
Görüntü Sınıflandırma için Evrişimli Sinir Ağı Kullanımı
Yayınlanan: 2020-08-14Görüntü Sınıflandırma Bir Makeover Alır. CNN'e teşekkürler.
Konvolüsyonel Sinir Ağları (CNN'ler), bir görüntüyü alan ve ona bir sınıf ve onu benzersiz kılan bir etiket atayan derin bir öğrenme olgusu olan görüntü sınıflandırmasının bel kemiğidir. CNN kullanarak görüntü sınıflandırması , makine öğrenimi deneylerinin önemli bir bölümünü oluşturur.
CNN ve onun uyarılmış yeteneklerinin kullanılmasıyla birlikte, artık Facebook resim etiketlemeden Amazon ürün tavsiyelerine ve sağlık hizmeti görüntülerinden otomatik arabalara kadar bir dizi uygulama için yaygın olarak kullanılmaktadır. CNN'nin bu kadar popüler olmasının nedeni, çok az ön işleme gerektirmesidir, yani diğer geleneksel algoritmaların yapamayacağı filtreler uygulayarak 2D görüntüleri okuyabilir. CNN kullanarak görüntü sınıflandırmanın nasıl çalıştığını daha derinlemesine inceleyeceğiz .
İçindekiler
CNN nasıl çalışır?
CNN'ler , tümü görüntüleri işlemeye ve sınıflandırmaya yardımcı olan bir giriş katmanı, bir çıkış katmanı ve gizli katmanlarla donatılmıştır. Gizli katmanlar, hepsi çok önemli bir rol oynayan evrişim katmanları, ReLU katmanları, havuz katmanları ve tam bağlantılı katmanlardan oluşur. Evrişimli sinir ağı hakkında daha fazla bilgi edinin.
CNN kullanarak görüntü sınıflandırmanın nasıl çalıştığına bakalım :
Giriş görüntüsünün bir fil olduğunu hayal edin. Piksel içeren bu görüntü, ilk olarak evrişim katmanlarına girilir. Siyah beyaz bir resimse, görüntü 2B katman olarak yorumlanır ve her piksele '0' ve '255' arasında bir değer atanır, '0' tamamen siyah ve '255' tamamen beyaz olur. Öte yandan, bu renkli bir resimse, bu, her bir renk değeri 0 ile 255 arasında olan mavi, yeşil ve kırmızı bir katmana sahip bir 3B dizi haline gelir.

Daha sonra, yazılımın 'filtre' (veya çekirdek) olarak bilinen daha küçük bir görüntü seçtiği matrisin okunması başlar. Filtrenin derinliği, girişin derinliği ile aynıdır. Filtre daha sonra giriş görüntüsü ile birlikte görüntü boyunca 1 birim hareket eden bir evrişim hareketi üretir.
Ardından değerleri orijinal resim değerleriyle çarpar. Tüm çarpılan rakamlar birlikte toplanır ve tek bir sayı üretilir. İşlem tüm görüntü ile birlikte tekrarlanır ve orijinal giriş görüntüsünden daha küçük bir matris elde edilir.
Son diziye bir aktivasyon haritasının özellik haritası denir. Bir görüntünün evrişimi, farklı filtreler uygulayarak kenar algılama, keskinleştirme ve bulanıklaştırma gibi işlemlerin gerçekleştirilmesine yardımcı olur. Tek yapılması gereken, filtrenin boyutu, filtre sayısı ve/veya ağın mimarisi gibi hususları belirlemektir.
İnsan perspektifinden bakıldığında, bu eylem bir görüntünün basit renklerini ve sınırlarını belirlemeye benzer. Bununla birlikte, görüntüyü sınıflandırmak ve onu bir kedinin değil de bir fil yapan özellikleri tanımak için, büyük kulaklar ve filin hortumu gibi benzersiz özelliklerin tanımlanması gerekir. Doğrusal olmayan ve havuz katmanları burada devreye girer.
Doğrusal olmayan katman (ReLU), görüntünün doğrusal olmayanlığını artırmak için özellik haritalarına bir etkinleştirme işlevinin uygulandığı evrişim katmanını takip eder. ReLU katmanı, tüm negatif değerleri kaldırır ve görüntünün doğruluğunu artırır. Tanh veya sigmoid gibi başka işlemler olsa da, ağı çok daha hızlı eğitebildiği için ReLU en popüler olanıdır.
Sonraki adım, boyutu veya konumu ne olursa olsun, ağın bu görüntüyü her zaman tanıyabilmesi için aynı nesnenin birkaç görüntüsünü oluşturmaktır. Örneğin, fil resminde ağ, fili yürüyor, hareketsiz duruyor veya koşuyor olsa da tanıması gerekir. Görüntü esnekliği olmalı ve işte burada havuzlama katmanı devreye giriyor.
Giriş görüntüsünün boyutunu kademeli olarak azaltmak için görüntünün ölçümleriyle (yükseklik ve genişlik) çalışır, böylece görüntüdeki nesneler nerede olursa olsun tespit edilebilir ve tanımlanabilir.
Havuzlama ayrıca, yeni bilgiler için kapsam olmaksızın çok fazla bilgi olduğunda 'fazla uydurma'yı kontrol etmeye yardımcı olur. Belki de en yaygın havuzlama örneği, görüntünün bir dizi örtüşmeyen alana bölündüğü maksimum havuzlamadır.
Maksimum havuzlama, tüm ekstra bilgilerin hariç tutulması ve görüntünün boyutu küçülmesi için her alandaki maksimum değeri belirlemekle ilgilidir. Bu eylem, görüntüdeki bozulmaları da hesaba katmaya yardımcı olur.
Şimdi CNN'yi kullanmak için bir yapay sinir ağı ekleyen tam bağlantılı katman geliyor. Bu yapay ağ, farklı özellikleri birleştirir ve görüntü sınıflarını daha doğru bir şekilde tahmin etmeye yardımcı olur. Bu aşamada, sinir ağının ağırlığına göre hata fonksiyonunun gradyanı hesaplanır. Ağırlıklar ve özellik algılayıcılar performansı optimize etmek için ayarlanır ve bu işlem tekrar tekrar tekrarlanır.
CNN mimarisi şöyle görünür:
Kaynak
CNN Application-MNIST için veri kümelerinden yararlanma
CNN'yi etkin bir şekilde uygulamak için çeşitli veri kümeleri kullanılabilir. CNN kullanarak görüntü sınıflandırmada hayati önem taşıyan en popüler üç tanesi MNIST, CIFAR-10 ve ImageNet'tir. Önce MNIST'e bakalım.
1. MNİST
MNIST, Modifiye Ulusal Standartlar ve Teknoloji Enstitüsü veri kümesinin kısaltmasıdır ve 0 ile 9 arasında el yazısıyla yazılmış tek basamaklı 60.000 küçük, kare 28×28 gri tonlamalı görüntüden oluşur. kısmı, 'çözüldü.' CNN kullanarak görüntü sınıflandırmasını uygulamak, geliştirmek ve değerlendirmek için bilgisayarlı görü ve derin öğrenmede kullanılabilir . Diğer şeylerin yanı sıra bu, modelin performansını değerlendirme, olası iyileştirmeleri keşfetme ve yeni verileri tahmin etmek için kullanma adımlarını içerir.
USP'si, zaten kullanabileceğimiz iyi tanımlanmış bir tren ve test veri setine sahip olmasıdır. Bu eğitim seti, bir eğitim çalıştırma modelinin performansının değerlendirilmesi gerekiyorsa, ayrıca bir trene bölünebilir ve veri setini doğrulayabilir. Trendeki performansı ve her çalıştırmadaki doğrulama seti, modelin sorunu ne kadar iyi öğrendiğine dair daha fazla bilgi için öğrenme eğrileri olarak kaydedilebilir.
Önde gelen sinir ağı API'lerinden biri olan Keras, modele “validation_data ” argümanını şart koşarak bunu desteklemektedir. Modeli eğitirken, sonunda her eğitim çalıştırmasındaki kayıp ve metrikler için model performansından bahseden bir nesne döndüren Fit() işlevi. Neyse ki, MNIST varsayılan olarak Keras ile donatılmıştır ve tren ve test dosyaları sadece birkaç satır kod kullanılarak yüklenebilir.
İlginç bir şekilde, New York Üniversitesi'ndeki Courant Matematik Bilimleri Enstitüsü'nde Profesör olan Yann LeCun ve New York'taki Google Labs'de Araştırma Bilimcisi olan Corinna Cortes'in bir makalesi, MNIST'in Özel Veritabanı 3'ün (SD-3) orijinal olarak atandığına işaret ediyor. Eğitim Seti. Özel Veritabanı 1 (SD-1) test seti olarak belirlendi.

Bununla birlikte, SD-3'ün SD-1'den daha kolay tanımlanıp tanınmasının daha kolay olduğuna inanıyorlar çünkü SD-3, Sayım Bürosunda çalışanlardan, SD-1 ise lise öğrencilerinden elde edildi. Öğrenme deneylerinden elde edilen doğru sonuçlar, sonucun eğitim seti ve testten bağımsız olmasını zorunlu kıldığı için, veri setlerini kaçırarak yeni bir veri tabanı geliştirmek gerekli görülmüştür.
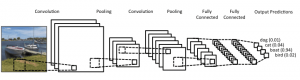
Veri kümesini kullanırken, onu mini toplu işlere bölmeniz, paylaşılan değişkenlerde saklamanız ve mini toplu iş dizinine göre erişmeniz önerilir. Paylaşılan değişkenlere olan ihtiyacı merak edebilirsiniz, ancak bu GPU'yu kullanmakla bağlantılıdır. Olan şu ki, verileri GPU belleğine kopyalarken, her mini grubu gerektiği gibi ve gerektiğinde ayrı ayrı kopyalarsanız, GPU kodu yavaşlayacak ve CPU kodundan çok daha hızlı olmayacaktır. Verileriniz Theano paylaşılan değişkenlerinde varsa, paylaşılan değişkenler oluşturulduğunda tüm verileri tek seferde GPU'ya kopyalamak için iyi bir şans vardır.
Daha sonra GPU, CPU belleğinden bilgi kopyalamaya gerek kalmadan bu paylaşılan değişkenlere erişerek mini grubu kullanabilir. Ayrıca, veri noktaları genellikle gerçek sayılar ve etiket tamsayıları olduğundan, kodun daha kolay okunmasını sağlamak için doğrulama kümesi, eğitim kümesi ve test kümesinin yanı sıra bunlar için farklı değişkenler kullanmak iyi olur.
Aşağıdaki kod, verileri nasıl depolayacağınızı ve bir mini partiye nasıl erişeceğinizi gösterir:
Kaynak
2. CIFAR-10 Veri Kümesi
CIFAR, Kanada İleri Araştırma Enstitüsü anlamına gelir ve CIFAR-10 veri seti, CIFAR-100 veri seti ile birlikte CIFAR enstitüsündeki araştırmacılar tarafından geliştirilmiştir. CIFAR-10 veri seti, kedi, gemi, kuş, kurbağa vb. on sınıfa ait nesnelerin 60.000 adet 32×32 piksel renkli görüntülerinden oluşmaktadır. Bu görüntüler ortalama bir fotoğraftan çok daha küçüktür ve bilgisayarla görme amaçlıdır.
CIFAR, CNN sürecini kullanan görüntü sınıflandırmasında %80 ve test veri setinde %90 doğru olan, iyi anlaşılmış, basit bir veri setidir . Ayrıca, bir test grubuna ve beş eğitim grubuna yayılmış 1.000 adede kadar görüntü.
CIFAR-10 veri seti, her sınıftan rastgele seçilmiş 1000 görüntüden oluşur, ancak bazı gruplar bir sınıftan diğerinden daha fazla görüntü içerebilir. Ancak eğitim grupları, her sınıftan tam olarak 5.000 görüntü içerir. CIFAR-10 veri seti, CNN kullanarak problemlerin görüntü sınıflandırmasını çözmek için bir başlangıç noktası olarak kullanım kolaylığı nedeniyle tercih edilir .
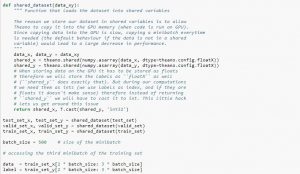
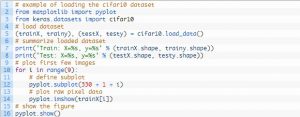
Test donanımının tasarımı modülerdir ve veri kümesi yükleme, model tanımlama, veri kümesi hazırlama ve değerlendirme ve sonuç sunumunu içeren beş unsurla geliştirilebilir. Aşağıdaki örnek, eğitim veri kümesindeki ilk dokuz görüntüyle Keras API'sini kullanan CIFAR-10 veri kümesini göstermektedir:
Kaynak
Örneği çalıştırmak, CIFAR-10 veri kümesini yükler ve şekillerini yazdırır.
3. Görüntü Ağı
ImageNet, görüntüleri önceden tanımlanmış kelimelere ve ifadelere dayalı olarak yaklaşık 22.000 kategoriye ayırmayı ve etiketlemeyi amaçlar. Bunu yapmak için, her kelimenin veya ifadenin bir eşanlamlı veya sözdizimi (kısaca) olduğu WordNet hiyerarşisini takip eder. ImageNet'te tüm görüntüler, synset başına binden fazla görüntüye sahip olacak şekilde bu synset'lere göre düzenlenir.
Ancak, bilgisayarla görme ve derin öğrenmede ImageNet'ten bahsedildiğinde, aslında kastedilen ImageNet Büyük Ölçekli Tanıma Mücadelesi veya ILSVRC'dir. Buradaki amaç, eğitim veri kümesi yaklaşık 1,2 milyon görüntü içerdiğinden 100.000'den fazla test görüntüsü kullanarak bir görüntüyü 1.000 farklı kategoriye ayırmaktır.
Belki de buradaki en büyük zorluk, ImageNet'teki görüntülerin 224×224 boyutunda olması ve bu nedenle bu kadar büyük miktarda veriyi işlemek için çok büyük CPU, GPU ve RAM kapasitesi gerektirmesidir. Bu, ortalama bir dizüstü bilgisayar için imkansız olabilir, peki bu sorunun üstesinden nasıl gelinir?
Bunu yapmanın bir yolu, ImageNet'ten çıkarılan ve çok fazla kaynak gerektirmeyen bir veri kümesi olan Imagenette'i kullanmaktır. Bu veri kümesinde, her sınıf için ayrı klasörler içeren 'train' (eğitim) ve 'Val' (doğrulama) adlı iki klasör bulunur. Tüm bu sınıflar, orijinal veri kümesiyle aynı kimliğe sahiptir ve sınıfların her biri yaklaşık 1.000 görüntüye sahiptir, bu nedenle tüm kurulum oldukça dengelidir.
Başka bir seçenek de, büyük veri kümelerinde önceden eğitilmiş ağırlıkları kullanan bir yöntem olan aktarım öğrenimini kullanmaktır. Bu, CNN kullanarak görüntü sınıflandırmanın çok etkili bir yoludur çünkü bizim için iyi çalışan modeller üretmek için kullanabiliriz. CNN modelini kullanan bir görüntü sınıflandırmasının yapabilmesi gereken bir yön, aynı sınıfa ait görüntüleri sınıflandırmak ve farklı olanları ayırt etmektir. Bu, önceden eğitilmiş ağırlıkları kullanabileceğimiz yerdir. Buradaki avantaj, birlikte çalıştığımız veri kümesinin türüne bağlı olarak farklı yöntemler kullanabilmemizdir.
Ayrıca Okuyun: ML Mühendislerinin Bilmesi Gereken 7 Yapay Sinir Ağı Türü
Özetliyor
Özetlemek gerekirse, CNN kullanarak görüntü sınıflandırma işlemi daha kolay, daha doğru ve daha az işlem ağırlıklı hale getirdi. Makine öğrenimini daha derinlemesine incelemek istiyorsanız, upGrad'da bir profesyonel gibi ustalaşmanıza yardımcı olacak bir dizi kurs vardır!
upGrad , çok çeşitli alt kategorilerle çevrimiçi olarak çeşitli kurslar sunar; daha fazla bilgi için resmi sitesini ziyaret edin .
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT- sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka PG Diplomasına göz atın. B Mezun statüsü, 5+ pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
Evrişimli sinir ağları nedir?
Konvolüsyonel sinir ağları (CNN'ler) veya convnet'ler, en yaygın olarak görsel görüntüleri analiz etmek için uygulanan derin, ileri beslemeli yapay sinir ağlarının bir kategorisidir. CNN'lerin tasarımı, ses, konuşma ve diğer alanlara da uygulanmış olmalarına rağmen, memeli görsel korteksinin organizasyonundan gevşek bir şekilde esinlenmiştir. CNN'ler, minimum ön işleme gerektirecek şekilde tasarlanmış çok katmanlı algılayıcıların bir varyasyonunu kullanır. Bu, onları daha az hataya açık hale getirir ve çeşitli problemler için daha taşınabilir hale getirir, ancak girdilerinde doğrusal olmayan dönüşümler gerçekleştirme yeteneğini feda eder.
Evrişimli sinir ağları neden görüntü sınıflandırması için iyidir?
CNN'nin en büyük sınırlaması, bir görüntüdeki bağlamı kavrayamamasıdır. Ayrıca yüz ve renk yapamıyor. CNN'nin daha fazla sınırlaması: Sinir ağlarında kullanılan öğrenme teknikleri, nesne tanıma, öğrenme, uzamsal farkındalık ve deneyim aktarma yeteneği gibi daha yüksek bilişsel işlevleri yeniden üretmek için yeterli değildir. Sinir ağlarının mimarisi bu sınırlamaların üstesinden gelebilecek kadar esnek değildir.