
هندسة Apache Pig في Hadoop: الميزات والتطبيقات وتدفق التنفيذ
نشرت: 2020-06-26جدول المحتويات
لماذا تحظى Apache Pig بشعبية كبيرة
لتحليل ومعالجة البيانات الضخمة ، يستخدم Hadoop Map Reduce. Map Reduce هو برنامج مكتوب بلغة Java. ولكن ، يجد المطورون صعوبة في كتابة رموز Java الطويلة هذه والاحتفاظ بها. باستخدام Apache Pig ، يمكن للمطورين تحليل مجموعات البيانات الكبيرة ومعالجتها بسرعة دون استخدام أكواد Java المعقدة. يقوم Apache Pig الذي طوره باحثو Yahoo بتنفيذ مهام Map Reduce على مجموعات بيانات واسعة النطاق ويوفر واجهة سهلة للمطورين لمعالجة البيانات بكفاءة.
ظهر Apache Pig كنعمة لأولئك الذين لا يفهمون برمجة Java. اليوم ، أصبح Apache Pig مشهورًا جدًا بين المطورين لأنه يوفر المرونة ويقلل من تعقيد التعليمات البرمجية ويتطلب جهدًا أقل. إذا كنت مبتدئًا ومهتمًا بمعرفة المزيد عن علم البيانات ، فراجع دورات علوم البيانات لدينا من أفضل الجامعات.
Map Reduce مقابل Apache Pig
يلخص الجدول التالي الفرق بين Map Reduce و Apache Pig:
| اباتشي خنزير | تقليل الخريطة |
| لغة البرمجة | اللغة المترجمة |
| يوفر مستوى أعلى من التجريد | يوفر مستوى منخفض من التجريد |
| يتطلب بضعة أسطر من التعليمات البرمجية (10 سطور من التعليمات البرمجية يمكن أن تلخص 200 سطر من رمز تقليل الخريطة) | يتطلب رمزًا أكثر شمولاً (المزيد من سطور التعليمات البرمجية) |
| يتطلب وقتًا وجهدًا أقل في التطوير | يتطلب المزيد من الوقت والجهد في التطوير |
| أقل كفاءة رمز | كفاءة أعلى للتعليمات البرمجية بالمقارنة مع Apache Pig |
ميزات خنزير أباتشي
يقدم Apache Pig الميزات التالية:
- يسمح للمبرمجين بكتابة عدد أقل من سطور الرموز. يمكن للمبرمجين كتابة 200 سطر من كود Java في عشرة أسطر فقط باستخدام لغة Pig Latin.
- يعمل نهج استعلامات Apache Pig المتعددة على تقليل وقت التطوير.
- يحتوي Apache pig على مجموعة غنية من مجموعات البيانات لإجراء عمليات مثل الانضمام ، والتصفية ، والفرز ، والتحميل ، والمجموعة ، وما إلى ذلك.
- تشبه لغة Pig Latin إلى حد كبير SQL. يجد المبرمجون ذوو المعرفة الجيدة بـ SQL أنه من السهل كتابة النص الخنزير.
- يسمح للمبرمجين بكتابة عدد أقل من سطور الرموز. يمكن للمبرمجين كتابة 200 سطر من كود Java في عشرة أسطر فقط باستخدام لغة Pig Latin.
- يعالج Apache Pig كلاً من تحليل البيانات المهيكلة وغير المهيكلة.
تطبيقات Apache Pig
بعض تطبيقات Apache Pig هي:
- يعالج حجمًا كبيرًا من البيانات
- يدعم النماذج الأولية السريعة والاستعلامات المخصصة عبر مجموعات البيانات الكبيرة
- يقوم بمعالجة البيانات في منصات البحث
- يعالج أحمال البيانات الحساسة للوقت
- تُستخدم من قبل شركات الاتصالات لإلغاء تحديد معلومات بيانات مكالمات المستخدم.
ما هو خنزير أباتشي؟
يتطلب Map Reduce ترجمة البرامج إلى خريطة وتقليل المراحل. نظرًا لأنه لم يكن جميع محللي البيانات على دراية بـ Map Reduce ، فقد تم تقديم Apache pig بواسطة باحثي Yahoo لسد الفجوة. تم بناء Pig على Hadoop الذي يوفر مستوى عالٍ من التجريد ويمكّن المبرمجين من قضاء وقت أقل في كتابة برامج Map Reduce المعقدة. الخنزير ليس اختصارًا ؛ سمي على اسم حيوان أليف. نظرًا لأن خنزير حيوان يأكل أي شيء ، يمكن للخنزير العمل على أي نوع من البيانات.

مصدر
Apache Pig Architecture في Hadoop
تتكون بنية Apache Pig من مترجم Pig Latin الذي يستخدم نصوص Pig Latin لمعالجة مجموعات البيانات الضخمة وتحليلها. يستخدم المبرمجون لغة Pig Latin لتحليل مجموعات البيانات الكبيرة في بيئة Hadoop. يحتوي Apache pig على مجموعة غنية من مجموعات البيانات لإجراء عمليات بيانات مختلفة مثل الانضمام ، والتصفية ، والفرز ، والتحميل ، والمجموعة ، وما إلى ذلك.
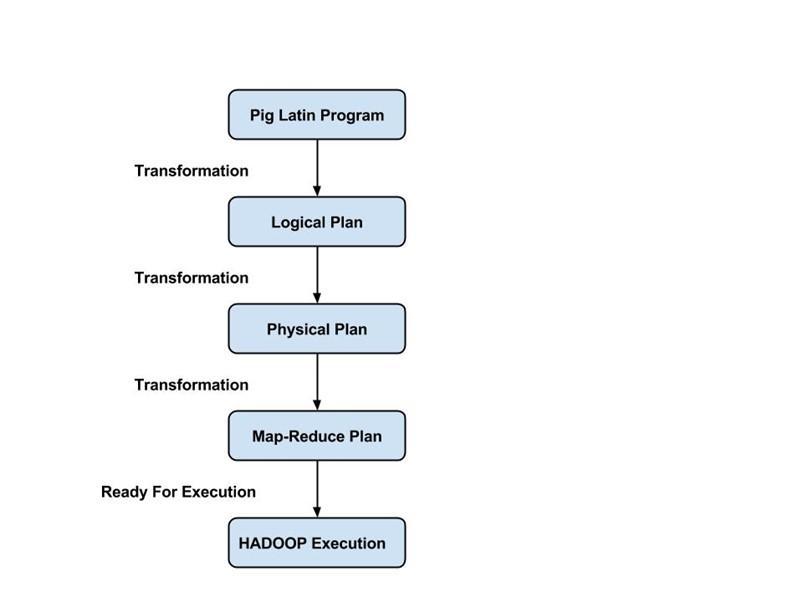
يجب أن يستخدم المبرمجون لغة Pig Latin لكتابة نص Pig لأداء مهمة محددة. يقوم Pig بتحويل نصوص Pig هذه إلى سلسلة من وظائف Map-Reduce لتسهيل عمل المبرمجين. يتم تنفيذ برامج Pig Latin عبر آليات مختلفة مثل UDFs و embedded و Grunt shell.
تتكون بنية Apache Pig من المكونات الرئيسية التالية:
- محلل
- محسن
- مترجم
- محرك التنفيذ
- وضع التنفيذ
دعونا ندرس كل مكونات الخنزير بالتفصيل.
نصوص لاتينية خنزير
يتم إرسال نصوص Pig إلى بيئة تنفيذ Pig للحصول على النتائج المرجوة.
يمكنك تنفيذ البرامج النصية Pig باستخدام إحدى الطرق:
- نخر شل
- ملف البرنامج النصي
- نص مضمن
محلل
يتعامل المحلل اللغوي مع جميع عبارات أو أوامر Pig Latin. يقوم المحلل بإجراء عدة فحوصات على عبارات Pig مثل فحص بناء الجملة وفحص النوع وإنشاء إخراج DAG (رسم بياني لا دوري مباشر) . يمثل إخراج DAG جميع العوامل المنطقية للنصوص كعقد وتدفق البيانات كحواف.

محسن
بمجرد اكتمال عملية التحليل وإنشاء إخراج DAG ، يتم تمرير الإخراج إلى المحسن. ثم يقوم المحسن بتنفيذ أنشطة التحسين على المخرجات ، مثل التقسيم والدمج والإسقاط والضغط والتحويل وإعادة الترتيب وما إلى ذلك. .
مترجم
يقوم المحول البرمجي بترجمة الإخراج الذي تم إنشاؤه بواسطة المُحسِّن في سلسلة من مهام Map Reduce. يقوم المحول البرمجي تلقائيًا بتحويل مهام Pig إلى مهام Map Reduce وتحسين الأداء عن طريق إعادة ترتيب أمر التنفيذ.
محرك التنفيذ
بعد إجراء جميع العمليات المذكورة أعلاه ، يتم إرسال مهام Map Reduce إلى محرك التنفيذ ، والذي يتم تنفيذه بعد ذلك على منصة Hadoop لتحقيق النتائج المرجوة. يمكنك بعد ذلك استخدام عبارة DUMP لعرض النتائج على الشاشة أو عبارات STORE لتخزين النتائج في HDFS (نظام الملفات الموزعة Hadoop).
وضع التنفيذ
يتم تنفيذ Apache Pig في وضعي تنفيذ محليين و Map Reduce. يعتمد اختيار وضع التنفيذ على مكان تخزين البيانات والمكان الذي تريد تشغيل البرنامج النصي Pig. يمكنك إما تخزين بياناتك محليًا (في جهاز واحد) أو في بيئة كتلة Hadoop الموزعة.
- الوضع المحلي - يمكنك استخدام الوضع المحلي إذا كانت مجموعة البيانات الخاصة بك صغيرة. في الوضع المحلي ، يعمل Pig في JVM واحد باستخدام المضيف المحلي ونظام الملفات. في هذا الوضع ، يكون تنفيذ مخطط الموازي مستحيلًا حيث يتم تثبيت جميع الملفات وتشغيلها على المضيف المحلي. يمكنك استخدام الأمر المحلي pig -x لتحديد الوضع المحلي.
- وضع تقليل الخريطة - يستخدم Apache Pig وضع Map Reduce افتراضيًا. في وضع Map Reduce ، ينفذ المبرمج عبارات Pig Latin على البيانات المخزنة بالفعل في HDFS (نظام الملفات الموزعة Hadoop) . يمكنك استخدام الأمر pig -x mapreduce لتحديد وضع Map-Reduce.
مصدر
نموذج البيانات اللاتينية الخنزير
نموذج بيانات Pig Latin يسمح لـ Pig بالتعامل مع أي نوع من البيانات. نموذج بيانات Pig Latin متداخل تمامًا ويمكنه معالجة كل من أنواع البيانات المعقدة مثل الأعداد الصحيحة والعائمة وغير الذرية مثل Map و tuple.
دعونا نفهم نموذج البيانات بعمق:
- الذرة - الذرة هي قيمة مفردة مخزنة في شكل سلسلة ويمكن استخدامها كرقم وسلسلة. القيم الذرية للخنزير هي عدد صحيح ، مزدوج ، عدد عشري ، مصفوفة بايت ، وصفيف شار. تسمى القيمة الذرية المفردة أيضًا حقل.
على سبيل المثال ، "كيارا" أو 27
- المجموعة - المجموعة هي سجل يحتوي على مجموعة مرتبة من الحقول (أي نوع). يشبه tuple إلى حد بعيد صفًا في RDBMS (نظام إدارة قواعد البيانات العلائقية) .
على سبيل المثال (كيارا ، 27)
- الحقيبة - الذرة هي قيمة مفردة مخزنة في شكل سلسلة ويمكن استخدامها كرقم وسلسلة. القيم الذرية للخنزير هي عدد صحيح ، مزدوج ، عدد عشري ، مصفوفة بايت ، وصفيف شار. تسمى القيمة الذرية المفردة أيضًا حقل.
على سبيل المثال ، {(كيارا ، 27) ، (كهساف ، 45)}
- الخريطة - تُعرف مجموعة أزواج القيمة الرئيسية بالخريطة. يجب أن يكون المفتاح فريدًا وأن يكون من نوع مصفوفة char. ومع ذلك ، يمكن أن تكون القيمة من أي نوع.
على سبيل المثال ، [name # Kiara، age # 27]
- العلاقة - كيس من المجموعات يسمى علاقة.
تدفق تنفيذ وظيفة الخنزير
توضح الخطوات التالية تدفق تنفيذ وظيفة Pig:
- يكتب المطور نصًا خنزيرًا باستخدام لغة Pig Latin ويخزنه في نظام الملفات المحلي.
- بعد إرسال نصوص Pig النصية ، ينشئ Apache Pig اتصالاً مع المترجم وينشئ سلسلة من Map Reduce Jobs كإخراج.
- يتلقى برنامج التحويل البرمجي Pig البيانات الأولية من HDFS لإجراء العمليات وتخزين النتائج في HDFS بعد انتهاء مهام Map Reduce.
اقرأ أيضًا: دروس Apache Pig
خاتمة
في هذه المدونة ، تعلمنا عن بنية Apache Pig ، ومكونات Pig ، والفرق بين Map Reduce و Apache Pig ، ونموذج بيانات Pig Latin ، وتدفق تنفيذ وظيفة Pig.
يعد Apache Pig نعمة للمبرمجين لأنه يوفر نظامًا أساسيًا بواجهة سهلة ، ويقلل من تعقيد التعليمات البرمجية ، ويساعدهم في تحقيق النتائج بكفاءة. Yahoo و eBay و LinkedIn و Twitter هي بعض الشركات التي تستخدم Pig لمعالجة كميات كبيرة من البيانات.
إذا كنت مهتمًا بالتعرف على Apache Pig ، وعلوم البيانات ، فراجع برنامج IIIT-B & upGrad's Executive PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع الصناعة خبراء ، وجهاً لوجه مع مرشدين في الصناعة ، وأكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
ما هي ميزات Apache Pig؟
Apache Pig هي أداة أو نظام أساسي عالي المستوى يتم استخدامه لمعالجة مجموعات البيانات الكبيرة. تم تطوير أكواد تحليل البيانات باستخدام لغة برمجة عالية المستوى تسمى Pig Latin. أولاً ، سيقوم المبرمجون بكتابة نصوص Pig Latin لمعالجة البيانات في خريطة محددة وتقليل المهام. يحتوي Apache Pig على الكثير من الميزات التي تجعله أداة مفيدة للغاية.
1. إنه يوفر مجموعة غنية من المشغلين للقيام بعمليات مختلفة ، مثل الفرز ، والصلات ، والتصفية ، إلخ.
2. يعتبر Apache Pig بمثابة نعمة لمبرمجي SQL لأنه من السهل التعلم والقراءة والكتابة.
3. جعل الوظائف والعمليات التي يحددها المستخدم أمرًا سهلاً
4. مطلوب أسطر أقل من التعليمات البرمجية لأي عملية أو وظيفة
5. يسمح للمستخدمين بإجراء تحليل لكل من البيانات غير المهيكلة والمنظمة
6. من السهل جدًا تنفيذ عمليات الانضمام والتقسيم
ما هي أوضاع التنفيذ المتاحة في Apache Pig؟
يمكن تنفيذ Apache Pig في وضعين مختلفين:
1. الوضع المحلي - سيتم تثبيت وتشغيل جميع الملفات من نظام الملفات المحلي والمضيف المحلي في هذا الوضع. عادة ، يتم استخدام هذا الوضع لغرض الاختبار. هنا ، لن تحتاج إلى HDFS أو Hadoop.
2. وضع MapReduce - في وضع MapReduce ، يتم استخدام Apache Pig لتحميل ومعالجة البيانات الموجودة بالفعل في نظام ملفات Hadoop (HDFS). سيتم استدعاء وظيفة MapReduce في النهاية الخلفية عندما نحاول تنفيذ عبارة Pig Latin لمعالجة البيانات. سيقوم بإجراء عملية معينة على البيانات الموجودة بالفعل في HDFS.
ما هي بعض التطبيقات الرئيسية لـ Apache Pig؟
تبين أن Apache Pig كان نعمة لجميع هؤلاء المبرمجين الذين لم يتمكنوا من فهم برمجة Java بكفاءة. أفضل شيء في Apache Pig هو أنه يوفر المرونة ، ويتطلب جهدًا أقل من الأنظمة الأساسية الأخرى ، ويقلل من تعقيد التعليمات البرمجية.
بعض التطبيقات الرئيسية لـ Apache Pig هي:
1. معالجة حجم كبير من البيانات من مجموعات البيانات
2. مفيدة في كل مكان تتطلب رؤى تحليلية مع استخدام أخذ العينات
3. لجمع كمية كبيرة من مجموعات البيانات في شكل زحف الويب وسجلات البحث
4. مطلوب لنمذجة خوارزميات المعالجة لمجموعات البيانات الكبيرة