieksekusi dalam dua mode berbeda:
1. Mode Lokal - Semua file akan diinstal dan dijalankan dari sistem file lokal dan host lokal Anda dalam mode ini. Biasanya, mode ini digunakan untuk tujuan pengujian. Di sini, Anda tidak perlu HDFS atau Hadoop.
2. Mode MapReduce - Pada mode MapReduce, Apache Pig digunakan untuk memuat dan memproses data yang sudah ada di Hadoop File System (HDFS). Pekerjaan MapReduce akan dipanggil di back-end setiap kali kami mencoba mengeksekusi pernyataan Pig Latin untuk memproses data. Ini akan melakukan operasi tertentu pada data yang sudah ada di HDFS.
Apa saja aplikasi utama Apache Pig?
Apache Pig ternyata menjadi keuntungan bagi semua programmer yang tidak bisa memahami pemrograman Java dengan mahir. Hal terbaik tentang Apache Pig adalah ia menawarkan fleksibilitas, membutuhkan lebih sedikit usaha daripada platform lain, dan mengurangi kerumitan kode.
Beberapa aplikasi utama Apache Pig adalah:
1. Memproses data dalam jumlah besar dari kumpulan data
2. Berguna di setiap tempat di mana wawasan analitis diperlukan dengan penggunaan pengambilan sampel
3. Untuk pengumpulan sejumlah besar kumpulan data dalam bentuk perayapan web dan log pencarian
4. Diperlukan untuk membuat prototipe algoritma pemrosesan kumpulan data besar