
Arquitetura Apache Pig no Hadoop: Recursos, Aplicativos, Fluxo de Execução
Publicados: 2020-06-26Índice
Por que o Apache Pig é tão popular
Para analisar e processar big data, o Hadoop usa o Map Reduce. Map Reduce é um programa escrito em Java. Mas, os desenvolvedores acham desafiador escrever e manter esses longos códigos Java. Com o Apache Pig, os desenvolvedores podem analisar e processar rapidamente grandes conjuntos de dados sem usar códigos Java complexos. O Apache Pig desenvolvido por pesquisadores do Yahoo executa tarefas Map Reduce em extensos conjuntos de dados e fornece uma interface fácil para os desenvolvedores processarem os dados com eficiência.
O Apache Pig surgiu como uma benção para aqueles que não entendem de programação Java. Hoje, o Apache Pig se tornou muito popular entre os desenvolvedores, pois oferece flexibilidade, reduz a complexidade do código e requer menos esforço. Se você é iniciante e está interessado em aprender mais sobre ciência de dados, confira nossos cursos de ciência de dados das melhores universidades.
Reduzir mapa vs. Apache Pig
A tabela a seguir resume a diferença entre Map Reduce e Apache Pig:
| Porco Apache | Reduzir mapa |
| Linguagem de script | Linguagem compilada |
| Fornece um nível mais alto de abstração | Fornece um baixo nível de abstração |
| Requer algumas linhas de código (10 linhas de código podem resumir 200 linhas de código Map Reduce) | Requer um código mais extenso (mais linhas de código) |
| Requer menos tempo e esforço de desenvolvimento | Requer mais tempo e esforço de desenvolvimento |
| Menor eficiência de código | Maior eficiência de código em comparação com o Apache Pig |
Recursos do Apache Pig
O Apache Pig oferece os seguintes recursos:
- Permite que os programadores escrevam menos linhas de códigos. Os programadores podem escrever 200 linhas de código Java em apenas dez linhas usando a linguagem Pig Latin.
- A abordagem de várias consultas do Apache Pig reduz o tempo de desenvolvimento.
- O Apache Pig possui um rico conjunto de conjuntos de dados para realizar operações como join, filter, sort, load, group, etc.
- A linguagem Pig Latin é muito semelhante ao SQL. Programadores com bons conhecimentos de SQL acham fácil escrever scripts Pig.
- Permite que os programadores escrevam menos linhas de códigos. Os programadores podem escrever 200 linhas de código Java em apenas dez linhas usando a linguagem Pig Latin.
- O Apache Pig lida com a análise de dados estruturados e não estruturados.
Aplicativos Apache Pig
Alguns dos aplicativos Apache Pig são:
- Processa grande volume de dados
- Suporta prototipagem rápida e consultas ad-hoc em grandes conjuntos de dados
- Realiza o processamento de dados em plataformas de busca
- Processa cargas de dados sensíveis ao tempo
- Usado por empresas de telecomunicações para desidentificar as informações de dados de chamadas do usuário.
O que é Apache Pig?
Map Reduce exige que os programas sejam traduzidos em estágios de mapa e redução. Como nem todos os analistas de dados estavam familiarizados com o Map Reduce, o Apache pig foi introduzido pelos pesquisadores do Yahoo para preencher a lacuna. O Pig foi construído em cima do Hadoop que fornece um alto nível de abstração e permite que os programadores gastem menos tempo escrevendo programas complexos de Map Reduce. Porco não é um acrônimo; foi nomeado após um animal doméstico. Como um porco animal come qualquer coisa, Pig pode trabalhar com qualquer tipo de dado.

Fonte
Arquitetura Apache Pig no Hadoop
A arquitetura do Apache Pig consiste em um interpretador Pig Latin que usa scripts Pig Latin para processar e analisar grandes conjuntos de dados. Os programadores usam a linguagem Pig Latin para analisar grandes conjuntos de dados no ambiente Hadoop. O Apache Pig possui um rico conjunto de conjuntos de dados para realizar diferentes operações de dados, como juntar, filtrar, classificar, carregar, agrupar etc.
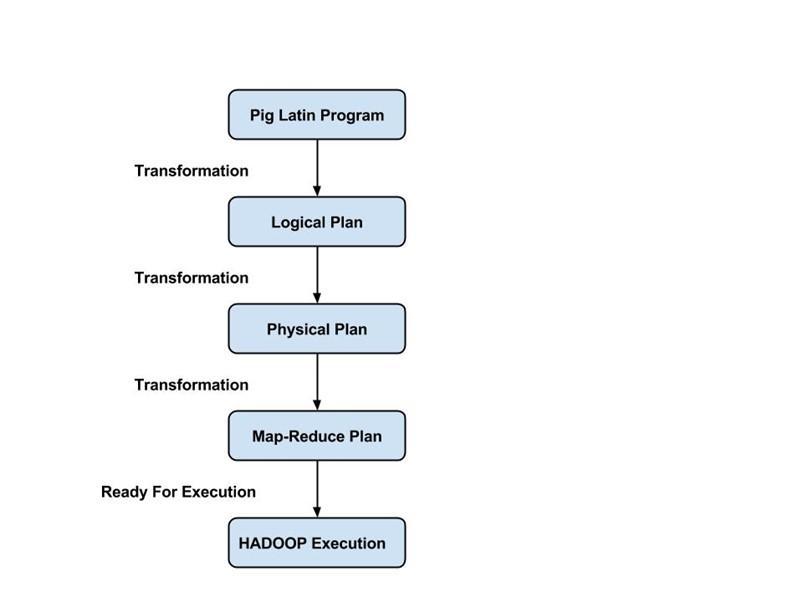
Os programadores devem usar a linguagem Pig Latin para escrever um script Pig para executar uma tarefa específica. O Pig converte esses scripts Pig em uma série de tarefas Map-Reduce para facilitar o trabalho dos programadores. Os programas Pig Latin são executados por meio de vários mecanismos, como UDFs, embutidos e shells Grunt.
A arquitetura do Apache Pig consiste nos seguintes componentes principais:
- Analisador
- Otimizador
- Compilador
- Mecanismo de execução
- Modo de execução
Vamos estudar todos esses componentes do Pig em detalhes.
Scripts latinos de porco
Os scripts do Pig são enviados ao ambiente de execução do Pig para produzir os resultados desejados.
Você pode executar os scripts Pig usando um dos métodos:
- Grunt Shell
- Arquivo de script
- Script incorporado
Analisador
O analisador lida com todas as instruções ou comandos do Pig Latin. O analisador executa várias verificações nas instruções Pig, como verificação de sintaxe, verificação de tipo e gera uma saída DAG (Directed Acyclic Graph) . A saída do DAG representa todos os operadores lógicos dos scripts como nós e o fluxo de dados como bordas.
Otimizador
Depois que a operação de análise é concluída e uma saída DAG é gerada, a saída é passada para o otimizador. O otimizador então executa as atividades de otimização na saída, como divisão, mesclagem, projeção, empilhamento, transformação e reordenação, etc. O otimizador processa os dados extraídos e omite dados ou colunas desnecessários executando atividades de empilhamento e projeção e melhora o desempenho da consulta .

Compilador
O compilador compila a saída gerada pelo otimizador em uma série de tarefas Map Reduce. O compilador converte automaticamente os trabalhos Pig em trabalhos Map Reduce e otimiza o desempenho reorganizando a ordem de execução.
Mecanismo de execução
Depois de realizar todas as operações acima, esses trabalhos Map Reduce são enviados ao mecanismo de execução, que é então executado na plataforma Hadoop para produzir os resultados desejados. Você pode então usar a instrução DUMP para exibir os resultados na tela ou instruções STORE para armazenar os resultados em HDFS (Hadoop Distributed File System).
Modo de execução
O Apache Pig é executado em dois modos de execução que são local e Map Reduce. A escolha do modo de execução depende de onde os dados são armazenados e onde você deseja executar o script Pig. Você pode armazenar seus dados localmente (em uma única máquina) ou em um ambiente de cluster Hadoop distribuído.
- Modo Local – Você pode usar o modo local se seu conjunto de dados for pequeno. No modo local, o Pig é executado em uma única JVM usando o host local e o sistema de arquivos. Nesse modo, a execução paralela do mapeador é impossível, pois todos os arquivos são instalados e executados no host local. Você pode usar o comando pig -x local para especificar o modo local.
- Modo Map Reduce – Apache Pig usa o modo Map Reduce por padrão. No modo Map Reduce, um programador executa as instruções Pig Latin em dados que já estão armazenados no HDFS (Hadoop Distributed File System) . Você pode usar o comando pig -x mapreduce para especificar o modo Map-Reduce.
Fonte
Modelo de Dados Pig Latin
O modelo de dados Pig Latin permite que o Pig lide com qualquer tipo de dados. O modelo de dados Pig Latin é totalmente aninhado e pode tratar tipos de dados atômicos como inteiros, flutuantes e complexos não atômicos, como Mapa e tupla.
Vamos entender o modelo de dados em profundidade:
- Átomo – Um átomo é um valor único armazenado em forma de string e pode ser usado como um número e uma string. Os valores atômicos de Pig são integer, double, float, byte array e char array. Um único valor atômico também é chamado de campo.
Por exemplo, “Kiara” ou 27
- Tupla – Uma tupla é um registro que contém um conjunto ordenado de campos (qualquer tipo). Uma tupla é muito semelhante a uma linha em um RDBMS (Relational Database Management System) .
Por exemplo, (Kiara, 27)
- Bag – Um átomo é um valor único armazenado em forma de string e pode ser usado como um número e uma string. Os valores atômicos de Pig são integer, double, float, byte array e char array. Um único valor atômico também é chamado de campo.
Por exemplo, {(Kiara, 27), (Kehsav, 45)}
- Mapa – Um conjunto de pares chave-valor é conhecido como mapa. A chave deve ser exclusiva e deve ser do tipo char array. No entanto, o valor pode ser de qualquer tipo.
Por exemplo, [nome#Kiara, idade#27]
- Relação – Um saco de tuplas é chamado de relação.
Fluxo de Execução de um Pig Job
As etapas a seguir explicam o fluxo de execução de um job do Pig:
- O desenvolvedor escreve um script Pig usando o idioma Pig Latin e o armazena no sistema de arquivos local.
- Depois de enviar os scripts Pig, o Apache Pig estabelece uma conexão com o compilador e gera uma série de Map Reduce Jobs como saída.
- O compilador Pig recebe dados brutos do HDFS para realizar operações e armazena os resultados no HDFS após a conclusão dos trabalhos Map Reduce.
Leia também: Tutorial Apache Pig
Conclusão
Neste blog, aprendemos sobre a arquitetura Apache Pig , componentes Pig, a diferença entre Map Reduce e Apache Pig, modelo de dados Pig Latin e fluxo de execução de um trabalho Pig.
O Apache Pig é uma benção para os programadores, pois fornece uma plataforma com uma interface fácil, reduz a complexidade do código e os ajuda a obter resultados com eficiência. Yahoo, eBay, LinkedIn e Twitter são algumas das empresas que usam o Pig para processar seus grandes volumes de dados.
Se você está curioso para aprender sobre Apache Pig, ciência de dados, confira o Programa PG Executivo em Ciência de Dados do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com a indústria especialistas, 1-on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Quais são os recursos do Apache Pig?
O Apache Pig é uma ferramenta ou plataforma de alto nível usada para o processamento de grandes conjuntos de dados. Os códigos de análise de dados são desenvolvidos com o uso de uma linguagem de script de alto nível chamada Pig Latin. Em primeiro lugar, os programadores escreverão scripts Pig Latin para processar os dados em um mapa específico e reduzir as tarefas. O Apache Pig tem muitos recursos, o que o torna uma ferramenta muito útil.
1. Ele fornece um rico conjunto de operadores para realizar diferentes operações, como classificar, unir, filtrar, etc.
2. O Apache Pig é considerado uma benção para os programadores SQL, pois é fácil de aprender, ler e escrever.
3. É fácil criar funções e processos definidos pelo usuário
4. Menos linhas de código são necessárias para qualquer processo ou função
5. Permite que os usuários realizem análises de dados não estruturados e estruturados
6. As operações de junção e divisão são muito fáceis de executar
Quais são os modos de execução disponíveis no Apache Pig?
O Apache Pig pode ser executado em dois modos diferentes:
1. Modo Local - Todos os arquivos serão instalados e executados a partir do sistema de arquivos local e do host local neste modo. Normalmente, este modo é utilizado para fins de teste. Aqui, você não precisará de HDFS ou Hadoop.
2. Modo MapReduce - No modo MapReduce, o Apache Pig é usado para carregar e processar os dados que já existem no Hadoop File System (HDFS). Um trabalho MapReduce será invocado no back-end sempre que tentarmos executar uma instrução Pig Latin para processar os dados. Ele realizará uma operação específica nos dados já existentes no HDFS.
Quais são algumas das principais aplicações do Apache Pig?
O Apache Pig acabou sendo uma benção para todos os programadores que não eram capazes de entender a programação Java com proficiência. A melhor coisa sobre o Apache Pig é que ele oferece flexibilidade, requer menos esforço do que outras plataformas e reduz a complexidade do código.
Algumas das principais aplicações do Apache Pig são:
1. Processando um grande volume de dados dos conjuntos de dados
2. Útil em todos os lugares onde são necessários insights analíticos com o uso de amostragem
3. Para a coleta de uma grande quantidade de conjuntos de dados na forma de rastreamentos da Web e logs de pesquisa
4. Necessário para prototipagem dos algoritmos de processamento de grandes conjuntos de dados