
Architecture Apache Pig dans Hadoop : fonctionnalités, applications, flux d'exécution
Publié: 2020-06-26Table des matières
Pourquoi Apache Pig est si populaire
Pour analyser et traiter le Big Data, Hadoop utilise Map Reduce. Map Reduce est un programme écrit en Java. Mais les développeurs trouvent difficile d'écrire et de maintenir ces longs codes Java. Avec Apache Pig, les développeurs peuvent rapidement analyser et traiter de grands ensembles de données sans utiliser de codes Java complexes. Apache Pig développé par les chercheurs de Yahoo exécute des travaux Map Reduce sur de vastes ensembles de données et fournit une interface simple permettant aux développeurs de traiter efficacement les données.
Apache Pig est apparu comme une aubaine pour ceux qui ne comprennent pas la programmation Java. Aujourd'hui, Apache Pig est devenu très populaire parmi les développeurs car il offre de la flexibilité, réduit la complexité du code et nécessite moins d'efforts. Si vous êtes débutant et que vous souhaitez en savoir plus sur la science des données, consultez nos cours de science des données dispensés par les meilleures universités.
Map Reduce contre Apache Pig
Le tableau suivant résume la différence entre Map Reduce et Apache Pig :
| Cochon Apache | Carte Réduire |
| Langage de script | Langage compilé |
| Fournit un niveau d'abstraction plus élevé | Fournit un faible niveau d'abstraction |
| Nécessite quelques lignes de code (10 lignes de code peuvent résumer 200 lignes de code Map Reduce) | Nécessite un code plus étendu (plus de lignes de code) |
| Nécessite moins de temps et d'efforts de développement | Nécessite plus de temps et d'efforts de développement |
| Moins d'efficacité du code | Plus grande efficacité du code par rapport à Apache Pig |
Fonctionnalités d'Apache Pig
Apache Pig propose les fonctionnalités suivantes :
- Permet aux programmeurs d'écrire moins de lignes de codes. Les programmeurs peuvent écrire 200 lignes de code Java en seulement dix lignes en utilisant le langage Pig Latin.
- L'approche multi-requêtes d'Apache Pig réduit le temps de développement.
- Apache pig dispose d'un riche ensemble de jeux de données pour effectuer des opérations telles que joindre, filtrer, trier, charger, regrouper, etc.
- Le langage Pig Latin est très similaire à SQL. Les programmeurs ayant de bonnes connaissances en SQL trouvent facile d'écrire un script Pig.
- Permet aux programmeurs d'écrire moins de lignes de codes. Les programmeurs peuvent écrire 200 lignes de code Java en seulement dix lignes en utilisant le langage Pig Latin.
- Apache Pig gère à la fois l'analyse de données structurées et non structurées.
Applications Apache Pig
Voici quelques-unes des applications Apache Pig :
- Traite un grand volume de données
- Prend en charge le prototypage rapide et les requêtes ad hoc sur de grands ensembles de données
- Effectue le traitement des données dans les plateformes de recherche
- Traite les chargements de données sensibles au facteur temps
- Utilisé par les entreprises de télécommunications pour anonymiser les informations sur les données d'appel de l'utilisateur.
Qu'est-ce qu'Apache Pig ?
Map Reduce nécessite que les programmes soient traduits en étapes de carte et de réduction. Étant donné que tous les analystes de données ne connaissaient pas Map Reduce, Apache Pig a été introduit par les chercheurs de Yahoo pour combler l'écart. Le Pig a été construit sur Hadoop qui fournit un haut niveau d'abstraction et permet aux programmeurs de passer moins de temps à écrire des programmes Map Reduce complexes. Pig n'est pas un acronyme; il porte le nom d'un animal domestique. Comme un cochon animal mange n'importe quoi, Pig peut travailler sur n'importe quel type de données.

La source
Architecture Apache Pig dans Hadoop
L' architecture Apache Pig consiste en un interpréteur Pig Latin qui utilise des scripts Pig Latin pour traiter et analyser des ensembles de données volumineux. Les programmeurs utilisent le langage Pig Latin pour analyser de grands ensembles de données dans l'environnement Hadoop. Apache pig dispose d'un riche ensemble d'ensembles de données pour effectuer différentes opérations de données telles que joindre, filtrer, trier, charger, grouper, etc.
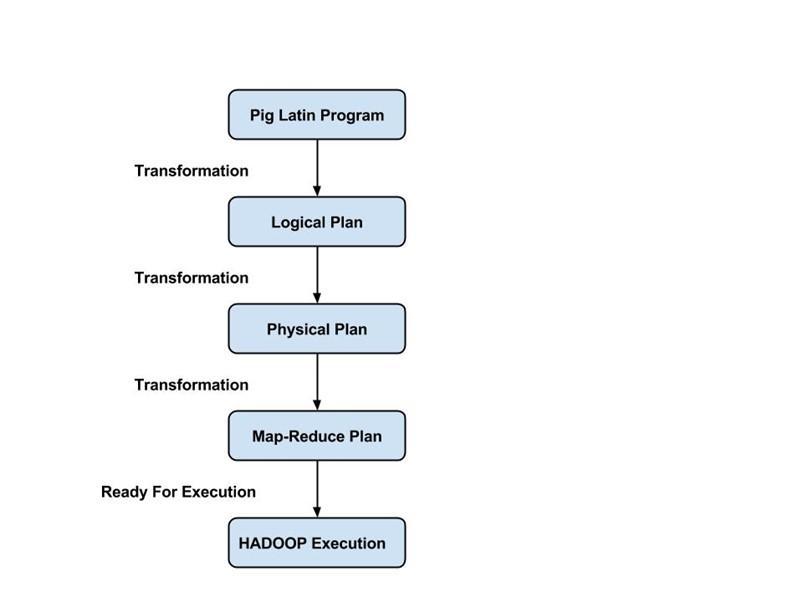
Les programmeurs doivent utiliser le langage Pig Latin pour écrire un script Pig afin d'effectuer une tâche spécifique. Pig convertit ces scripts Pig en une série de tâches Map-Reduce pour faciliter le travail des programmeurs. Les programmes Pig Latin sont exécutés via divers mécanismes tels que les UDF, les shells embarqués et Grunt.
L' architecture d'Apache Pig se compose des principaux composants suivants :
- Analyseur
- Optimiseur
- Compilateur
- Moteur d'exécution
- Mode d'exécution
Étudions en détail tous ces composants de Pig.
Scripts latins de cochon
Les scripts Pig sont soumis à l'environnement d'exécution Pig pour produire les résultats souhaités.
Vous pouvez exécuter les scripts Pig en utilisant l'une des méthodes :
- Coquille de grognement
- Fichier de script
- Script intégré
Analyseur
Parser gère toutes les instructions ou commandes Pig Latin. L'analyseur effectue plusieurs vérifications sur les instructions Pig telles que la vérification de la syntaxe, la vérification du type et génère une sortie DAG (Directed Acyclic Graph) . La sortie DAG représente tous les opérateurs logiques des scripts en tant que nœuds et le flux de données en tant que bords.
Optimiseur
Une fois que l'opération d'analyse est terminée et qu'une sortie DAG est générée, la sortie est transmise à l'optimiseur. L'optimiseur effectue ensuite les activités d'optimisation sur la sortie, telles que le fractionnement, la fusion, la projection, le refoulement, la transformation et la réorganisation, etc. L'optimiseur traite les données extraites et omet les données ou colonnes inutiles en effectuant une activité de refoulement et de projection et améliore les performances des requêtes. .

Compilateur
Le compilateur compile la sortie générée par l'optimiseur dans une série de tâches Map Reduce. Le compilateur convertit automatiquement les travaux Pig en travaux Map Reduce et optimise les performances en réorganisant l'ordre d'exécution.
Moteur d'exécution
Après avoir effectué toutes les opérations ci-dessus, ces tâches Map Reduce sont soumises au moteur d'exécution, qui est ensuite exécuté sur la plate-forme Hadoop pour produire les résultats souhaités. Vous pouvez ensuite utiliser l'instruction DUMP pour afficher les résultats à l'écran ou les instructions STORE pour stocker les résultats dans HDFS (Hadoop Distributed File System).
Mode d'exécution
Apache Pig est exécuté dans deux modes d'exécution qui sont local et Map Reduce. Le choix du mode d'exécution dépend de l'endroit où les données sont stockées et de l'endroit où vous souhaitez exécuter le script Pig. Vous pouvez stocker vos données localement (sur une seule machine) ou dans un environnement de cluster Hadoop distribué.
- Mode local – Vous pouvez utiliser le mode local si votre ensemble de données est petit. En mode local, Pig s'exécute dans une seule JVM en utilisant l'hôte et le système de fichiers locaux. Dans ce mode, l'exécution du mappeur parallèle est impossible car tous les fichiers sont installés et exécutés sur l'hôte local. Vous pouvez utiliser la commande pig -x local pour spécifier le mode local.
- Mode Map Reduce – Apache Pig utilise le mode Map Reduce par défaut. En mode Map Reduce, un programmeur exécute les instructions Pig Latin sur des données déjà stockées dans le HDFS (Hadoop Distributed File System) . Vous pouvez utiliser la commande pig -x mapreduce pour spécifier le mode Map-Reduce.
La source
Modèle de données latin cochon
Le modèle de données Pig Latin permet à Pig de gérer tout type de données. Le modèle de données Pig Latin est entièrement imbriqué et peut traiter à la fois des types de données atomiques comme des entiers, des flottants et des types de données complexes non atomiques tels que Map et tuple.
Comprenons le modèle de données en profondeur :
- Atome – Un atome est une valeur unique stockée sous forme de chaîne et peut être utilisé comme nombre et chaîne. Les valeurs atomiques de Pig sont entier, double, flottant, tableau d'octets et tableau de caractères. Une valeur atomique unique est également appelée un champ.
Par exemple, "Kiara" ou 27
- Tuple – Un tuple est un enregistrement qui contient un ensemble ordonné de champs (de tout type). Un tuple est très similaire à une ligne dans un RDBMS (Relational Database Management System) .
Par exemple, (Kiara, 27 ans)
- Sac – Un atome est une valeur unique stockée sous forme de chaîne et peut être utilisé comme nombre et chaîne. Les valeurs atomiques de Pig sont entier, double, flottant, tableau d'octets et tableau de caractères. Une valeur atomique unique est également appelée un champ.
Par exemple, {(Kiara, 27 ans), (Kehsav, 45 ans)}
- Carte – Un ensemble de paires clé-valeur est appelé carte. La clé doit être unique et doit être de type tableau de caractères. Cependant, la valeur peut être de n'importe quelle nature.
Par exemple, [nom#Kiara, âge#27]
- Relation - Un sac de tuples est appelé une relation.
Flux d'exécution d'un Pig Job
Les étapes suivantes expliquent le flux d'exécution d'un travail Pig :
- Le développeur écrit un script Pig en utilisant le langage Pig Latin et le stocke dans le système de fichiers local.
- Après avoir soumis les scripts Pig, Apache Pig établit une connexion avec le compilateur et génère une série de tâches Map Reduce en sortie.
- Le compilateur Pig reçoit des données brutes de HDFS, effectue des opérations et stocke les résultats dans HDFS une fois les travaux Map Reduce terminés.
Lire aussi : Tutoriel Apache Pig
Conclusion
Dans ce blog, nous avons découvert l' architecture Apache Pig , les composants Pig, la différence entre Map Reduce et Apache Pig, le modèle de données Pig Latin et le flux d'exécution d'un travail Pig.
Apache Pig est une aubaine pour les programmeurs car il fournit une plate-forme avec une interface simple, réduit la complexité du code et les aide à obtenir efficacement des résultats. Yahoo, eBay, LinkedIn et Twitter font partie des entreprises qui utilisent Pig pour traiter leurs gros volumes de données.
Si vous êtes curieux d'en savoir plus sur Apache Pig, la science des données, consultez le programme Executive PG en science des données de IIIT-B & upGrad qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, du mentorat avec l'industrie experts, 1-on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Quelles sont les fonctionnalités d'Apache Pig ?
Apache Pig est un outil ou une plate-forme de très haut niveau utilisé pour le traitement de grands ensembles de données. Les codes d'analyse de données sont développés à l'aide d'un langage de script de haut niveau appelé Pig Latin. Premièrement, les programmeurs écriront des scripts Pig Latin pour traiter les données dans une carte spécifique et réduire les tâches. Apache Pig possède de nombreuses fonctionnalités qui en font un outil très utile.
1. Il fournit un riche ensemble d'opérateurs pour effectuer différentes opérations, telles que le tri, les jointures, le filtrage, etc.
2. Apache Pig est considéré comme une aubaine pour les programmeurs SQL car il est facile à apprendre, à lire et à écrire.
3. Il est facile de créer des fonctions et des processus définis par l'utilisateur
4. Moins de lignes de code sont nécessaires pour tout processus ou fonction
5. Permet aux utilisateurs d'effectuer une analyse des données non structurées et structurées
6. Les opérations Join et Split sont assez faciles à réaliser
Quels sont les modes d'exécution disponibles dans Apache Pig ?
Apache Pig peut être exécuté selon deux modes différents :
1. Mode local - Tous les fichiers seront installés et exécutés à partir de votre système de fichiers local et de votre hôte local dans ce mode. Habituellement, ce mode est utilisé à des fins de test. Ici, vous n'aurez pas besoin de HDFS ou de Hadoop.
2. Mode MapReduce - En mode MapReduce, Apache Pig est utilisé pour charger et traiter les données qui existent déjà dans le système de fichiers Hadoop (HDFS). Une tâche MapReduce sera appelée dans le back-end chaque fois que nous essaierons d'exécuter une instruction Pig Latin pour traiter les données. Il effectuera une opération particulière sur les données déjà existantes dans le HDFS.
Quelles sont certaines des principales applications d'Apache Pig ?
Apache Pig s'est avéré être une aubaine pour tous les programmeurs qui n'étaient pas capables de comprendre correctement la programmation Java. La meilleure chose à propos d'Apache Pig est qu'il offre de la flexibilité, nécessite moins d'efforts que les autres plates-formes et réduit la complexité du code.
Certaines des applications clés d'Apache Pig sont :
1. Traiter un grand volume de données à partir des jeux de données
2. Utile à chaque endroit où des informations analytiques sont nécessaires avec l'utilisation de l'échantillonnage
3. Pour la collecte d'une grande quantité d'ensembles de données sous la forme d'explorations Web et de journaux de recherche
4. Requis pour le prototypage des algorithmes de traitement de grands ensembles de données