
Hadoop 中的 Apache Pig 架構:特性、應用程序、執行流程
已發表: 2020-06-26目錄
為什麼 Apache Pig 如此受歡迎
為了分析和處理大數據,Hadoop 使用 Map Reduce。 Map Reduce 是一個用 Java 編寫的程序。 但是,開發人員發現編寫和維護這些冗長的 Java 代碼具有挑戰性。 使用 Apache Pig,開發人員可以快速分析和處理大型數據集,而無需使用複雜的 Java 代碼。 雅虎研究人員開發的 Apache Pig 在大量數據集上執行 Map Reduce 作業,並為開發人員提供了一個簡單的界面來有效地處理數據。
Apache Pig 的出現對於那些不懂 Java 編程的人來說是一個福音。 今天,Apache Pig 在開發人員中變得非常流行,因為它提供了靈活性、降低了代碼複雜性並且需要的工作量更少。 如果您是初學者並且有興趣了解有關數據科學的更多信息,請查看我們來自頂尖大學的數據科學課程。
Map Reduce 與 Apache Pig
下表總結了 Map Reduce 和 Apache Pig 的區別:
| 阿帕奇豬 | 地圖縮減 |
| 腳本語言 | 編譯語言 |
| 提供更高層次的抽象 | 提供低層次的抽象 |
| 需要幾行代碼(10行代碼可以總結200行Map Reduce代碼) | 需要更廣泛的代碼(更多代碼行) |
| 需要更少的開發時間和精力 | 需要更多的開發時間和精力 |
| 代碼效率較低 | 與 Apache Pig 相比,代碼效率更高 |
Apache Pig 特性
Apache Pig 提供以下功能:
- 允許程序員編寫更少的代碼行。 程序員可以使用 Pig Latin 語言僅用 10 行代碼編寫 200 行 Java 代碼。
- Apache Pig 多查詢方法減少了開發時間。
- Apache pig 擁有豐富的數據集,用於執行連接、過濾、排序、加載、分組等操作。
- Pig Latin 語言與 SQL 非常相似。 具有良好 SQL 知識的程序員發現編寫 Pig 腳本很容易。
- 允許程序員編寫更少的代碼行。 程序員可以使用 Pig Latin 語言僅用 10 行代碼編寫 200 行 Java 代碼。
- Apache Pig 處理結構化和非結構化數據分析。
Apache Pig 應用程序
一些 Apache Pig 應用程序是:
- 處理大量數據
- 支持跨大型數據集的快速原型設計和臨時查詢
- 在搜索平台中執行數據處理
- 處理時間敏感的數據加載
- 電信公司用於對用戶通話數據信息進行去標識化。
什麼是阿帕奇豬?
Map Reduce 需要將程序轉換為 map 和 reduce 階段。 由於並非所有數據分析師都熟悉 Map Reduce,因此雅虎研究人員引入了 Apache pig 來彌補這一差距。 Pig 構建在 Hadoop 之上,提供了高級抽象,使程序員能夠花費更少的時間編寫複雜的 Map Reduce 程序。 豬不是首字母縮略詞; 它以家畜命名。 作為動物豬吃任何東西,豬可以處理任何類型的數據。

資源
Hadoop 中的 Apache Pig 架構
Apache Pig 架構由一個 Pig Latin 解釋器組成,它使用 Pig Latin 腳本來處理和分析海量數據集。 程序員使用 Pig Latin 語言分析 Hadoop 環境中的大型數據集。 Apache pig 擁有豐富的數據集,用於執行不同的數據操作,如連接、過濾、排序、加載、分組等。
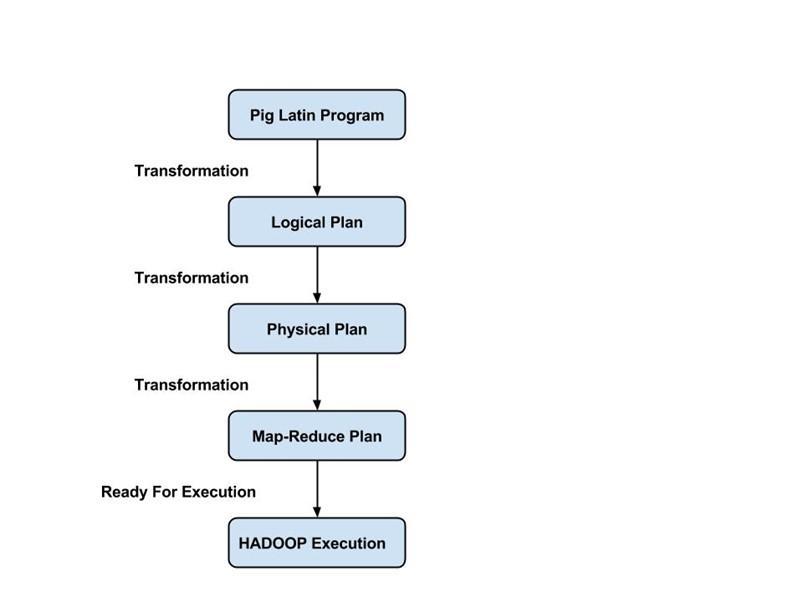
程序員必須使用 Pig Latin 語言編寫 Pig 腳本來執行特定任務。 Pig 將這些 Pig 腳本轉換為一系列 Map-Reduce 作業,以簡化程序員的工作。 Pig Latin 程序通過各種機制執行,例如 UDF、嵌入式和 Grunt shell。
Apache Pig 架構由以下主要組件組成:
- 解析器
- 優化器
- 編譯器
- 執行引擎
- 執行模式
讓我們詳細研究所有這些 Pig 組件。
豬拉丁文
Pig 腳本被提交到 Pig 執行環境以產生所需的結果。
您可以使用以下方法之一執行 Pig 腳本:
- 咕嚕殼
- 腳本文件
- 嵌入式腳本
解析器
Parser 處理所有 Pig Latin 語句或命令。 Parser 對 Pig 語句執行多項檢查,如語法檢查、類型檢查,並生成DAG(有向無環圖)輸出。 DAG 輸出將腳本的所有邏輯運算符表示為節點,將數據流表示為邊。

優化器
解析操作完成並生成 DAG 輸出後,將輸出傳遞給優化器。 優化器然後對輸出執行優化活動,例如拆分、合併、投影、下推、轉換和重新排序等。優化器處理提取的數據並通過執行下推和投影活動省略不必要的數據或列,並提高查詢性能.
編譯器
編譯器將優化器生成的輸出編譯成一系列 Map Reduce 作業。 編譯器自動將 Pig 作業轉換為 Map Reduce 作業,並通過重新排列執行順序來優化性能。
執行引擎
在執行完上述所有操作後,這些 Map Reduce 作業被提交給執行引擎,然後在 Hadoop 平台上執行以產生所需的結果。 然後,您可以使用 DUMP 語句在屏幕上顯示結果或使用 STORE 語句將結果存儲在HDFS (Hadoop 分佈式文件系統)中。
執行模式
Apache Pig 以本地和 Map Reduce 兩種執行模式執行。 執行模式的選擇取決於數據的存儲位置以及您要運行 Pig 腳本的位置。 您可以將數據存儲在本地(在單台機器中)或分佈式 Hadoop 集群環境中。
- 本地模式——如果您的數據集很小,您可以使用本地模式。 在本地模式下,Pig 使用本地主機和文件系統在單個 JVM 中運行。 在這種模式下,並行映射器執行是不可能的,因為所有文件都安裝並在本地主機上運行。 您可以使用pig -x local命令指定本地模式。
- Map Reduce 模式——Apache Pig 默認使用 Map Reduce 模式。 在 Map Reduce 模式下,程序員對已存儲在HDFS(Hadoop 分佈式文件系統)中的數據執行 Pig Latin 語句。 您可以使用pig -x mapreduce命令指定 Map-Reduce 模式。
資源
豬拉丁數據模型
Pig Latin 數據模型允許 Pig 處理任何類型的數據。 Pig Latin 數據模型是完全嵌套的,可以處理整數、浮點數等原子數據類型和 Map 和元組等非原子復雜數據類型。
讓我們深入了解數據模型:
- 原子——原子是以字符串形式存儲的單個值,可以用作數字和字符串。 Pig 的原子值是整數、雙精度、浮點數、字節數組和字符數組。 單個原子值也稱為字段。
例如,“Kiara”或 27
- 元組 –元組是包含一組有序字段(任何類型)的記錄。 元組與RDBMS(關係數據庫管理系統)中的行非常相似。
例如,(Kiara,27 歲)
- Bag –原子是以字符串形式存儲的單個值,可以用作數字和字符串。 Pig 的原子值是整數、雙精度、浮點數、字節數組和字符數組。 單個原子值也稱為字段。
例如,{(Kiara, 27), (Kehsav, 45)}
- Map –鍵值對集合稱為映射。 鍵必須是唯一的,並且應該是 char 數組類型。 但是,該值可以是任何類型。
例如,[姓名#Kiara,年齡#27]
- 關係——一袋元組稱為關係。
Pig Job的執行流程
以下步驟解釋了 Pig 作業的執行流程:
- 開發人員使用 Pig Latin 語言編寫 Pig 腳本並將其存儲在本地文件系統中。
- 提交 Pig 腳本後,Apache Pig 與編譯器建立連接並生成一系列 Map Reduce Jobs 作為輸出。
- Pig 編譯器從 HDFS 接收原始數據執行操作,並在 Map Reduce 作業完成後將結果存儲到 HDFS。
另請閱讀: Apache Pig 教程
結論
在這篇博客中,我們了解了Apache Pig 架構、Pig 組件、Map Reduce 和 Apache Pig 的區別、Pig Latin 數據模型以及 Pig 作業的執行流程。
Apache Pig 對程序員來說是一個福音,因為它提供了一個具有簡單界面的平台,降低了代碼複雜性,並幫助他們有效地實現了結果。 雅虎、eBay、LinkedIn 和 Twitter 是使用 Pig 處理大量數據的一些公司。
如果您想了解 Apache Pig、數據科學,請查看 IIIT-B 和 upGrad 的數據科學執行 PG 計劃,該計劃是為在職專業人士創建的,並提供 10 多個案例研究和項目、實用的實踐研討會、行業指導專家,與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
Apache Pig 的特點是什麼?
Apache Pig 是一個非常高級的工具或平台,用於處理大型數據集。 數據分析代碼是使用稱為 Pig Latin 的高級腳本語言開發的。 首先,程序員將編寫 Pig Latin 腳本,將數據處理成特定的地圖並減少任務。 Apache Pig 有很多特性,這使它成為一個非常有用的工具。
1. 提供豐富的運算符集來執行不同的操作,如排序、連接、過濾等。
2. Apache Pig 被認為是 SQL 程序員的福音,因為它易於學習、閱讀和編寫。
3. 製作用戶定義的功能和流程很容易
4. 任何流程或功能都需要更少的代碼行
5. 允許用戶對非結構化和結構化數據進行分析
6. Join 和 Split 操作非常容易執行
Apache Pig 中有哪些可用的執行模式?
Apache Pig 可以以兩種不同的模式執行:
1. 本地模式 - 在此模式下,所有文件都將從您的本地文件系統和本地主機安裝和運行。 通常,此模式用於測試目的。 在這裡,您不需要 HDFS 或 Hadoop。
2. MapReduce 模式——在 MapReduce 模式中,Apache Pig 用於加載和處理已經存在於 Hadoop 文件系統 (HDFS) 中的數據。 每當我們嘗試執行 Pig Latin 語句來處理數據時,都會在後端調用 MapReduce 作業。 它將對 HDFS 中已經存在的數據執行特定操作。
Apache Pig 的一些關鍵應用是什麼?
事實證明,Apache Pig 對那些無法熟練理解 Java 編程的程序員來說是一個福音。 Apache Pig 最好的地方在於它提供了靈活性,比其他平台需要更少的努力,並降低了代碼的複雜性。
Apache Pig 的一些關鍵應用包括:
1.從數據集中處理大量數據
2. 在需要使用採樣進行分析洞察力的每個地方都很有用
3.用於網絡爬取和搜索日誌形式的大量數據集的收集
4. 對大型數據集的處理算法進行原型設計所需