
Использование сверточной нейронной сети для классификации изображений
Опубликовано: 2020-08-14Классификация изображений преображается. Благодаря CNN.
Сверточные нейронные сети (CNN) являются основой классификации изображений, явления глубокого обучения, которое берет изображение и присваивает ему класс и метку, которые делают его уникальным. Классификация изображений с использованием CNN составляет значительную часть экспериментов по машинному обучению.
Наряду с использованием CNN и индуцированных им возможностей, он теперь широко используется для целого ряда приложений — от тегов к фотографиям в Facebook до рекомендаций продуктов Amazon и изображений здравоохранения до автоматических автомобилей. Причина популярности CNN заключается в том, что она требует очень небольшой предварительной обработки, а это означает, что она может считывать 2D-изображения, применяя фильтры, недоступные другим традиционным алгоритмам. Мы углубимся в процесс того, как работает классификация изображений с использованием CNN .
Оглавление
Как работает CNN?
CNN оснащены входным слоем, выходным слоем и скрытыми слоями, которые помогают обрабатывать и классифицировать изображения. Скрытые слои включают сверточные слои, слои ReLU, объединяющие слои и полносвязные слои, все из которых играют решающую роль. Узнайте больше о сверточной нейронной сети.
Давайте посмотрим, как работает классификация изображений с помощью CNN :
Представьте, что входное изображение — это изображение слона. Это изображение с пикселями сначала вводится в сверточные слои. Если это черно-белое изображение, оно интерпретируется как 2D-слой, где каждому пикселю присваивается значение от «0» до «255», где «0» означает полностью черный, а «255» — полностью белый. Если, с другой стороны, это цветное изображение, оно становится трехмерным массивом с синим, зеленым и красным слоями со значением каждого цвета от 0 до 255.

Затем начинается чтение матрицы, для которого программа выбирает изображение меньшего размера, известное как «фильтр» (или ядро). Глубина фильтра такая же, как и глубина входа. Затем фильтр производит сверточное движение вместе с входным изображением, перемещаясь вправо по изображению на 1 единицу.
Затем он умножает значения на исходные значения изображения. Все перемноженные числа складываются вместе, и получается одно число. Процесс повторяется со всем изображением, и получается матрица, меньшая, чем исходное входное изображение.
Окончательный массив называется картой признаков карты активации. Свертка изображения помогает выполнять такие операции, как обнаружение краев, повышение резкости и размытие, применяя различные фильтры. Все, что нужно сделать, это указать такие аспекты, как размер фильтра, количество фильтров и/или архитектуру сети.
С точки зрения человека это действие похоже на определение простых цветов и границ изображения. Однако, чтобы классифицировать изображение и распознать черты, которые делают его, скажем, изображением слона, а не кошки, необходимо идентифицировать уникальные черты, такие как большие уши и хобот слона. Вот тут-то и появляются нелинейные слои и слои пула.
Нелинейный слой (ReLU) следует за слоем свертки, где к картам объектов применяется функция активации для увеличения нелинейности изображения. Слой ReLU удаляет все отрицательные значения и повышает точность изображения. Хотя есть и другие операции, такие как tanh или sigmoid, ReLU является наиболее популярным, поскольку он может обучать сеть намного быстрее.
Следующим шагом является создание нескольких изображений одного и того же объекта, чтобы сеть всегда могла распознать это изображение, независимо от его размера или местоположения. Например, на изображении слона сеть должна распознавать слона, идет ли он, стоит на месте или бежит. Должна быть гибкость изображения, и здесь на помощь приходит слой пула.
Он работает с измерениями изображения (высота и ширина), чтобы постепенно уменьшать размер входного изображения, чтобы объекты на изображении можно было обнаружить и идентифицировать, где бы они ни находились.
Объединение также помогает контролировать «переоснащение», когда информации слишком много и нет места для новой. Пожалуй, наиболее распространенным примером объединения является максимальное объединение, когда изображение делится на ряд непересекающихся областей.
Максимальный пул — это определение максимального значения в каждой области, чтобы исключить всю дополнительную информацию и уменьшить размер изображения. Это действие также помогает учитывать искажения изображения.
Теперь идет полносвязный слой, который добавляет искусственную нейронную сеть для использования CNN. Эта искусственная сеть сочетает в себе различные функции и помогает предсказывать классы изображений с большей точностью. На этом этапе вычисляется градиент функции ошибок относительно веса нейронной сети. Детекторы весов и признаков настраиваются для оптимизации производительности, и этот процесс многократно повторяется.
Вот как выглядит архитектура CNN:
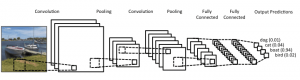
Источник
Использование наборов данных для CNN Application-MNIST
Для эффективного применения CNN можно использовать несколько наборов данных. Тремя наиболее популярными из них, жизненно важными для классификации изображений с использованием CNN , являются MNIST, CIFAR-10 и ImageNet. Давайте сначала посмотрим на MNIST.
1. МНИСТ
MNIST — это аббревиатура модифицированного набора данных Национального института стандартов и технологий, который содержит 60 000 небольших квадратных изображений 28×28 в градациях серого, состоящих из отдельных рукописных цифр от 0 до 9. MNIST — это популярный и понятный набор данных, часть, «решено». Его можно использовать в компьютерном зрении и глубоком обучении для практики, разработки и оценки классификации изображений с использованием CNN . Помимо прочего, это включает шаги по оценке производительности модели, изучению возможных улучшений и использованию ее для прогнозирования новых данных.
Его USP заключается в том, что у него уже есть четко определенный набор данных для обучения и тестирования, который мы можем использовать. Этот тренировочный набор можно дополнительно разделить на набор данных для обучения и проверки, если нужно оценить производительность модели тренировочного прогона. Его производительность в наборе поездов и проверок при каждом запуске может быть записана в виде кривых обучения для лучшего понимания того, насколько хорошо модель изучает проблему.
Keras, один из ведущих API-интерфейсов нейронных сетей, поддерживает это, указывая аргумент «validation_data » для модели. Fit() при обучении модели, которая в конечном итоге возвращает объект, в котором упоминается производительность модели для потерь и метрик при каждом запуске обучения. К счастью, MNIST по умолчанию оснащен Keras, а файлы поезда и теста можно загрузить с помощью всего нескольких строк кода.
Интересно, что в статье Яна Лекуна, профессора Института математических наук Куранта при Нью-Йоркском университете, и Коринны Кортес, научного сотрудника Google Labs в Нью-Йорке, указывается, что специальная база данных MNIST 3 (SD-3) изначально была назначена в качестве Обучающий набор. В качестве тестового набора была выбрана специальная база данных 1 (SD-1).

Однако они считают, что SD-3 гораздо легче идентифицировать и распознать, чем SD-1, потому что SD-3 был получен от сотрудников, работающих в Бюро переписи населения, а SD-1 был получен от старшеклассников. Поскольку точные выводы из обучающих экспериментов требуют, чтобы результат не зависел от обучающего набора и теста, было сочтено необходимым разработать новую базу данных, пропустив наборы данных.
При использовании набора данных рекомендуется разделить его на мини-пакеты, хранить в общих переменных и обращаться к ним на основе индекса мини-пакета. Вы можете задаться вопросом о необходимости общих переменных, но это связано с использованием GPU. Что происходит, так это то, что при копировании данных в память GPU, если вы копируете каждый мини-пакет отдельно по мере необходимости, код GPU будет работать медленнее и не намного быстрее, чем код CPU. Если у вас есть данные в общих переменных Theano, есть хороший шанс скопировать все данные на графический процессор за один раз при построении общих переменных.
Позже GPU может использовать мини-пакет, обращаясь к этим общим переменным без необходимости копировать информацию из памяти CPU. Кроме того, поскольку точки данных обычно представляют собой действительные числа и целые числа меток, было бы хорошо использовать разные переменные для них, а также для набора проверки, обучающего набора и набора тестов, чтобы упростить чтение кода.
В приведенном ниже коде показано, как хранить данные и получать доступ к мини-пакету:
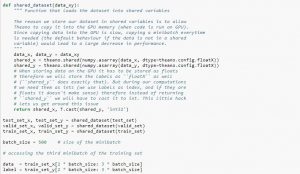
Источник
2. Набор данных CIFAR-10
CIFAR означает Канадский институт перспективных исследований, а набор данных CIFAR-10 был разработан исследователями института CIFAR вместе с набором данных CIFAR-100. Набор данных CIFAR-10 состоит из 60 000 цветных изображений размером 32×32 пикселя объектов, принадлежащих к десяти классам, таким как кошки, корабли, птицы, лягушки и т. д. Эти изображения намного меньше средней фотографии и предназначены для целей компьютерного зрения.
CIFAR — это хорошо понятный, простой набор данных, точность которого составляет 80 % при классификации изображений с использованием процесса CNN и 90 % при наборе тестовых данных. Кроме того, до 1000 изображений распределены по одному тестовому пакету и пяти обучающим пакетам.
Набор данных CIFAR-10 состоит из 1000 случайно выбранных изображений из каждого класса, но некоторые пакеты могут содержать больше изображений из одного класса, чем из другого. Однако обучающие пакеты содержат ровно 5000 изображений из каждого класса. Набор данных CIFAR-10 предпочтительнее из-за его простоты использования в качестве отправной точки для решения классификации изображений CNN с использованием задач.
Дизайн его тестовой системы является модульным, и его можно разработать с пятью элементами, которые включают загрузку набора данных, определение модели, подготовку набора данных, а также оценку и представление результатов. В приведенном ниже примере показан набор данных CIFAR-10 с использованием API Keras с первыми девятью изображениями в наборе обучающих данных:
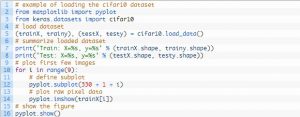
Источник
Выполнение примера загружает набор данных CIFAR-10 и печатает их форму.
3. Имиджнет
ImageNet стремится классифицировать и маркировать изображения почти по 22 000 категорий на основе предопределенных слов и фраз. Для этого он следует иерархии WordNet, где каждое слово или фраза является синонимом или синсетом (сокращенно). В ImageNet все изображения организованы в соответствии с этими синсетами, чтобы иметь более тысячи изображений на синсет.
Однако, когда ImageNet упоминается в компьютерном зрении и глубоком обучении, на самом деле имеется в виду конкурс ImageNet Large Scale Recognition Challenge или ILSVRC. Цель здесь состоит в том, чтобы разделить изображение на 1000 различных категорий, используя более 100 000 тестовых изображений, поскольку набор обучающих данных содержит около 1,2 миллиона изображений.
Возможно, самая большая проблема здесь заключается в том, что изображения в ImageNet имеют размер 224×224, поэтому для обработки такого большого объема данных требуются огромные ресурсы процессора, графического процессора и оперативной памяти. Это может оказаться невозможным для среднего ноутбука, так как же решить эту проблему?
Один из способов сделать это — использовать Imagenette, набор данных, извлеченный из ImageNet, который не требует слишком много ресурсов. Этот набор данных имеет две папки с именами «train» (обучение) и «Val» (проверка) с отдельными папками для каждого класса. Все эти классы имеют тот же идентификатор, что и исходный набор данных, причем каждый из классов имеет около 1000 изображений, поэтому вся настройка довольно сбалансирована.
Другой вариант — использовать трансферное обучение, метод, который использует предварительно обученные веса для больших наборов данных. Это очень эффективный способ классификации изображений с использованием CNN , потому что мы можем использовать его для создания моделей, которые нам подходят. Один аспект, который должна уметь классифицировать изображения с использованием модели CNN , — это классифицировать изображения, принадлежащие к одному и тому же классу, и различать те, которые отличаются. Здесь мы можем использовать предварительно обученные веса. Преимущество здесь в том, что мы можем использовать разные методы в зависимости от типа набора данных, с которым мы работаем.
Читайте также: 7 типов искусственных нейронных сетей, которые нужно знать инженерам машинного обучения
Подведение итогов
Подводя итог, классификация изображений с использованием CNN сделала процесс более простым, точным и менее трудоемким. Если вы хотите глубже погрузиться в машинное обучение, у upGrad есть ряд курсов, которые помогут вам освоить его как профессионалу!
upGrad предлагает различные онлайн-курсы с широким спектром подкатегорий; посетите официальный сайт для получения дополнительной информации.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Что такое сверточные нейронные сети?
Сверточные нейронные сети (CNN) или консети — это категория глубоких искусственных нейронных сетей с прямой связью, которые чаще всего применяются для анализа визуальных образов. Дизайн CNN частично вдохновлен организацией зрительной коры млекопитающих, хотя они также применялись к аудио, речи и другим областям. CNN используют разновидность многослойных персептронов, разработанных для минимальной предварительной обработки. Это делает их менее подверженными ошибкам и более переносимыми для решения разнообразных задач, но жертвует возможностью выполнять нелинейные преобразования своих входных данных.
Почему сверточные нейронные сети хороши для классификации изображений?
Большим ограничением CNN является то, что он не может понять контекст изображения. Он также не может делать лица и делать цвет. Дополнительные ограничения CNN: методы обучения, используемые в нейронных сетях, недостаточны для воспроизведения более высоких когнитивных функций, таких как распознавание объектов, обучение, пространственное восприятие и способность передавать опыт. Архитектура нейронных сетей недостаточно гибка, чтобы преодолеть эти ограничения.